Im Dezember letzten Jahres brachte die neue Architektur Mamba den KI-Kreis zum Explodieren und stellte eine Herausforderung für den ewigen Transformer dar. Der heutige Start von Google DeepMind „Hawk“ und „Griffin“ bietet neue Optionen für den KI-Kreis.
Dieses Mal hat Google DeepMind neue Schritte in Bezug auf Grundmodelle unternommen. Wir wissen, dass rekurrente neuronale Netze (RNN) in den Anfängen der Deep-Learning- und Natural-Language-Processing-Forschung eine zentrale Rolle spielten und in vielen Anwendungen praktische Ergebnisse erzielt haben, darunter auch Googles erstes durchgängiges maschinelles Übersetzungssystem . In den letzten Jahren wurden Deep Learning und NLP jedoch von der Transformer-Architektur dominiert, die Multi-Layer-Perceptron (MLP) und Multi-Head-Attention (MHA) kombiniert. Transformer hat in der Praxis eine bessere Leistung als RNN erzielt und ist außerdem sehr effizient bei der Nutzung moderner Hardware. Transformer-basierte große Sprachmodelle werden mit bemerkenswertem Erfolg auf riesigen, aus dem Internet gesammelten Datensätzen trainiert. Obwohl die Transformer-Architektur große Erfolge erzielt hat, weist sie immer noch Mängel auf. Aufgrund der quadratischen Komplexität der globalen Aufmerksamkeit ist es beispielsweise schwierig, Transformer effektiv auf lange Sequenzen auszudehnen. Darüber hinaus wächst der Schlüsselwert-Cache (KV) linear mit der Sequenzlänge, was dazu führt, dass Transformer während der Inferenz langsamer wird. An diesem Punkt werden wiederkehrende Sprachmodelle zu einer Alternative. Sie können die gesamte Sequenz in einen verborgenen Zustand fester Größe komprimieren und iterativ aktualisieren. Doch wenn es Transformer ablösen will, muss das neue RNN-Modell nicht nur eine vergleichbare Leistung bei der Skalierung zeigen, sondern auch eine ähnliche Hardware-Effizienz erreichen. In einem aktuellen Artikel von Google DeepMind schlugen Forscher die RG-LRU-Schicht vor, bei der es sich um eine neuartige Gated-Linear-Loop-Schicht handelt, und entwarfen um sie herum einen neuen Schleifenblock, um Multi-Query Attention (MQA) zu ersetzen. Sie haben diesen Loop-Block verwendet, um zwei neue Modelle zu bauen: Eines ist das Modell Hawk, das MLP- und Loop-Blöcke mischt, Das andere ist das Modell Griffin, das MLP mit Loop-Blöcken und lokaler Aufmerksamkeit mischt. 
- Papiertitel: Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
- Papierlink: https://arxiv.org/pdf/2402.19427.pdf
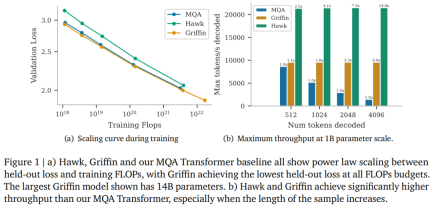
Die Forscher sagen, dass Hawk und Griffin eine Potenzgesetzsskalierung zwischen ausgehaltenem Verlust und Trainings-FLOPs von bis zu 7B Parametern aufweisen, wie sie zuvor bei Transformers beobachtet wurde. Unter anderem erreicht Griffin bei allen Modellgrößen einen etwas geringeren Dauerverlust als die leistungsstarke Transformer-Basislinie.
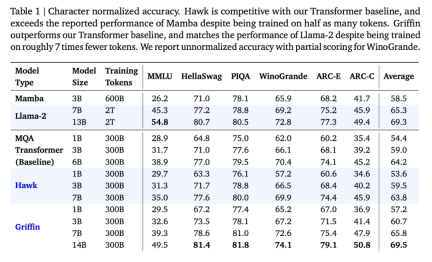
Die Forscher haben Hawk und Griffin mit 300B-Tokens für eine Reihe von Modellgrößen übertrainiert. Die Ergebnisse zeigten, dass Hawk-3B Mamba-3B bei der Leistung nachgelagerter Aufgaben übertraf, obwohl die Anzahl der trainierten Token nur halb so hoch war letztere. Griffin-7B und Griffin-14B weisen eine vergleichbare Leistung wie Llama-2 auf, obwohl sie nur mit einem Siebtel der Anzahl an Token trainiert werden. Darüber hinaus erreichten Hawk und Griffin auf TPU-v3 eine mit Transformers vergleichbare Trainingseffizienz. Da die diagonale RNN-Schicht speicherbeschränkt ist, nutzten die Forscher den Kernel der RG-LRU-Schicht, um dies zu erreichen. Auch während der Inferenz erzielen sowohl Hawk als auch Griffin einen höheren Durchsatz als MQA Transformer und eine geringere Latenz beim Abtasten langer Sequenzen. Griffin schneidet besser ab als Transformers, wenn die ausgewerteten Sequenzen länger sind als die im Training beobachteten, und kann Kopier- und Abrufaufgaben effektiv aus den Trainingsdaten erlernen. Als die vorab trainierten Modelle jedoch bei Kopier- und exakten Abrufaufgaben ohne Feinabstimmung bewertet wurden, schnitten Hawk und Griffin schlechter ab als Transformers. Co-Autor und DeepMind-Forscher Aleksandar Botev sagte, dass Griffin, ein Modell, das geschlossene lineare Schleifen und lokale Aufmerksamkeit kombiniert, alle hocheffizienten Vorteile von RNN und die Ausdrucksfähigkeiten von Transformer beibehält und erweitert werden kann bis 14B Parameterskala. SeitGriffin Model ArchitectureGriffin Alle Modelle enthalten die folgenden Komponenten: (i) einen Restblock, (ii) einen MLP-Block, (iii) einen zeitlichen Mischblock. (i) und (ii) sind für alle Modelle gleich, es gibt jedoch drei zeitliche Mischblöcke: globale Multi-Query-Aufmerksamkeit (MQA), lokale (Schiebefenster) MQA und der in diesem Artikel vorgeschlagene wiederkehrende Block. Als Teil des wiederkehrenden Blocks verwendeten die Forscher eine Really Gated Linear Recurrent Unit (RG-LRU), eine neue wiederkehrende Schicht, die von linearen wiederkehrenden Einheiten inspiriert ist. Wie in Abbildung 2(a) dargestellt, definiert der Restblock die globale Struktur des Griffin-Modells, das vom VornormTransformer inspiriert ist. Nach dem Einbetten der Eingabesequenz leiten wir sie durch Blöcke wie ? (? stellt die Modelltiefe dar) und wenden dann RMSNorm an, um die endgültigen Aktivierungen zu generieren. Zur Berechnung der Token-Wahrscheinlichkeiten wird eine abschließende lineare Schicht angewendet, gefolgt von Softmax. Die Gewichte dieser Ebene werden mit der Eingabeeinbettungsebene geteilt.
Rekurrentes Modell, Skalierungseffizienz vergleichbar mit Transformer Skalierungsforschung liefert wichtige Erkenntnisse darüber, wie die Hyperparameter des Modells und sein Verhalten bei der Skalierung angepasst werden können. Die Forscher definierten die in dieser Studie bewerteten Modelle, lieferten Skalierungskurven bis zu 7B-Parametern und darüber hinaus und bewerteten die Modellleistung bei nachgelagerten Aufgaben. Sie betrachteten drei Modellfamilien: (1) MQA-Transformer-Basislinie; (2) Hawk: ein reines RNN-Modell; (3) Griffin: ein Hybridmodell, das wiederkehrende Blöcke mit lokaler Aufmerksamkeit mischt. Wichtige Modellhyperparameter für Modelle unterschiedlicher Größe sind in Anhang C definiert. Die Hawk-Architektur verwendet das gleiche Restmuster und den gleichen MLP-Block wie die Transformer-Basislinie, aber die Forscher verwendeten anstelle von MQA einen wiederkehrenden Block mit einer RG-LRU-Schicht als zeitlichen Mischblock. Sie erweiterten die Breite des Schleifenblocks um einen Faktor von etwa 4/3 (d. h. ?_??? ≈4?/3), um ungefähr der Anzahl der Parameter des MHA-Blocks zu entsprechen, wenn beide die gleiche Modelldimension ? verwenden. Griffin. Der Hauptvorteil wiederkehrender Blöcke im Vergleich zur globalen Aufmerksamkeit besteht darin, dass sie eine feste Zustandsgröße zum Zusammenfassen von Sequenzen verwenden, während die KV-Cache-Größe von MQA proportional zur Sequenzlänge wächst. Lokale Aufmerksamkeit hat die gleichen Eigenschaften, und durch die Mischung wiederkehrender Blöcke mit lokaler Aufmerksamkeit bleibt dieser Vorteil erhalten. Die Forscher fanden diese Kombination äußerst effizient, da die lokale Aufmerksamkeit die jüngste Vergangenheit genau modellieren kann, während wiederkehrende Schichten Informationen über lange Sequenzen vermitteln können. Griffin verwendet das gleiche Restmuster und die gleichen MLP-Blöcke wie die Transformer-Basislinie. Aber im Gegensatz zur MQA Transformer-Basislinie und dem Hawk-Modell verwendet Griffin eine Mischung aus Schleifenblöcken und MQA-Blöcken. Konkret verwenden wir eine hierarchische Struktur, die zwei Restblöcke mit einem wiederkehrenden Block und dann einem lokalen (MQA) Aufmerksamkeitsblock abwechselt. Sofern nicht anders angegeben, ist die Größe des lokalen Aufmerksamkeitsfensters auf 1024 Token festgelegt. Die wichtigsten Skalierungsergebnisse sind in Abbildung 1(a) dargestellt. Alle drei Modellfamilien wurden auf Modellgrößen im Bereich von 100 Millionen bis 7 Milliarden Parametern trainiert, obwohl Griffin über eine Version mit 14 Milliarden Parametern verfügt. Die Bewertungsergebnisse von zu nachgelagerten Aufgaben sind in Tabelle 1 dargestellt:
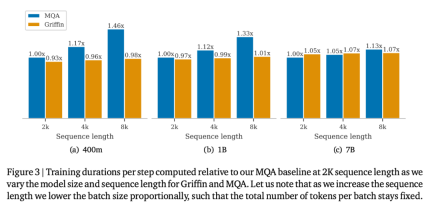
Hawk und Griffin haben beide wirklich gut gespielt. Die obige Tabelle zeigt die merkmalsnormalisierte Genauigkeit für MMLU, HellaSwag, PIQA, ARC-E und ARC-C, während die absolute Genauigkeit und Teilwerte für WinoGrande angegeben werden. Mit zunehmender Größe des Modells verbessert sich auch die Leistung von Hawk erheblich, und Hawk-3B schneidet bei nachgelagerten Aufgaben besser ab als Mamba-3B, obwohl die Anzahl der trainierten Token nur halb so hoch ist wie die von Mamba-3B. Griffin-3B schneidet deutlich besser ab als Mamba-3B, und Griffin-7B und Griffin-14B schneiden vergleichbar mit Llama-2 ab, obwohl sie mit fast 7x weniger Token trainiert werden. Hawk ist mit der MQA Transformer-Basislinie vergleichbar, während Griffin diese übertrifft. Effizientes Trainieren des Schleifenmodells auf der GeräteseiteBei der Entwicklung und Erweiterung des Modells stießen die Forscher auf zwei große technische Herausforderungen. Erstens, wie man Verarbeitungsmodelle effizient auf mehrere Geräte verteilt. Zweitens, wie man lineare Schleifen effektiv implementiert, um die Effizienz des TPU-Trainings zu maximieren. In diesem Artikel werden diese beiden Herausforderungen erörtert und anschließend ein empirischer Vergleich der Trainingsgeschwindigkeit von Griffin- und MQA-Basislinien bereitgestellt. Die Forscher verglichen die Trainingsgeschwindigkeiten verschiedener Modellgrößen und Sequenzlängen, um die Rechenvorteile des Modells in diesem Artikel während des Trainingsprozesses zu untersuchen. Die Gesamtzahl der Token pro Stapel wird für jede Modellgröße konstant gehalten, was bedeutet, dass mit zunehmender Sequenzlänge die Anzahl der Sequenzen proportional abnimmt. Abbildung 3 zeigt die relative Laufzeit des Griffin-Modells im Vergleich zum MQA-Basismodell bei 2048 Sequenzlängen.
Die Inferenz von LLM besteht aus zwei Stufen. In der „Prefill“-Phase werden Eingabeaufforderungen empfangen und verarbeitet. Dieser Schritt führt tatsächlich einen Vorwärtsdurchlauf des Modells durch. Da Eingabeaufforderungen während der gesamten Sequenz parallel verarbeitet werden können, sind die meisten Modelloperationen in dieser Phase rechnerisch gebunden. Daher erwarten wir, dass die relative Geschwindigkeit von Transformern und Schleifenmodellen in der Vorbelegungsphase mit den zuvor besprochenen relativen Geschwindigkeiten übereinstimmt während des Trainings waren ähnlich. Nach der Vorpopulation folgt die Dekodierungsphase, in der der Forscher autoregressiv Token aus dem Modell extrahiert. Wie unten gezeigt, weist das wiederkehrende Modell insbesondere bei längeren Sequenzlängen, bei denen der in der Aufmerksamkeit verwendete Schlüsselwert-Cache (KV) groß wird, eine geringere Latenz und einen höheren Durchsatz in der Dekodierungsphase auf. Bei der Bewertung der Inferenzgeschwindigkeit sind zwei Hauptmetriken zu berücksichtigen. Die erste ist die Latenz, die die Zeit misst, die erforderlich ist, um eine bestimmte Anzahl von Tokens bei einer bestimmten Stapelgröße zu generieren. Der zweite ist der Durchsatz, der die maximale Anzahl an Token misst, die pro Sekunde generiert werden können, wenn eine bestimmte Anzahl an Token auf einem einzelnen Gerät abgetastet wird. Da der Durchsatz als Anzahl der abgetasteten Token multipliziert mit der Batch-Größe dividiert durch die Latenz berechnet wird, können Sie den Durchsatz erhöhen, indem Sie die Latenz reduzieren oder die Speichernutzung reduzieren, um eine größere Batch-Größe auf dem Gerät zu verwenden. Die Berücksichtigung der Latenz ist für Echtzeitanwendungen nützlich, die schnelle Reaktionszeiten erfordern. Auch der Durchsatz ist eine Überlegung wert, da er uns die maximale Anzahl an Token angibt, die von einem bestimmten Modell in einer bestimmten Zeit abgetastet werden können. Diese Eigenschaft ist attraktiv, wenn man andere Sprachanwendungen in Betracht zieht, wie z. B. Reinforcement Learning basierend auf menschlichem Feedback (RLHF) oder die Bewertung der Ausgabe von Sprachmodellen (wie in AlphaCode), da es attraktiv ist, in einer bestimmten Zeit eine große Anzahl von Token ausgeben zu können Besonderheit. Hier untersuchten die Forscher die Inferenzergebnisse des Modells mit Parameter 1B. In Bezug auf die Basislinien werden sie mit dem MQA-Transformer verglichen, der bei der Inferenz deutlich schneller ist als der in der Literatur häufig verwendete Standard-MHA-Transformer. Die von den Forschern verglichenen Modelle sind: i) MQA-Konverter, ii) Hawk und iii) Griffin. Um verschiedene Modelle zu vergleichen, berichten wir über Latenz und Durchsatz. Wie in Abbildung 4 dargestellt, verglichen die Forscher die Latenz des Modells mit einer Stapelgröße von 16, leerer Vorfüllung und Vorfüllung von 4096 Token.
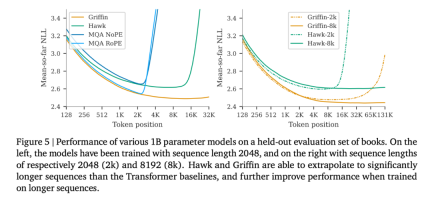
Abbildung 1(b) vergleicht den maximalen Durchsatz (Tokens/Sekunde) derselben Modelle bei der Abtastung von 512, 1024, 2048 bzw. 4196 Tokens nach leeren Hinweisen. Lange Kontextmodellierung In diesem Artikel wird auch die Wirksamkeit von Hawk und Griffin untersucht, die längere Kontexte verwenden, um die Vorhersagen des nächsten Tokens zu verbessern, und ihre Fähigkeit zur Extrapolation während der Inferenz untersucht. Griffins Leistung bei Aufgaben, die Kopier- und Abruffähigkeiten erfordern, wird ebenfalls untersucht, sowohl in Modellen, die für solche Aufgaben trainiert wurden, als auch wenn diese Fähigkeiten mithilfe vorab trainierter Sprachmodelle getestet werden. Aus der Grafik auf der linken Seite von Abbildung 5 ist ersichtlich, dass sowohl Hawk als auch Griffin innerhalb eines bestimmten maximalen Längenbereichs die Vorhersagefähigkeit des nächsten Tokens in einem längeren Kontext verbessern können und insgesamt in der Lage sind um auf längere Sequenzen (mindestens viermal) als beim Training zu schließen. Insbesondere Griffin schneidet beim Denken sehr gut ab, selbst wenn RoPE in der lokalen Aufmerksamkeitsschicht verwendet wird.
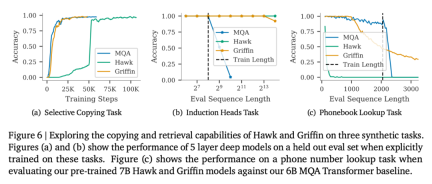
Wie in Abbildung 6 gezeigt, können bei der selektiven Kopieraufgabe alle drei Modelle die Aufgabe perfekt erledigen. Beim Vergleich der Lerngeschwindigkeit bei dieser Aufgabe ist Hawk deutlich langsamer als Transformer, was den Beobachtungen von Jelassi et al. (2024) ähnelt, die herausfanden, dass Mamba bei einer ähnlichen Aufgabe deutlich langsamer lernte. Obwohl Griffin nur eine lokale Aufmerksamkeitsschicht verwendet, wird seine Lerngeschwindigkeit interessanterweise kaum verlangsamt und liegt auf dem gleichen Niveau wie die Lerngeschwindigkeit von Transformer.
Für weitere Einzelheiten lesen Sie bitte das Originalpapier.
Das obige ist der detaillierte Inhalt vonDie RNN-Effizienz ist mit der von Transformer vergleichbar. Die neue Architektur von Google hat zwei aufeinanderfolgende Veröffentlichungen: Sie ist im gleichen Maßstab stärker als Mamba. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Technologie-Peripheriegeräte
Technologie-Peripheriegeräte

 Seit
Seit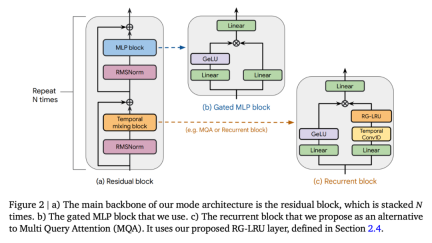


 So erstellen Sie Ihren persönlichen KI -Assistenten mit Smollm mit Umarmung. SmollmApr 18, 2025 am 11:52 AM
So erstellen Sie Ihren persönlichen KI -Assistenten mit Smollm mit Umarmung. SmollmApr 18, 2025 am 11:52 AM KI für psychische Gesundheit wird aufmerksam durch aufregende neue Initiative an der Stanford University analysiertApr 18, 2025 am 11:49 AM
KI für psychische Gesundheit wird aufmerksam durch aufregende neue Initiative an der Stanford University analysiertApr 18, 2025 am 11:49 AM Die 2025 WNBA -Entwurfsklasse tritt in eine Liga ein, die wächst und gegen Online -Belästigung kämpftApr 18, 2025 am 11:44 AM
Die 2025 WNBA -Entwurfsklasse tritt in eine Liga ein, die wächst und gegen Online -Belästigung kämpftApr 18, 2025 am 11:44 AM Umfassende Anleitung zu Python -integrierten Datenstrukturen - Analytics VidhyaApr 18, 2025 am 11:43 AM
Umfassende Anleitung zu Python -integrierten Datenstrukturen - Analytics VidhyaApr 18, 2025 am 11:43 AM Erste Eindrücke von OpenAIs neuen Modellen im Vergleich zu AlternativenApr 18, 2025 am 11:41 AM
Erste Eindrücke von OpenAIs neuen Modellen im Vergleich zu AlternativenApr 18, 2025 am 11:41 AM AI -Portfolio | Wie baue ich ein Portfolio für eine KI -Karriere?Apr 18, 2025 am 11:40 AM
AI -Portfolio | Wie baue ich ein Portfolio für eine KI -Karriere?Apr 18, 2025 am 11:40 AM Welche Agenten KI könnte für Sicherheitsvorgänge bedeutenApr 18, 2025 am 11:36 AM
Welche Agenten KI könnte für Sicherheitsvorgänge bedeutenApr 18, 2025 am 11:36 AM Google versus openai: Der KI -Kampf für SchülerApr 18, 2025 am 11:31 AM
Google versus openai: Der KI -Kampf für SchülerApr 18, 2025 am 11:31 AM













