
Heim >Backend-Entwicklung >Python-Tutorial >Python-Crawling-Methode für den Datenaustausch auf Anjuke-Gebrauchtwohnungswebsites
Python-Crawling-Methode für den Datenaustausch auf Anjuke-Gebrauchtwohnungswebsites

- 小云云Original
- 2018-01-09 13:20:283765Durchsuche
Dieser Artikel enthält hauptsächlich einen Python-Artikel zum Crawlen von Anjuke-Gebrauchtwohnungs-Website-Daten (Erklärung mit Beispielen). Der Herausgeber findet es ziemlich gut, deshalb teile ich es jetzt mit Ihnen und gebe es als Referenz. Folgen wir dem Herausgeber und schauen wir uns das an. Ich hoffe, es kann allen helfen.
Beginnen wir nun mit dem Schreiben des offiziellen Crawlers. Zuerst müssen wir die Struktur der zu crawlenden Website analysieren: Schauen wir uns als Student in Henan die Informationen zu Gebrauchtwohnungen in Zhengzhou an! 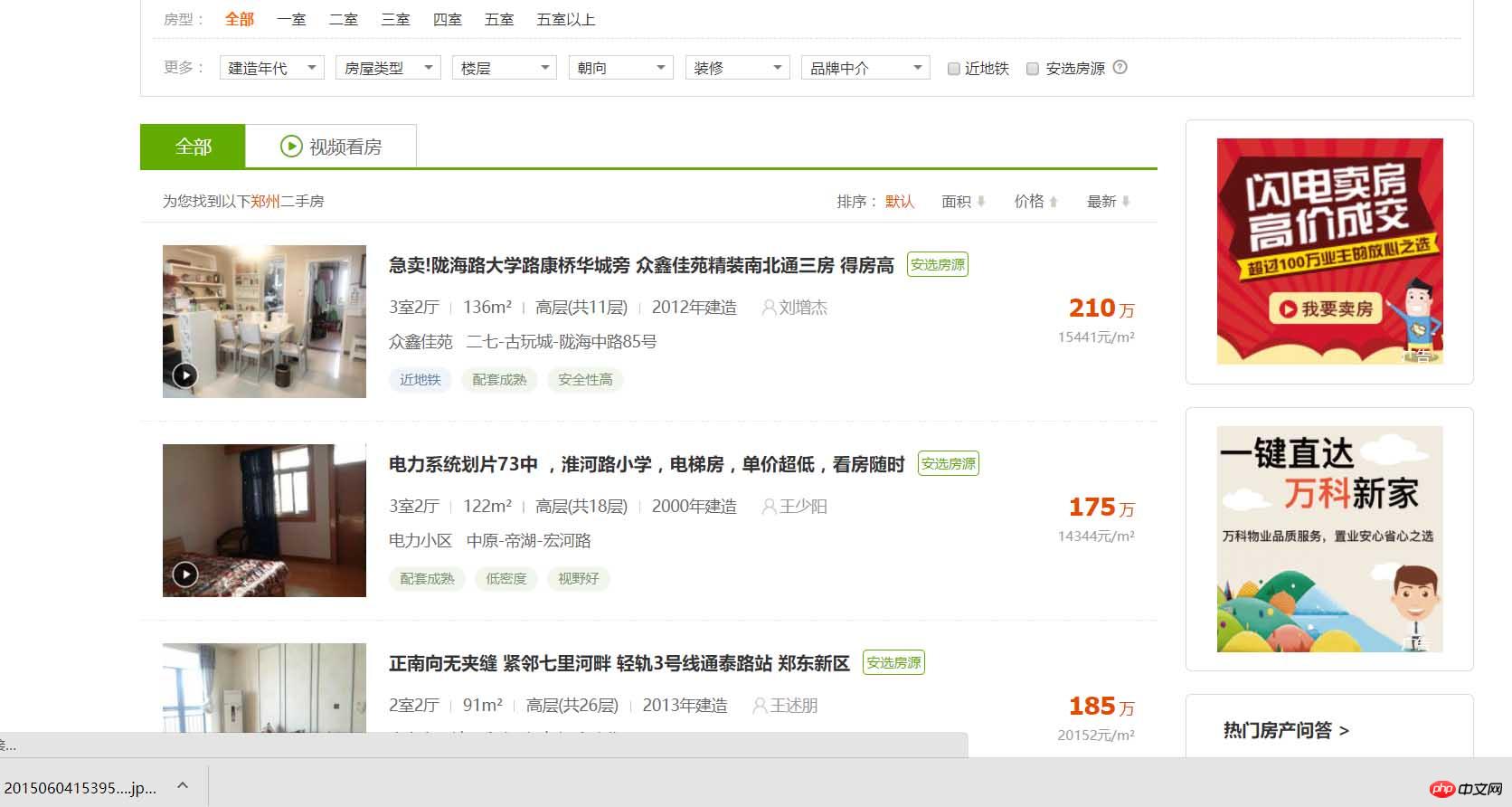
Auf der obigen Seite können wir die Immobilieninformationen einzeln sehen. Von oben können wir die Immobilieninformationen einzeln auf der Webseite sehen finden Sie:
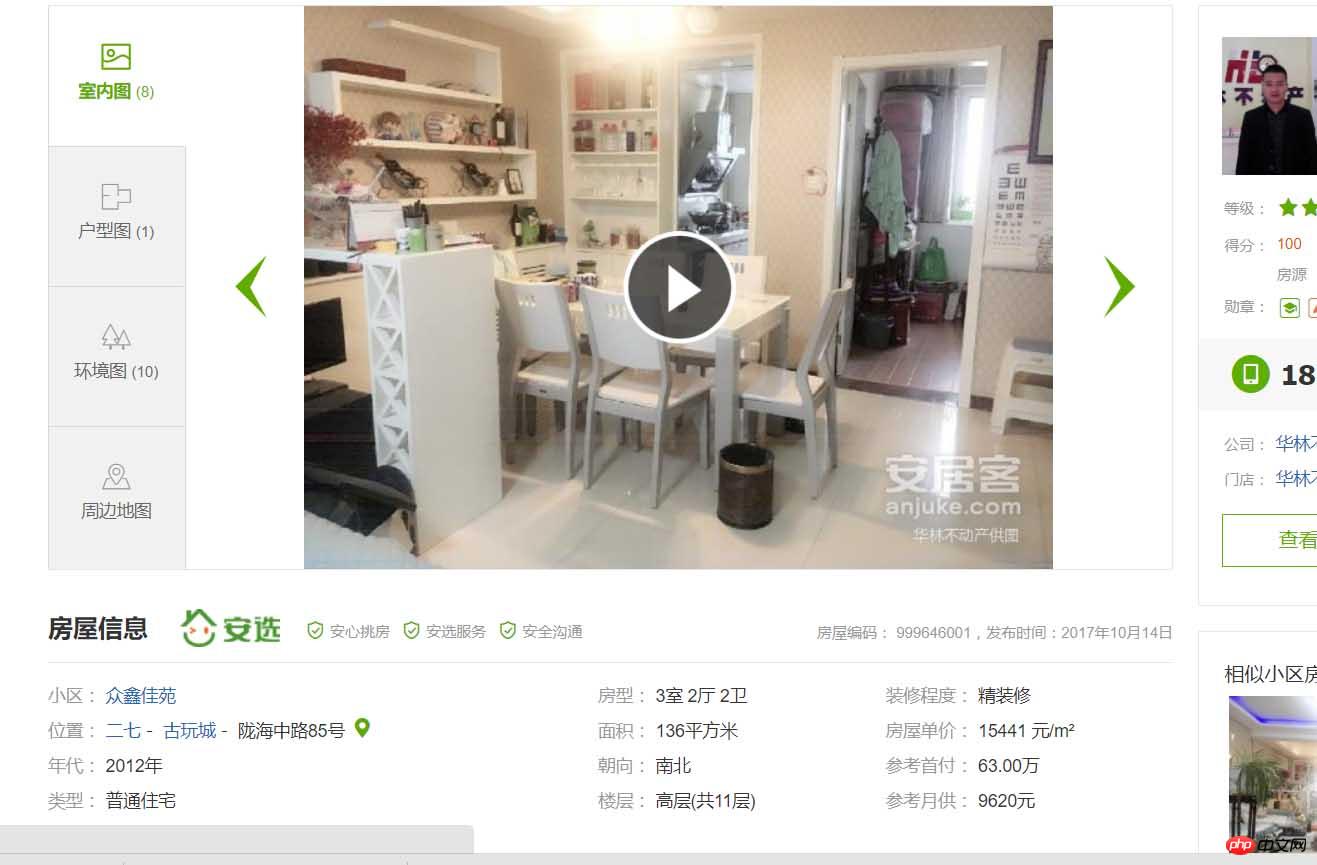
Details zur Immobilie. OK! Was werden wir also tun? Das heißt, alle Informationen zu Gebrauchtwohnungen in Zhengzhou abzurufen und sie in der Datenbank zu speichern. Als Geograph werde ich noch nicht näher darauf eingehen Diesmal. Okay, fangen wir offiziell an. Zuerst verwende ich die Module „Requests“ und „BeautifulSoup“ zum Crawlen der Seite:
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
response = requests.get(url, headers=header)
print(response.text)Ausführung Dann erhalten Sie den HTML-Code dieser Website
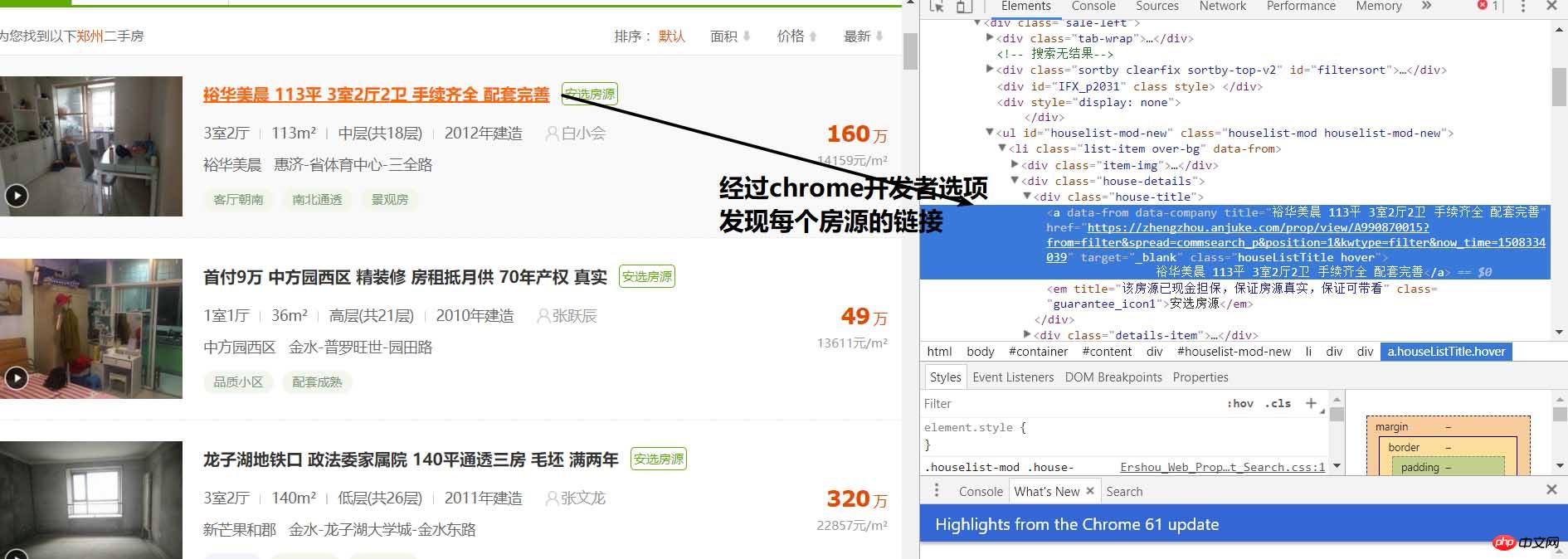
 Durch Analyse können wir feststellen, dass sich jedes Haus im li-Tag von class="list-item" befindet. , dann können wir es gemäß BeautifulSoup verwenden. Durch Extrahieren des Pakets
Durch Analyse können wir feststellen, dass sich jedes Haus im li-Tag von class="list-item" befindet. , dann können wir es gemäß BeautifulSoup verwenden. Durch Extrahieren des Pakets
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
for i in result_li:
print(i)kann die Codemenge durch Drucken weiter reduziert werden. Okay, extrahieren Sie weiter
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
print(result_href.attrs['href']) Auf diese Weise können wir die URLs einzeln sehen 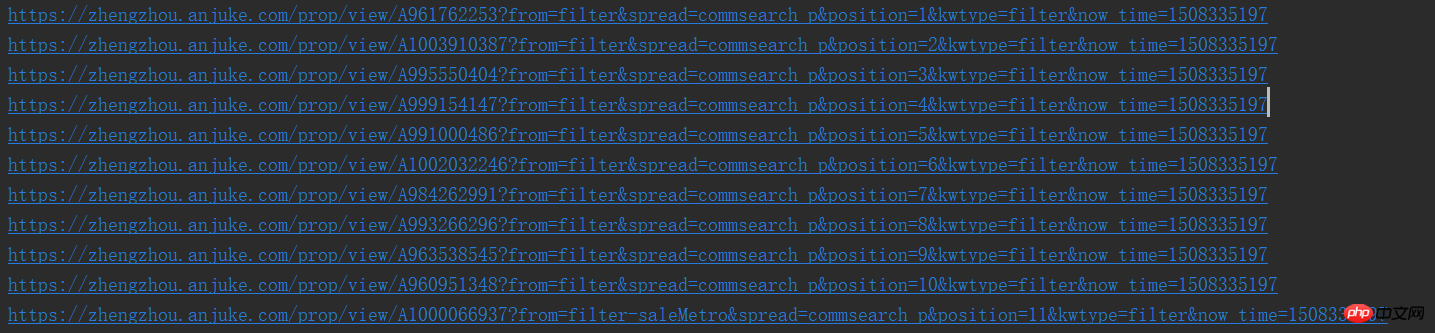
Okay, nach normaler Logik, wir Wir müssen die Seite aufrufen und mit der Analyse der detaillierten Seite beginnen, aber nach dem Crawlen müssen wir zunächst analysieren, ob die Seite eine nächste Seite hat
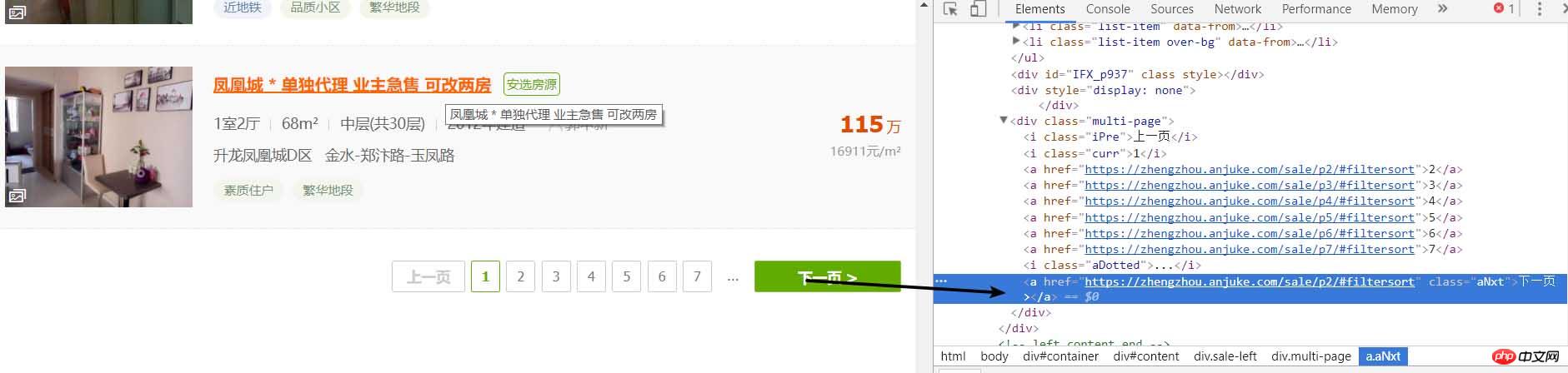
Auf die gleiche Weise können wir feststellen, dass die nächste Seite auch so einfach ist, dass wir mit dem Originalrezept und dem Originalgeschmack fortfahren können
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
print(result_next_page[0].attrs['href'])
else:
print('没有下一页了')Denn wann Es gibt die nächste Seite, es gibt ein a-Tag auf der Webseite. Wenn nicht, wird es zu einem i-Tag, also können wir es verbessern und das Obige in eine Funktion kapseln
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 先不做分析,等一会进行详细页面函数完成后进行调用
print(result_href.attrs['href'])
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)Okay, dann fangen wir an, die detaillierten Seiten zu crawlen
Hey, der Strom wird auf Schritt und Tritt abgeschaltet, was für eine Falle in der Universität, ich‘ Ich hänge zuerst die Ergebnisse an, ich füge weitere hinzu, wenn ich Zeit habe,
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup_idex = BeautifulSoup(response.text, 'html.parser')
result_li = soup_idex.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 详细页面的函数调用
get_page_detail(result_href.attrs['href'])
# 进行下一页的爬取
result_next_page = soup_idex.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行字符串中空格,换行,tab键的替换及删除字符串两边的空格删除
def my_strip(s):
return str(s).replace(" ", "").replace("\n", "").replace("\t", "").strip()
# 由于频繁进行BeautifulSoup的使用,封装一下,很鸡肋
def my_Beautifulsoup(response):
return BeautifulSoup(str(response), 'html.parser')
# 详细页面的爬取
def get_page_detail(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 标题什么的一大堆,哈哈
result_title = soup.find_all('h3', {'class': 'long-title'})[0]
result_price = soup.find_all('span', {'class': 'light info-tag'})[0]
result_house_1 = soup.find_all('p', {'class': 'first-col detail-col'})
result_house_2 = soup.find_all('p', {'class': 'second-col detail-col'})
result_house_3 = soup.find_all('p', {'class': 'third-col detail-col'})
soup_1 = my_Beautifulsoup(result_house_1)
soup_2 = my_Beautifulsoup(result_house_2)
soup_3 = my_Beautifulsoup(result_house_3)
result_house_tar_1 = soup_1.find_all('dd')
result_house_tar_2 = soup_2.find_all('dd')
result_house_tar_3 = soup_3.find_all('dd')
'''
文博公寓,省实验中学,首付只需70万,大三房,诚心卖,价可谈 270万
宇泰文博公寓 金水-花园路-文博东路4号 2010年 普通住宅
3室2厅2卫 140平方米 南北 中层(共32层)
精装修 19285元/m² 81.00万
'''
print(my_strip(result_title.text), my_strip(result_price.text))
print(my_strip(result_house_tar_1[0].text),
my_strip(my_Beautifulsoup(result_house_tar_1[1]).find_all('p')[0].text),
my_strip(result_house_tar_1[2].text), my_strip(result_house_tar_1[3].text))
print(my_strip(result_house_tar_2[0].text), my_strip(result_house_tar_2[1].text),
my_strip(result_house_tar_2[2].text), my_strip(result_house_tar_2[3].text))
print(my_strip(result_house_tar_3[0].text), my_strip(result_house_tar_3[1].text),
my_strip(result_house_tar_3[2].text))
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)Da ich beim Bloggen Code geschrieben habe, habe ich einige Änderungen an der get_page vorgenommen Funktion, das heißt, der rekursive Aufruf für die nächste Seite muss nach der Funktion platziert und gekapselt werden. Die beiden Funktionen werden nicht eingeführt,
und die Daten werden nicht in MySQL geschrieben, daher werde ich weiterverfolgen Später danke!!!
Verwandte Empfehlungen:
Beispiel-Tutorial für Python-Crawling-Artikel
10 empfohlene Artikel über Python Crawling
Teilen eines Python-Crawlings So machen Sie beliebte Kommentare zu NetEase Cloud Music
Das obige ist der detaillierte Inhalt vonPython-Crawling-Methode für den Datenaustausch auf Anjuke-Gebrauchtwohnungswebsites. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!