
Heim >Technologie-Peripheriegeräte >KI >Tan Zhongyi: Von Model-Centric zu Data-Centric MLOps trägt dazu bei, dass KI schneller und kostengünstiger implementiert werden kann
Tan Zhongyi: Von Model-Centric zu Data-Centric MLOps trägt dazu bei, dass KI schneller und kostengünstiger implementiert werden kann

- PHPznach vorne
- 2023-04-09 19:51:111473Durchsuche
Gast: Tan Zhongyi
Zusammengestellt von: Qianshan
Enda Ng hat mehrfach zum Ausdruck gebracht, dass sich KI von einem modellzentrierten Forschungsparadigma zu einem datenzentrierten Forschungsparadigma gewandelt hat. Daten sind die größte Herausforderung für die Implementierung von KI. Um dieses Problem zu lösen, müssen wir MLOps-Praktiken und -Tools nutzen, um eine schnelle, einfache und kostengünstige Implementierung von KI zu ermöglichen.
Kürzlich hielt Tan Zhongyi, stellvertretender Vorsitzender des TOC der Open Atomic Foundation, auf der AISummit Global Artificial Intelligence Technology Conference , die von 51CTO veranstaltet wurde, eine Grundsatzrede mit dem Titel „Von modellzentriert zu datenzentriert – MLOps hilft KI.“ „Wie man MLOps schnell und kostengünstig implementiert“ konzentrierte sich darauf, den Teilnehmern die Definition von MLOps zu vermitteln, welche Probleme MLOps lösen können, gängige MLOps-Projekte und wie man die MLOps-Fähigkeiten und das Niveau eines KI-Teams bewertet.
Der Inhalt der Rede ist nun wie folgt gegliedert, ich hoffe, Sie zu inspirieren.
Von Model-Centric zu Data-Centric
Aktuell gibt es in der KI-Branche einen Trend – „von Model-Centric zu Data-Centric“. Was genau bedeutet es? Beginnen wir mit einigen Analysen aus Wissenschaft und Industrie.
- Der KI-Wissenschaftler Andrew NG analysierte, dass der Schlüssel zur aktuellen Implementierung von KI in der Verbesserung der Datenqualität liegt.
- Industrieingenieure und Analysten haben berichtet, dass KI-Projekte häufig scheitern. Die Gründe für das Scheitern verdienen eine weitere Untersuchung.
Andrew Ng hielt einmal seine Rede „MLOps: From Model-centric to Data-centric“, die im Silicon Valley große Resonanz hervorrief. In seiner Rede glaubte er, dass „KI = Code + Daten“ (wobei Code Modelle und Algorithmen umfasst) und verbesserte das KI-System durch die Verbesserung von Daten statt von Code.
Konkret wird die modellzentrierte Methode übernommen, d Das heißt, das Modell beibehalten Keine Änderungen, Verbesserung der Datenqualität, z. B. Verbesserung der Datenbeschriftung, Verbesserung der Datenanmerkungsqualität usw.
Bei demselben KI-Problem ist der Effekt völlig unterschiedlich, unabhängig davon, ob Sie den Code oder die Daten verbessern.
Empirische Belege zeigen, dass die Genauigkeit durch den datenzentrierten Ansatz effektiv verbessert werden kann, der Grad, in dem die Genauigkeit durch eine Verbesserung des Modells oder einen Ersatz des Modells verbessert werden kann, ist jedoch äußerst begrenzt. Beispielsweise betrug die Basisgenauigkeitsrate bei der folgenden Aufgabe zur Erkennung von Stahlplattenfehlern 76,2 %. Nach verschiedenen Vorgängen zum Ändern von Modellen und Anpassen von Parametern wurde die Genauigkeitsrate nahezu nicht verbessert. Durch die Optimierung des Datensatzes konnte die Genauigkeit jedoch um 16,9 % gesteigert werden. Das beweisen auch die Erfahrungen aus anderen Projekten.
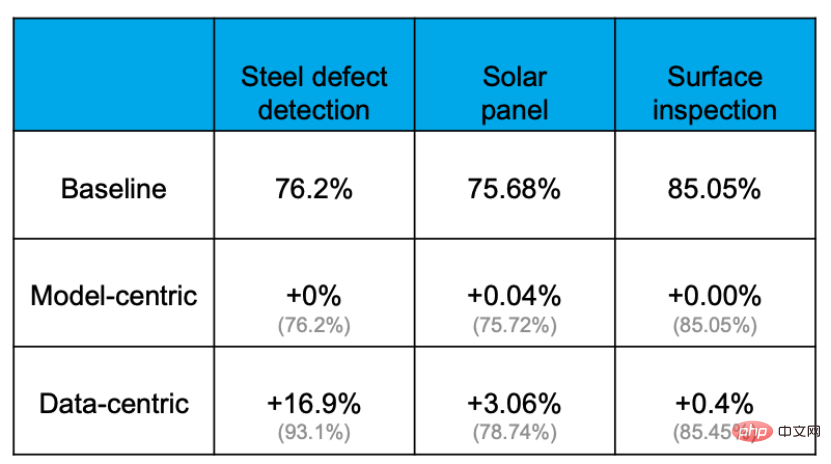
Der Grund dafür ist, dass Daten wichtiger sind als gedacht. Jeder weiß: „Daten sind Nahrung für KI“. In einer echten KI-Anwendung werden etwa 80 % der Zeit für die Verarbeitung datenbezogener Inhalte aufgewendet, die restlichen 20 % werden für die Anpassung des Algorithmus verwendet. Dieser Vorgang ähnelt dem Kochen. 80 % der Zeit werden mit der Vorbereitung der Zutaten, der Verarbeitung und Anpassung verschiedener Zutaten verbracht, aber das eigentliche Kochen dauert möglicherweise nur wenige Minuten, wenn der Koch den Topf in den Topf stellt. Man kann sagen, dass der Schlüssel darüber, ob ein Gericht köstlich ist, in den Zutaten und ihrer Verarbeitung liegt.
Nach Ansicht von Ng besteht die wichtigste Aufgabe von MLOps (dh „Machine Learning Engineering for Production“) in allen Phasen des maschinellen Lernlebenszyklus, einschließlich Datenvorbereitung, Modelltraining, Modell online sowie Modellüberwachung und Umschulung in jeder Phase und stellen Sie stets eine qualitativ hochwertige Datenversorgung sicher.
Das Obige ist, was KI-Wissenschaftler über MLOps wissen. Werfen wir als Nächstes einen Blick auf einige Meinungen von KI-Ingenieuren und Branchenanalysten.
Zunächst einmal ist die aktuelle Misserfolgsquote von KI-Projekten aus Sicht von Branchenanalysten erstaunlich hoch. Eine Umfrage von Dimensional Research im Mai 2019 ergab, dass 78 % der KI-Projekte im Juni 2019 nicht online gingen. Ein Bericht von VentureBeat ergab, dass 87 % der KI-Projekte nicht in der Produktionsumgebung eingesetzt wurden. Mit anderen Worten: Obwohl KI-Wissenschaftler und KI-Ingenieure viel Arbeit geleistet haben, haben sie letztendlich keinen Geschäftswert geschaffen.
Warum kommt es zu diesem Ergebnis? In dem 2015 am NIPS veröffentlichten Artikel „Hidden Technical Debt in Machine Learning Systems“ wurde erwähnt, dass ein echtes Online-KI-System Datenerfassung, Verifizierung, Ressourcenverwaltung, Merkmalsextraktion, Prozessverwaltung, Überwachung und viele andere Inhalte umfasst. Der Code, der sich tatsächlich auf maschinelles Lernen bezieht, macht jedoch nur 5 % des gesamten KI-Systems aus, und 95 % sind technikbezogene Inhalte und datenbezogene Inhalte. Daher sind Daten sowohl die wichtigsten als auch die fehleranfälligsten.
Die Herausforderungen von Daten an ein echtes KI-System liegen hauptsächlich in den folgenden Punkten:
- Skalierung: Das Lesen riesiger Datenmengen ist eine Herausforderung;
- Geringe Latenz: Wie man die hohen QPS- und niedrigen Latenzanforderungen während der Bereitstellung erfüllt;
- Datenänderungen verursachen Modellverfall: Die reale Welt verändert sich ständig, wie man mit Modelleffekten umgeht Dämpfung;
- Zeitreise: Die Verarbeitung von Zeitreihen-Feature-Daten ist anfällig für Probleme.
- Trainings-/Bereitstellungsverzerrung: Die für Training und Vorhersage verwendeten Daten sind inkonsistent.
Die oben aufgeführten sind einige Herausforderungen im Zusammenhang mit Daten beim maschinellen Lernen. Darüber hinaus stellen Echtzeitdaten im wirklichen Leben größere Herausforderungen dar.
Wie kann also KI in großem Maßstab für ein Unternehmen implementiert werden? Am Beispiel eines großen Unternehmens können mehr als 1.000 Anwendungsszenarien und mehr als 1.500 Modelle gleichzeitig online ausgeführt werden. Wie kann man so viele Modelle unterstützen? Wie können wir technisch eine „mehr, schnellere, bessere und kostengünstigere“ Implementierung von KI erreichen?
Viele: Für wichtige Geschäftsprozesse müssen mehrere Szenarien implementiert werden, die bei großen Unternehmen in der Größenordnung von 1.000 oder sogar Zehntausenden liegen können.
Schnell: Die Implementierungszeit jeder Szene sollte kurz und die Iterationsgeschwindigkeit schnell sein. In empfohlenen Szenarien ist es beispielsweise häufig erforderlich, einmal am Tag ein vollständiges Training und alle 15 Minuten oder sogar alle 5 Minuten ein inkrementelles Training durchzuführen.
Gut: Der Landeeffekt jeder Szene muss den Erwartungen entsprechen, zumindest besser als vor der Implementierung.
Einsparung: Die Implementierungskosten jedes Szenarios sind relativ günstig und entsprechen den Erwartungen.
Um wirklich „mehr, schneller, besser und billiger“ zu erreichen, brauchen wir MLOps.

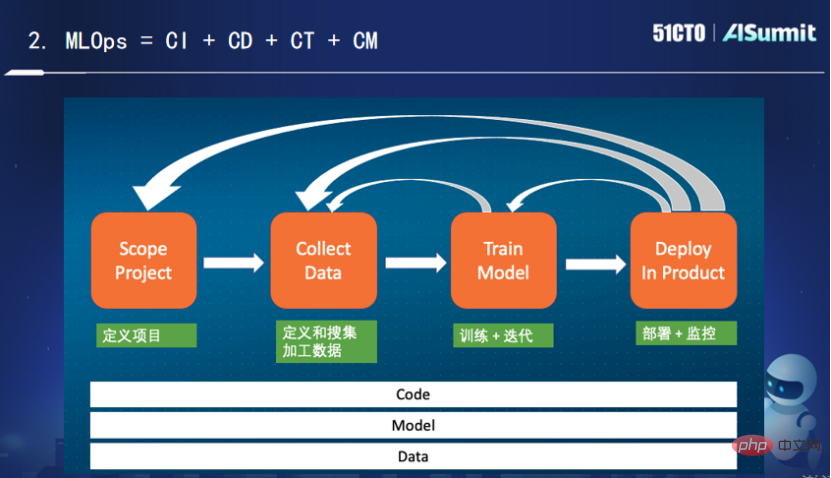
Wenn wir im Bereich der traditionellen Softwareentwicklung auf ähnliche Probleme wie langsame Einführung und instabile Qualität stoßen, verwenden wir DevOps, um diese zu lösen. DevOps hat die Effizienz der Softwareentwicklung und -einführung erheblich verbessert und die schnelle Iteration und Entwicklung moderner Software gefördert. Bei Problemen mit KI-Systemen können wir aus der ausgereiften Erfahrung im DevOps-Bereich lernen, um MLOps zu entwickeln. Wie in der Abbildung gezeigt, wird „Entwicklung maschinellen Lernens + moderne Softwareentwicklung“ zu MLOps.
Was genau ist MLOps?
Derzeit gibt es in der Branche keine Standarddefinition dafür, was MLOps ist.
- Definition aus Wikipedia: MLOps ist eine Reihe von Praktiken, die darauf abzielen, maschinelle Lernmodelle zuverlässig und effizient in der Produktion bereitzustellen und zu warten.
Definition aus der Google Cloud: MLOps ist eine technische Kultur und Praxis für maschinelles Lernen, die darauf abzielt, die Entwicklung und den Betrieb von Systemen für maschinelles Lernen zu vereinheitlichen. - Definition von Microsoft Azure: MLOps kann Datenwissenschaftlern und Anwendungsingenieuren dabei helfen, Modelle für maschinelles Lernen in der Produktion effektiver zu machen.
(3) Nachrichtenwarteschlange: Wird zum Empfangen von Echtzeitdaten verwendet
(4) Planungstool: Planung verschiedener Ressourcen (Computer/Speicher)
(5 ) Feature Store: Registrieren, entdecken und teilen Sie verschiedene Funktionen
(6) Model Store: Funktionen des Modells
(7) Evaluation Store: Modellüberwachung/AB-Tests# 🎜 🎜#
Feature Store, Model Store und Evaluation Store sind allesamt aufstrebende Anwendungen und Plattformen im Bereich des maschinellen Lernens, da manchmal mehrere Modelle gleichzeitig online ausgeführt werden, um eine schnelle Iteration zu erreichen. Durch die Beibehaltung dieser Informationen, um die Iteration effizienter zu gestalten, entstehen diese neuen Anwendungen und neuen Plattformen, wenn es die Zeit erfordert. MLOps‘ einzigartiges Projekt – Feature StoreDas Folgende ist eine kurze Einführung in den Feature Store, die Feature-Plattform. Als einzigartige Plattform im Bereich des maschinellen Lernens verfügt Feature Store über viele Funktionen. Zunächst ist es notwendig, gleichzeitig die Anforderungen des Modelltrainings und der Vorhersage zu erfüllen. Feature-Data-Storage-Engines haben in verschiedenen Szenarien völlig unterschiedliche Anwendungsanforderungen. Das Modelltraining erfordert eine gute Skalierbarkeit und großen Speicherplatz; die Anforderungen an hohe Leistung und geringe Latenz müssen für die Vorhersage in Echtzeit erfüllt sein. Zweitens muss das Problem der Inkonsistenz zwischen der Merkmalsverarbeitung während der Trainings- und Vorhersagephase gelöst werden. Während des Modelltrainings verwenden KI-Wissenschaftler im Allgemeinen Python-Skripte und verwenden dann Spark oder SparkSQL, um die Feature-Verarbeitung abzuschließen. Diese Art der Schulung ist unempfindlich gegenüber Verzögerungen und im Umgang mit Online-Geschäften weniger effizient. Daher verwenden Ingenieure eine leistungsfähigere Sprache, um den Feature-Verarbeitungsprozess zu übersetzen. Allerdings ist der Übersetzungsprozess äußerst umständlich und Ingenieure müssen immer wieder mit Wissenschaftlern abklären, ob die Logik den Erwartungen entspricht. Solange es geringfügig von den Erwartungen abweicht, führt es zu dem Problem der Inkonsistenz zwischen Online und Offline. Drittens muss das Problem der Wiederverwendung bei der Feature-Verarbeitung gelöst werden, um Verschwendung zu vermeiden und effizient zu teilen. In den KI-Anwendungen eines Unternehmens tritt diese Situation häufig auf: Dieselbe Funktion wird von verschiedenen Geschäftsabteilungen verwendet, die Datenquelle stammt aus derselben Protokolldatei und die in der Mitte durchgeführte Extraktionslogik ist ebenfalls ähnlich, liegt jedoch an unterschiedlichen Abteilungen Oder wenn es in verschiedenen Szenarien verwendet wird, kann es nicht wiederverwendet werden, was gleichbedeutend damit ist, dass dieselbe Logik N-mal ausgeführt wird, und die Protokolldateien sind riesig, was eine enorme Verschwendung von Speicherressourcen und Rechenressourcen darstellt. Zusammenfassend lässt sich sagen, dass Feature Store hauptsächlich zur Lösung von Hochleistungs-Feature-Speicher und -Diensten, Modelltraining und Modellvorhersage, Feature-Datenkonsistenz, Feature-Wiederverwendung und anderen Problemen verwendet wird Aktie. Die derzeit auf dem Markt befindlichen Mainstream-Feature-Plattform-Produkte lassen sich grob in drei Kategorien einteilen.- Jedes KI-Unternehmen führt Selbstforschung durch. Solange das Unternehmen einen Schulungsbedarf in Echtzeit hat, werden diese Unternehmen grundsätzlich eine ähnliche Funktionsplattform entwickeln, um die oben genannten drei Probleme zu lösen. Aber diese Feature-Plattform ist eng mit dem Geschäft verbunden.
- SAAS-Produkte oder Teil der von Cloud-Anbietern bereitgestellten Plattform für maschinelles Lernen. Zum Beispiel SageMaker von AWS, Vertex von Google und die Azure-Plattform für maschinelles Lernen von Microsoft. Sie werden über eine in die Plattform für maschinelles Lernen integrierte Funktionsplattform verfügen, um Benutzern die Verwaltung verschiedener komplexer Funktionen zu erleichtern.
- Einige Open-Source- und kommerzielle Produkte. Um nur einige Beispiele zu nennen: Feast, ein Open-Source-Feature-Store-Produkt; Tecton bietet ein vollständiges kommerzielles Open-Source-Feature-Plattform-Produkt; OpenMLDB, ein Open-Source-Feature-Store-Produkt.
 Der Reifegrad ist 2, also automatisiertes Training. Das Modelltraining wird automatisch abgeschlossen, nachdem die Daten aktualisiert wurden, wird sofort eine ähnliche Pipeline für das automatisierte Training gestartet. Die Auswertung und der Start der Trainingsergebnisse erfolgen jedoch weiterhin manuell.
Der Reifegrad ist 2, also automatisiertes Training. Das Modelltraining wird automatisch abgeschlossen, nachdem die Daten aktualisiert wurden, wird sofort eine ähnliche Pipeline für das automatisierte Training gestartet. Die Auswertung und der Start der Trainingsergebnisse erfolgen jedoch weiterhin manuell.
Der Reifegrad ist 3, was einer automatisierten Bereitstellung entspricht. Nachdem das automatische Training des Modells abgeschlossen ist, werden die Bewertung und der Start des Modells automatisch ohne manuellen Eingriff abgeschlossen.
Der Reifegrad ist 4, was eine automatische Umschulung und Bereitstellung bedeutet. Es überwacht kontinuierlich das Online-Modell. Wenn festgestellt wird, dass die Online-Modellfähigkeit von Model DK nachgelassen hat, wird automatisch ein wiederholtes Training ausgelöst. Der gesamte Prozess ist vollständig automatisiert, was als das ausgereifteste System bezeichnet werden kann.
Weitere spannende Inhalte finden Sie auf der offiziellen Website der Konferenz: Zum Anzeigen klicken
Das obige ist der detaillierte Inhalt vonTan Zhongyi: Von Model-Centric zu Data-Centric MLOps trägt dazu bei, dass KI schneller und kostengünstiger implementiert werden kann. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr