
Heim >Backend-Entwicklung >Python-Tutorial >Am Beispiel des Erfassens von Taobao-Kommentaren wird erläutert, wie Python von Ajax dynamisch generierte Daten crawlt (klassisch).
Am Beispiel des Erfassens von Taobao-Kommentaren wird erläutert, wie Python von Ajax dynamisch generierte Daten crawlt (klassisch).

- 不言Original
- 2018-04-18 11:14:434070Durchsuche
Wenn Sie Python lernen, werden Sie definitiv auf die Situation stoßen, dass der Website-Inhalt JSON-Daten sind, die durch dynamische Ajax-Anforderung und asynchrone Aktualisierung generiert werden, und die vorherige Methode zum Crawlen statischer Webinhalte durch Python nicht möglich ist. Daher wird dieser Artikel beschrieben So crawlen Sie von Ajax dynamisch generierte Daten in Python.
Wenn Sie Python lernen, werden Sie definitiv auf die Situation stoßen, dass der Website-Inhalt JSON-Daten sind, die durch dynamische Ajax-Anforderungen und asynchrone Aktualisierungen generiert werden, und die vorherige Methode zum Crawlen statischer Webinhalte durch Python nicht möglich ist In diesem Artikel wird beschrieben, wie von Ajax dynamisch generierte Daten in Python gecrawlt werden.
Was das Lesen statischer Webinhalte betrifft, können Interessierte den Inhalt dieses Artikels überprüfen.
Hier nehmen wir das Crawlen von Taobao-Kommentaren als Beispiel, um zu erklären, wie das geht.
Dies ist hauptsächlich in vier Schritte unterteilt:
Wenn Sie Taobao-Bewertungen erhalten, fordert Ajax den Link (URL) an
2. Rufen Sie die von der Ajax-Anfrage zurückgegebenen JSON-Daten ab
3. Verwenden Sie Python, um die JSON-Daten zu analysieren
Vier Speichern Sie die analysierten Ergebnisse
Schritt 1:
Wenn Sie Taobao-Kommentare erhalten, ajax Anforderungslink (URL) Hier verwende ich zum Vervollständigen den Chrome-Browser. Öffnen Sie den Taobao-Link und suchen Sie im Suchfeld nach einem Produkt, z. B. „Schuhe“. Hier wählen wir das erste Produkt aus.

Dann wird zu einer neuen Webseite gesprungen. Da wir hier Benutzerbewertungen crawlen müssen, klicken wir auf „Akkumulierte Bewertungen“.

Dann können wir die Bewertung des Produkts durch den Benutzer sehen. Zu diesem Zeitpunkt klicken wir mit der rechten Maustaste auf die Webseite und wählen das Bewertungselement aus (oder öffnen es direkt mit F12). ) und wählen Sie Netzwerkoptionen aus, wie im Bild gezeigt:
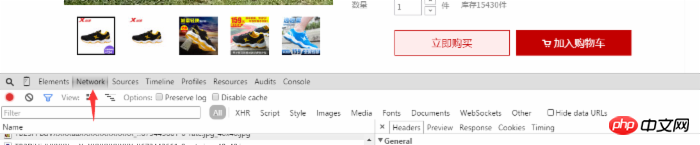
In den Benutzerkommentaren scrollen wir nach unten und klicken auf die nächste Seite oder die zweite Seite, die wir sehen Bei mehreren dynamischen Ergänzungen im Netzwerkelement wählen wir das Element aus, das mit list_detail_rate.htm?itemId=35648967399 beginnt.

Dann klicken Sie auf diese Option. Wir können die Informationen zum Link im rechten Optionsfeld sehen. Wir möchten den Linkinhalt in die Anforderungs-URL kopieren.

Wir geben den URL-Link, den wir gerade erhalten haben, in die Adressleiste des Browsers ein. Nach dem Öffnen werden wir feststellen, dass die Seite die von uns benötigten Daten zurückgibt, aber sie sieht aus Sehr chaotisch. Weil es sich um JSON-Daten handelt.

Zweitens: Holen Sie sich die von der Ajax-Anfrage zurückgegebenen JSON-Daten.
Als nächstes müssen wir abrufen die URL-JSON-Daten in. Der Python-Editor, den ich verwende, ist Pycharm. Schauen wir uns den Python-Code an:
# -*- coding: utf-8 -*- import sys reload(sys) sys.setdefaultencoding('utf-8') import requests url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143' #这里的url比较长 content=requests.get(url).content
Inhalt drucken #Der gedruckte Inhalt ist der, auf dem wir zuvor gedruckt haben die Webseite Die erhaltenen JSON-Daten. Fügen Sie Benutzerkommentare hinzu.
Der Inhalt hier sind die JSON-Daten, die wir benötigen. Der nächste Schritt besteht darin, diese JSON-Daten zu analysieren.
3 Verwenden Sie Python, um JSON-Daten zu analysieren
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requests
import json
import re
url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143'
cont=requests.get(url).content
rex=re.compile(r'\w+[(]{1}(.*)[)]{1}')
content=rex.findall(cont)[0]
con=json.loads(content,"gbk")
count=len(con['rateDetail']['rateList'])
for i in xrange(count):
print con['rateDetail']['rateList'][i]['appendComment']['content']

Analyse:
Hier müssen Sie das erforderliche Paket importieren, re ist das für reguläre Ausdrücke erforderliche Paket, und um JSON-Daten zu analysieren, müssen Sie json importieren
cont=requests .get(url).content #Holen Sie sich die JSON-Daten auf der Webseite
rex=re.compile(r'w+[(]{1}(.*)[)]{1}') # Regulärer Ausdruck zum Entfernen des redundanten Teils der Inhaltsdaten. Die Daten werden zu echten Daten im JSON-Format {"a": "b", "c": "d"}
con=json.loads(content, „gbk“) Verwenden Sie die Ladefunktion von JSON. Konvertieren Sie den Inhalt in ein Datenformat, das von der JSON-Bibliotheksfunktion verarbeitet werden kann. Da das Win-System standardmäßig gbk ist count=len(con['rateDetail']['rateList'] ) #Erhalten Sie die Anzahl der Benutzerkommentare (hier gilt nur für die aktuelle Seite)
für i in xrange(count):
print con['rateDetail']['rateList'][i] ['appendComment']
# Durchlaufen Sie Benutzerkommentare und -ausgaben (Sie können die Daten auch entsprechend Ihren Anforderungen speichern und überprüfen der vierte Teil)
Die Schwierigkeit besteht hier darin, es im unordentlichen JSON-Datenpfad zu Benutzerkommentaren zu finden
4. Speichern Sie die analysierten Ergebnisse
Hier kann der Benutzer die Kommentarinformationen des Benutzers lokal speichern, beispielsweise im CSV-Format.
Das ist alles in diesem Artikel, ich hoffe, er gefällt euch allen.
Das obige ist der detaillierte Inhalt vonAm Beispiel des Erfassens von Taobao-Kommentaren wird erläutert, wie Python von Ajax dynamisch generierte Daten crawlt (klassisch).. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!