
Heim >Technologie-Peripheriegeräte >KI >ICRA 2022 Outstanding Paper: Durch die Umwandlung von 2D-Bildern des autonomen Fahrens in eine Vogelperspektive erhöht sich die Modellerkennungsgenauigkeit um 15 %
ICRA 2022 Outstanding Paper: Durch die Umwandlung von 2D-Bildern des autonomen Fahrens in eine Vogelperspektive erhöht sich die Modellerkennungsgenauigkeit um 15 %

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-09 19:51:141257Durchsuche
Viele Aufgaben beim autonomen Fahren lassen sich leichter von oben nach unten, auf der Karte oder aus der Vogelperspektive (BEV) erledigen. Da viele Themen rund um das autonome Fahren auf die Bodenebene beschränkt sind, ist eine Draufsicht eine praktischere niedrigdimensionale Darstellung und eignet sich ideal für die Navigation, um relevante Hindernisse und Gefahren zu erfassen. Für Szenarien wie autonomes Fahren müssen semantisch segmentierte BEV-Karten als sofortige Schätzungen generiert werden, um frei bewegliche Objekte und Szenen zu verarbeiten, die nur einmal besucht werden.
Um eine BEV-Karte aus einem Bild abzuleiten, muss man die Entsprechung zwischen Bildelementen und ihren Positionen in der Umgebung bestimmen. Einige frühere Untersuchungen verwendeten dichte Tiefenkarten und Bildsegmentierungskarten, um diesen Konvertierungsprozess zu steuern, und einige Untersuchungen erweiterten die Methode der impliziten Analyse von Tiefe und Semantik. Einige Studien nutzen geometrische Prioritäten der Kamera, lernen jedoch nicht explizit die Interaktion zwischen Bildelementen und BEV-Ebenen.
In einem aktuellen Artikel stellten Forscher der University of Surrey einen Aufmerksamkeitsmechanismus vor, um 2D-Bilder des autonomen Fahrens in eine Vogelperspektive umzuwandeln und so das Modell zu erkennen Genauigkeit um 15 % erhöht. Diese Forschung wurde auf der ICRA-Konferenz 2022, die vor kurzem zu Ende ging, mit dem Outstanding Paper Award ausgezeichnet.

Papierlink: https://arxiv.org/pdf/2110.00966.pdf#🎜 🎜#

Anders als frühere Methoden kombiniert diese Studie BEV Die Umrechnung ist Wird als „Image-to-World“-Konvertierungsproblem angesehen , dessen Ziel darin besteht, die vertikalen Scanlinien im Bild und die vertikalen Scanlinien in der BEV-Ausrichtung zu lernen zwischen Polarstrahlen. Daher ist diese projektive Geometrie implizit für das Netzwerk.
Im Ausrichtungsmodell verwendeten die Forscher Transformer, eine aufmerksamkeitsbasierte Sequenzvorhersagestruktur#🎜🎜 ## 🎜🎜#. Mithilfe ihres Aufmerksamkeitsmechanismus modellieren wir explizit die paarweise Interaktion zwischen vertikalen Scanlinien in einem Bild und ihren polaren BEV-Projektionen. Transformer eignen sich ideal für Bild-zu-BEV-Übersetzungsprobleme, da sie über die gegenseitigen Abhängigkeiten zwischen Objekten, Tiefe und Szenenbeleuchtung nachdenken können, um global konsistente Darstellungen zu erzielen. Die Forscher betten das Transformer-basierte Ausrichtungsmodell in eine End-to-End-Lernformel ein, die monokulare Bilder und deren Intrinsik verwendet Die Matrix wird als Eingabe verwendet und dann wird die semantische BEV-Zuordnung statischer und dynamischer Klassen vorhergesagt.
Dieses Papier erstellt eine Architektur, die dabei hilft, die semantische BEV-Zuordnung aus monokularen Bildern um ein Ausrichtungsmodell vorherzusagen. Wie in Abbildung 1 unten dargestellt, enthält es drei Hauptkomponenten: ein Standard-CNN-Backbone zum Extrahieren räumlicher Merkmale auf der Bildebene; einen Encoder-Decoder-Transformer zum Konvertieren der Merkmale auf der Bildebene in BEV-Merkmale; in semantische Karten.
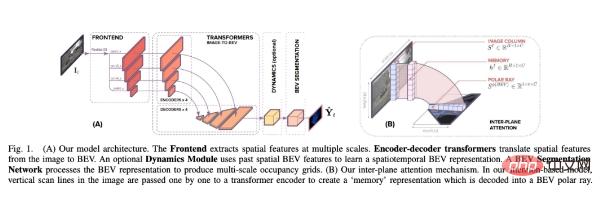
 Im Einzelnen ist der Hauptbeitrag dieser Studie:
Im Einzelnen ist der Hauptbeitrag dieser Studie:
- (1) Verwenden Sie eine Reihe von 1D-Sequenz-Sequenz-Konvertierungen, um eine BEV-Karte aus einem Bild zu generieren.
- (2) Erstellen Sie ein eingeschränktes dateneffizientes Transformer-Netzwerk mit räumlichen Wahrnehmungsfunktionen der Formel (3) und der monotonen Aufmerksamkeit im Sprachbereich zeigen, dass es für eine genaue Zuordnung wichtiger ist, zu wissen, was sich unter einem Punkt im Bild befindet, als zu wissen, was darüber liegt, obwohl die Verwendung beider zur besten Leistung führt
- (4) zeigt, wie axiale Aufmerksamkeit die Leistung verbessert, indem sie zeitliches Bewusstsein schafft, und präsentiert hochmoderne Ergebnisse zu drei großen Datensätzen.
- Experimentelle Ergebnisse
Ablationsexperiment
Wie im ersten Teil der Tabelle 2 unten gezeigt, verglichen die Forscher sanfte Aufmerksamkeit (in beide Richtungen schauen), monotone Aufmerksamkeit beim Zurückverfolgen des Bildes unten (Blick nach unten) und beim Zurückverfolgen des Bildes oben (Blick). nach oben) monotone Aufmerksamkeit.
Es stellt sich heraus, dass es besser ist, von einem Punkt im Bild nach unten zu schauen, als nach oben zu schauen.Entlang lokaler Texturhinweise – Dies steht im Einklang mit der Art und Weise, wie Menschen versuchen, die Entfernung von Objekten in städtischen Umgebungen zu bestimmen. Wir verwenden die Stelle, an der das Objekt die Bodenebene schneidet. Die Ergebnisse zeigen auch, dass die Beobachtung in beide Richtungen die Genauigkeit weiter verbessert und tiefe Schlussfolgerungen diskriminierender macht.

Die Bild-zu-BEV-Konvertierung erfolgt hier als eine Reihe von 1D-Sequenz-zu-Sequenz-Konvertierungen. Eine Frage ist also, was passiert, wenn das gesamte Bild in BEV konvertiert wird. Angesichts der sekundären Rechenzeit und des Speichers, die zum Generieren von Aufmerksamkeitskarten erforderlich sind, ist dieser Ansatz unerschwinglich teuer. Die kontextbezogenen Vorteile der Verwendung des gesamten Bildes können jedoch angenähert werden, indem die horizontale axiale Aufmerksamkeit auf Bildebenenmerkmale gerichtet wird. Bei axialer Aufmerksamkeit durch die Bildzeilen haben Pixel in vertikalen Scanzeilen jetzt einen weitreichenden horizontalen Kontext, und dann wird ein weitreichender vertikaler Kontext durch den Übergang zwischen 1D-Sequenzen wie zuvor bereitgestellt. Wie im mittleren Teil von Tabelle 2 gezeigt,
das Zusammenführen von Kontexten auf langer Sequenzebene kommt dem Modell nicht zuguteund hat sogar eine leichte nachteilige Wirkung. Dies verdeutlicht zwei Punkte: Erstens erfordert jeder transformierte Strahl keine Informationen über die gesamte Breite des Eingabebilds, oder vielmehr liefert der lange Sequenzkontext keine zusätzlichen Informationen im Vergleich zu dem Kontext, der bereits durch die Front-End-Faltung aggregiert wurde . Dies zeigt, dass die Verwendung des gesamten Bildes zur Durchführung der Transformation die Modellgenauigkeit nicht über die Grundlinienbeschränkungsformel hinaus verbessert. Darüber hinaus bedeutet die durch die Einführung horizontaler axialer Aufmerksamkeit verursachte Leistungseinbuße, dass es schwierig ist, die Aufmerksamkeit auf die Trainingssequenzen der Bildbreite zu verwenden Wie man sieht, wird es schwieriger sein, das gesamte Bild als Eingabesequenz zu trainieren.
Polaragnostische vs. polaradaptive Transformatoren: Der letzte Teil von Tabelle 2 vergleicht Po-Ag- und Po-Ad-Varianten. Ein Po-Ag-Modell verfügt über keine Polarisationspositionsinformationen, das Po-Ad der Bildebene enthält Polarkodierungen, die dem Transformer-Encoder hinzugefügt wurden, und für die BEV-Ebene werden diese Informationen dem Decoder hinzugefügt. Das Hinzufügen polarer Kodierungen zu beiden Ebenen ist vorteilhafter als das Hinzufügen zum agnostischen Modell, wobei die dynamische Klasse den größten Beitrag leistet. Das Hinzufügen zu beiden Ebenen verstärkt dies noch weiter, hat jedoch die größte Auswirkung auf statische Klassen. Vergleich mit SOTA-Methoden
Die Forscher verglichen diese Methode mit einigen SOTA-Methoden.
Wie in Tabelle 1 unten gezeigt, ist die Leistung des räumlichen Modells besser als die der aktuellen komprimierten SOTA-Methode STA-S, mit einer durchschnittlichen relativen Verbesserung von 15 %. Bei den kleineren dynamischen Klassen ist die Verbesserung sogar noch deutlicher, da die Genauigkeit der Bus-, LKW-, Anhänger- und Hinderniserkennung um relative 35–45 % zunimmt. Die in Abbildung 2 unten erhaltenen qualitativen Ergebnisse stützen diese Schlussfolgerung ebenfalls. Das Modell in diesem Artikel zeigt eine größere strukturelle Ähnlichkeit und ein besseres Formgefühl. Dieser Unterschied kann teilweise auf die für die Komprimierung verwendeten vollständig verbundenen Schichten (FCL) zurückgeführt werden: Bei der Erkennung kleiner und entfernter Objekte ist ein Großteil des Bildes redundanter Kontext. Darüber hinaus werden Fußgänger und andere Objekte häufig teilweise von Fahrzeugen blockiert. In diesem Fall wird die vollständig verbundene Schicht dazu neigen, Fußgänger zu ignorieren und stattdessen die Semantik von Fahrzeugen beizubehalten. Hier zeigt die Aufmerksamkeitsmethode ihren Vorteil, da jede radiale Tiefe unabhängig vom Bild wahrgenommen werden kann – sodass tiefere Tiefen die Körper von Fußgängern sichtbar machen können, während frühere Tiefen nur Fahrzeuge wahrnehmen können. Die Ergebnisse des Argoverse-Datensatzes in Tabelle 3 unten zeigen ein ähnliches Muster, bei dem sich unsere Methode im Vergleich zu PON [8] um 30 % verbessert. Wie in Tabelle 4 unten gezeigt, ist die Leistung dieser Methode auf nuScenes und Lyft besser als bei LSS [9 ] und FIERY [20]. Ein echter Vergleich ist bei Lyft nicht möglich, da es keine kanonische Zug-/Val-Aufteilung gibt und es keine Möglichkeit gibt, die Aufteilung von LSS zu nutzen. Weitere Forschungsdetails finden Sie im Originalpapier. 



Das obige ist der detaillierte Inhalt vonICRA 2022 Outstanding Paper: Durch die Umwandlung von 2D-Bildern des autonomen Fahrens in eine Vogelperspektive erhöht sich die Modellerkennungsgenauigkeit um 15 %. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr