
Heim >Technologie-Peripheriegeräte >KI >Die Universität für Wissenschaft und Technologie Chinas und Huawei Noah haben das Entropiegesetz vorgeschlagen, um den Zusammenhang zwischen der Leistung großer Modelle, der Datenkomprimierungsrate und dem Trainingsverlust aufzudecken.
Die Universität für Wissenschaft und Technologie Chinas und Huawei Noah haben das Entropiegesetz vorgeschlagen, um den Zusammenhang zwischen der Leistung großer Modelle, der Datenkomprimierungsrate und dem Trainingsverlust aufzudecken.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-07-22 16:39:35843Durchsuche

Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. E-Mail für die Einreichung: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com China und Huaweis Arche Noah-Labor. Das Team von Professor Chen Enhong beschäftigt sich intensiv mit den Bereichen Data Mining und maschinelles Lernen und hat zahlreiche Artikel in führenden Fachzeitschriften und Konferenzen veröffentlicht, die mehr als 20.000 Mal zitiert wurden. Das Noah's Ark Laboratory ist das Huawei-Labor, das sich mit Grundlagenforschung zu künstlicher Intelligenz beschäftigt. Es verfolgt das Konzept, theoretische Forschung und Anwendungsinnovation gleichermaßen in den Vordergrund zu stellen, und setzt sich für die Förderung technologischer Innovationen und Entwicklungen im Bereich der künstlichen Intelligenz ein.
 Link zum Papier: https://arxiv.org/pdf/2407.06645
Link zum Papier: https://arxiv.org/pdf/2407.06645
Code-Link: https://github.com/USTC-StarTeam/ZIP - O Abbildung 1 tENTropiegesetz
Datenkonsistenz C: Die Konsistenz der Daten spiegelt sich in der Entropie der Wahrscheinlichkeit des nächsten Tokens angesichts der vorherigen Situation wider. Eine höhere Datenkonsistenz führt normalerweise zu einem geringeren Trainingsverlust. Durchschnittliche Datenqualität Q: spiegelt die durchschnittliche Qualität der Daten auf Stichprobenebene wider, die anhand verschiedener objektiver und subjektiver Aspekte gemessen werden kann. - Bei einer bestimmten Menge an Trainingsdaten kann die Modellleistung anhand der oben genannten Faktoren geschätzt werden:
- Bei gleichem Komprimierungsverhältnis bedeutet ein höherer Trainingsverlust eine geringere Datenkonsistenz. Daher ist das vom Modell erlernte effektive Wissen möglicherweise begrenzter. Dies kann verwendet werden, um die Leistung von LLM bei verschiedenen Daten mit ähnlichem Komprimierungsverhältnis und ähnlicher Probenqualität vorherzusagen. Die Anwendung dieser Argumentation in der Praxis werden wir später zeigen.
Trainingsverlust L: Gibt an, ob die Daten für das Modell schwer zu merken sind. Unter demselben Basismodell ist ein hoher Trainingsverlust normalerweise auf das Vorhandensein von Rauschen oder inkonsistenten Informationen im Datensatz zurückzuführen.
Da ein Datensatz mit höherer Homogenität oder besserer Datenkonsistenz vom Modell leichter zu erlernen ist, wird L erwartet in R und C monoton sein. Daher können wir die obige Formel wie folgt umschreiben: 
wobei g' eine Umkehrfunktion ist. Durch die Kombination der obigen drei Gleichungen erhalten wir: 
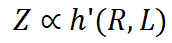
Basierend auf dem Entropiegesetz schlagen wir zwei Schlussfolgerungen vor:
- Wenn C als Konstante betrachtet wird, wird der Trainingsverlust direkt von der Kompressionsrate beeinflusst. Daher wird die Modellleistung durch das Komprimierungsverhältnis gesteuert: Wenn das Datenkomprimierungsverhältnis R höher ist, ist Z normalerweise schlechter, was in unseren Experimenten bestätigt wird.
Unter der Anleitung des Entropiegesetzes haben wir ZIP vorgeschlagen, eine Datenauswahlmethode, um Datenproben anhand der Datenkomprimierungsrate auszuwählen, mit dem Ziel, die zu maximieren Menge effektiver Informationen bei begrenztem Trainingsdatenbudget. Aus Effizienzgründen verwenden wir ein iteratives mehrstufiges Greedy-Paradigma, um Näherungslösungen mit relativ niedrigen Komprimierungsraten effizient zu erhalten. In jeder Iteration verwenden wir zunächst eine globale Auswahlphase, um einen Pool von Kandidatenproben mit niedrigem Komprimierungsverhältnis auszuwählen, um Proben mit hoher Informationsdichte zu finden. Anschließend verwenden wir eine grobkörnige lokale Auswahlstufe, um einen Satz kleinerer Stichproben auszuwählen, die mit den ausgewählten Stichproben die geringste Redundanz aufweisen. Schließlich verwenden wir eine feinkörnige lokale Auswahlstufe, um die Ähnlichkeit zwischen den hinzuzufügenden Proben zu minimieren. Der obige Prozess wird fortgesetzt, bis genügend Daten vorliegen:

Beim Vergleich verschiedener SFT-Datenauswahlalgorithmen zeigt das auf ZIP-Auswahldaten trainierte Modell Vorteile in der Leistung und ist auch in der Effizienz überlegen. Die spezifischen Ergebnisse sind in der folgenden Tabelle aufgeführt:
 Dank der modellunabhängigen und inhaltsunabhängigen Eigenschaften von ZIP kann es auch auf die Datenauswahl in der Präferenzausrichtungsphase angewendet werden. Auch die von ZIP ausgewählten Daten weisen große Vorteile auf. Die spezifischen Ergebnisse sind in der folgenden Tabelle aufgeführt: 2. Experimentelle Überprüfung des Entropiegesetzes des Modells in den vorherigen Trainingsschritten bzw. Es wurden mehrere Beziehungskurven angepasst. Die Ergebnisse sind in den Abbildungen 2 und 3 dargestellt, aus denen wir die enge Korrelation zwischen den drei Faktoren erkennen können. Erstens führen Daten mit niedriger Komprimierungsrate normalerweise zu besseren Modellergebnissen. Dies liegt daran, dass der Lernprozess von LLMs stark mit der Informationskomprimierung zusammenhängt. Wir können uns LLM als Datenkomprimierer vorstellen, sodass Daten mit niedrigerer Komprimierungsrate mehr Daten bedeuten Wissen und damit wertvoller für den Kompressor. Gleichzeitig ist zu beobachten, dass niedrigere Komprimierungsraten in der Regel mit höheren Trainingsverlusten einhergehen. Dies liegt daran, dass Daten, die schwer zu komprimieren sind, mehr Wissen enthalten, was das LLM vor größere Herausforderungen stellt, das darin enthaltene Wissen zu absorbieren.
Dank der modellunabhängigen und inhaltsunabhängigen Eigenschaften von ZIP kann es auch auf die Datenauswahl in der Präferenzausrichtungsphase angewendet werden. Auch die von ZIP ausgewählten Daten weisen große Vorteile auf. Die spezifischen Ergebnisse sind in der folgenden Tabelle aufgeführt: 2. Experimentelle Überprüfung des Entropiegesetzes des Modells in den vorherigen Trainingsschritten bzw. Es wurden mehrere Beziehungskurven angepasst. Die Ergebnisse sind in den Abbildungen 2 und 3 dargestellt, aus denen wir die enge Korrelation zwischen den drei Faktoren erkennen können. Erstens führen Daten mit niedriger Komprimierungsrate normalerweise zu besseren Modellergebnissen. Dies liegt daran, dass der Lernprozess von LLMs stark mit der Informationskomprimierung zusammenhängt. Wir können uns LLM als Datenkomprimierer vorstellen, sodass Daten mit niedrigerer Komprimierungsrate mehr Daten bedeuten Wissen und damit wertvoller für den Kompressor. Gleichzeitig ist zu beobachten, dass niedrigere Komprimierungsraten in der Regel mit höheren Trainingsverlusten einhergehen. Dies liegt daran, dass Daten, die schwer zu komprimieren sind, mehr Wissen enthalten, was das LLM vor größere Herausforderungen stellt, das darin enthaltene Wissen zu absorbieren.

Das obige ist der detaillierte Inhalt vonDie Universität für Wissenschaft und Technologie Chinas und Huawei Noah haben das Entropiegesetz vorgeschlagen, um den Zusammenhang zwischen der Leistung großer Modelle, der Datenkomprimierungsrate und dem Trainingsverlust aufzudecken.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr