
Heim >Technologie-Peripheriegeräte >KI >Entscheidungspositionierungsanwendung basierend auf einem Kausalwaldalgorithmus
Entscheidungspositionierungsanwendung basierend auf einem Kausalwaldalgorithmus

- WBOYnach vorne
- 2023-04-08 11:21:101910Durchsuche
Übersetzer | Zhu Xianzhong
Rezensent | Ursache-Wirkungs-Baum zu Bewerten Sie die heterogenen
Behandlungseffekteder Richtlinie. Wenn Sie es noch nicht gelesengelesen haben, empfehle ich Ihnen, es zu lesen bevor Sie diesen Artikel lesen, denn wir in diesem Artikeldenkendass Sie s bereits verstehen Einige Inhalte zu diesem Artikel. Warum gibt es heterogene Behandlungseffekte (HTE: heterogene Behandlungseffekte) ? Erstens ermöglicht uns die Schätzung heterogener Behandlungseffekte
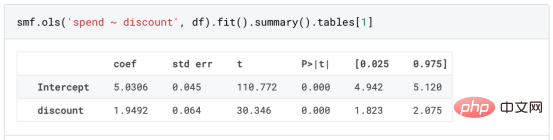
die Auswahl derBehandlungseffekte (Medikamente, Anzeigen, Produkte usw.) für Benutzer (Patienten, Benutzer, Kunden usw.). Mit anderen Worten: Es wird geschätzt, dass HTE uns beim Targeting hilft . Tatsächlich kann ein Behandlungsansatz , wie wir später in diesem Artikel sehen werden , einem Teil der Anwender zwar positive Vorteile bringen, aber im Durchschnitt unwirksam oder sogar kontraproduktiv sein. Das Gegenteil könnte auch der Fall sein: ein Medikament ist im Durchschnitt wirksam, ist aber , wenn wir klare Informationen über die Anwender haben, es Nebenwirkungen hat , die Wirksamkeit dieses Medikaments wird weiter verbessert werden. In diesem Artikel werden wir eine Erweiterung des Kausalbaums untersuchen – den Kausalwald. So wie zufällige Wälder Regressionsbäume erweitern, indem sie mehrere Bootstrap-Bäume zusammen mitteln, erweitern kausale Wälder auch kausale Bäume. Der Hauptunterschied ergibt sich aus der Argumentationsperspektive, die weniger einfach ist. Wir werden auch sehen, wie die Ergebnisse verschiedener HTE-Schätzalgorithmen verglichen und für politische Ziele verwendet werden können. Online-RabattkofferFür den Rest dieses Artikels verwenden wir weiterhin
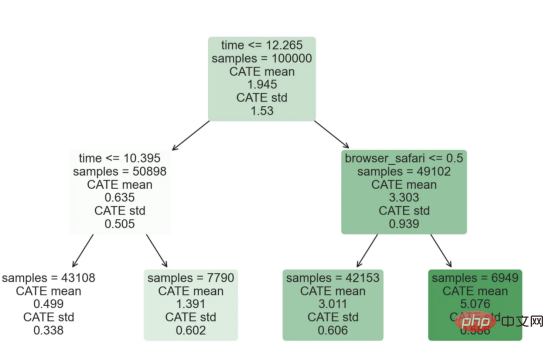
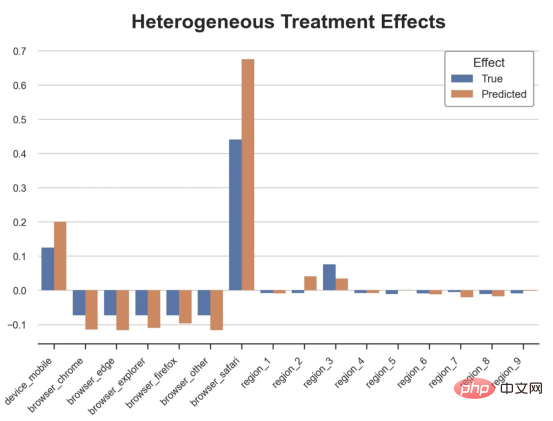
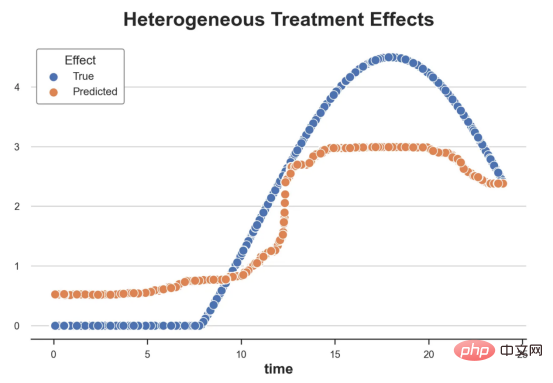
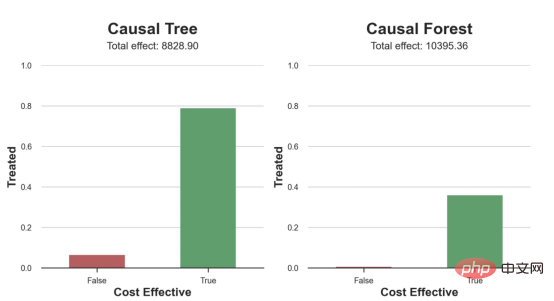
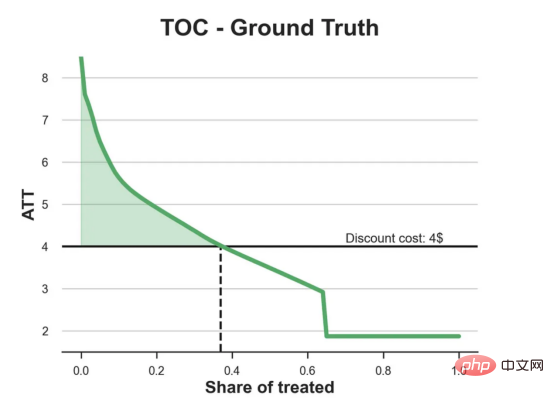
das Spielzeugbeispiel aus meinem letzten Artikel überUrsache- und Wirkungsbäume: Nehmen wir an, wir sind ein Online-Shop und Uns interessiert, ob das Anbieten von Rabatten für Neukunden ihre Ausgaben im Geschäft erhöht. Um herauszufinden, ob der Rabatt ein gutes Angebot ist, haben wir das folgende Zufallsexperiment oder A/B-Test durchgeführt: Jedes Mal, wenn ein neuer Kunde unseren Online-Shop durchstöbert, ordnen wir ihm nach dem Zufallsprinzip eine Behandlung Bedingung zu. Wir bieten Rabatte für Benutzer an, die der Verarbeitung unterliegen , wir bieten keine Rabatte für Kontrollbenutzer an. Ich importiere den Datengenerierungsprozess dgp_online_discounts() aus der Datei src.dgp. Ich importiere auch einige Zeichenfunktionen und Bibliotheken aus src.utilslibrary. Um nicht nur Code, sondern auch Daten und Tabellen und andere Inhalte einzubinden, habe ich das Deepnote -Framework verwendet, eine Jupyter-ähnliche kollaborative Notizbuchumgebung, die auf Web basiert. Wir verfügen über Daten von 100.000 Online-Cstore-Besuchern und beobachten die Zeit, die sie auf der Website besuchen, das von ihnen verwendete Gerät, den von ihnen verwendeten Browser und ihre geografische Region. Wir schauen uns auch an, ob sie einen Rabatt bekommen haben, wie wir damit umgegangen sind, wie viel sie ausgegeben haben, und einige andere interessante Ergebnisse. Da das Experiment zufällig zugewiesen wird, können wir eine einfache mittlere Differenzschätzung verwenden, um den Experiment-Effekt abzuschätzen. Wir gehen davon aus, dass die experimentelle Der Rabatt sieht aus und er scheint zu funktionieren: Die durchschnittlichen Ausgaben der Experiment-Gruppe stiegen um 1,95 $. Aber sind alle Kunden gleichermaßen betroffen? Um diese Frage zu beantworten, möchten wir heterogene Behandlungseffekte Effekte abschätzen, ggf. auf individueller Ebene. Kausalwald Es gibt viele verschiedene Möglichkeiten, heterogene Verarbeitungseffekte zu berechnen. Der einfachste Ansatz besteht darin, mit dem interessierenden Ergebnis im Hinblick auf Heterogenitätsdimensionen zu interagieren. Das Problem bei diesem Ansatz besteht darin, welche Variable ausgewählt werden soll. Manchmal verfügen wir über Informationen, die unser Handeln im Voraus leiten können Im vorherigen Artikel haben wir einen datengesteuerten Ansatz zur Schätzung von heterogenen Behandlungseffekten – Kausalbäumen – untersucht. Wir werden sie nun auf Kausalwälder erweitern. Bevor wir jedoch beginnen, müssen wir seinen nicht-kausalen Cousin vorstellen, den Random Forest. Random Forest ist, wie der Name schon sagt, eine Erweiterung des Regressionsbaums und fügt ihm zwei unabhängige Zufallsquellen hinzu. Insbesondere ist der Random-Forest-Algorithmus in der Lage , Vorhersagen über viele verschiedene Regressionsbäume zu treffen, die jeweils auf Bootstrap-Stichproben der Daten trainiert sind, und diese gemeinsam zu mitteln. Dieser Prozess wird oft als geführter Aggregationsalgorithmus oder auch als Bagging-Algorithmus bezeichnet. Er kann auf jeden Vorhersagealgorithmus angewendet werden und ist nicht spezifisch für zufällige Gesamtstrukturen. Eine zusätzliche Zufälligkeitsquelle ergibt sich aus der Merkmalsauswahl, da bei jeder Aufteilung nur eine zufällige Teilmenge aller Merkmale X für die optimale Aufteilung berücksichtigt wird. Diese beiden zusätzlichen Zufallsquellen sind sehr wichtig und tragen dazu bei, die Leistung von Zufallswäldern zu verbessern. Erstens ermöglicht der Bagging-Algorithmus, dass zufällige Wälder durch die Mittelung mehrerer diskreter Vorhersagen glattere Vorhersagen als Regressionsbäume erzeugen. Im Gegensatz dazu ermöglicht die zufällige Merkmalsauswahl zufälligen Wäldern, den Merkmalsraum tiefer zu erkunden, sodass sie mehr Interaktionen entdecken können als einfache Regressionsbäume. Tatsächlich kann es Wechselwirkungen zwischen Variablen geben, die für sich genommen nicht sehr prädiktiv (und daher nicht spaltend) sind, aber zusammen sehr wirkungsvoll sind. Kausalwälder entsprechen Zufallswäldern, werden jedoch genau wie Kausalbäume und Regressionsbäume zur Schätzung von heterogenen Behandlungseffekten verwendet. Wie bei Kausalbäumen haben wir ein Grundproblem: Wir sind daran interessiert, ein Objekt vorherzusagen, das wir nicht beobachtet haben: die individuelle Behandlung Wirkung τᵢ. Die Lösung besteht darin, eine Hilfsergebnisvariable Y* zu erstellen, deren erwarteter Wert für jede Beobachtung genau dem Behandlungseffekt entspricht. Hilfsergebnisvariable Wenn Sie mehr darüber erfahren möchten, warum diese Variable keinen Einfluss auf die individuelle Behandlung hat s fügt Voreingenommenheit hinzu, wenn Sie Wenn du es einstellen möchtest , schau dir bitte meinen vorherigen Artikel an, ich habe ausführlich in diesem Artikel vorgestellt. Kurz gesagt, Sie können sich Yᵢ* als Mittelwertdifferenzschätzer für eine einzelne Beobachtung vorstellen. heterogene Behandlungseffekte abzuschätzen. Zuerst müssen wir den Baum mit der gleichen Anzahl an Verarbeitungseinheiten und Steuereinheiten auf jedem Blatt aufbauen. Zweitens müssen wir verschiedene Stichproben verwenden, um den Baum zu erstellen und auszuwerten, d. h. das durchschnittliche Ergebnis für jedes Blatt zu berechnen. Dieser Prozess wird oft als ehrlicher Baum bezeichnet, da wir die Proben jedes Blattes unabhängig von der Baumstruktur behandeln können und daher für Schlussfolgerungen sehr nützlich sind. und Region. heterogene Behandlungseffekte abzuschätzen. Glücklicherweise müssen wir das alles nicht manuell erledigen, denn bietet bereits eine schöne Implementierung von Kausalbäumen und Wäldern in Microsofts EconML-Paket . Wir werden die CausalForestML-Funktion von verwenden. 与因果树不同,因果森林更难解释,因为我们无法可视化每一棵树。我们可以使用SingleTreeateInterpreter函数来绘制因果森林算法的等效表示。 因果森林模型表示 我们可以像因果树模型一样解释树形图。在顶部,我们可以看到数据中的平均$Y^*$的值为1.917$。从那里开始,根据每个节点顶部突出显示的规则,数据被拆分为不同的分支。例如,根据时间是否晚于11.295,第一节点将数据分成大小为46878$和53122$的两组。在底部,我们得到了带有预测值的最终分区。例如,最左边的叶子包含40191$的观察值(时间早于11.295,在非Safari浏览器环境下),我们预测其花费为0.264$。较深的节点颜色表示预测值较高。 这种表示的问题在于,与因果树的情况不同,它只是对模型的解释。由于因果森林是由许多自助树组成的,因此无法直接检查每个决策树。了解在确定树分割时哪个特征最重要的一种方法是所谓的特征重要性。 显然,时间是异质性的第一个维度,其次是设备(特别是移动设备)和浏览器(特别是Safari)。其他维度无关紧要。 现在,让我们检查一下模型性能如何。 通常,我们无法直接评估模型性能,因为与标准的机器学习设置不同,我们没有观察到实际情况。因此,我们不能使用测试集来计算模型精度的度量。然而,在我们的案例中,我们控制了数据生成过程,因此我们可以获得基本的真相。让我们从分析模型如何沿着数据、设备、浏览器和区域的分类维度估计异质处理效应开始。 对于每个分类变量,我们绘制了实际和估计的平均处理效果。 作者提供的每个分类值的真实和估计处理效果 因果森林算法非常善于预测与分类变量相关的处理效果。至于因果树,这是预期的,因为算法具有非常离散的性质。然而,与因果树不同的是,预测更加微妙。 我们现在可以做一个更相关的测试:算法在时间等连续变量下的表现如何?首先,让我们再次隔离预测的处理效果,并忽略其他协变量。 def compute_time_effect(df, hte_model, avg_effect_notime): 我们现在可以复制之前的数字,但时间维度除外。我们绘制了一天中每个时间的平均真实和估计处理效果。 沿时间维度绘制的真实和估计的处理效果 我们现在可以充分理解因果树和森林之间的区别:虽然在因果树的情况下,估计基本上是一个非常粗略的阶跃函数,但我们现在可以看到因果树如何产生更平滑的估计。 我们现在已经探索了该模型,是时候使用它了! 假设我们正在考虑向访问我们在线商店的新客户提供4美元的折扣。 折扣对哪些客户有效?我们估计平均处理效果为1.9492美元。这意味着,平均而言折扣并不真正有利可图。然而,现在可以针对单个客户,我们只能向一部分新客户提供折扣。我们现在将探讨如何进行政策目标定位,为了更好地了解目标定位的质量,我们将使用因果树模型作为参考点。 我们使用相同的CauselForestML函数构建因果树,但将估计数和森林大小限制为1。 接下来,我们将数据集分成一个训练集和一个测试集。这一想法与交叉验证非常相似:我们使用训练集来训练模型——在我们的案例中是异质处理效应的估计器——并使用测试集来评估其质量。主要区别在于,我们没有观察到测试数据集中的真实结果。但是我们仍然可以使用训练测试分割来比较样本内预测和样本外预测。 我们将所有观察结果的80%放在训练集中,20%放在测试集中。 首先,让我们仅在训练样本上重新训练模型。 现在,我们可以确定目标策略,即决定我们向哪些客户提供折扣。答案似乎很简单:我们向所有预期处理效果大于成本(4美元)的客户提供折扣。 借助于一个可视化工具,它可以让我们了解处理对谁有效以及如何有效,这就是所谓的处理操作特征(TOC)曲线。这个名字可以看作是基于另一个更著名的接收器操作特性(ROC)曲线的修正,该曲线描绘了二元分类器的不同阈值的真阳性率与假阳性率。这两种曲线的想法类似:我们绘制不同比例受处理人群的平均处理效果。在一个极端情况下,当所有客户都被处理时,曲线的值等于平均处理效果;而在另一个极端情况下,当只有一个客户被处理时曲线的值则等于最大处理效果。 现在让我们计算曲线。 现在,我们可以绘制两个CATE估算器的处理操作特征(TOC)曲线。 处理操作特性曲线 正如预期的那样,两种估算器的TOC曲线都在下降,因为平均效应随着我们处理客户份额的增加而降低。换言之,我们在发布折扣时越有选择,每个客户的优惠券效果就越高。我还画了一条带有折扣成本的水平线,以便我们可以将TOC曲线下方和成本线上方的阴影区域解释为预期利润。 这两种算法预测的处理份额相似,约为20%,因果森林算法针对的客户略多一些。然而,他们预测的利润结果却大相径庭。因果树算法预测的边际较小且恒定,而因果林算法预测的是更大且更陡的边际。那么,哪一种算法更准确呢? 为了比较它们,我们可以在测试集中对它们进行评估。我们采用训练集上训练的模型,预测处理效果,并将其与测试集上训练模型的预测进行比较。注意,与机器学习标准测试程序不同,有一个实质性的区别:在我们的案例中,我们无法根据实际情况评估我们的预测,因为没有观察到处理效果。我们只能将两个预测相互比较。 因果树模型似乎比因果森林模型表现得更好一些,总净效应为8386美元——相对于4948美元。从图中,我们也可以了解差异的来源。因果森林算法往往限制性更强,处理的客户更少,没有误报的阳性,但也有很多误报的阴性。另一方面,因果树算法看起来更加“慷慨”,并将折扣分配给更多的新客户。这既转化为更多的真阳性,也转化为假阳性。总之,净效应似乎有利于因果树算法。 通常,我们讨论到这里就可以停止了,因为我们可以做的事情不多了。然而,在我们的案例情形中,我们还可以访问真正的数据生成过程。因此,接下来我们不妨检查一下这两种算法的真实精度。 首先,让我们根据处理效果的预测误差来比较它们。对于每个算法,我们计算处理效果的均方误差。 结果是,随机森林模型更好地预测了平均处理效果,均方误差为0.5555美元,而不是0.9035美元。 那么,这是否意味着更好的目标定位呢?我们现在可以复制上面所做的相同的柱状图,以了解这两种算法在策略目标方面的表现。 这两幅图非常相似,但结果却大相径庭。事实上,因果森林算法现在优于因果树算法,总效果为10395美元,而非8828美元。为什么会出现这种突然的差异呢? 为了更好地理解差异的来源,让我们根据实际情况绘制TOC。 处理操作特性曲线。 正如我们所看到的,TOC是倾斜度非常大的,存在一些平均处理效果非常高的客户。随机森林算法能够更好地识别它们,因此总体上更有效,尽管目标客户较少些。 In diesem Artikel lernten eine Funktionsehr leistungsfähige Schätzung von heterogenen Verarbeitungseffekten‘s kausaler Wald. Kausalwälder basieren auf den gleichen Prinzipien wie Kausalbäume, profitieren jedoch von einer tiefergehenden Erforschung des Parameterraums und der Bagging-Algorithmen . Darüber hinaus verstehen wir auch, wie Schätzungen von heterogenen Behandlungseffekten zur Umsetzung der politischen Positionierung eingesetzt werden können. Indem wir Benutzer mit der höchsten Behandlungswirksamkeit identifizieren, können wir sicherstellen, dass eine Police profitabel ist. Wir sehen auch Unterschiede zwischen den politischen Zielen und den Bewertungszielen für heterogene Behandlungseffekte, da die Enden der Verteilung möglicherweise stärkere Korrelationen als der Mittelwert aufweisen. ReferenzenS Annals of Statistics. Rem. OPRESCU, v. Syritkanis, Z. Wu, Tagungsband der 36. Internationalen Konferenz für maschinelles Lernen. 51CTO-Expertenblogger, Dozent, Computerlehrer an einer Universität in Weifang und ein Veteran in der freiberuflichen Programmierbranche. Titel von Original: From Causal Trees to Forests , Autor: Matteo Courthoud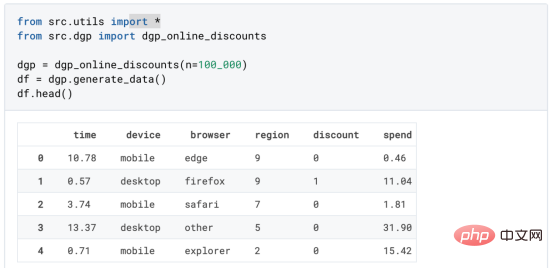
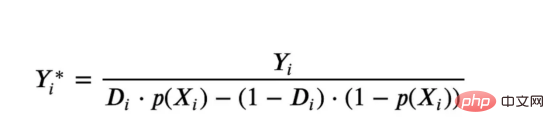
df_dummies = pd.get_dummies(df[dgp.X[1:]], drop_first=True)
df = pd.concat([df, df_dummies], axis=1)
X = ['time'] + list(df_dummies.columns)
from econml.dml import CausalForestDML
np.random.seed(0)
forest_model = CausalForestDML(max_depth=3)
forest_model = forest_model.fit(Y=df[dgp.Y], X=df[X], T=df[dgp.D])
from econml.cate_interpreter import SingleTreeCateInterpreter
intrp = SingleTreeCateInterpreter(max_depth=2).interpret(forest_model, df[X])
intrp.plot(feature_names=X, fnotallow=12)

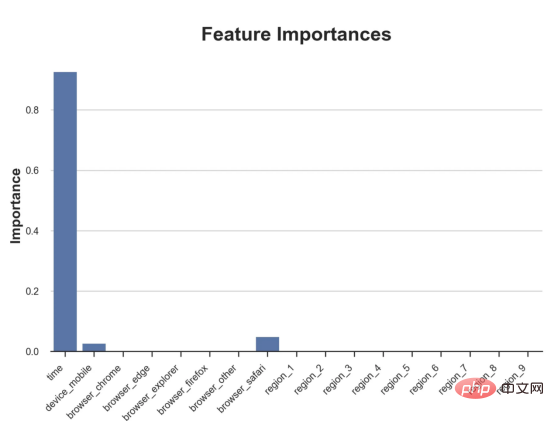
性能
def compute_discrete_effects(df, hte_model):
temp_df = df.copy()
temp_df.time = 0
temp_df = dgp.add_treatment_effect(temp_df)
temp_df = temp_df.rename(columns={'effect_on_spend': 'True'})
temp_df['Predicted'] = hte_model.effect(temp_df[X])
df_effects = pd.DataFrame()
for var in X[1:]:
for effect in ['True', 'Predicted']:
v = temp_df.loc[temp_df[var]==1, effect].mean() - temp_df[effect][temp_df[var]==0].mean()
effect_var = {'Variable': [var], 'Effect': [effect], 'Value': [v]}
df_effects = pd.concat([df_effects, pd.DataFrame(effect_var)]).reset_index(drop=True)
return df_effects, temp_df['Predicted'].mean()
df_effects, avg_effect_notime = compute_discrete_effects(df, forest_model)fig, ax = plt.subplots()
sns.barplot(data=df_effects, x="Variable", y="Value", hue="Effect", ax=ax).set(
xlabel='', ylabel='', title='Heterogeneous Treatment Effects')
ax.set_xticklabels(ax.get_xticklabels(), rotatinotallow=45, ha="right");
df_time = df.copy()
df_time[[X[1:]] + ['device', 'browser', 'region']] = 0
df_time = dgp.add_treatment_effect(df_time)
df_time['predicted'] = hte_model.effect(df_time[X]) + avg_effect_notime
return df_time
df_time = compute_time_effect(df, forest_model, avg_effect_notime)
sns.scatterplot(x='time', y='effect_on_spend', data=df_time, label='True')
sns.scatterplot(x='time', y='predicted', data=df_time, label='Predicted').set(
ylabel='', title='Heterogeneous Treatment Effects')
plt.legend(title='Effect');
策略定位
cost = 4
from econml.dml import CausalForestDML
np.random.seed(0)
tree_model = CausalForestDML(n_estimators=1, subforest_size=1, inference=False, max_depth=3)
tree_model = tree_model.fit(Y=df[dgp.Y], X=df[X], T=df[dgp.D])
df_train, df_test = df.iloc[:80_000, :], df.iloc[20_000:,]
np.random.seed(0)
tree_model = tree_model.fit(Y=df_train[dgp.Y], X=df_train[X], T=df_train[dgp.D])
forest_model = forest_model.fit(Y=df_train[dgp.Y], X=df_train[X], T=df_train[dgp.D])
def compute_toc(df, hte_model, cost, truth=False):
df_toc = pd.DataFrame()
for q in np.linspace(0, 1, 101):
if truth:
df = dgp.add_treatment_effect(df_test)
effect = df['effect_on_spend']
else:
effect = hte_model.effect(df[X])
ate = np.mean(effect[effect >= np.quantile(effect, 1-q)])
temp = pd.DataFrame({'q': [q], 'ate': [ate]})
df_toc = pd.concat([df_toc, temp]).reset_index(drop=True)
return df_toc
df_toc_tree = compute_toc(df_train, tree_model, cost)
df_toc_forest = compute_toc(df_train, forest_model, cost)def plot_toc(df_toc, cost, ax, color, title):
ax.axhline(y=cost, lw=2, c='k')
ax.fill_between(x=df_toc.q, y1=cost, y2=df_toc.ate, where=(df_toc.ate > cost), color=color, alpha=0.3)
if any(df_toc.ate > cost):
q = df_toc_tree.loc[df_toc.ate > cost, 'q'].values[-1]
else:
q = 0
ax.axvline(x=q, ymin=0, ymax=0.36, lw=2, c='k', ls='--')
sns.lineplot(data=df_toc, x='q', y='ate', ax=ax, color=color).set(
title=title, ylabel='ATT', xlabel='Share of treated', ylim=[1.5, 8.5])
ax.text(0.7, cost+0.1, f'Discount cost: {cost:.0f}$', fnotallow=12)
fix, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6))
plot_toc(df_toc_tree, cost, ax1, 'C0', 'TOC - Causal Tree')
plot_toc(df_toc_forest, cost, ax2, 'C1', 'TOC - Causal Forest')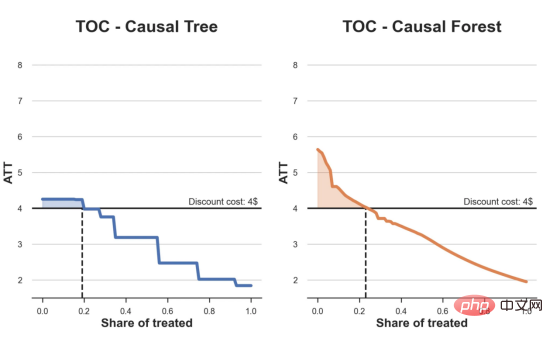
def compute_effect_test(df_test, hte_model, cost, ax, title, truth=False):
df_test['Treated'] = hte_model.effect(df_test[X]) > cost
if truth:
df_test = dgp.add_treatment_effect(df_test)
df_test['Effect'] = df_test['effect_on_spend']
else:
np.random.seed(0)
hte_model_test = copy.deepcopy(hte_model).fit(Y=df_test[dgp.Y], X=df_test[X], T=df_test[dgp.D])
df_test['Effect'] = hte_model_test.effect(df_test[X])
df_test['Cost Effective'] = df_test['Effect'] > cost
tot_effect = ((df_test['Effect'] - cost) * df_test['Treated']).sum()
sns.barplot(data=df_test, x='Cost Effective', y='Treated', errorbar=None, width=0.5, ax=ax, palette=['C3', 'C2']).set(
title=title + 'n', ylim=[0,1])
ax.text(0.5, 1.08, f'Total effect: {tot_effect:.2f}', fnotallow=14, ha='center')
return
fix, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
compute_effect_test(df_test, tree_model, cost, ax1, 'Causal Tree')
compute_effect_test(df_test, forest_model, cost, ax2, 'Causal Forest')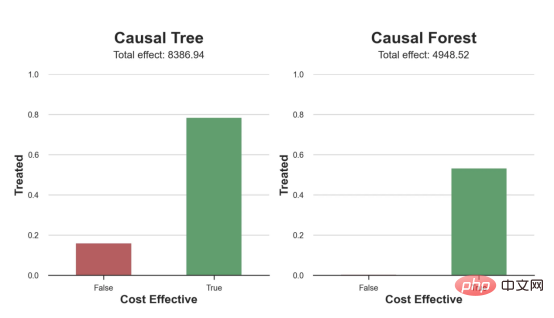
from sklearn.metrics import mean_squared_error as mse
def compute_mse_test(df_test, hte_model):
df_test = dgp.add_treatment_effect(df_test)
print(f"MSE = {mse(df_test['effect_on_spend'], hte_model.effect(df_test[X])):.4f}")
compute_mse_test(df_test, tree_model)
compute_mse_test(df_test, forest_model)fix, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
compute_effect_test(df_test, tree_model, cost, ax1, 'Causal Tree', True)
compute_effect_test(df_test, forest_model, cost, ax2, 'Causal Forest', True)
df_toc = compute_toc(df_test, tree_model, cost, True)
fix, ax = plt.subplots(1, 1, figsize=(7, 5))
plot_toc(df_toc, cost, ax, 'C2', 'TOC - Ground Truth')
Fazit
Das obige ist der detaillierte Inhalt vonEntscheidungspositionierungsanwendung basierend auf einem Kausalwaldalgorithmus. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr