La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Les auteurs de cet article proviennent de l'Université du Zhejiang, du Laboratoire d'intelligence artificielle de Shanghai, de l'Université chinoise de Hong Kong, de l'Université de Sydney et de l'Université d'Oxford. Liste des auteurs : Wu Yixuan, Wang Yizhou, Tang Shixiang, Wu Wenhao, He Tong, Wanli Ouyang, Philip Torr, Jian Wu. Parmi eux, le co-premier auteur Wu Yixuan est doctorant à l'Université du Zhejiang et Wang Yizhou est assistant de recherche scientifique au Laboratoire d'intelligence artificielle de Shanghai. L'auteur correspondant Tang Shixiang est chercheur postdoctoral à l'Université chinoise de Hong Kong.
Les modèles multimodaux de langage étendu (MLLM) ont montré des capacités impressionnantes dans différentes tâches, malgré cela, le potentiel de ces modèles dans les tâches de détection est encore sous-estimé. Lorsque des coordonnées précises sont requises dans des tâches complexes de détection d'objets, les hallucinations des MLLM leur font souvent manquer des objets cibles ou donnent des cadres de délimitation inexacts. Afin de permettre la détection des MLLM, les travaux existants nécessitent non seulement de collecter de grandes quantités d'ensembles de données d'instructions de haute qualité, mais également d'affiner les modèles open source. Bien que long et laborieux, il ne parvient pas non plus à tirer parti des capacités de compréhension visuelle plus puissantes du modèle fermé. À cette fin, l'Université du Zhejiang, en collaboration avec le Laboratoire d'intelligence artificielle de Shanghai et l'Université d'Oxford, a proposé DetToolChain, un nouveau paradigme d'invite qui libère les capacités de détection des grands modèles de langage multimodaux. Les grands modèles multimodaux peuvent apprendre à détecter avec précision sans formation. Des recherches pertinentes ont été incluses dans ECCV 2024. Afin de résoudre les problèmes de MLLM dans les tâches de détection, DetToolChain part de trois points : (1) Concevoir des invites visuelles pour la détection, qui sont plus directes et efficaces pour MLLM que les invites textuelles traditionnelles, ( 2) décomposer les tâches de détection détaillées en tâches petites et simples, (3) utiliser une chaîne de pensée pour optimiser progressivement les résultats de détection et éviter autant que possible l'illusion de grands modèles multimodaux. Correspondant aux informations ci-dessus, DetToolChain contient deux conceptions clés : (1) Un ensemble complet d'invites de traitement visuel (invites de traitement visuel), qui sont dessinées directement dans l'image et peuvent réduire considérablement l'écart entre les informations visuelles et différence d'informations textuelles. (2) Un ensemble complet de raisonnements de détection incite à améliorer la compréhension spatiale de la cible de détection et à déterminer progressivement l'emplacement précis final de la cible grâce à une chaîne d'outils de détection adaptative à l'échantillon. En combinant DetToolChain avec MLLM, comme GPT-4V et Gemini, diverses tâches de détection peuvent être prises en charge sans réglage d'instructions, y compris la détection de vocabulaire ouvert, la détection de cible de description, la compréhension d'expression référentielle et la détection de cible orientée. 
- Titre de l'article : DetToolChain : Un nouveau paradigme d'incitation pour libérer la capacité de détection du MLLM
- Lien de l'article : https://arxiv.org/abs/2403.12488
Qu'est-ce que DetToolChain ?
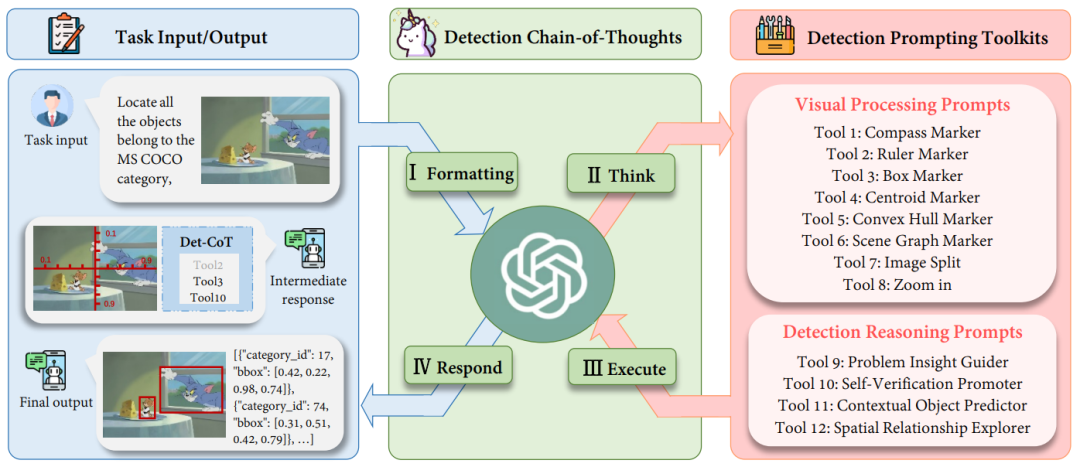
I. Formatage : convertissez le format d'entrée d'origine de la tâche en un modèle d'instruction approprié comme entrée dans le MLLM ; II Réfléchissez : décomposez une détection complexe spécifique. tâche en sous-tâches plus simples et sélectionnez des conseils efficaces dans la boîte à outils de conseils de détection (invites) ; III. Exécuter : exécuter de manière itérative des invites spécifiques (invites) en séquence
IV Répondre : utiliser les propres capacités de raisonnement de MLLM pour superviser l'ensemble du processus de détection ; et renvoie la réponse finale (réponse finale).
Boîte à outils d'invite de détection : invites de traitement visuel
Abbildung 2: Schematische Darstellung visueller Verarbeitungsaufforderungen. Wir haben (1) regionalen Verstärker, (2) räumlichen Messstandard und (3) Szenenbild-Parser entwickelt, um die Erkennungsfähigkeiten von MLLMs aus verschiedenen Perspektiven zu verbessern. Wie in Abbildung 2 dargestellt, (1) zielt Regional Amplifier darauf ab, die Sichtbarkeit von MLLMs auf Regionen von Interesse (ROI) zu verbessern, einschließlich des Zuschneidens des Originalbilds in verschiedene Unterregionen, wobei der Schwerpunkt auf den Unterregionen liegt wo sich das Zielobjekt befindet; darüber hinaus ermöglicht die Zoomfunktion eine feinkörnige Betrachtung bestimmter Teilbereiche im Bild. (2) Spatial Measurement Standard bietet eine klarere Referenz für die Zielerkennung, indem ein Lineal und ein Kompass mit linearen Skalen auf das Originalbild gelegt werden, wie in Abbildung 2 (2) dargestellt. Hilfslineale und Kompasse ermöglichen MLLMs die Ausgabe genauer Koordinaten und Winkel mithilfe von Translations- und Rotationsreferenzen, die dem Bild überlagert sind. Im Wesentlichen vereinfacht diese Hilfslinie die Erkennungsaufgabe und ermöglicht es MLLMs, die Koordinaten von Objekten zu lesen, anstatt sie direkt vorherzusagen. (3) Der Scene Image Parser markiert die vorhergesagte Objektposition oder -beziehung und verwendet räumliche und kontextbezogene Informationen, um ein Verständnis der räumlichen Beziehung des Bildes zu erreichen. Scene Image Parser kann in zwei Kategorien unterteilt werden: Zuerst beschriften wir für ein einzelnes Zielobjekt das vorhergesagte Objekt mit Schwerpunkt, konvexer Hülle und Begrenzungsrahmen mit Beschriftungsname und Boxindex. Diese Markierungen stellen Objektpositionsinformationen in verschiedenen Formaten dar und ermöglichen es MLLM, verschiedene Objekte unterschiedlicher Form und mit unterschiedlichem Hintergrund zu erkennen, insbesondere Objekte mit unregelmäßigen Formen oder stark verdeckte Objekte. Der konvexe Hüllenmarker markiert beispielsweise die Grenzpunkte eines Objekts und verbindet sie zu einer konvexen Hülle, um die Erkennungsleistung sehr unregelmäßig geformter Objekte zu verbessern. Zweitens verbinden wir für Multiobjektive die Mittelpunkte verschiedener Objekte durch Szenendiagrammmarkierungen, um die Beziehung zwischen Objekten im Bild hervorzuheben. Basierend auf dem Szenendiagramm kann MLLM seine kontextbezogenen Argumentationsfunktionen nutzen, um vorhergesagte Begrenzungsrahmen zu optimieren und Halluzinationen zu vermeiden. Wie in Abbildung 2 (3) gezeigt, möchte Jerry beispielsweise Käse essen, daher sollten ihre Begrenzungsrahmen sehr nahe beieinander liegen. Toolkit für Erkennungsbegründungsaufforderungen: Erkennungsbegründungsaufforderungen
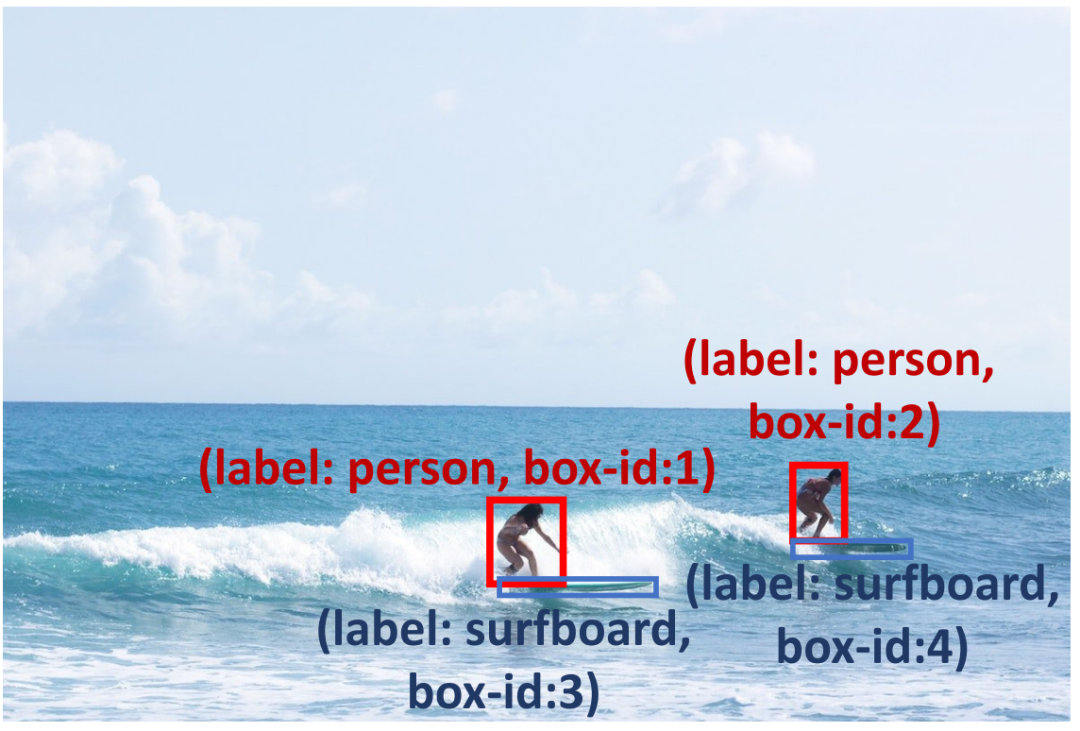
Um die Zuverlässigkeit des Vorhersagefelds zu verbessern, haben wir Erkennungsbegründungsaufforderungen durchgeführt (siehe Tabelle 1), um die Vorhersageergebnisse zu überprüfen und mögliche potenzielle Probleme zu diagnostizieren . Zunächst schlagen wir den Problem Insight Guider vor, der schwierige Probleme hervorhebt und effektive Erkennungsvorschläge und ähnliche Beispiele für Abfragebilder bereitstellt. Beispielsweise definiert der Problem Insight Guider für Abbildung 3 die Abfrage als ein Problem der Erkennung kleiner Objekte und schlägt vor, es durch Vergrößern des Surfbrettbereichs zu lösen. Zweitens entwerfen wir den Spatial Relationship Explorer und den Contextual Object Predictor, um die inhärenten räumlichen und kontextbezogenen Fähigkeiten von MLLMs zu nutzen, um sicherzustellen, dass die Erkennungsergebnisse mit dem gesunden Menschenverstand übereinstimmen. Wie in Abbildung 3 dargestellt, kann ein Surfbrett gleichzeitig mit dem Ozean vorkommen (Kontextwissen), und es sollte sich ein Surfbrett in der Nähe der Füße des Surfers befinden (Raumwissen). Darüber hinaus verwenden wir den Self-Verification Promoter, um die Konsistenz der Antworten über mehrere Runden hinweg zu verbessern. Um die Argumentationsfähigkeiten von MLLMs weiter zu verbessern, übernehmen wir weit verbreitete Aufforderungsmethoden wie Debatten und Selbst-Debugging. Eine detaillierte Beschreibung finden Sie im Originaltext.
Erkennungsinferenzhinweise können MLLMs dabei helfen, Probleme bei der Erkennung kleiner Objekte zu lösen, indem sie beispielsweise mit gesundem Menschenverstand ein Surfbrett unter den Füßen einer Person lokalisieren und das Modell dazu ermutigen, Surfbretter im Meer zu erkennen.
Experiment: Sie können die Feinabstimmungsmethode übertreffen, ohne dass in der Tabelle wie in 2 gezeigt gezeigt wurde. Wir haben unsere Methode auf offenem Vokabularerkennung (OVD) bewertet. , wobei die AP50-Ergebnisse für 17 neue Klassen, 48 Basisklassen und alle Klassen im COCO OVD-Benchmark getestet wurden. Die Ergebnisse zeigen, dass die Leistung von GPT-4V und Gemini durch den Einsatz unserer DetToolChain deutlich verbessert wird. Um die Wirksamkeit unserer Methode zum Verständnis referenzieller Ausdrücke zu demonstrieren, vergleichen wir unsere Methode mit anderen Zero-Shot-Methoden für die Datensätze RefCOCO, RefCOCO+ und RefCOCOg (Tabelle 5). Auf RefCOCO verbesserte DetToolChain die Leistung der GPT-4V-Basislinie um 44,53 %, 46,11 % bzw. 24,85 % bei val, test-A und test-B und demonstrierte damit das überlegene Verständnis und die Leistung von DetToolChain für referenzielle Ausdrücke unter Zero-Shot-Positionierungsbedingungen. Das obige ist der detaillierte Inhalt vonECCV 2024 |. Um die Leistung von GPT-4V- und Gemini-Erkennungsaufgaben zu verbessern, benötigen Sie dieses Prompt-Paradigma. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:Der Inhalt dieses Artikels wird freiwillig von Internetnutzern beigesteuert und das Urheberrecht liegt beim ursprünglichen Autor. Diese Website übernimmt keine entsprechende rechtliche Verantwortung. Wenn Sie Inhalte finden, bei denen der Verdacht eines Plagiats oder einer Rechtsverletzung besteht, wenden Sie sich bitte an admin@php.cn