
Heim >Technologie-Peripheriegeräte >KI >Das Team von KDD 2024|Hong Kong Rhubarb Chao analysiert eingehend die „unbekannten Grenzen' großer Modelle im Bereich des maschinellen Lernens von Graphen
Das Team von KDD 2024|Hong Kong Rhubarb Chao analysiert eingehend die „unbekannten Grenzen' großer Modelle im Bereich des maschinellen Lernens von Graphen

- PHPzOriginal
- 2024-07-22 16:54:341196Durchsuche

Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail für die Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Der Hauptautor dieses Artikels ist vom Data Intelligence Lab der University of Hong Kong. Unter den Autoren sind der Erstautor Ren Xubin und der Zweitautor Tang Jiabin beide Doktoranden im ersten Jahr an der School of Data Science der Universität Hongkong, und ihr Betreuer ist Professor Huang Chao vom Data Intelligence Lab@HKU. Das Data Intelligence Laboratory der University of Hong Kong widmet sich der Forschung im Zusammenhang mit künstlicher Intelligenz und Data Mining und deckt Bereiche wie große Sprachmodelle, graphische neuronale Netze, Informationsabruf, Empfehlungssysteme und raumzeitliches Data Mining ab. Frühere Arbeiten umfassen allgemeine Diagramme für große Sprachmodelle wie GraphGPT, HiGPT; den interpretierbaren Empfehlungsalgorithmus für große Sprachmodelle XRec usw.
Wie erforschen wir im heutigen Zeitalter der Informationsexplosion tiefe Zusammenhänge aus dem riesigen Datenmeer?
In diesem Zusammenhang haben Experten und Wissenschaftler der University of Hong Kong, der University of Notre Dame und anderer Institutionen in der neuesten Übersicht über das Gebiet des Graphenlernens und großer Sprachmodelle die Antwort für uns enthüllt.
Graph ist eine grundlegende Datenstruktur, die verschiedene Beziehungen in der realen Welt darstellt. Seine Bedeutung liegt auf der Hand. Frühere Untersuchungen haben gezeigt, dass graphische neuronale Netze beeindruckende Ergebnisse bei graphbezogenen Aufgaben erzielt haben. Da jedoch die Komplexität von Anwendungsszenarien für Diagrammdaten weiter zunimmt, ist das Engpassproblem des maschinellen Lernens von Diagrammen immer deutlicher geworden. In jüngster Zeit haben groß angelegte Sprachmodelle im Bereich der Verarbeitung natürlicher Sprache für Aufsehen gesorgt, und ihre hervorragenden Sprachverständnis- und Zusammenfassungsfähigkeiten haben viel Aufmerksamkeit erregt. Aus diesem Grund ist die Integration großer Sprachmodelle mit Graph-Learning-Technologie zur Verbesserung der Leistung von Graph-Lernaufgaben zu einem neuen Forschungsschwerpunkt in der Branche geworden.
Diese Rezension bietet eine eingehende Analyse der wichtigsten technischen Herausforderungen im aktuellen Bereich des Graphenlernens, wie z. B. die Fähigkeit zur Modellverallgemeinerung, Robustheit und die Fähigkeit, komplexe Diagrammdaten zu verstehen, und wirft einen Blick auf die zukünftigen Durchbrüche großer Modelle Technologie.“ Potenzial im Hinblick auf „unbekannte Grenzen“.

Papieradresse: https://arxiv.org/abs/2405.08011
Projektadresse: https://github.com/HKUDS/Awesome-LLM4Graph-Papers
HKU Data Intelligence Labor: https://sites.google.com/view/chaoh/home
Diese Rezension bietet einen detaillierten Überblick über die neuesten LLMs, die beim Graphenlernen angewendet werden, und schlägt eine neue Klassifizierungsmethode basierend auf dem Framework-Design vor. Die vorhandenen Technologien werden systematisch klassifiziert. Es bietet eine detaillierte Analyse von vier verschiedenen Algorithmus-Designideen: Einer geht ein graphisches neuronales Netzwerk voran, der zweiten geht ein großes Sprachmodell voran, bei der dritten werden große Sprachmodelle und Graphen integriert und bei der vierten wird nur ein großes Sprachmodell verwendet. Für jede Kategorie konzentrieren wir uns auf die wichtigsten technischen Methoden. Darüber hinaus bietet die Übersicht einen Einblick in die Stärken verschiedener Frameworks sowie deren Grenzen und zeigt mögliche Richtungen für zukünftige Forschung auf.
Das Forschungsteam unter der Leitung von Professor Huang Chao vom Data Intelligence Laboratory der Universität Hongkong wird auf der KDD 2024-Konferenz eine ausführliche Diskussion über die „unbekannten Grenzen“ führen, mit denen große Modelle im Bereich des Graphenlernens konfrontiert sind.
1 Grundkenntnisse
Im Bereich der Informatik ist Graph (Graph) eine wichtige nichtlineare Datenstruktur, die aus Knotenmenge (V) und Kantenmenge (E) besteht. Jede Kante verbindet ein Knotenpaar und kann gerichtet (mit einem klaren Start- und Endpunkt) oder ungerichtet (keine Richtung angegeben) sein. Besonders hervorzuheben ist, dass Text-Attributed Graph (TAG) als spezielle Form des Graphen jedem Knoten ein serialisiertes Textmerkmal zuweist. Dieses Merkmal ist im Zeitalter großer Sprachmodelle besonders wichtig essentiell. Der Textattributgraph kann kanonisch als Triplett dargestellt werden, das aus einer Knotenmenge V, einer Kantenmenge E und einer Textmerkmalsmenge T besteht, d. h. G* = (V, E, T).
Graph Neural Networks (GNNs) ist ein Deep-Learning-Framework, das für graphstrukturierte Daten entwickelt wurde. Es aktualisiert die Einbettungsdarstellung eines Knotens, indem es Informationen von benachbarten Knoten aggregiert. Insbesondere aktualisiert jede GNN-Schicht die Knoteneinbettung h durch eine bestimmte Funktion, die den Einbettungsstatus des aktuellen Knotens und die Einbettungsinformationen der umgebenden Knoten umfassend berücksichtigt, um die Knoteneinbettung der nächsten Schicht zu generieren.
Large Language Models (LLMs) ist ein leistungsstarkes Regressionsmodell. Neuere Forschungen haben gezeigt, dass Sprachmodelle, die Milliarden von Parametern enthalten, bei der Lösung einer Vielzahl natürlicher Sprachaufgaben wie Übersetzung, Zusammenfassungserstellung und Befehlsausführung gut funktionieren und daher als große Sprachmodelle bezeichnet werden. Derzeit basieren die meisten hochmodernen LLMs auf Transformer-Blöcken und nutzen den Abfrage-Schlüssel-Wert-Mechanismus (QKV), der Informationen effizient in Token-Sequenzen integriert. Je nach Anwendungsrichtung und Trainingsmethode können Sprachmodelle in zwei Haupttypen unterteilt werden:
Masked Language Modeling (MLM) ist ein beliebtes Vortrainingsziel für LLMs. Dabei werden bestimmte Token in einer Sequenz selektiv maskiert und das Modell trainiert, diese maskierten Token basierend auf dem umgebenden Kontext vorherzusagen. Um eine genaue Vorhersage zu erreichen, berücksichtigt das Modell umfassend die Kontextumgebung der maskierten Wortelemente.
Causal Language Modeling (CLM) ist ein weiteres gängiges Vorschulungsziel für LLMs. Es erfordert, dass das Modell den nächsten Token basierend auf den vorherigen Token in der Sequenz vorhersagt. In diesem Prozess verlässt sich das Modell nur auf den Kontext vor dem aktuellen Wortelement, um genaue Vorhersagen zu treffen.
2 Graphenlernen und große Sprachmodelle
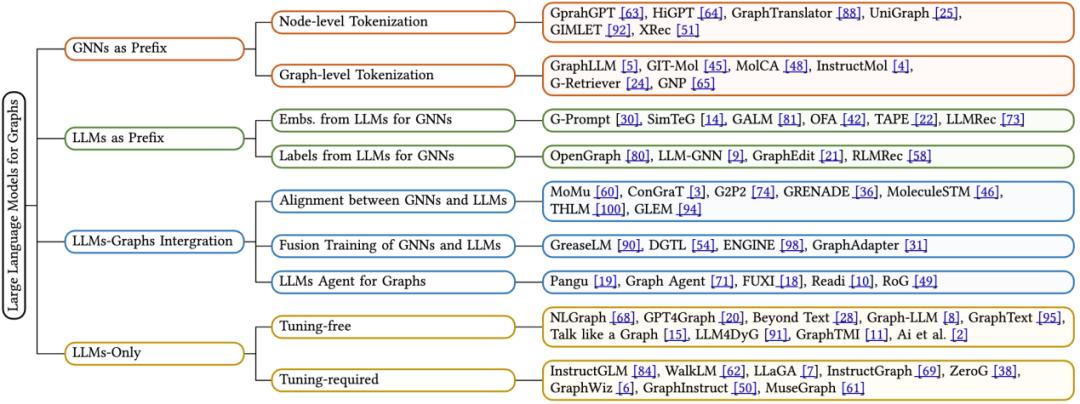
In diesem Übersichtsartikel stützt sich der Autor auf den Inferenzprozess des Modells – also die Verarbeitung von Diagrammdaten, Textdaten und großen Sprachmodellen (LLMs). ) Interaktive Methoden, eine neue Klassifizierungsmethode wird vorgeschlagen. Konkret fassen wir vier Haupttypen des Modellarchitekturdesigns wie folgt zusammen:
GNNs als Präfix: In dieser Kategorie dienen Graph Neural Networks (GNNs) als Hauptkomponente, die für die Verarbeitung von Graphendaten verantwortlich ist und LLMs mit versorgt Strukturbewusste Tags (z. B. Tags auf Knotenebene, Kantenebene oder Diagrammebene) für nachfolgende Rückschlüsse.
LLMs als Präfix: In dieser Kategorie verarbeiten LLMs zunächst Diagrammdaten zusammen mit Textinformationen und stellen anschließend Knoteneinbettungen oder generierte Beschriftungen für das Training graphischer neuronaler Netze bereit.
LLMs-Graphs-Integration (LLMs- und Graphen-Integration): Methoden in dieser Kategorie streben eine tiefere Integration zwischen LLMs und Diagrammdaten an, beispielsweise durch Fusionstraining oder Ausrichtung mit GNNs. Darüber hinaus wurde ein LLM-basierter Agent entwickelt, der mit Diagramminformationen interagiert.
Nur LLMs (nur unter Verwendung von LLMs): In dieser Kategorie werden praktische Hinweise und Techniken zum Einbetten grafisch strukturierter Daten in Tokensequenzen entwickelt, um die Inferenz durch LLMs zu erleichtern. Gleichzeitig integrieren einige Methoden auch multimodale Marker, um die Verarbeitungsfähigkeiten des Modells weiter zu erweitern.
2.1 GNNs als Präfix
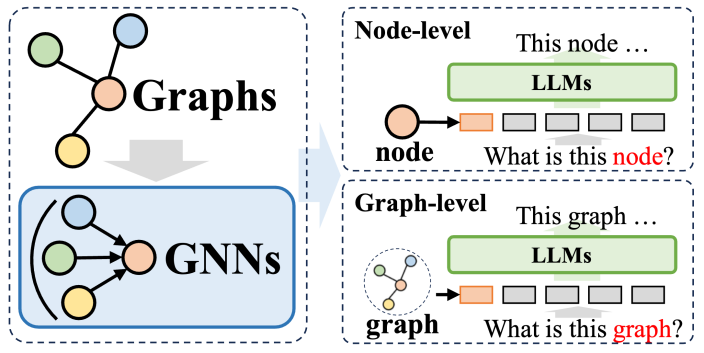
In dem Methodensystem, in dem Graph Neural Networks (GNNs) als Präfixe verwendet werden, spielen GNNs die Rolle struktureller Encoder und verbessern die Leistung großer Sprachmodelle (LLMs) erheblich. auf Graphstrukturen Datenanalysefunktionen, wodurch eine Vielzahl nachgelagerter Aufgaben von Nutzen sind. Bei diesen Methoden dienen GNNs hauptsächlich als Encoder, die für die Umwandlung komplexer Diagrammdaten in Diagramm-Token-Sequenzen verantwortlich sind, die umfangreiche Strukturinformationen enthalten. Diese Sequenzen werden dann in LLMs eingegeben, was mit dem Verarbeitungsprozess natürlicher Sprache übereinstimmt.
Diese Methoden lassen sich grob in zwei Kategorien einteilen: Die erste ist die Tokenisierung auf Knotenebene, d. h. jeder Knoten in der Diagrammstruktur wird einzeln in LLM eingegeben. Der Zweck dieses Ansatzes besteht darin, LLM in die Lage zu versetzen, feinkörnige Strukturinformationen auf Knotenebene tiefgreifend zu verstehen und die Korrelationen und Unterschiede zwischen verschiedenen Knoten genau zu identifizieren. Bei der zweiten handelt es sich um die Tokenisierung auf Diagrammebene, bei der mithilfe einer speziellen Pooling-Technologie das gesamte Diagramm in eine Tokensequenz fester Länge komprimiert wird, mit dem Ziel, die allgemeine Semantik der Diagrammstruktur auf hoher Ebene zu erfassen.
Für die Tokenisierung auf Knotenebene eignet es sich besonders für Diagrammlernaufgaben, die die Modellierung von Feinstrukturinformationen auf Knotenebene erfordern, wie z. B. Knotenklassifizierung und Linkvorhersage. Bei diesen Aufgaben muss das Modell in der Lage sein, subtile semantische Unterschiede zwischen verschiedenen Knoten zu unterscheiden. Herkömmliche graphische neuronale Netze generieren eine eindeutige Darstellung für jeden Knoten auf der Grundlage der Informationen benachbarter Knoten und führen dann auf dieser Grundlage eine nachgelagerte Klassifizierung oder Vorhersage durch. Die Tokenisierungsmethode auf Knotenebene kann die einzigartigen Strukturmerkmale jedes Knotens weitestgehend beibehalten, was für die Ausführung nachgelagerter Aufgaben von großem Vorteil ist.
Andererseits dient die Tokenisierung auf Diagrammebene der Anpassung an Aufgaben auf Diagrammebene, die das Extrahieren globaler Informationen aus Knotendaten erfordern. Im Rahmen von GNN als Präfix kann die Tokenisierung auf Diagrammebene durch verschiedene Pooling-Operationen viele Knotendarstellungen zu einer einheitlichen Diagrammdarstellung synthetisieren, was nicht nur die globale Semantik des Diagramms erfasst, sondern auch die Leistung verschiedener nachgelagerter Aufgaben weiter verbessert . Ausführungseffekt.
2.2 LLMs als Präfix
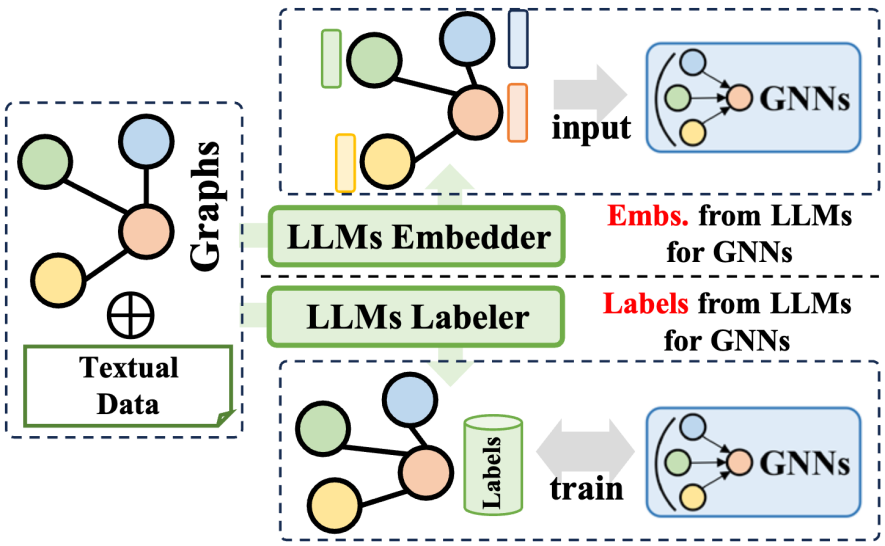
Die Präfixmethode „Large Language Models“ (LLMs) nutzt die umfangreichen Informationen, die von großen Sprachmodellen generiert werden, um den Trainingsprozess von graphischen neuronalen Netzen (GNNs) zu optimieren. Diese Informationen umfassen verschiedene Daten wie Textinhalte, Tags oder Einbettungen, die von LLMs generiert werden. Je nachdem, wie diese Informationen angewendet werden, können verwandte Technologien in zwei Hauptkategorien unterteilt werden: Die eine besteht darin, die von LLMs generierten Einbettungen zu verwenden, um das Training von GNNs zu unterstützen, und die andere darin, die von LLMs generierten Labels in den Trainingsprozess von GNNs zu integrieren .
In Bezug auf die Verwendung von LLMs-Einbettungen umfasst der Inferenzprozess von GNNs die Übertragung und Aggregation von Knoteneinbettungen. Die Qualität und Vielfalt der anfänglichen Knoteneinbettungen variieren jedoch erheblich zwischen den Domänen, z. B. ID-basierte Einbettungen in Empfehlungssystemen oder Einbettungen von Bag-of-Words-Modellen in Zitationsnetzwerken, und es mangelt ihnen möglicherweise an Klarheit und Fülle. Dieser Mangel an Einbettungsqualität schränkt manchmal die Leistung von GNNs ein. Darüber hinaus beeinträchtigt das Fehlen eines universellen Knoteneinbettungsdesigns auch die Generalisierungsfähigkeit von GNNs beim Umgang mit verschiedenen Knotensätzen. Glücklicherweise können wir durch die Nutzung der überlegenen Fähigkeiten großer Sprachmodelle bei der Sprachzusammenfassung und -modellierung sinnvolle und effektive Einbettungen für GNNs generieren und so deren Trainingsleistung verbessern.
Im Hinblick auf die Integration von LLMs-Labels besteht eine weitere Strategie darin, diese Labels als Überwachungssignale zu verwenden, um den Trainingseffekt von GNNs zu verstärken. Es ist erwähnenswert, dass die überwachten Etiketten hier nicht auf herkömmliche Klassifizierungsetiketten beschränkt sind, sondern auch Einbettungen, Diagramme und andere Formen umfassen. Die von LLMs generierten Informationen werden nicht direkt als Eingabedaten für GNNs verwendet, sondern stellen ein verfeinertes Optimierungsüberwachungssignal dar und helfen so GNNs, eine bessere Leistung bei verschiedenen graphbezogenen Aufgaben zu erzielen.
2.3 LLMs-Graphs-Integration
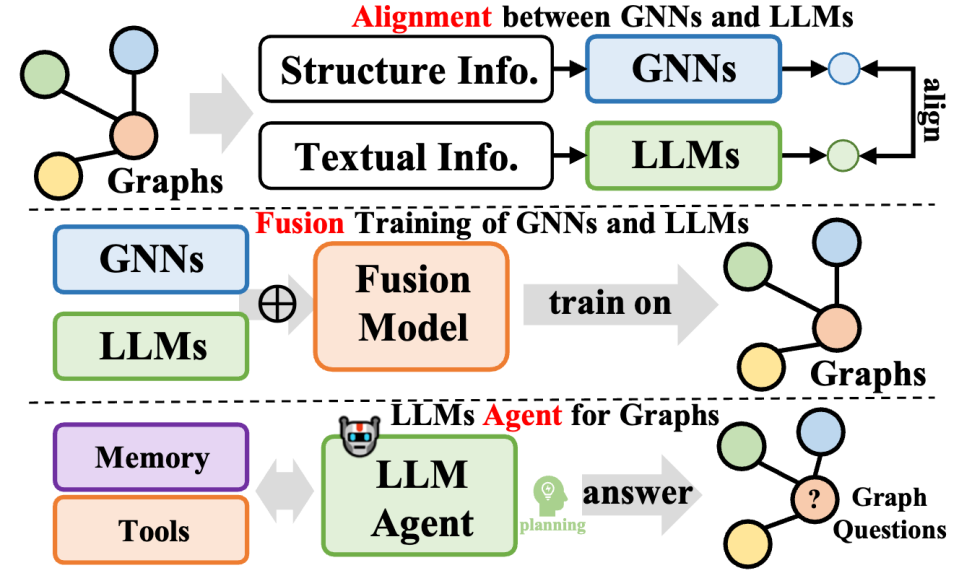
Diese Art von Methode integriert große Sprachmodelle und Diagrammdaten weiter, deckt verschiedene Methoden ab und verbessert nicht nur die Fähigkeiten großer Sprachmodelle (LLMs) bei Diagrammverarbeitungsaufgaben Gleichzeitig wird auch das Parameterlernen von Graph Neural Networks (GNNs) optimiert. Diese Methoden lassen sich in drei Typen zusammenfassen: Die eine ist die Fusion von GNNs und LLMs mit dem Ziel, eine tiefe Integration und ein gemeinsames Training zwischen Modellen zu erreichen. Die andere ist die Ausrichtung zwischen GNNs und LLMs und konzentriert sich auf die Darstellungs- oder Aufgabenebene der beiden Modelle Die dritte besteht darin, auf LLMs basierende autonome Agenten zu erstellen, um graphbezogene Aufgaben zu planen und auszuführen.
In Bezug auf die Fusion von GNNs und LLMs konzentrieren sich GNNs normalerweise auf die Verarbeitung strukturierter Daten, während LLMs gut in der Verarbeitung von Textdaten sind, was dazu führt, dass die beiden unterschiedliche Merkmalsräume haben. Um dieses Problem anzugehen und den gemeinsamen Gewinn beider Datenmodalitäten beim Lernen von GNNs und LLMs zu fördern, übernehmen einige Methoden Techniken wie kontrastives Lernen oder iteratives Training zur Erwartungsmaximierung (EM), um die Merkmalsräume der beiden Modelle auszurichten. Dieser Ansatz verbessert die Genauigkeit der Modellierung von Diagramm- und Textinformationen und verbessert dadurch die Leistung bei einer Vielzahl von Aufgaben.
In Bezug auf die Ausrichtung von GNNs mit LLMs ist die Darstellungsausrichtung zwar eine gemeinsame Optimierung und eine Ausrichtung auf Einbettungsebene beider Modelle, sie sind jedoch während der Inferenzphase immer noch unabhängig. Um eine engere Integration zwischen LLMs und GNNs zu erreichen, konzentrieren sich einige Forschungsarbeiten auf die Gestaltung einer tieferen Modularchitekturfusion, beispielsweise auf die Kombination von Transformatorschichten in LLMs mit graphischen neuronalen Schichten in GNNs. Durch das gemeinsame Training von GNNs und LLMs ist es möglich, bei Graphaufgaben bidirektionale Vorteile für beide Module zu erzielen.
Was schließlich LLM-basierte Graphagenten betrifft, besteht die neue Forschungsrichtung mithilfe der hervorragenden Fähigkeiten von LLMs beim Verstehen von Anweisungen und der Selbstplanung zur Lösung von Problemen darin, autonome Agenten zu entwickeln, die auf LLMs basieren, um sie zu verarbeiten oder zu erforschen -Verwandte Aufgaben. Typischerweise umfasst ein solcher Agent drei Module: Gedächtnis, Wahrnehmung und Aktion, die einen Zyklus aus Beobachtung, Gedächtnisabruf und Aktion zur Lösung spezifischer Aufgaben bilden. Im Bereich der Graphentheorie können auf LLMs basierende Agenten direkt mit Diagrammdaten interagieren und Aufgaben wie Knotenklassifizierung und Verbindungsvorhersage ausführen.
2.4 Nur LLMs
Diese Rezension geht im Kapitel über Nur-LLMs, die sogenannten „nur“ LLMs, auf die direkte Anwendung großer Sprachmodelle (LLMs) auf verschiedene graphorientierte Aufgaben ein. Kategorie. Das Ziel dieser Methoden besteht darin, LLMs in die Lage zu versetzen, Informationen zur Graphenstruktur direkt zu akzeptieren, sie zu verstehen und diese Informationen zu kombinieren, um Überlegungen zu verschiedenen nachgelagerten Aufgaben anzustellen. Diese Methoden können hauptsächlich in zwei Kategorien unterteilt werden: i) Methoden, die keine Feinabstimmung erfordern und darauf abzielen, Hinweise zu entwerfen, die LLMs verstehen können, und vorab trainierte LLMs direkt dazu zu veranlassen, graphorientierte Aufgaben auszuführen; ii) Methoden, die Feinabstimmung erfordern -Tuning, Fokussierung auf Das Diagramm wird auf eine bestimmte Weise in eine Sequenz konvertiert, und die Diagramm-Token-Sequenz und die Token-Sequenz in natürlicher Sprache werden durch Feinabstimmungsmethoden ausgerichtet.
Ansatz ohne Feinabstimmung: Angesichts der einzigartigen Strukturmerkmale von Diagrammdaten ergeben sich zwei wesentliche Herausforderungen: Erstens, Diagramme im natürlichen Sprachformat effektiv zu erstellen, und zweitens, um festzustellen, ob große Sprachmodelle (LLMs) die Daten genau verstehen können Sprachform dargestellte Diagrammstruktur. Um diese Probleme anzugehen, entwickelte eine Gruppe von Forschern abstimmungsfreie Methoden zur Modellierung und Schlussfolgerung über Diagramme in einem Nur-Text-Raum und erforschte dabei das Potenzial vorab trainierter LLMs zur Verbesserung des Strukturverständnisses.
Methoden, die einer Feinabstimmung bedürfen: Aufgrund der Einschränkungen bei der Verwendung von Klartext zum Ausdruck von Diagrammstrukturinformationen besteht die aktuelle Mainstream-Methode darin, das Diagramm als Knoten-Token-Sequenz und als Token-Sequenz in natürlicher Sprache bei der Eingabe des Diagramms zu verwenden große Sprachmodelle (LLMs). Anders als das oben erwähnte GNN als Präfixmethode verzichtet die einzige LLM-Methode, die angepasst werden muss, auf den Diagramm-Encoder und verwendet stattdessen eine spezifische Textbeschreibung, um die Diagrammstruktur widerzuspiegeln, sowie sorgfältig gestaltete Eingabeaufforderungen in den Eingabeaufforderungen, die sich auf verschiedene nachgelagerte Elemente beziehen In der Mission wurden vielversprechende Leistungen erzielt.
3 Zukünftige Forschungsrichtungen
In diesem Aufsatz werden auch einige offene Fragen und mögliche zukünftige Forschungsrichtungen für große Sprachmodelle im Bereich der Graphen erörtert:
Die Fusion von multimodalen Graphen und großen Sprachmodellen (LLMs). Neuere Forschungsergebnisse zeigen, dass große Sprachmodelle außergewöhnliche Fähigkeiten bei der Verarbeitung und dem Verständnis multimodaler Daten wie Bilder und Videos gezeigt haben. Dieser Fortschritt bietet neue Möglichkeiten, LLMs mit multimodalen Kartendaten zu kombinieren, die mehrere modale Features enthalten. Die Entwicklung multimodaler LLMs, die solche Diagrammdaten verarbeiten können, wird es uns ermöglichen, präzisere und umfassendere Rückschlüsse auf Diagrammstrukturen zu ziehen, die auf einer umfassenden Berücksichtigung mehrerer Datentypen wie Text, Bild und Gehör basieren.
Verbessern Sie die Effizienz und senken Sie die Rechenkosten. Derzeit sind die hohen Rechenkosten, die mit den Trainings- und Inferenzphasen von LLMs verbunden sind, zu einem großen Engpass in ihrer Entwicklung geworden und schränken ihre Fähigkeit ein, umfangreiche Diagrammdaten mit Millionen von Knoten zu verarbeiten. Beim Versuch, LLMs mit graphischen neuronalen Netzen (GNNs) zu kombinieren, wird diese Herausforderung durch die Fusion zweier leistungsstarker Modelle noch größer. Daher besteht ein dringender Bedarf, wirksame Strategien zur Reduzierung der Trainingsrechenkosten von LLMs und GNNs zu finden und umzusetzen. Dies wird nicht nur dazu beitragen, die aktuellen Einschränkungen zu mildern, sondern dadurch auch den Anwendungsbereich von LLMs bei graphbezogenen Aufgaben weiter zu erweitern Verbesserung ihrer Rolle in der Datenwissenschaft und ihres Einflusses auf diesem Gebiet.
Bewältigen Sie verschiedene Grafikaufgaben. Aktuelle Forschungsmethoden konzentrieren sich hauptsächlich auf traditionelle graphbezogene Aufgaben wie Linkvorhersage und Knotenklassifizierung. Angesichts der leistungsstarken Fähigkeiten von LLMs ist es jedoch notwendig, dass wir ihr Potenzial bei der Verarbeitung komplexerer und generativer Aufgaben wie der Graphgenerierung, dem Graphverständnis und der graphbasierten Beantwortung von Fragen eingehend untersuchen. Durch die Erweiterung LLM-basierter Methoden zur Abdeckung dieser komplexen Aufgaben werden wir unzählige neue Möglichkeiten für die Anwendung von LLMs in verschiedenen Bereichen eröffnen. Beispielsweise können LLMs im Bereich der Arzneimittelforschung die Generierung neuer molekularer Strukturen erleichtern; im Bereich der Analyse sozialer Netzwerke können sie tiefe Einblicke in komplexe Beziehungsmuster liefern; umfassendere und kontextbezogene genauere Wissensbasis.
Erstellen Sie benutzerfreundliche Diagrammagenten. Derzeit sind die meisten LLM-basierten Agenten, die für diagrammbezogene Aufgaben entwickelt wurden, für eine einzelne Aufgabe angepasst. Diese Agenten arbeiten typischerweise im Single-Shot-Modus und sind darauf ausgelegt, Probleme auf einmal zu lösen. Ein idealer LLM-basierter Agent sollte jedoch benutzerfreundlich und in der Lage sein, dynamisch nach Antworten in Diagrammdaten als Antwort auf verschiedene offene Fragen der Benutzer zu suchen. Um dieses Ziel zu erreichen, müssen wir einen Agenten entwickeln, der sowohl flexibel als auch robust ist, zu iterativen Interaktionen mit Benutzern fähig ist und mit der Komplexität von Diagrammdaten umgehen kann, um genaue und relevante Antworten zu liefern. Dies erfordert nicht nur eine hohe Anpassungsfähigkeit der Agenten, sondern auch eine hohe Robustheit.
4 Zusammenfassung
Diese Überprüfung führte eine ausführliche Diskussion über groß angelegte Sprachmodelle (LLMs) durch, die auf Diagrammdaten zugeschnitten sind, und schlug eine Klassifizierungsmethode vor, die auf modellbasierten Inferenzrahmenwerken basiert und verschiedene Modelle sorgfältig in vier Typen unterteilt . Einzigartiges Rahmendesign. Jedes Design weist seine eigenen Stärken und Grenzen auf. Darüber hinaus bietet diese Rezension auch eine umfassende Diskussion dieser Funktionen und geht eingehend auf das Potenzial und die Herausforderungen jedes Frameworks bei der Bearbeitung von Diagrammdatenverarbeitungsaufgaben ein. Diese Forschungsarbeit zielt darauf ab, eine Referenzressource für Forscher bereitzustellen, die große Sprachmodelle zur Lösung graphbezogener Probleme erforschen und anwenden möchten, und es besteht die Hoffnung, dass sie letztendlich durch diese Arbeit ein tieferes Verständnis der Anwendung von fördern wird LLMs und Diagrammdaten sowie weitere technologische Innovationen und Durchbrüche in diesem Bereich.
Das obige ist der detaillierte Inhalt vonDas Team von KDD 2024|Hong Kong Rhubarb Chao analysiert eingehend die „unbekannten Grenzen' großer Modelle im Bereich des maschinellen Lernens von Graphen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr