
Heim >Backend-Entwicklung >Python-Tutorial >Ausführliche Erklärung und Beispiele für API-Aufrufe in Python
Ausführliche Erklärung und Beispiele für API-Aufrufe in Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2022-06-16 12:03:195318Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Python, in dem hauptsächlich Probleme im Zusammenhang mit API-Aufrufen vorgestellt werden, einschließlich API-Aufrufen und Datenschnittstellenaufrufen, Anforderungsmethoden, mehreren gängigen Beispielen für API-Aufrufe usw. Werfen wir einen Blick auf den folgenden Inhalt Ich hoffe, es wird für alle hilfreich sein.

Empfohlenes Lernen: Python-Video-Tutorial
Bei der täglichen Arbeit müssen Sie möglicherweise einige aktuelle APIs im Internet oder vom Unternehmen bereitgestellte Datenschnittstellen kombinieren, um entsprechende Daten zu erhalten oder entsprechende Funktionen zu implementieren.
Daher sind das Aufrufen von APIs und der Zugriff auf Datenschnittstellen gängige Vorgänge für die Datenanalyse. Viele Sprachversionen sind im Allgemeinen online verfügbar, aber die zur Verfolgung der Quelle verwendeten Methoden verwenden alle HTTP-Anfragen implementieren.
API
API: Einfach ausgedrückt handelt es sich um eine Reihe von Protokollen, ein Tool oder eine Reihe von Regeln, die Kommunikationsmethoden zwischen verschiedenen Anwendungen definieren, den spezifischen Implementierungsprozess verbergen und nur die Teile offenlegen, die für Entwickler aufgerufen werden müssen verwenden .
Die obige Definition ist relativ offiziell. Hier ist ein einfaches Beispiel zur Veranschaulichung: Fast-Food-Restaurants wie McDonald's verwenden jetzt Mobiltelefone, um online Bestellungen aufzugeben und Mahlzeiten an der Rezeption abzuholen. Dabei wählt der Verbraucher in der Regel die entsprechende Mahlzeit auf seinem Mobiltelefon aus, gibt dort eine Bestellung auf und bezahlt und wartet dann darauf, dass die Rezeption die Nummer zur Abholung der Mahlzeit anruft. Wir wissen nicht genau, wie dieser Prozess umgesetzt wird. Der gesamte Prozess verfügt über eine entsprechende App oder ein kleines Programm, das mit den Küchendaten kommuniziert, und dann bereitet der Koch das Essen zu. Diese APP und dieses Applet dienen als entsprechende API-Funktionen.
Um ein einfaches Beispiel zu nennen: Eine soziale Plattform erhält jeden Tag Kommentare in verschiedenen Sprachen. Als entsprechender Analyst ist es ein großes Problem, sich mit der komplexen Sprachdatenverarbeitung auseinanderzusetzen. Obwohl diese Methode machbar klingt, ist die Integration von Funktionen sehr kostspielig. Zweitens muss man zur Lösung eines Problems ein schwierigeres Problem entwickeln. Dies entfernt sich immer weiter vom ursprünglichen Ziel. Derzeit können wir die relativ ausgereifte inländische Übersetzungsplattform-API verwenden, um die vorhandenen Daten direkt zu verarbeiten. Dies ist relativ günstig, bequemer und kann bestehende Ziele schnell erreichen. An der Rolle der API besteht hier kein Zweifel.
Datenschnittstelle
Datenschnittstelle: Einfach ausgedrückt handelt es sich um einen Satz gekapselter Datensatzkennwörter, was bedeutet, dass entsprechende Parameter gemäß den entsprechenden Regeln gesendet und dann die entsprechenden zugehörigen Dateninformationen zurückgegeben werden. API-Aufrufe und Datenschnittstellen sind bei täglichen Aufrufen sehr ähnlich. Relativ gesehen hat die API einen größeren Umfang und implementiert mehr Funktionen, während die Datenschnittstelle eher als Datenerfassungstool dient.
Große E-Commerce-Unternehmen verwenden beispielsweise im Allgemeinen einheitliche SKUs, um Produkte zu verwalten. Dieses Unternehmen ist beispielsweise Markeninhaber und verkauft auf verschiedenen Plattformen, und die auf diesen Plattformen abgebildeten Produktlogos unterscheiden sich von der SKU des Unternehmens. Da die SKU des Unternehmens nicht nur auf Produkten basiert, sondern auch verschiedene lokale Lager und verschiedene Produktmodelle berücksichtigt, ist diese Zuordnung relativ komplex.
Personen, die mit Daten auf verschiedenen Plattformen arbeiten, können die Datenbank des Unternehmens im Allgemeinen nicht direkt zur Analyse von Produkten verwenden, da die Granularität zu fein ist, was die Analyse komplizierter und schwieriger macht. Derzeit kann die Entwicklung im vorhandenen System durchgeführt werden Anforderungen an die entsprechenden Funktionen Es besteht darin, eine separate Datenschnittstelle zu entwickeln, um entsprechenden Unternehmen die direkte Anforderung entsprechender Informationen wie komplexe Datenbankprozesse zu ersparen. Allerdings kommt es bei der Datenschnittstelle zu einer gewissen Verzögerung gegenüber der Echtzeitdatenbank.
API-Aufruf und Datenschnittstellenaufruf
API und Datenschnittstelle werden anhand der vorherigen Beispiele erläutert und sind relativ einfach zu verstehen. Hier finden Sie eine kurze Einführung in die Implementierung von API-Aufrufen und Datenschnittstellenaufrufen.
Vereinfacht ausgedrückt ähneln API-Aufrufe und Schnittstellenaufrufe einer HTTP-Anfrage. Das Wichtigste beim Aufruf ist, die Anforderungsmethode, den Anforderungsheader, die URL und den Anforderungstext gemäß den entsprechenden Regeln zu kapseln und dann die zu erreichende Anforderung zu senden den entsprechenden Anruf.
Aber im Vergleich zu den Aufrufen von Datenschnittstellen und APIs ist die allgemeine Datenschnittstelle relativ einfach. In vielen Fällen wird die Datenschnittstelle für den Datenzugriff im Intranet des Unternehmens verwendet, sodass das Anfordern von Informationen relativ einfach ist, während APIs größtenteils entwickelt werden Um die Sicherheit der Anfrage zu gewährleisten, ist es relativ kompliziert, Informationen wie AK, SK und Signatur hinzuzufügen Zeitstempel.
Die beiden Aufrufe zur Rückverfolgung zur Quelle ähneln HTTP-Anfragen. Die spezifischen Aufrufe sind in etwa gleich, hauptsächlich weil die API-Aufrufe mehr Informationen zu den Anfrageparametern enthalten. Die konkrete Implementierung wird im Folgenden kurz vorgestellt.
Die Grundlage des Aufrufs – Anforderungsmethode
Im Allgemeinen gibt es viele gängige HTTP-Anforderungsaufrufmethoden. Sie können sie online überprüfen.
GET-Anfrage
Eine GET-Anfrage ruft einfach Ressourcen vom Server ab und kann in den Cache des Browsers geladen werden.
POST-Anfrage
POST-Anfrage sendet im Allgemeinen eine Anfrage in Form eines Formulars an den Server. Die im Anfragetext enthaltenen Anfrageparameter können zur Erstellung und Änderung von Ressourcen führen. Informationen aus POST-Anfragen können nicht im Browser zwischengespeichert werden.
Diese beiden Anforderungsmethoden sind sehr einfach zu sagen, aber der wichtigste Punkt besteht darin, den Unterschied zwischen diesen beiden Anforderungen zu verstehen, um mit dem Design der Schnittstelle und der Verwendung der API vertrauter zu werden.
Der Unterschied zwischen GET- und POST-Anfragen
1 Die Anfragelänge der GET-Anfrage beträgt bis zu 1024 KB, und bei POST gibt es keine Begrenzung für die Anfragedaten. Der Grund dafür ist, dass GET-Anfragen oft die entsprechenden Informationen in die URL einfügen und die Länge der URL begrenzt ist, was zu einer gewissen Begrenzung der Länge der GET-Anfrage führt. Die entsprechenden Parameterinformationen der POST-Anfrage werden im Anfragetext abgelegt und unterliegen daher im Allgemeinen keinen Längenbeschränkungen.
2. Die POST-Anfrage ist sicherer als die GET-Anfrage, da die URL in der GET-Anfrage die entsprechenden Informationen enthält, die Seite vom Browser zwischengespeichert wird und andere Personen die entsprechenden Informationen sehen können.
3.GET generiert ein TCP-Datenpaket und POST generiert zwei TCP-Datenpakete.
Bei einer GET-Anfrage werden Header und Daten zusammen gesendet und der Server antwortet dann mit 200. POST sendet zuerst den Header, wartet darauf, dass der Server mit 100 antwortet, sendet dann Daten und schließlich antwortet der Server mit 200. Beachten Sie hier jedoch, dass die POST-Anfrage in zwei Teile geteilt ist, der Anfragetext jedoch unmittelbar nach dem Header gesendet wird , daher kann die Zeit dazwischen vernachlässigbar sein.
4. GET-Anfragen unterstützen nur die URL-Kodierung, während POST über verschiedene Kodierungsmethoden verfügt.
5. GET-Anfrageparameter werden über die URL übergeben, mehrere Parameter werden mit & verbunden und POST-Anfragen werden im Anfragetext platziert.
6.GET-Anfragen unterstützen nur ASCII-Zeichen, während POST keine Begrenzung hat.
Im Allgemeinen ist die URL, auf die der Browser direkt zugreifen kann, normalerweise eine GET-Anfrage.
Python implementiert GET-Anfragen und POST-Anfragen
Das oben Gesagte hat einige Datenschnittstellen, API-bezogene Kenntnisse und Anforderungsmethoden in großem Zeitaufwand eingeführt. Im Folgenden können Sie sich mit der allgemeinen Vertrautheit vertraut machen entsprechende Anfragemethoden. Im Allgemeinen können Sie die Anforderungsbibliothek von Python direkt verwenden.
GET-Anfrage
import request
# GET请求发送的参数一定要是字典的形式,可以发送多个参数。
# 发送格式:{'key1':value1', 'key2':'value2', 'key3', 'value3'}
# 样例不能运行
url ='http://www.xxxxx.com'
params = {'user':'lixue','password':111112333}
requests.get(url,data = parms)
POST-Anfrage
POST-Anfragen haben im Allgemeinen drei Einreichungsformen: application/x-www-form-urlencoded, multipart/form-data, application/json.
Es gibt drei Typen, die angezeigt werden können Konkret. Welche Anfragemethode: Überprüfen Sie mit Google Chrome → Netzwerk → Wählen Sie, um die Datei zu laden → Header → Reuqest-Header → Inhaltstyp
Die spezifischen Codierungsmethoden sind im Allgemeinen die internen Daten Die Schnittstelle des Unternehmens hat ein LAN eingerichtet, sodass einige keine Header hinzufügen müssen.
Drei Einreichungsformen von POST-Anfragen
1. Die häufigsten Post-Einreichungsdaten sind hauptsächlich Formular: application/x-www-form-urlencoded
import request
data={'k1':'v1','k2':'v2'}
headers= {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'}
requests.post(url,headers = headers,data=data)
2. Senden Sie Daten im JSON-Format: application/json
data = {'user':'lixue','password':12233}
data_json = json.dumps(params)
requests.post(url,headers = headers,data = data_json) 3. Im Allgemeinen zum Übertragen von Dateien verwendet (selten von Crawlern verwendet): multipart/form-data
files = {'files':open('c://xxx.txt','rb')}
requests.post(url = url,headers = headers,files = files)
Ein Beispiel für eine einfache API-Anfrage
Durch die obige einfache Einführung können Sie sich ein allgemeines Verständnis der spezifischen Anforderungen verschaffen , hier gesammelt Es wird ein einfaches API-Aggregationszentrum erstellt, das viele nützliche Funktionen bereitstellt. Im Folgenden wird diese einfache API als einfache Demonstrations-API-Adresse verwendet.
In diesem kleinen Beispiel wird die Wetter-API-Schnittstelle verwendet, um das Wetter der letzten 15 Tage abzurufen. Denken Sie daran, den entsprechenden API-Schlüssel zu erhalten und die spezifische Nutzungsdokumentation zu überprüfen, bevor Sie diese API verwenden. Diese API-Website stellt im Allgemeinen eine bestimmte Anzahl freier Zeiten für die entsprechende API bereit, die zum Lernen verwendet werden können, und unterstützt GET- und POST-Anfragen. Genau richtig zum Üben.
GET-Anfrage
params = {
"apiKey":'换成你的apikey',
"area":'武汉市',
}
url = 'https://api.apishop.net/common/weather/get15DaysWeatherByArea'
response = requests.get(url,params)
print(response.text)
POST-Anfrage
Die POST-Anfrage hier entspricht den oben genannten häufigsten Post-Übermittlungsdaten, hauptsächlich dem Formular: application/x-www-form-urlencoded
url = 'https://api.apishop.net/common/weather/get15DaysWeatherByArea'
params = {
"apiKey":'换成你的apikey',
"area":'武汉市武昌区',
}
response = requests.post(url,params)
print(response.text)
Rufen Sie diese API-Schnittstelle auf. Im Allgemeinen ist dies der Fall Es ist erforderlich, einen Statuscode- und anderen Rückgabeinformationstest durchzuführen, um zu überprüfen, ob die Anfrage normal ist. Sie können sich auf Folgendes beziehen.
params = {
"apiKey":'换成你的apikey,
"area":'武汉市',
}
url = 'https://api.apishop.net/common/weather/get15DaysWeatherByArea'
response = requests.post(url,params)
print(response.text)
if response.status_code != 200:
raise ConnectionError(f'{url} status code is {response.status_code}.')
response = json.loads(response.content)
if 'desc' not in response.keys():
raise ValueError(f'{url} miss key msg.')
if response['desc'] != '请求成功':
print(11)
Datenextraktion
Tatsächlich ist der API-Aufruf sehr einfach, aber der Kern besteht darin, die Daten in den zurückgegebenen Informationen zu extrahieren. Im Allgemeinen liegen die zurückgegebenen Informationen in JSON-Form vor und die Daten müssen extrahiert werden Unter Verwendung von Wörterbuch-Schlüssel-Wert-Paaren gibt der folgende Block die entsprechenden Informationen basierend auf den angeforderten Daten zurück und extrahiert sie. Die erhaltenen Informationen werden später angezeigt.
import requestsimport pandas as pd
import numpy as npimport jsondef get_url(area):
url = 'https://api.apishop.net/common/weather/get15DaysWeatherByArea'
params = {
"apiKey":'换成你的apikey',
"area":area,
}
response = requests.get(url,params)
if response.status_code != 200:
raise ConnectionError(f'{url} status code is {response.status_code}.')
response = json.loads(response.content)
if 'desc' not in response.keys():
raise ValueError(f'{url} miss key msg.')
if response['desc'] != '请求成功':
print(11)
return responsedef extract_data(web_data):
data= web_data['result']['dayList']
weather_data = pd.DataFrame(columns = ['city','daytime','day_weather','day_air_temperature','day_wind_direction','day_wind_power', 'night_weather','night_air_temperature','night_wind_direction','night_wind_power'])
for i in range(len(data)):
city = data[i]["area"]
daytime = data[i]["daytime"]
daytime = daytime[:4]+'-'+daytime[4:6]+'-'+daytime[-2:]
day_weather = data[i]["day_weather"]
day_air_temperature = data[i]['day_air_temperature']
day_wind_direction = data[i]["day_wind_direction"]
day_wind_power = data[i]['day_wind_power']
night_weather = data[i]['night_weather']
night_air_temperature = data[i]["night_air_temperature"]
night_wind_direction = data[i]['night_wind_direction']
night_wind_power = data[i]["night_wind_power"]
c = {"city": city,"daytime": daytime,"day_weather":day_weather,"day_air_temperature":day_air_temperature,
"day_wind_direction":day_wind_direction,"day_wind_power":day_wind_power,"night_weather":night_weather,
"night_air_temperature":night_air_temperature,"night_wind_direction":night_wind_direction,
"night_wind_power":night_wind_power}
weather_data = weather_data.append(c,ignore_index = True)
weather_data.to_excel(r"C:\Users\zhangfeng\Desktop\最近十五天天气.xlsx",index = None)
return weather_dataif __name__ == '__main__':
print("请输入对应的城市")
web_data = get_url(input())
weather_data = extract_data(web_data)
Ein Teil der Ergebnisse lautet wie folgt: 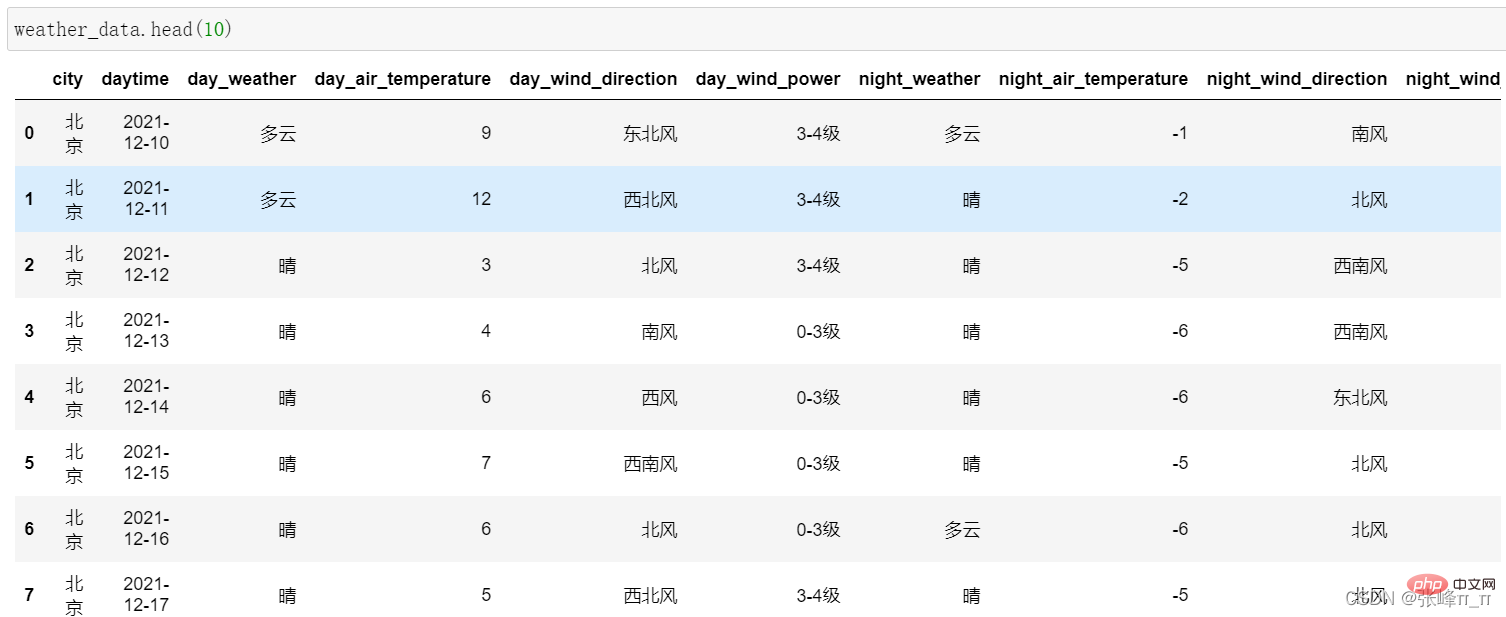
Beispiele für Datenschnittstellen
Der Einsatz von Datenschnittstellen ist im täglichen Lernen möglicherweise relativ selten. In den meisten Fällen werden die Anwendungsszenarien von Datenschnittstellen zum Abrufen von Daten verwendet Es gibt viele, daher wird hier die Verwendung von zwei Datenschnittstellen gezeigt, die aus Arbeitsgründen nicht aufgerufen werden können. Sie können sich auf die aufrufende Implementierung und die Spezifikationen beziehen.
POST请求调用数据接口
# 销售状态查询def id_status(id_dir):
id_data = pd.read_excel(id_dir,sheet_name="Sheet1")
id_data.columns = ['shop', 'Campaign Name','Ad Group Name','Item Id'] # 方便后期处理更改列名
id_data["Item Id"] = id_data["Item Id"].astype(str)
id_list = list(id_data['Item Id'])
print(len(id_list))
id_list = ','.join(id_list)
if isinstance(id_list, int):
id_list = str(id_list)
id1 = id_list.strip().replace(',', ',').replace(' ', '')
request_url = "http://xxx.com"
# 通过item_id查询id状态
params = {
"item_id":id1,
}
data_json = json.dumps(params) # 属于POST第二种请求方式
response = requests.post(request_url, data = data_json)
print(response.text)
if response.status_code != 200:
raise ConnectionError(f'{request_url} status code is {response.status_code}.')
response = json.loads(response.content)
if 'message' not in response.keys():
raise ValueError(f'{request_url} miss key msg.')
if response['message'] != 'ok':
print(11)
data= response['result']
ad_data = pd.DataFrame(columns = ['Item Id','saleStatusName'])
for j in range(len(data)):
item_id =data[j]["item_id"]
saleStatusName = data[j]['saleStatusName']
c = {"Item Id": item_id,
"saleStatusName": saleStatusName,
}
ad_data = ad_data.append(c,ignore_index = True)
total_data = pd.merge(ad_data,id_data,on ='Item Id', how ='left')
df_column = ['shop', 'Campaign Name','Ad Group Name','Item Id','saleStatusName']
total_data = total_data.reindex(columns=df_column)
return total_data
GET请求调用数据接口
### 库存数据查询def Smart_investment_treasure(investment_dir):
product_data = pd.read_excel(investment_dir,sheet_name="product")
if len(product_data)>0:
product_data['商品ID']=product_data['商品ID'].astype(str)
product_list=list(product_data['商品ID'])
product_id = ','.join(product_list)
else:
product_id='没有数据'
return product_id
def stock_query(investment_dir):
product_data = pd.read_excel(investment_dir,sheet_name="product")
if len(product_data)>0:
product_data['商品ID']=product_data['商品ID'].astype(str)
product_list=list(product_data['商品ID'])
product_id = ','.join(product_list)
else:
product_id='没有数据'
if isinstance(product_id, int):
product_id = str(id)
product_id = product_id.strip().replace(',', ',').replace(' ', '')
request_url = "http://xxx.com"
# 通过ali_sku查询erpsku
params = {
"product_id":product_id,
}
response = requests.get(request_url, params) #属于GET请求
if response.status_code != 200:
raise ConnectionError(f'{request_url} status code is {response.status_code}.')
response = json.loads(response.content)
if 'msg' not in response.keys():
raise ValueError(f'{request_url} miss key msg.')
if response['msg'] != 'success':
print(11)
data= response['data']['data']
# requestProductId = id.split(',')
id_state=[]
overseas_stock=[]
china_stock=[]
id_list=[]
for j in range(len(data)):
inventory_data= data[j]['list']
overseas_inventory=0
ep_sku_list=[]
sea_test=0
china_inventory=0
test="paused"
id_test=""
id_test=data[j]['product_id']
for i in range(len(inventory_data)):
if inventory_data[i]["simple_code"] in ["FR","DE","PL","CZ","RU"] and inventory_data[i]["erp_sku"] not in ep_sku_list:
overseas_inventory+=inventory_data[i]["ipm_sku_stock"]
ep_sku_list.append(inventory_data[i]["erp_sku"])
sea_test=1
elif inventory_data[i]["simple_code"] == 'CN':
china_inventory+=int(inventory_data[i]["ipm_sku_stock"])
if overseas_inventory>30:
test="open"
elif overseas_inventory==0 and china_inventory>100:
test="open"
id_list.append(id_test)
overseas_stock.append(overseas_inventory)
china_stock.append(china_inventory)
id_state.append(test)
c={"id":id_list,
"id_state":id_state,
"海外仓库存":overseas_stock,
"国内大仓":china_stock }
ad_data=pd.DataFrame(c)
return ad_data
几种常见API调用实例
百度AI相关API
百度API是市面上面比较成熟的API服务,在大二期间由于需要使用一些文本打标签和图像标注工作了解了百度API,避免了重复造轮子,当时百度API的使用比较复杂,参考文档很多不规范,之前也写过类似的百度API调用极其不稳定,但最近查阅了百度API参考文档,发现目前的调用非常简单。
通过安装百度开发的API第三方包,直接利用Python调包传参即可使用非常简单。这里展示一个具体使用,相应安装第三方库官方文档查阅。
''' 第三方包名称:baidu-aip 百度API """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Api Key' SECRET_KEY = '你的 Secret Key' 参考文档:https://ai.baidu.com/ai-doc/NLP/tk6z52b9z ''' from aip import AipNlp APP_ID = 'xxxxxx' API_KEY = '换成你的apikey' SECRET_KEY = '换成你的SECRET_KEY' client = AipNlp(APP_ID, API_KEY, SECRET_KEY) text = "我还没饭吃" # 调用文本纠错 client.ecnet(text)

百度地图API
这个API当时为了设计一个推荐体系引入经纬度换算地址,这样为数据计算带来极大的方便,而且对于一般人来说文本地址相比经纬度信息更加直观,然后结合Python一个第三方包实现两个地址之间经纬度计算得出相对的距离。
# https://lbsyun.baidu.com/
# 计算校验SN(百度API文档说明需要此步骤)
import pandas as pd
import numpy as np
import warnings
import requests
import urllib
import hashlib
import json
from geopy.distance import geodesic
location = input("输入所在的位置\n") # "广州市天河区"
ak = "ak1111" # 参照自己的应用
sk = "sk111111" # 参照自己的应用
url = "http://api.map.baidu.com"
query = "/geocoding/v3/?address={0}&output=json&ak={1}&callback=showLocation".format(location, ak)
encodedStr = urllib.parse.quote(query, safe="/:=&?#+!$,;'@()*[]")
sn = hashlib.md5(urllib.parse.quote_plus(encodedStr + sk).encode()).hexdigest()
# 使用requests获取返回的json
response = requests.get("{0}{1}&sn={2}".format(url, query, sn))
data1=response.text.replace("showLocation&&showLocation(","").replace(")","")
data = json.loads(data1)
print(data)
lat = data["result"]["location"]["lat"]
lon = data["result"]["location"]["lng"]
print("纬度: ", lat, " 经度: ", lon)
distance=geodesic((lat,lon), (39.98028,116.30495))
print("距离{0}这个位置大概{1}".format(location, distance))

有道API
在网上查阅了很多API,前面介绍的几种API,他们携带的请求参数信息相对比较简单,调用实现和基础请求没啥区别,这里找了一个相对而言比较多的请求参数的API,相对而言这种API数据付费API,它的安全性以及具体的实现都相对复杂,但是更适合商用。下面可以简单看看。
import requests
import time
import hashlib
import uuid
youdao_url = 'https://openapi.youdao.com/api' # 有道api地址
translate_text = "how are you!"
input_text = ""
# 当文本长度小于等于20时,取文本
if(len(translate_text) 20):
input_text = translate_text[:10] + str(len(translate_text)) + translate_text[-10:]
uu_id = uuid.uuid1()
now_time = int(time.time())
app_id = '1111111'
app_key = '11111111111'
sign = hashlib.sha256((app_id + input_text + str(uu_id) + str(now_time) + app_key).encode('utf-8')).hexdigest() # sign生成
data = {
'q':translate_text, # 翻译文本
'from':"en", # 源语言
'to':"zh-CHS", # 翻译语言
'appKey':app_id, # 应用id
'salt':uu_id, # 随机生产的uuid码
'sign':sign, # 签名
'signType':"v3", # 签名类型,固定值
'curtime':now_time, # 秒级时间戳
}
r = requests.get(youdao_url, params = data).json() # 获取返回的json()内容
print("翻译后的结果:" + r["translation"][0]) # 获取翻译内容
翻译后的结果:你好!
这个API调用中引用了几个真正商用中的一些为了安全性等设置的验证信息,比如uuid、sign、timestamp,这几个在API调用中也是老生常谈的几个概念,是比较全面的。下面简单介绍一下。
uuid
uuid码:UUID是一个128比特的数值,这个数值可以通过一定的算法计算出来。为了提高效率,常用的UUID可缩短至16位。UUID用来识别属性类型,在所有空间和时间上被视为唯一的标识。一般来说,可以保证这个值是真正唯一的任何地方产生的任意一个UUID都不会有相同的值。使用UUID的一个好处是可以为新的服务创建新的标识符。是一种独特的唯一标识符,python 第三方库uuid 提供对应的uuid生成方式,有以下的几种 uuid1(),uuid3(),uuid4(),uuid5()上面采用的是uuid1()生成,还可以使用uuid4()生成。
sign
sign:一般为了防止被恶意抓包,通过数字签名等保证API接口的安全性。为了防止发送的信息被串改,发送方通过将一些字段要素按一定的规则排序后,在转化成密钥,通过加密机制发送,当接收方接受到请求后需要验证该信息是否被篡改过,也需要将对应的字段按照同样的规则生成验签sign,然后在于后台接收到的进行比对,可以发现信息是否被串改过。在上面的例子利用hashlib.sha256()来进行随机产生一段密钥,最后使用.hexdigest()返回最终的密钥。
curtime:引入一个时间戳参数,保证接口仅在一分钟内有效,需要和客户端时间保持一致。避免重复访问。
推荐学习:python视频教程
Das obige ist der detaillierte Inhalt vonAusführliche Erklärung und Beispiele für API-Aufrufe in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Python-Zeichen und -Listen einfach lernen (detaillierte Beispiele)
- Die besten neuen Funktionen und Funktionskorrekturen in Python 3.11
- Fassen Sie die fortgeschrittene Verwendung von Python-Funktionen zusammen
- Python-Automatisierungspraxis für das Screening von Lebensläufen
- Praktische Python-Analyse der Grundelemente von Selenium sowie Tastatur- und Maussimulationsereignissen