
Heim >Technologie-Peripheriegeräte >KI >Hochbewerteter Beitrag von COLM, der ersten großen Modellkonferenz: Der Präferenzsuchalgorithmus PairS macht die Textauswertung großer Modelle effizienter
Hochbewerteter Beitrag von COLM, der ersten großen Modellkonferenz: Der Präferenzsuchalgorithmus PairS macht die Textauswertung großer Modelle effizienter

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-08-05 14:31:52950Durchsuche

AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com, zhaoyunfeng@jiqizhixin.com
기사의 저자는 모두 케임브리지 대학의 언어 기술 연구소 출신입니다. 그 중 한 명은 박사 과정 3년차 학생인 Liu Yinhong과 그의 지도교수입니다. Nigel Collier 교수와 Ehsan Shareghi 교수가 있습니다. 그의 연구 관심 분야는 대형 모델 및 텍스트 평가, 데이터 생성 등입니다. Tongyi의 박사과정 2년차인 Zhou Han은 Anna Korhonen 교수와 Ivan Vulić 교수의 지도를 받고 있습니다. 그의 연구 관심 분야는 효율적인 대형 모델입니다.
대형 모델은 뛰어난 명령 따르기 및 작업 일반화 기능을 보여줍니다. 이 독특한 능력은 LLM 교육에서 명령 따르기 데이터와 인간 피드백 강화 학습(RLHF)을 사용하여 비롯됩니다. RLHF 훈련 패러다임에서 보상 모델은 순위 비교 데이터를 기반으로 인간의 선호도에 맞춰 조정됩니다. 이는 LLM과 인간 가치의 정렬을 향상시켜 인간을 더 잘 지원하고 인간 가치를 준수하는 응답을 생성합니다.
최근 첫 번째 대규모 모델 컨퍼런스인 COLM에서 높은 점수를 받은 작품 중 하나가 LLM을 텍스트 평가자로 사용할 때 피하고 수정하기 어려운 점수 편향 문제를 분석하고 이를 변환하도록 제안했습니다. 평가 문제를 선호도 순위 문제로 변환하여 쌍별 선호도를 검색하고 정렬할 수 있는 알고리즘인 pairS 알고리즘을 설계했습니다. 불확실성과 LLM 전이성의 가정을 활용함으로써 pairS는 효율적이고 정확한 선호도 순위를 제공하고 여러 테스트 세트에 대한 인간의 판단과 더 높은 일관성을 보여줄 수 있습니다.

논문 링크: https://arxiv.org/abs/2403.16950
논문 제목: Aligning with Human Judgment: The Role of pairwise Preference in Large Language Model Evaluators
Github 주소: https://github.com/cambridgeltl/PairS
대형 모델 평가의 문제점은 무엇인가요?
많은 최근 연구에서 텍스트 품질 평가에서 LLM의 탁월한 성능이 입증되었으며, 생성 작업에 대한 참조 없는 평가를 위한 새로운 패러다임을 형성하고 값비싼 인적 주석 비용을 피했습니다. 그러나 LLM 평가자는 신속한 설계에 매우 민감하며 위치 편향, 장황 편향, 맥락 편향 등 다양한 편향의 영향을 받을 수도 있습니다. 이러한 편견으로 인해 LLM 평가자가 공정하고 신뢰할 수 없게 되어 인간의 판단과 불일치 및 불일치가 발생합니다.
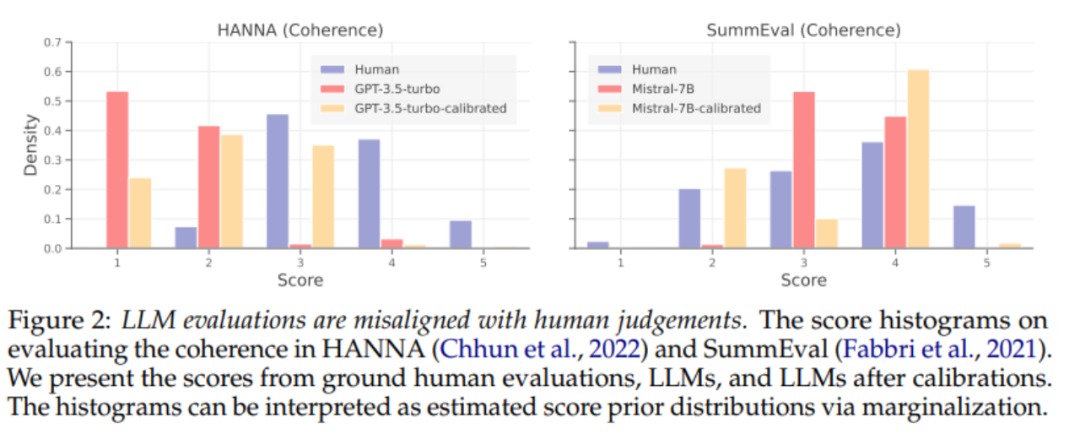
LLM의 편향된 예측을 줄이기 위해 이전 작업에서는 LLM 예측의 편향을 줄이는 교정 기술을 개발했습니다. 먼저 점별 LLM 추정기를 정렬할 때 교정 기술의 효율성에 대한 체계적인 분석을 수행합니다. 위의 그림 2에서 볼 수 있듯이 기존 교정 방법은 감독 데이터가 제공되는 경우에도 여전히 LLM 추정기를 제대로 정렬하지 못합니다.
공식 1에서 보듯이, 평가가 어긋나는 주된 원인은 LLM의 평가 점수 분포에 대한 편향된 사전이 아니라 평가 기준, 즉 LLM 평가자의 어긋남에 있다고 생각합니다. 우도(Likelihood) . 우리는 LLM 평가자가 쌍별 평가를 수행할 때 인간과 보다 일관된 평가 기준을 갖게 될 것이라고 믿기 때문에 보다 일치된 판단을 촉진하기 위해 새로운 LLM 평가 패러다임을 탐구합니다.

RLHF에서 가져온 영감
아래 그림 1에서 볼 수 있듯이 RLHF의 선호도 데이터를 통한 보상 모델 정렬에서 영감을 받아 선호도 순위를 생성하여 LLM 평가자를 얻을 수 있다고 믿습니다. -정렬된 예측. 최근 일부 연구에서는 LLM에 쌍별 비교를 수행하도록 요청하여 선호도 순위를 얻기 시작했습니다. 그러나 선호도 순위의 복잡성과 확장성을 평가하는 것은 크게 간과되었습니다. 그들은 전이성 가정을 무시하여 비교 횟수를 O(N^2)로 만들어 평가 프로세스를 비용이 많이 들고 실행 불가능하게 만듭니다.
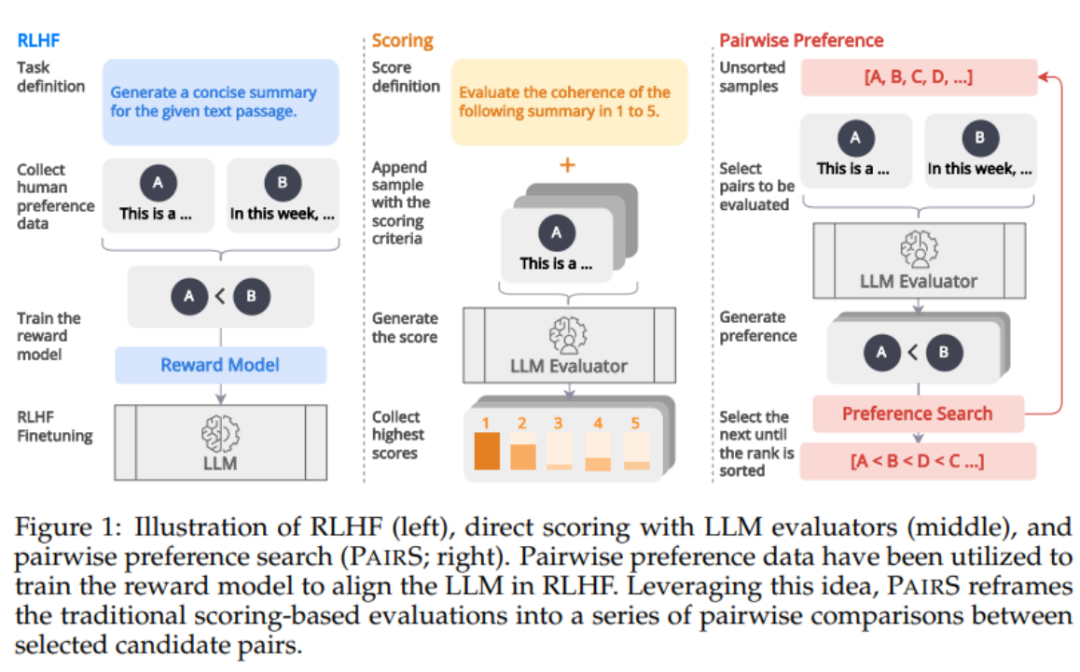
PairS: Effizienter Präferenzsuchalgorithmus
In dieser Arbeit schlagen wir zwei paarweise Präferenzsuchalgorithmen vor (PairS-greedy und PairS-beam). PairS-greedy ist ein Algorithmus, der auf der Annahme einer vollständigen Transitivität und einer Zusammenführungssortierung basiert und eine globale Präferenzsortierung mit nur einer Komplexität von O (NlogN) erhalten kann. Die Transitivitätsannahme bedeutet, dass LLM beispielsweise für drei Kandidaten immer gilt, wenn A≻B und B≻C, dann A≻C. Unter dieser Annahme können wir traditionelle Ranking-Algorithmen direkt verwenden, um Präferenzrankings aus paarweisen Präferenzen zu erhalten.
Aber LLM hat keine perfekte Transitivität, deshalb haben wir den PairS-Beam-Algorithmus entwickelt. Unter der lockereren Transitivitätsannahme leiten und vereinfachen wir die Wahrscheinlichkeitsfunktion für das Präferenzranking. PairS-beam ist eine Suchmethode, die eine Strahlsuche basierend auf dem Wahrscheinlichkeitswert in jeder Zusammenführungsoperation des Zusammenführungssortierungsalgorithmus durchführt und den paarweisen Vergleichsraum durch die Unsicherheit der Präferenzen reduziert. PairS-beam kann die Kontrastkomplexität und die Rankingqualität anpassen und effizient die Maximum-Likelihood-Schätzung (MLE) des Präferenzrankings bereitstellen. In Abbildung 3 unten zeigen wir ein Beispiel dafür, wie PairS-beam einen Zusammenführungsvorgang durchführt.
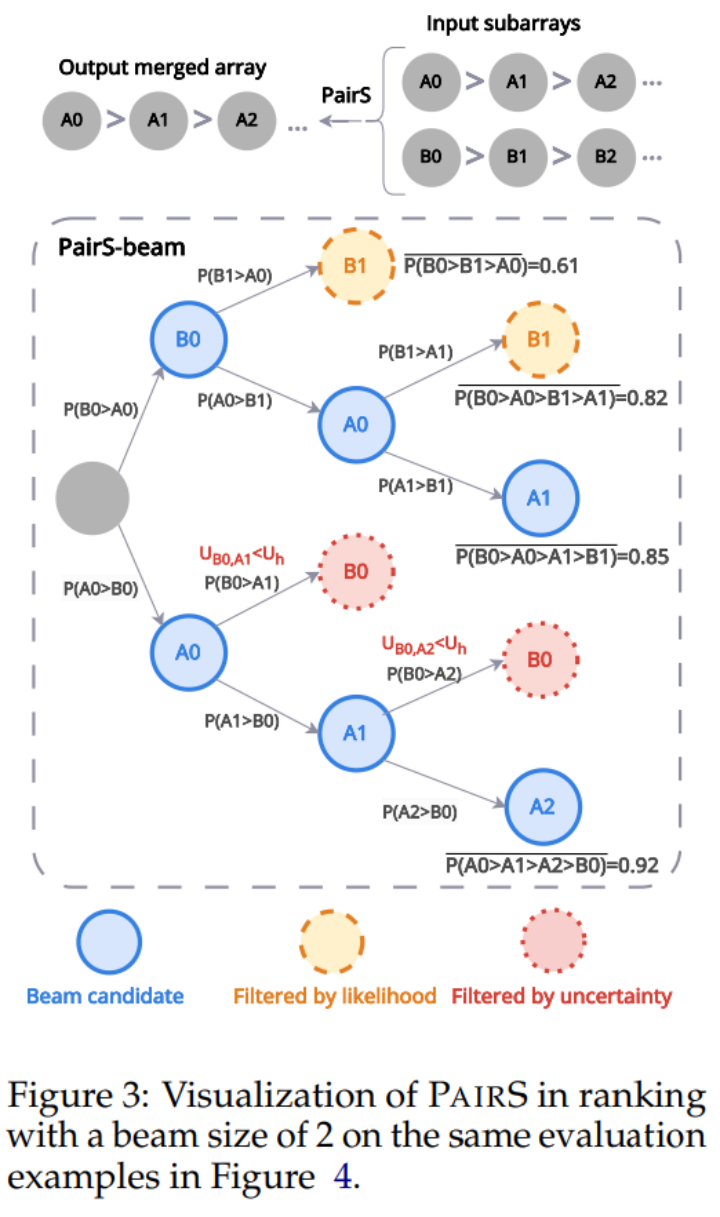
Experimentelle Ergebnisse
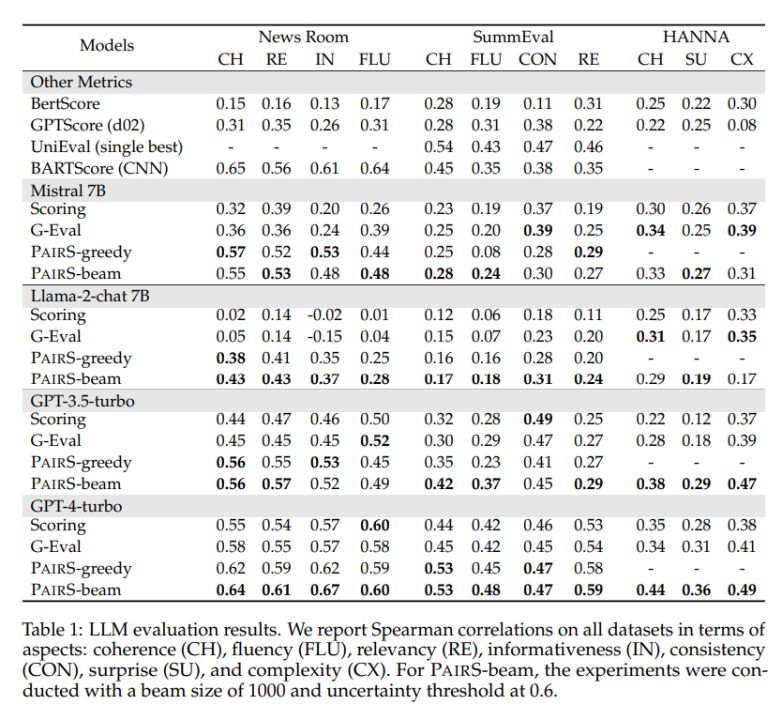
Wir haben mehrere repräsentative Datensätze getestet, darunter die geschlossenen Abkürzungsaufgaben NewsRoom und SummEval sowie die offene Story-Generierungsaufgabe HANNA, und mehrere Baseline-Methoden für LLM-Einzelpunkt verglichen Bewertung, einschließlich unbeaufsichtigter direkter Bewertung, G-Eval, GPTScore und überwachtem Training UniEval und BARTScore. Wie in Tabelle 1 unten gezeigt, weist PairS bei jeder Aufgabe eine höhere Übereinstimmung mit menschlichen Bewertungen auf als sie. GPT-4-Turbo kann sogar SOTA-Effekte erzielen.
In dem Artikel haben wir auch zwei Basismethoden für Präferenzranking, Gewinnrate und ELO-Bewertung verglichen. PairS kann mit nur etwa 30 % der Anzahl der Vergleiche das gleiche Qualitätspräferenzranking erreichen. Das Papier liefert außerdem weitere Einblicke, wie paarweise Präferenzen zur quantitativen Berechnung der Transitivität von LLM-Schätzern verwendet werden können und wie paarweise Schätzer von der Kalibrierung profitieren können.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonHochbewerteter Beitrag von COLM, der ersten großen Modellkonferenz: Der Präferenzsuchalgorithmus PairS macht die Textauswertung großer Modelle effizienter. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr