
Heim >Technologie-Peripheriegeräte >KI >Eine einfache Möglichkeit, große Datensätze für maschinelles Lernen in Python zu verarbeiten
Eine einfache Möglichkeit, große Datensätze für maschinelles Lernen in Python zu verarbeiten

- 王林nach vorne
- 2023-04-09 19:51:011843Durchsuche
Die Zielgruppe dieses Artikels:
- Menschen, die Pandas/NumPy-Operationen an großen Datensätzen durchführen möchten.
- Personen, die Python verwenden möchten, um maschinelle Lernaufgaben für Big Data auszuführen.

In diesem Artikel werden Dateien im CSV-Format verwendet, um verschiedene Vorgänge von Python sowie andere Formate wie Arrays und Textdateien zu demonstrieren , usw. .
Warum können wir Pandas nicht für große Datensätze für maschinelles Lernen verwenden?
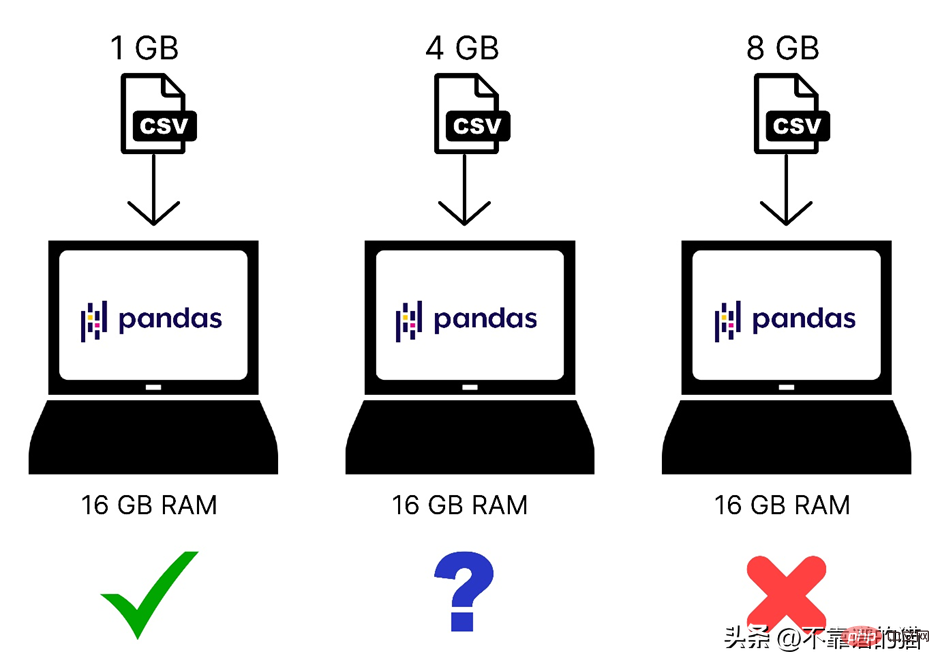
Wir wissen, dass Pandas Computerspeicher (RAM) verwendet, um Ihren Datensatz für maschinelles Lernen zu laden. Wenn Ihr Computer jedoch über 8 GB Speicher (RAM) verfügt, warum können Pandas dann immer noch nicht 2 GB davon laden? Was ist damit? der Datensatz? Der Grund dafür ist, dass das Laden einer 2-GB-Datei mit Pandas nicht nur 2 GB RAM, sondern auch mehr Speicher erfordert, da der Gesamtspeicherbedarf von der Größe des Datensatzes und den Vorgängen abhängt, die Sie an diesem Datensatz ausführen.
Hier ist ein schneller Vergleich unterschiedlich großer Datensätze, die in den Computerspeicher geladen werden:
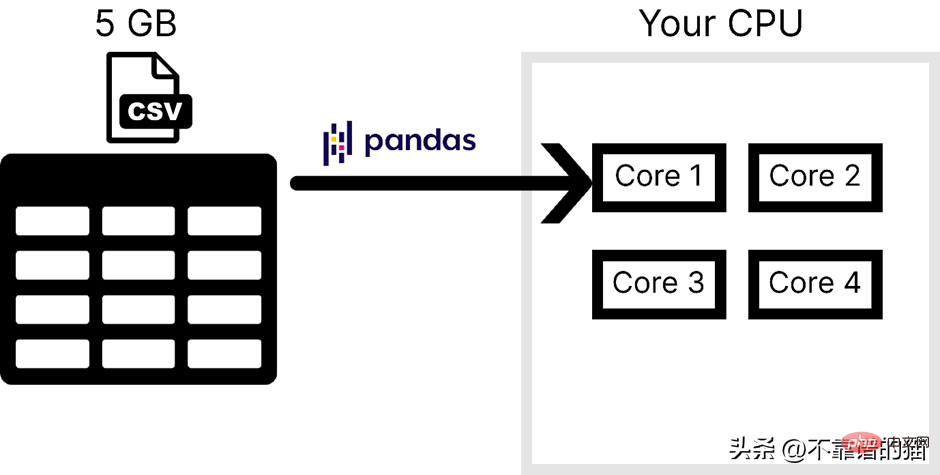
Darüber hinaus verwendet Pandas nur einen Kern des Betriebssystem, was die Verarbeitung verlangsamt. Mit anderen Worten können wir sagen, dass Pandas keine Parallelität (Aufteilung eines Problems in kleinere Aufgaben) unterstützt.
Unter der Annahme, dass der Computer über 4 Kerne verfügt, zeigt das folgende Bild die Anzahl der von Pandas beim Laden einer CSV-Datei verwendeten Kerne:
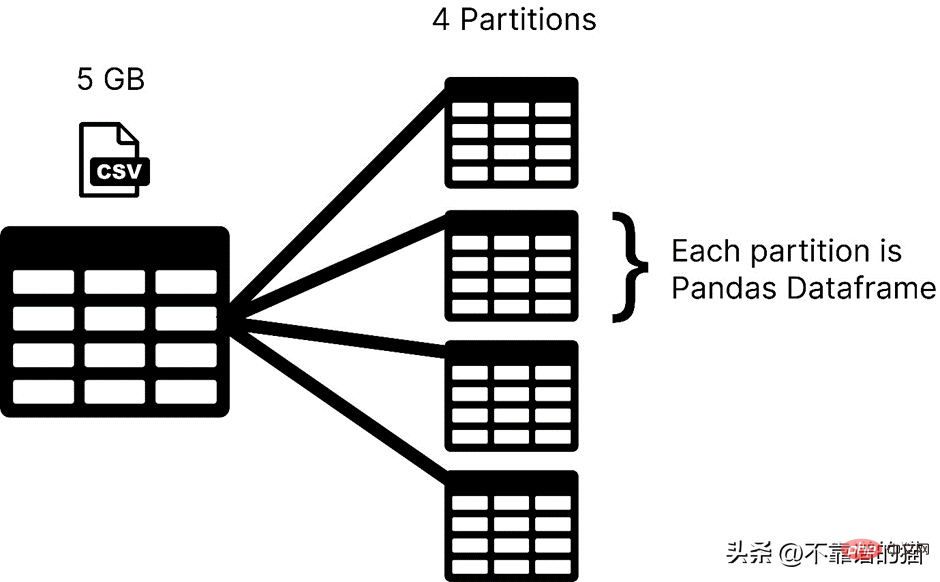
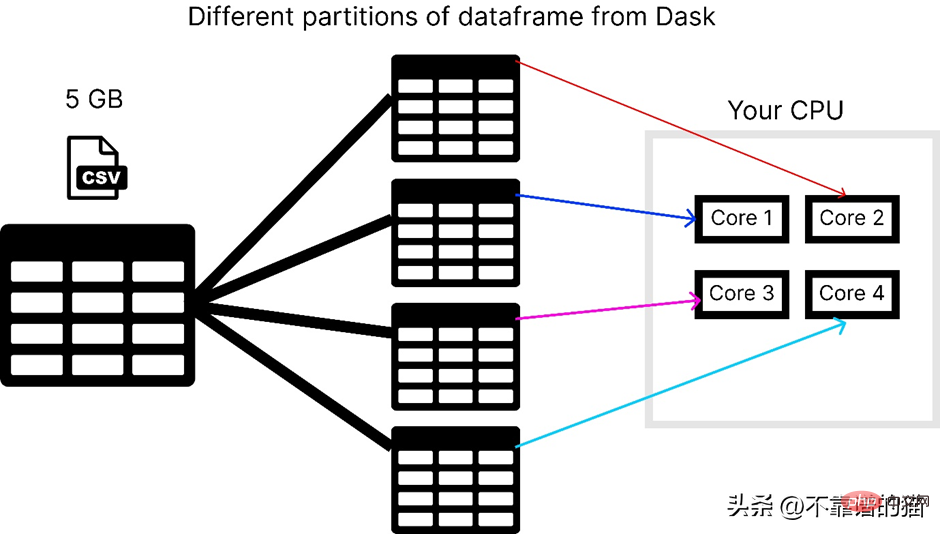
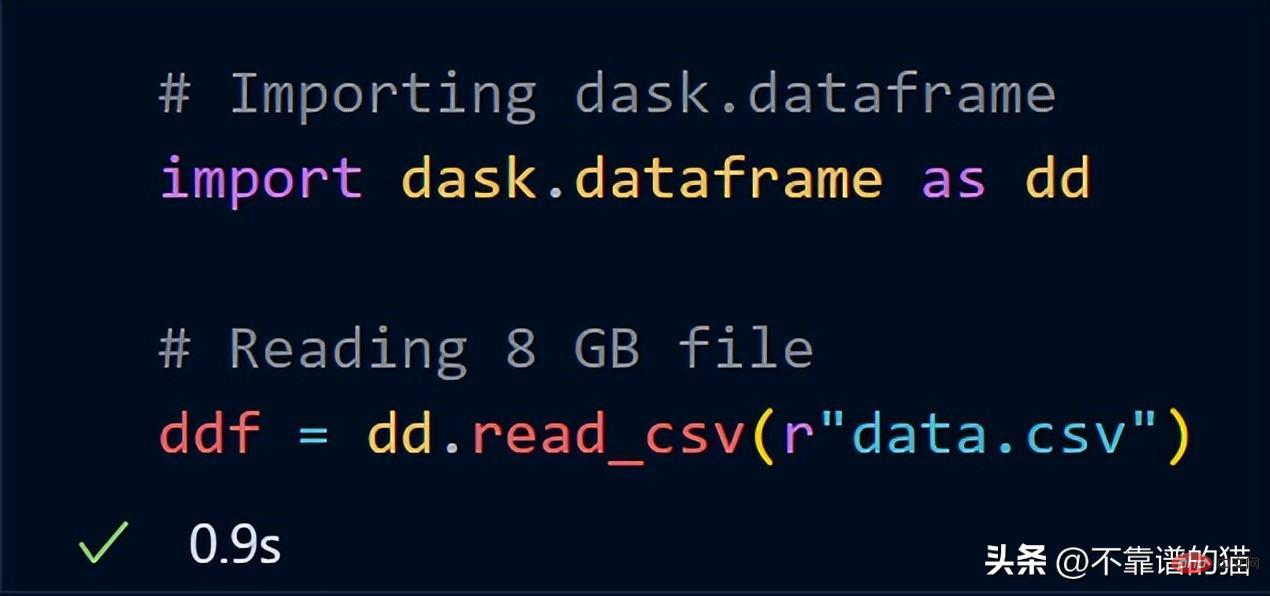
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>Dask verfügt über mehrere Module, wie zum Beispiel dask.array, dask.dataframe und dask.distributed, die nur installiert werden können, wenn Sie die entsprechenden installiert haben Bibliotheken (wie NumPy, Pandas und Tornado). Wie verwende ich Dask, um große CSV-Dateien zu verarbeiten? dask.dataframe wird zum Verarbeiten großer CSV-Dateien verwendet. Zuerst habe ich versucht, mit Pandas einen Datensatz mit einer Größe von 8 GB zu importieren.
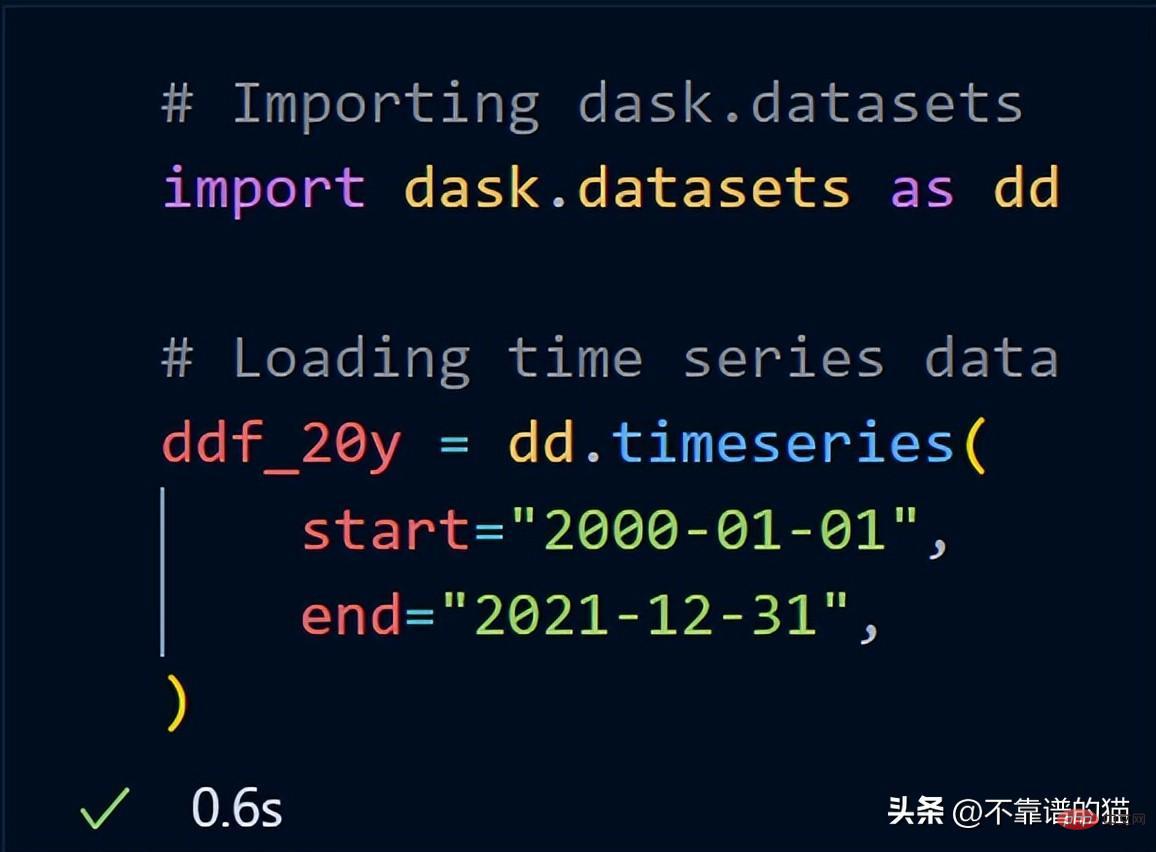
<span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">import</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pandas</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">as</span> <span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span><br><span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">df</span> <span style="color: rgb(215, 58, 73); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">=</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pd</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">read_csv</span>(<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">“data</span>.<span style="color: rgb(0, 92, 197); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">csv”</span>)Es hat einen Speicherzuordnungsfehler in meinem 16-GB-RAM-Laptop ausgelöst. Versuchen Sie nun, dieselben 8-GB-Daten mit dask.dataframe zu importieren Die GB-Datei wird in die ddf-Variable geladen. Sehen wir uns die Ausgabe der ddf-Variablen an.
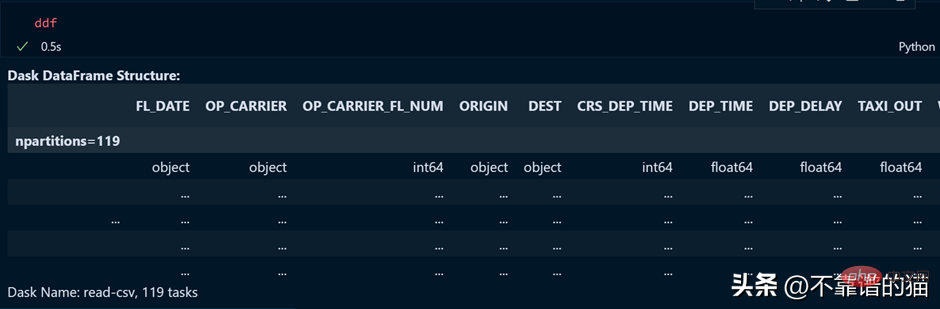
Ich kann beim Laden der CSV-Datei auch meine eigene Anzahl an Partitionen angeben, indem ich den Blocksize-Parameter verwende.
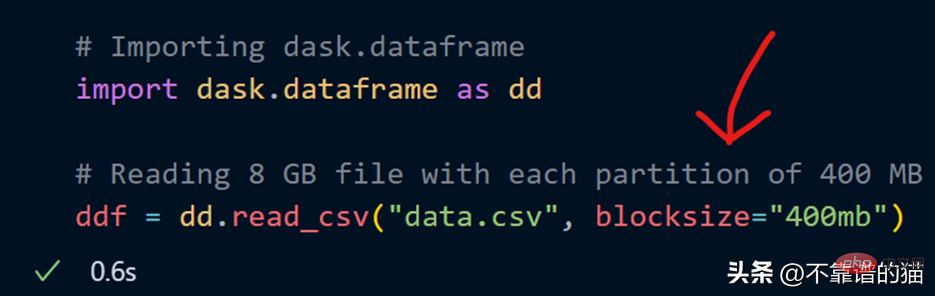
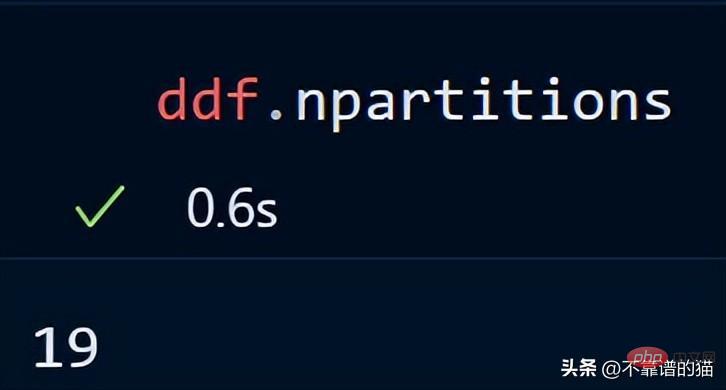
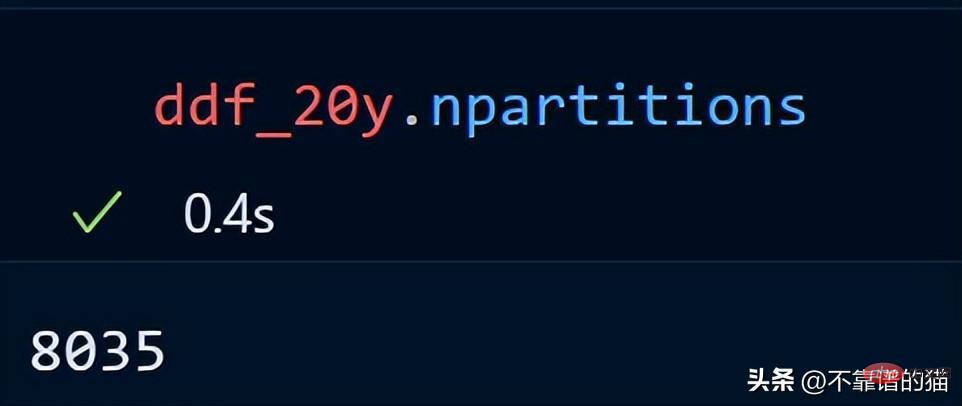
Jetzt wird ein Blocksize-Parameter mit einem String-Wert von 400 MB angegeben, wodurch jede Partition 400 MB groß ist. Schauen wir uns an, wie viele Partition #🎜 es gibt 🎜#
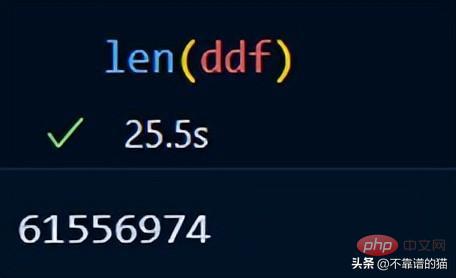
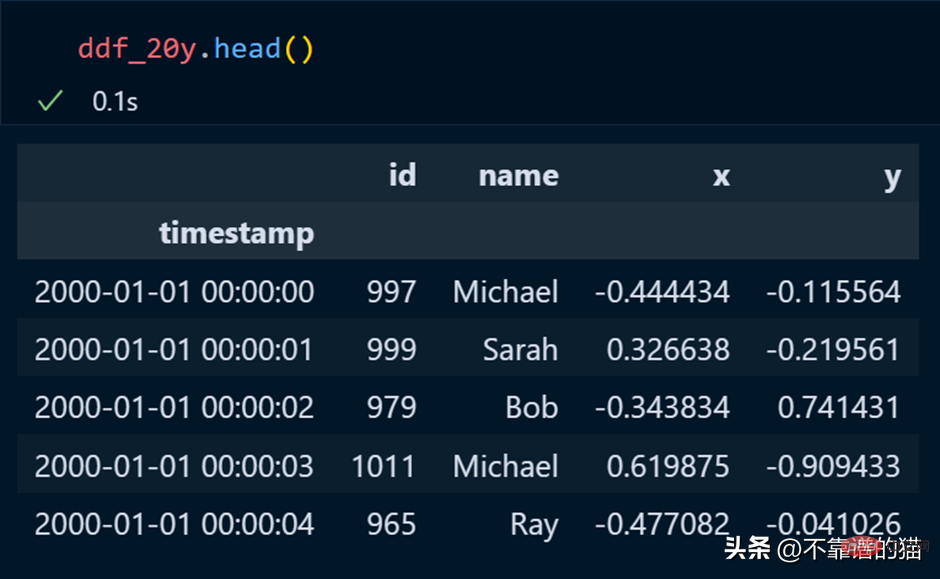
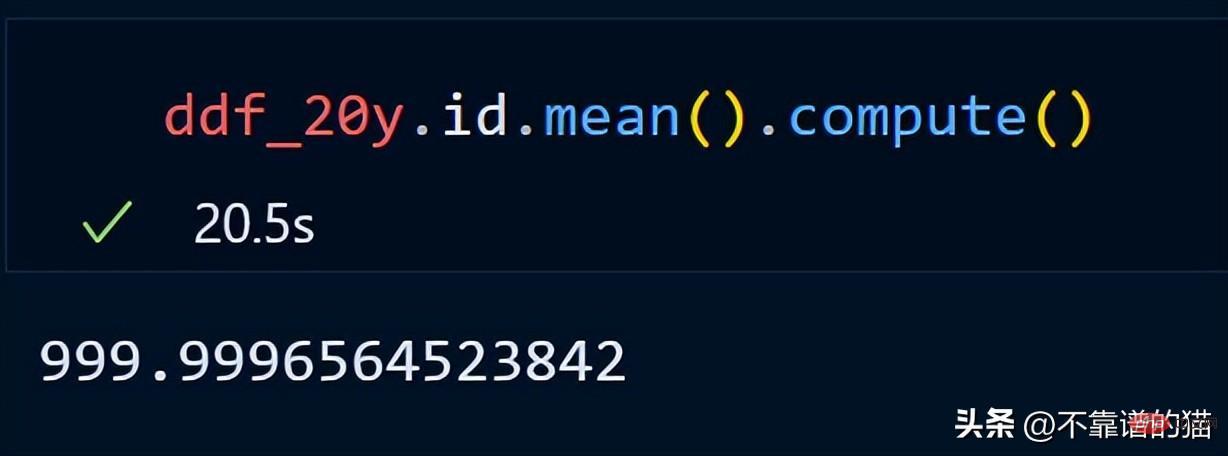
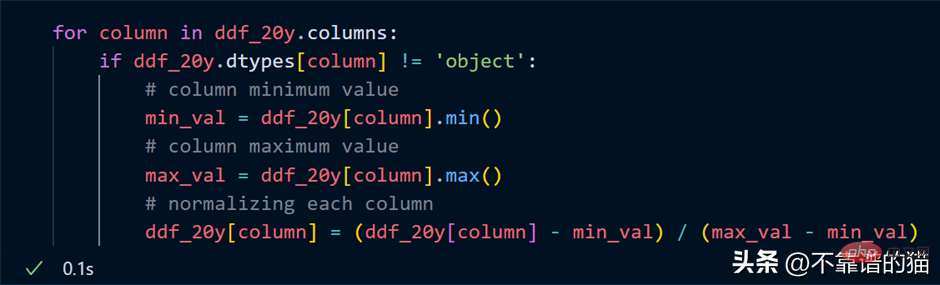 Durchlaufen Sie die Spalten, ermitteln Sie die Minimal- und Maximalwerte für jede Spalte und normalisieren Sie die Spalten mithilfe einer einfachen mathematischen Formel.
Durchlaufen Sie die Spalten, ermitteln Sie die Minimal- und Maximalwerte für jede Spalte und normalisieren Sie die Spalten mithilfe einer einfachen mathematischen Formel.
Kernpunkt: Denken Sie in unserem Normalisierungsbeispiel nicht, dass eine tatsächliche numerische Berechnung stattfindet, es handelt sich lediglich um eine verzögerte Auswertung (die Ausgabe wird Ihnen erst angezeigt, wenn sie benötigt wird).
Warum Dask-Array verwenden?
Dask teilt ein Array in kleine Blöcke auf, wobei jeder Block ein NumPy-Array ist.
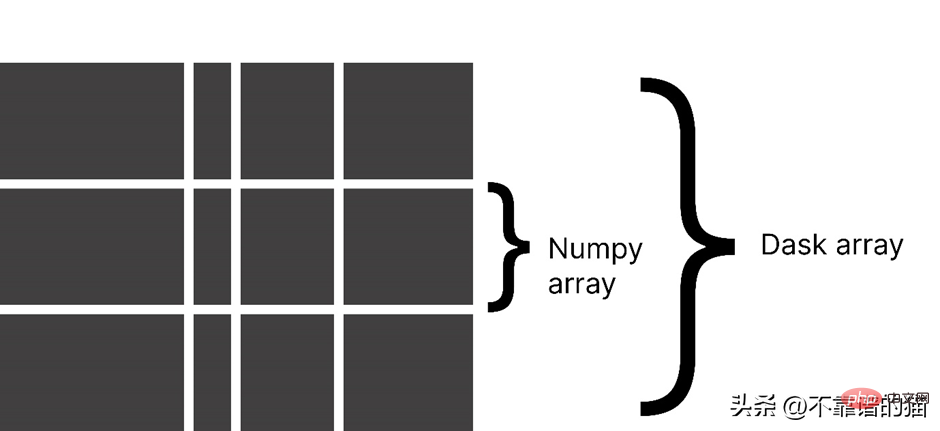 dask.arrays wird verwendet, um große Arrays zu verarbeiten. Der folgende Python-Code verwendet dask, um ein Array von 10000 x 10000 zu erstellen und es im x zu speichern variabel.
dask.arrays wird verwendet, um große Arrays zu verarbeiten. Der folgende Python-Code verwendet dask, um ein Array von 10000 x 10000 zu erstellen und es im x zu speichern variabel.
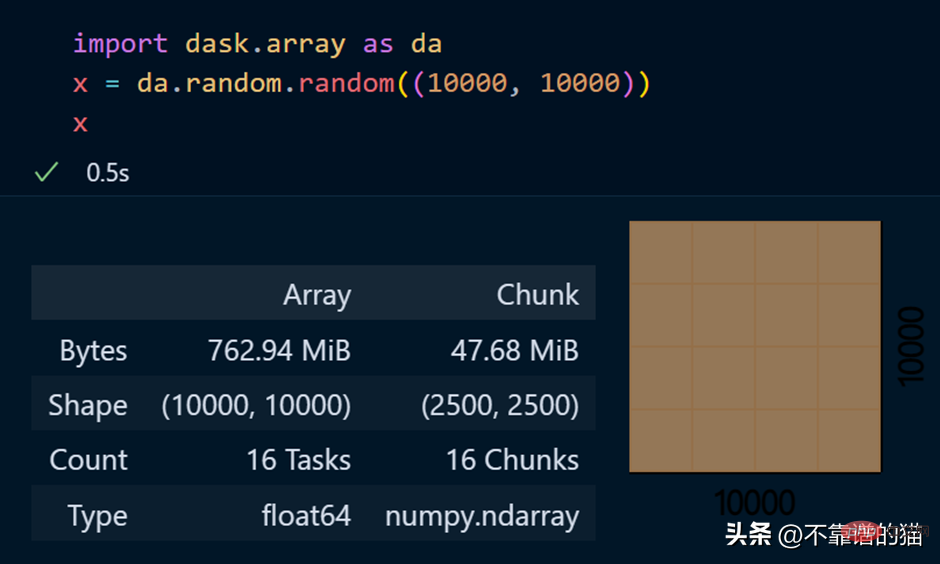 Der Aufruf der x-Variablen erzeugt verschiedene Informationen über das Array.
Der Aufruf der x-Variablen erzeugt verschiedene Informationen über das Array.
Spezifische Elemente eines Arrays anzeigen
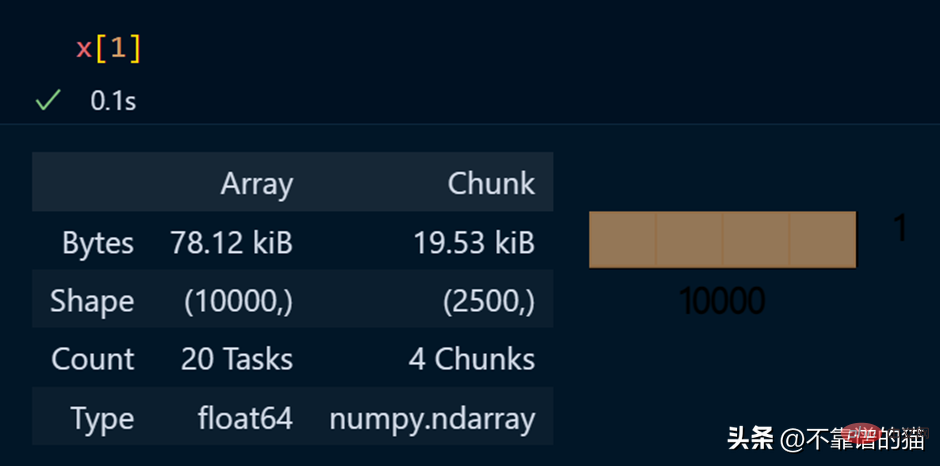 Python-Beispiel für die Ausführung mathematischer Operationen an einem Dask-Array:
Python-Beispiel für die Ausführung mathematischer Operationen an einem Dask-Array:
正如您所看到的,由于延迟执行,它不会向您显示输出。我们可以使用compute来显示输出:
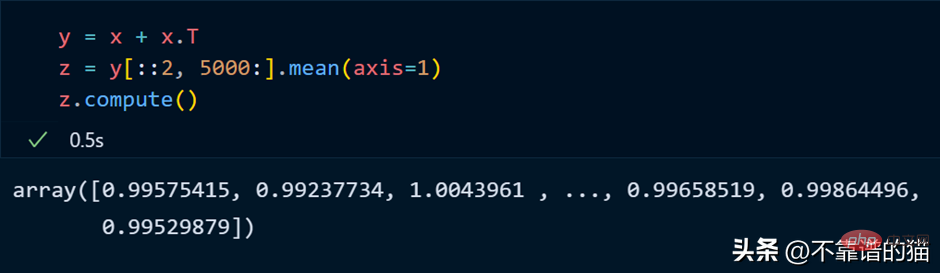
dask 数组支持大多数 NumPy 接口,如下所示:
- 数学运算:+, *, exp, log, ...
- sum(), mean(), std(), sum(axis=0), ...
- 张量/点积/矩阵乘法:tensordot
- 重新排序/转置:transpose
- 切片:x[:100, 500:100:-2]
- 使用列表或 NumPy 数组进行索引:x[:, [10, 1, 5]]
- 线性代数:svd、qr、solve、solve_triangular、lstsq
但是,Dask Array 并没有实现完整 NumPy 接口。
你可以从他们的官方文档中了解更多关于 dask.arrays 的信息。
什么是Dask Persist?
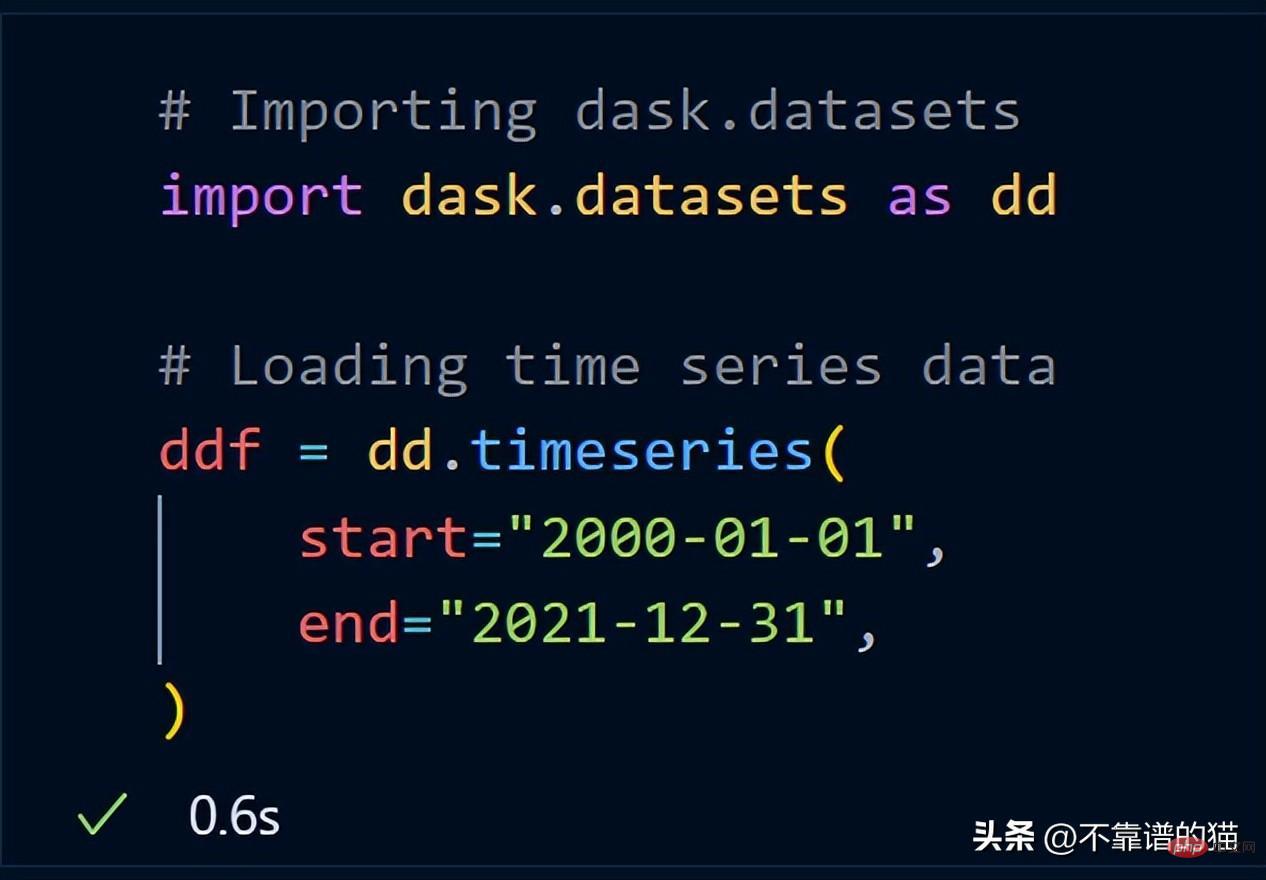
假设您想对机器学习数据集执行一些耗时的操作,您可以将数据集持久化到内存中,从而使数学运算运行得更快。
从 dask.datasets 导入了时间序列数据
让我们取数据集的一个子集并计算该子集的总行数。
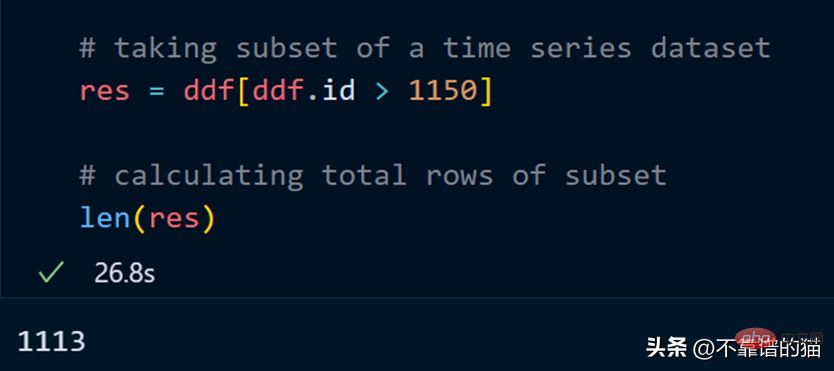
计算总行数需要 27 秒。
我们现在使用 persist 方法:
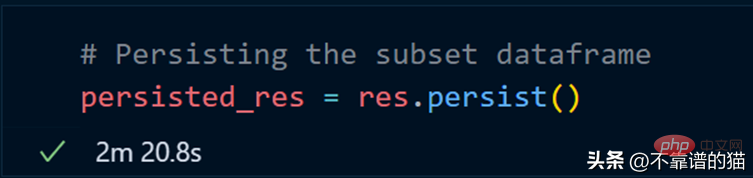
持久化我们的子集总共花了 2 分钟,现在让我们计算总行数。
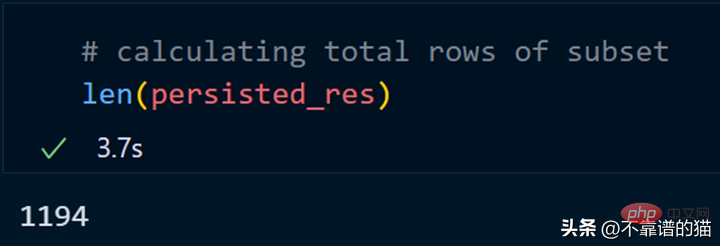
同样,我们可以对持久化数据集执行其他操作以减少计算时间。
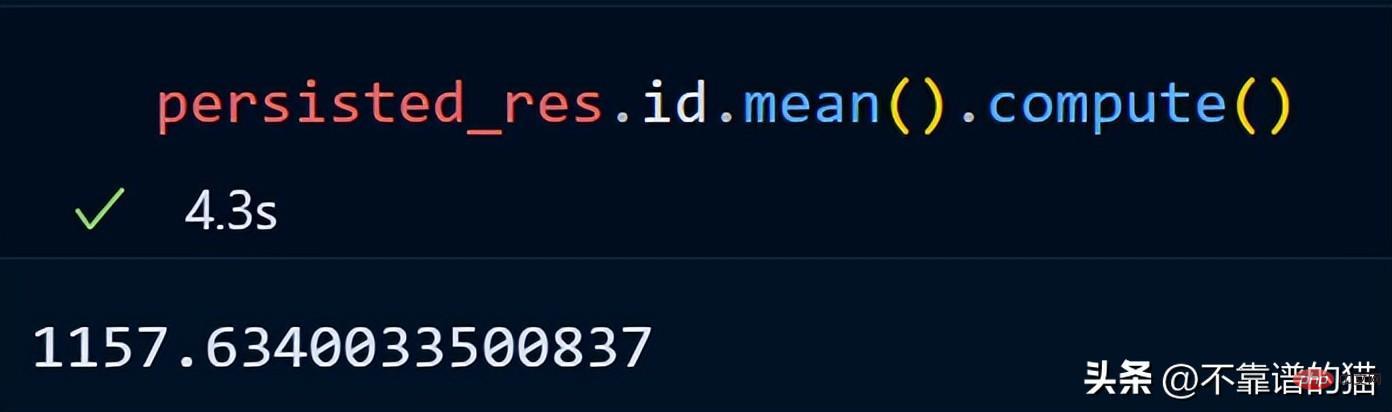
persist应用场景:
- 数据量大
- 获取数据的一个子集
- 对子集应用不同的操作
为什么选择 Dask ML?
Dask ML有助于在大型数据集上使用流行的Python机器学习库(如Scikit learn等)来应用ML(机器学习)算法。
什么时候应该使用 dask ML?
- 数据不大(或适合 RAM),但训练的机器学习模型需要大量超参数,并且调优或集成技术需要大量时间。
- 数据量很大。
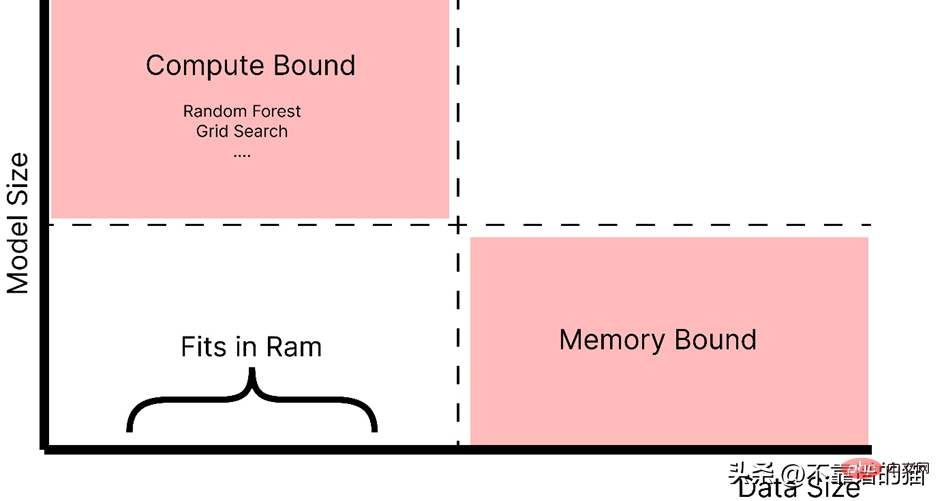
正如你所看到的,随着模型大小的增加,例如,制作一个具有大量超参数的复杂模型,它会引起计算边界的问题,而如果数据大小增加,它会引起内存分配错误。因此,在这两种情况下(红色阴影区域)我们都使用 Dask 来解决这些问题。
如官方文档中所述,dask ml 库用例:
- 对于内存问题,只需使用 scikit-learn(或其他ML 库)。
- 对于大型模型,使用 dask_ml.joblib 和scikit-learn estimators。
- 对于大型数据集,使用 dask_ml estimators。
让我们看一下 Dask.distributed 的架构:
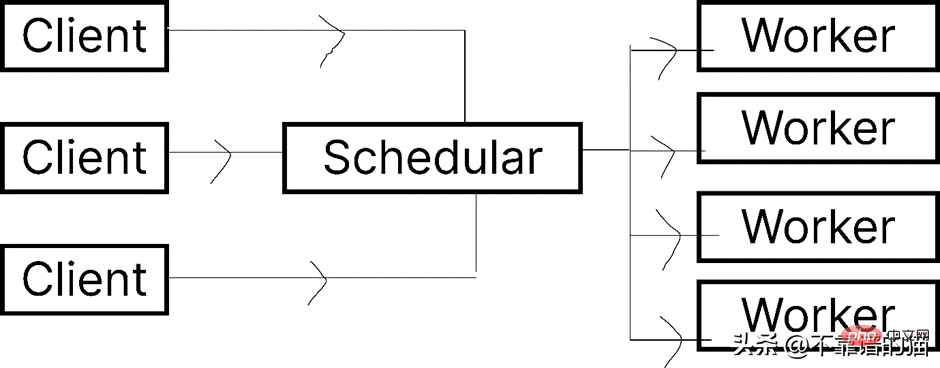
Dask 让您能够在计算机集群上运行任务。在 dask.distributed 中,只要您分配任务,它就会立即开始执行。
简单地说,client就是提交任务的你,执行任务的是Worker,调度器则执行两者之间通信。
python -m <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span> distributed –upgrade
如果您使用的是单台机器,那么就可以通过以下方式创建一个具有4个worker的dask集群
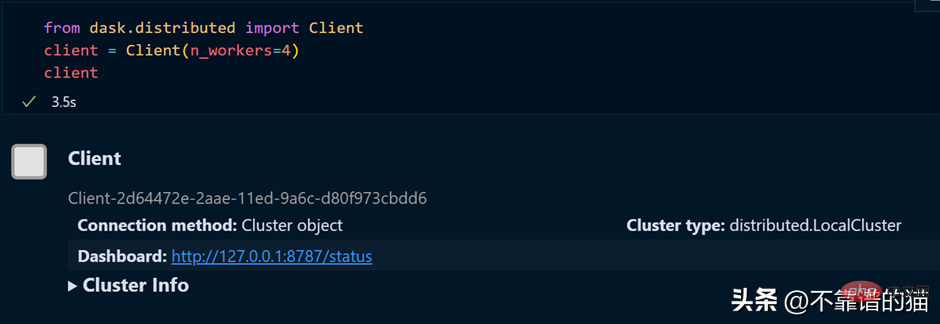
如果需要dashboard,可以安装bokeh,安装bokeh的命令如下:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">bokeh</span>
就像我们从 dask.distributed 创建客户端一样,我们也可以从 dask.distributed 创建调度程序。
要使用 dask ML 库,您必须使用以下命令安装它:
<span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">pip</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">install</span> <span style="color: rgb(89, 89, 89); margin: 0px; padding: 0px; background: none 0% 0% / auto repeat scroll padding-box border-box rgba(0, 0, 0, 0);">dask</span>-ml
我们将使用 Scikit-learn 库来演示 dask-ml 。
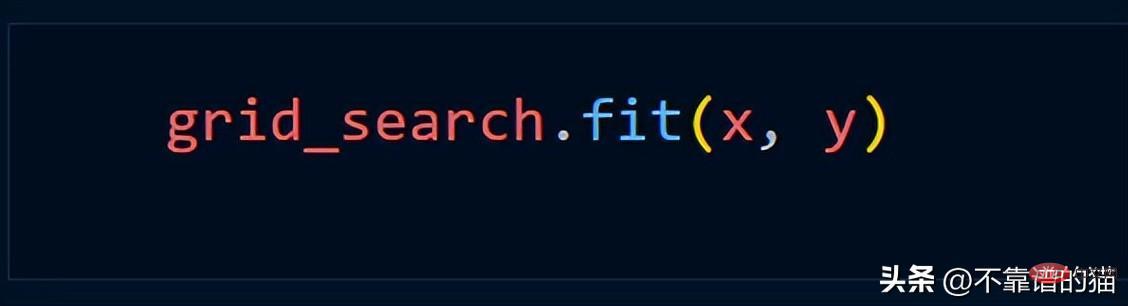
Angenommen, wir verwenden die Grid_Search-Methode, verwenden wir normalerweise den folgenden Python-Code
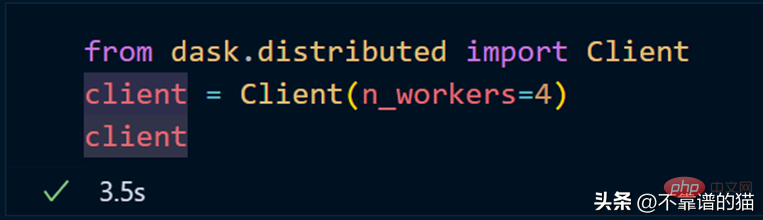
Erstellen Sie einen Cluster mit dask.distributed:
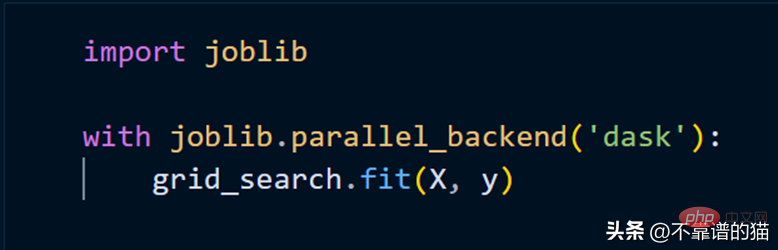
Um das Scikit-Learn-Modell mithilfe von Clustern anzupassen, müssen wir lediglich joblib verwenden.
Das obige ist der detaillierte Inhalt vonEine einfache Möglichkeit, große Datensätze für maschinelles Lernen in Python zu verarbeiten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr