
Heim >Backend-Entwicklung >Python-Tutorial >Python crawlt Douban-Filmdaten und extrahiert wertvolle XPath- und LXML-Module (Code)
Python crawlt Douban-Filmdaten und extrahiert wertvolle XPath- und LXML-Module (Code)

- 不言nach vorne
- 2018-09-28 14:45:343929Durchsuche
In diesem Artikel geht es um das Crawlen von Douban-Filmdaten und das Extrahieren von Wert-XPath- und LXML-Modulen. Ich hoffe, dass es für Sie hilfreich ist. helfen.
Tools: Python 3.6.5, PyCharm-Entwicklungstools, Windows 10-Betriebssystem, Google Chrome
Zweck: Crawlen des Titels, Linkadresse des Films in der Douban-Filmrankings, Bilder, Anzahl der Rezensenten, Bewertungen usw.
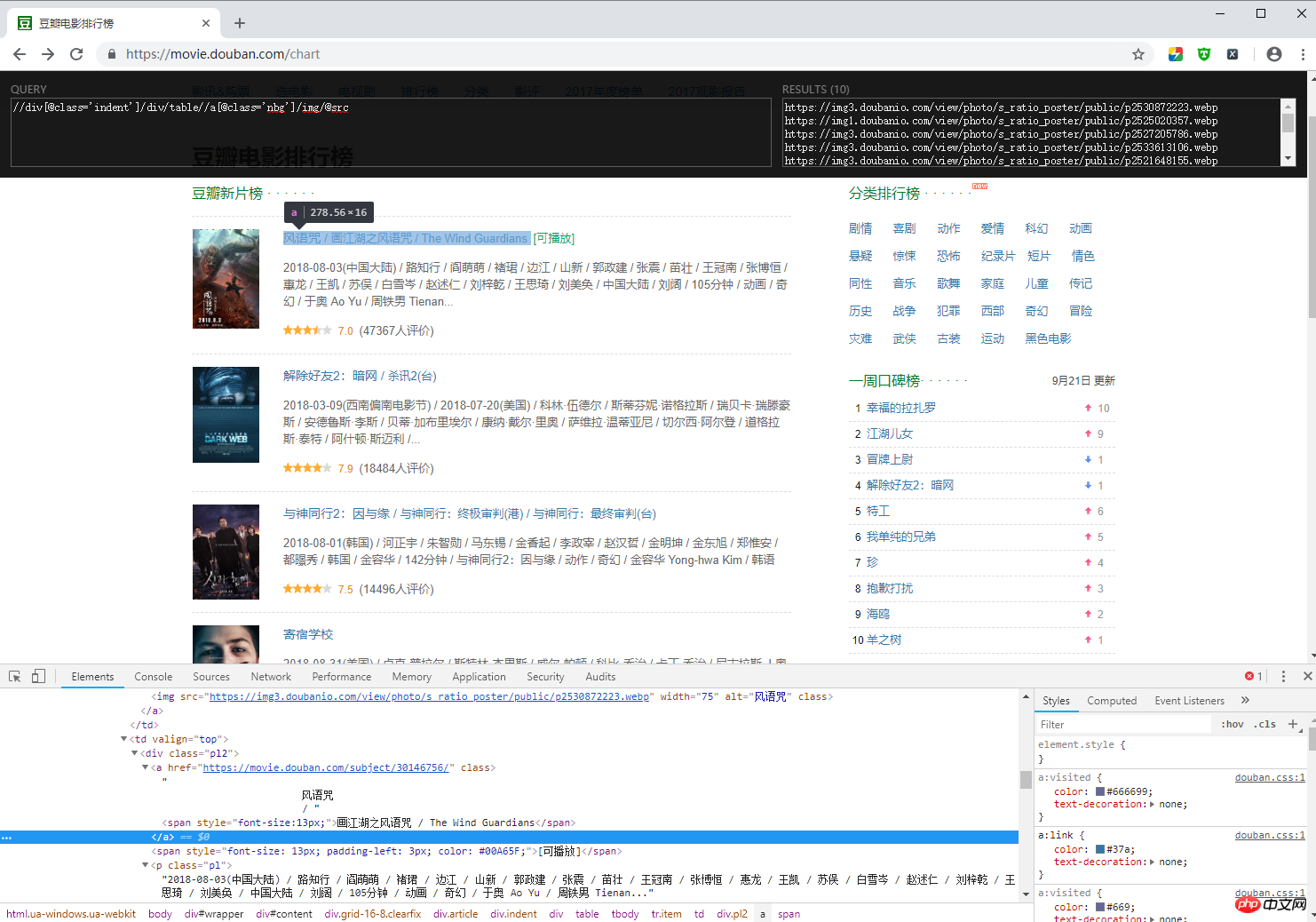
Website: https://movie.douban.com/chart
Grammatikpunkte:
xpath-Syntax:
Google Chrome installiert das xpath-Hilfs-Plug-in: Helfen Sie uns, Daten aus Elementen zu finden
1. Wählen Sie den Knoten (Label)
(1 ), /html/ head/meta: kann alle Meta-Tags unter HTML auswählen
(2), //li: alle li-Tags auf der aktuellen Seite
(3), /html/head//link: Alle Link-Tags unter head
2. //: Sie können aus jedem Knoten auswählen
(1), //li: Alle li-Tags auf der aktuellen Seite
(2), /html/head//link: head Alle Link-Tags unter
3. Der Zweck des @-Symbols
(1) Wählen Sie ein bestimmtes Element aus: //p[ @class ='feed']/ul/li, wählen Sie li unter ul unter p von class='feed'
(2), a/@href: Wählen Sie den href-Wert eines
4. Holen Sie sich den Text
( 1), /a/text(): Holen Sie sich den Text unter einem
(2), /a//text(): Holen Sie sich den gesamten Text unter einem Text
Beispiel:
lxml-Syntax:
1. Installation: pip install lxml
2 >
from lxml import etree
element = etree.HTML("html string")
element.xpath("")
Code:
from lxml import etree
import requests
url = "https://movie.douban.com/chart"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
response = requests.get(url,headers=headers)
html_str = response.content.decode()
#print(html_str)
html = etree.HTML(html_str)
print(html)
#1.获取所有的电影的URL地址
#url_list = html.xpath("//div[@class='indent']/div/table//div[@class='pl2']/a/@href")
#print(url_list)
#2.所有图片的地址
#img_list = html.xpath("//div[@class='indent']/div/table//a[@class='nbg']/img/@src")
#print(img_list)
ret1 = html.xpath("//div[@class='indent']/div/table")
print(ret1)
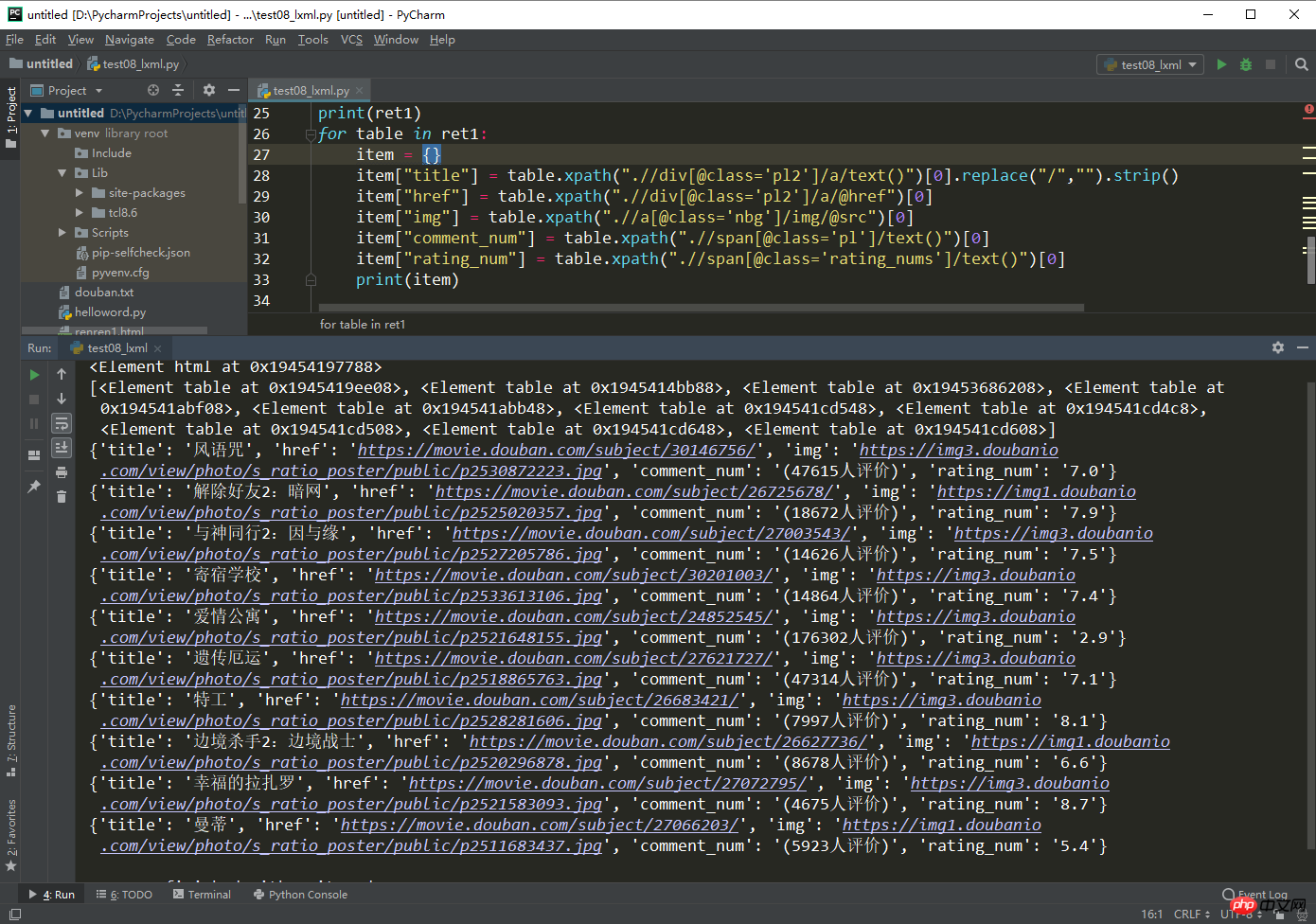
for table in ret1:
item = {}
item["title"] = table.xpath(".//div[@class='pl2']/a/text()")[0].replace("/","").strip()
item["href"] = table.xpath(".//div[@class='pl2']/a/@href")[0]
item["img"] = table.xpath(".//a[@class='nbg']/img/@src")[0]
item["comment_num"] = table.xpath(".//span[@class='pl']/text()")[0]
item["rating_num"] = table.xpath(".//span[@class='rating_nums']/text()")[0]
print(item)
Betriebseffekt:
Das obige ist der detaillierte Inhalt vonPython crawlt Douban-Filmdaten und extrahiert wertvolle XPath- und LXML-Module (Code). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Beispiel für den Prozess des Crawlens von qq-Musik mit Python
- Beispiel-Tutorial für einen Python-Crawling-Artikel
- Python-Crawling-Methode für den Datenaustausch auf Anjuke-Gebrauchtwohnungswebsites
- Am Beispiel des Erfassens von Taobao-Kommentaren wird erläutert, wie Python von Ajax dynamisch generierte Daten crawlt (klassisch).