
Heim >Backend-Entwicklung >Python-Tutorial >Beispiel-Tutorial für einen Python-Crawling-Artikel
Beispiel-Tutorial für einen Python-Crawling-Artikel
- 巴扎黑Original
- 2017-08-07 17:37:451968Durchsuche
Dieser Artikel führt Sie hauptsächlich in die relevanten Informationen zur Verwendung von Python zum Crawlen von Artikeln auf Prosa-Websites ein. Die Einführung im Artikel ist sehr detailliert und bietet einen gewissen Referenz- und Lernwert für alle Freunde, die sie benötigen.
Dieser Artikel stellt Ihnen hauptsächlich die relevanten Inhalte zu Python-Crawling-Prosa-Netzwerkartikeln vor. Er wird als Referenz und zum Studium zur Verfügung gestellt:
Das Rendering ist wie folgt:

Konfigurieren Sie Python 2.7
bs4 requests
Installation mit pipsudo pip install bs4
sudo pip install requests
Da es Webseiten crawlt, werde ich es tun Führen Sie find und find_all ein.
Der Unterschied zwischen find und find_all besteht darin, dass das, was zurückgegeben wird, unterschiedlich ist; find gibt das erste übereinstimmende Tag zurück und der Inhalt im Tag
find_all gibt eine Liste zurück
Beispielsweise schreiben wir eine test.html, um den Unterschied zwischen find und find_all zu testen.
Der Inhalt ist:
<html> <head> </head> <body> <p id="one"><a></a></p> <p id="two"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >abc</a></p> <p id="three"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a></p> <p id="four"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >four<p>four p</p><p>four p</p><p>four p</p> a</a></p> </body> </html>
Dann lautet der Code von test.py:
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('p') print s.find_all('p') print "------------------------------" print s.find('p',id='one') print s.find_all('p',id='one') print "------------------------------" print s.find('p',id="two") print s.find_all('p',id="two") print "------------------------------" print s.find('p',id="three") print s.find_all('p',id="three") print "------------------------------" print s.find('p',id="four") print s.find_all('p',id="four") print "------------------------------"
Nach dem Ausführen können wir das Ergebnis sehen. Beim Abrufen einer Gruppe von Tags wird der Unterschied zwischen den beiden angezeigt .
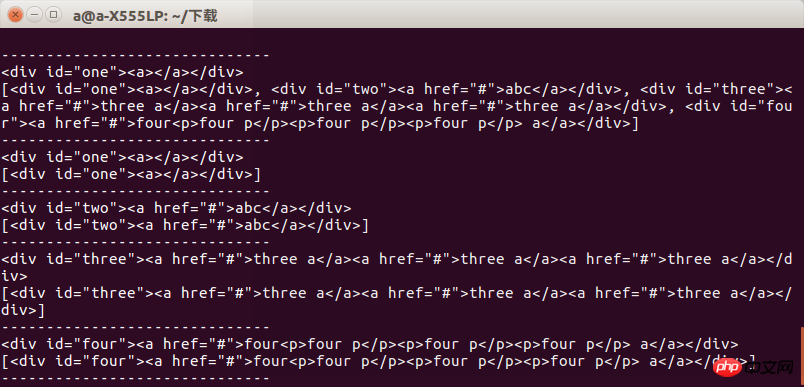
Wir müssen also darauf achten, was wir wollen, wenn wir es verwenden, sonst erscheint ein Fehler
Der nächste Schritt ist es, Webseiteninformationen durch Anfragen zu erhalten. Warum schreibe ich gehörte und andere Dinge? Ich greife direkt auf die Webseite zu und erhalte mehrere klassifizierte sekundäre Webseiten Durch die Methode get und dann einen Gruppentest bestehen, um alle Webseiten zu crawlen
In diesem Teil des Codes habe ich das
def get_html():
url = "https://www.sanwen.net/"
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel']
for doc in two_html:
i=1
if doc=='sanwen':
print "running sanwen -----------------------------"
if doc=='shige':
print "running shige ------------------------------"
if doc=='zawen':
print 'running zawen -------------------------------'
if doc=='suibi':
print 'running suibi -------------------------------'
if doc=='rizhi':
print 'running ruzhi -------------------------------'
if doc=='nove':
print 'running xiaoxiaoshuo -------------------------'
while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)
if res.status_code==200:
soup(res.text)
i+=ires.status_codeDer Maximalwert von p ist 10. Ich verstehe das nicht Als ich die Festplatte das letzte Mal gecrawlt habe, waren es 100 Seiten. Vergessen Sie es und analysieren Sie es später. Rufen Sie dann den Inhalt jeder Seite über die get-Methode ab.
Nachdem Sie den Inhalt jeder Seite erhalten haben, analysieren Sie den Autor und den Titel. Der Code sieht so aus:
Es gibt einen Ich möchte euch fragen, warum ihr nicht nur einen, sondern auch zwei Schrägstriche in den Dateinamen einfügt, als ich die Datei später schrieb. Also habe ich einen regulären Ausdruck geschrieben und werde ihn Ihnen geben. Ändern Sie Ihre Karriere.
def soup(html_text): s = BeautifulSoup(html_text,'lxml') link = s.find('p',class_='categorylist').find_all('li') for i in link: if i!=s.find('li',class_='page'): title = i.find_all('a')[1] author = i.find_all('a')[2].text url = title.attrs['href'] sign = re.compile(r'(//)|/') match = sign.search(title.text) file_name = title.text if match: file_name = sign.sub('a',str(title.text))
Der letzte Schritt besteht darin, den Prosainhalt zu erhalten, indem wir die Artikeladresse analysieren und dann den Inhalt erhalten, den ich ursprünglich einzeln erhalten wollte die Webadresse, was Ärger erspart.
Schreiben Sie abschließend die Datei und speichern Sie sie in Ordnung
def get_content(url): res = requests.get('https://www.sanwen.net'+url) if res.status_code==200: soup = BeautifulSoup(res.text,'lxml') contents = soup.find('p',class_='content').find_all('p') content = '' for i in contents: content+=i.text+'\n' return content
Drei Funktionen, um die zu erhalten Prosa-Netzwerk Prosa, aber es gibt ein Problem, dass ich nicht weiß, warum einige Artikel verloren gehen. Dies unterscheidet sich stark von den Artikeln auf Prose.com Seite für Seite. Ich hoffe, jemand kann mir bei diesem Problem helfen. Vielleicht sollten wir die Webseite unzugänglich machen. Natürlich denke ich, dass es etwas mit dem kaputten Netzwerk in meinem Wohnheim zu tun hat
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
Ich hätte das Rendering fast vergessen
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
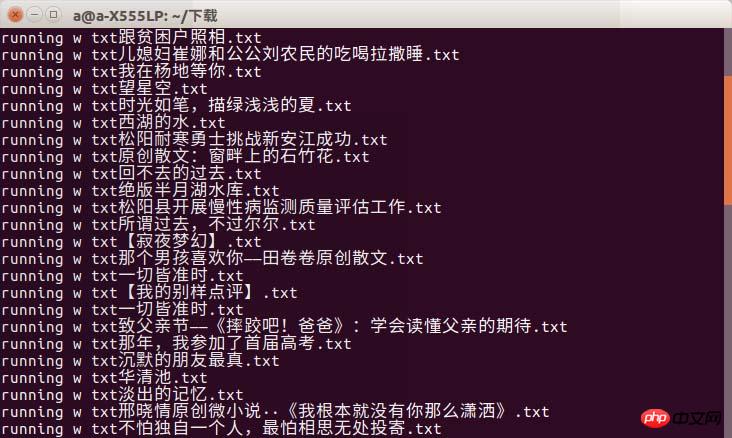 Es kann zu einem Timeout-Phänomen kommen. Ich kann nur sagen, dass Sie eine gute Internetverbindung wählen müssen, wenn Sie zur Uni gehen!
Es kann zu einem Timeout-Phänomen kommen. Ich kann nur sagen, dass Sie eine gute Internetverbindung wählen müssen, wenn Sie zur Uni gehen!
Das obige ist der detaillierte Inhalt vonBeispiel-Tutorial für einen Python-Crawling-Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!