
Heim >Technologie-Peripheriegeräte >KI >DynRefer übertrifft die CVPR 2024-Methode und erreicht mehrere SOTAs bei multimodalen Erkennungsaufgaben auf regionaler Ebene
DynRefer übertrifft die CVPR 2024-Methode und erreicht mehrere SOTAs bei multimodalen Erkennungsaufgaben auf regionaler Ebene

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2024-06-20 20:31:51691Durchsuche
Um ein hochpräzises multimodales Verständnis auf regionaler Ebene zu erreichen, schlägt dieser Artikel ein dynamisches Auflösungsschema zur Simulation des menschlichen visuellen kognitiven Systems vor.
Der Autor dieses Artikels stammt vom LAMP-Labor der Universität der Chinesischen Akademie der Wissenschaften. Der Erstautor Zhao Yuzhong ist Doktorand der Universität der Chinesischen Akademie der Wissenschaften im Jahr 2023 und der Co-Autor Liu Feng ist im Jahr 2020 direkter Doktorand der Universität der Chinesischen Akademie der Wissenschaften. Ihre Hauptforschungsrichtungen sind visuelle Sprachmodelle und visuelle Objektwahrnehmung.

Papiertitel: DynRefer: Delving into Region-level Multi-modality Tasks via Dynamic Resolution Papierlink: https://arxiv.org/abs/2405.16071 Papiercode: https ://github.com/callsys/DynRefer


Methode
1. Bild mit dynamischer Auflösung simulieren (Aufbau mit mehreren Ansichten).
 repräsentiert die Größe des gesamten Bildes und t repräsentiert den Interpolationskoeffizienten. Während des Trainings wählen wir zufällig n Ansichten aus Kandidatenansichten aus, um Bilder zu simulieren, die durch Blicke und schnelle Augenbewegungen erzeugt werden. Diese n Ansichten entsprechen dem Interpolationskoeffizienten t, der
repräsentiert die Größe des gesamten Bildes und t repräsentiert den Interpolationskoeffizienten. Während des Trainings wählen wir zufällig n Ansichten aus Kandidatenansichten aus, um Bilder zu simulieren, die durch Blicke und schnelle Augenbewegungen erzeugt werden. Diese n Ansichten entsprechen dem Interpolationskoeffizienten t, der  ist. Wir behalten die Ansicht fest bei, die nur den Referenzbereich enthält (d. h.
ist. Wir behalten die Ansicht fest bei, die nur den Referenzbereich enthält (d. h.  ). Es wurde experimentell nachgewiesen, dass diese Ansicht dazu beiträgt, regionale Details zu bewahren, was für alle regionalen multimodalen Aufgaben von entscheidender Bedeutung ist.
). Es wurde experimentell nachgewiesen, dass diese Ansicht dazu beiträgt, regionale Details zu bewahren, was für alle regionalen multimodalen Aufgaben von entscheidender Bedeutung ist. 


 . Dies ist auf der linken Seite von Abbildung 3 dargestellt. Diese Regionseinbettungen sind aufgrund von räumlichen Fehlern, die durch Zuschneiden, Größenänderung und RoI-Ausrichtung entstehen, nicht räumlich ausgerichtet. Inspiriert durch die verformbare Faltungsoperation schlagen wir ein Ausrichtungsmodul vor, um die Verzerrung zu reduzieren, indem
. Dies ist auf der linken Seite von Abbildung 3 dargestellt. Diese Regionseinbettungen sind aufgrund von räumlichen Fehlern, die durch Zuschneiden, Größenänderung und RoI-Ausrichtung entstehen, nicht räumlich ausgerichtet. Inspiriert durch die verformbare Faltungsoperation schlagen wir ein Ausrichtungsmodul vor, um die Verzerrung zu reduzieren, indem 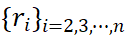 an
an  ausgerichtet wird, wobei
ausgerichtet wird, wobei  die Regionseinbettung der Ansichtskodierung ist, die nur die Referenzregion enthält. Für jede Region, die
die Regionseinbettung der Ansichtskodierung ist, die nur die Referenzregion enthält. Für jede Region, die  einbettet, wird sie zunächst mit
einbettet, wird sie zunächst mit  verkettet und dann wird eine 2D-Offset-Karte über eine Faltungsschicht berechnet. Die räumlichen Merkmale von
verkettet und dann wird eine 2D-Offset-Karte über eine Faltungsschicht berechnet. Die räumlichen Merkmale von  werden dann basierend auf dem 2D-Offset erneut abgetastet. Schließlich werden die ausgerichteten Regionseinbettungen entlang der Kanaldimension verkettet und durch lineare Schichten verschmolzen. Die Ausgabe wird durch ein visuelles Resampling-Modul, d. h. Q-Former, weiter komprimiert, wodurch eine regionale Darstellung des Referenzbereichs
werden dann basierend auf dem 2D-Offset erneut abgetastet. Schließlich werden die ausgerichteten Regionseinbettungen entlang der Kanaldimension verkettet und durch lineare Schichten verschmolzen. Die Ausgabe wird durch ein visuelles Resampling-Modul, d. h. Q-Former, weiter komprimiert, wodurch eine regionale Darstellung des Referenzbereichs  des Originalbilds x (
des Originalbilds x ( in Abbildung 3) extrahiert wird.
in Abbildung 3) extrahiert wird. 
 wird von drei Decodern
wird von drei Decodern  dekodiert, wie in Abbildung 3 (rechts) dargestellt, und jeweils von drei multimodalen Aufgaben überwacht:
dekodiert, wie in Abbildung 3 (rechts) dargestellt, und jeweils von drei multimodalen Aufgaben überwacht:  ist in Abbildung 3 (rechts) dargestellt. Der Tagging-Prozess wird abgeschlossen, indem die Konfidenz eines vordefinierten Tags berechnet wird, wobei das Tag als Abfrage,
ist in Abbildung 3 (rechts) dargestellt. Der Tagging-Prozess wird abgeschlossen, indem die Konfidenz eines vordefinierten Tags berechnet wird, wobei das Tag als Abfrage,  als Schlüssel und Wert verwendet wird. Wir analysieren Etiketten aus Ground-Truth-Untertiteln, um den Erkennungsdecoder zu überwachen. ii) Kontrastives Lernen von Region und Text. Ähnlich wie der Region-Tag-Decoder ist der Decoder
als Schlüssel und Wert verwendet wird. Wir analysieren Etiketten aus Ground-Truth-Untertiteln, um den Erkennungsdecoder zu überwachen. ii) Kontrastives Lernen von Region und Text. Ähnlich wie der Region-Tag-Decoder ist der Decoder  als abfragebasierter Erkennungsdecoder definiert. Der Decoder berechnet Ähnlichkeitswerte zwischen Untertiteln und Regionsmerkmalen und überwacht dabei den SigLIP-Verlust. iii) Sprachmodellierung. Wir verwenden ein vorab trainiertes großes Sprachmodell
als abfragebasierter Erkennungsdecoder definiert. Der Decoder berechnet Ähnlichkeitswerte zwischen Untertiteln und Regionsmerkmalen und überwacht dabei den SigLIP-Verlust. iii) Sprachmodellierung. Wir verwenden ein vorab trainiertes großes Sprachmodell  , um die regionale Darstellung
, um die regionale Darstellung  in eine Sprachbeschreibung umzuwandeln.
in eine Sprachbeschreibung umzuwandeln. 
 . Ansicht eins ist festgelegt (
. Ansicht eins ist festgelegt ( ), Ansicht zwei ist zufällig ausgewählt oder festgelegt.
), Ansicht zwei ist zufällig ausgewählt oder festgelegt.  der abgetasteten n Ansichten können wir eine regionale Darstellung mit dynamischen Auflösungseigenschaften erhalten. Um die Eigenschaften bei unterschiedlichen dynamischen Auflösungen zu bewerten, haben wir ein Dual-View-DynRefer-Modell (n=2) trainiert und es anhand von vier multimodalen Aufgaben ausgewertet. Wie aus der Kurve in Abbildung 4 ersichtlich ist, erzielt die Attributerkennung bessere Ergebnisse für Ansichten ohne Kontextinformationen (
der abgetasteten n Ansichten können wir eine regionale Darstellung mit dynamischen Auflösungseigenschaften erhalten. Um die Eigenschaften bei unterschiedlichen dynamischen Auflösungen zu bewerten, haben wir ein Dual-View-DynRefer-Modell (n=2) trainiert und es anhand von vier multimodalen Aufgaben ausgewertet. Wie aus der Kurve in Abbildung 4 ersichtlich ist, erzielt die Attributerkennung bessere Ergebnisse für Ansichten ohne Kontextinformationen ( ). Dies lässt sich dadurch erklären, dass für solche Aufgaben häufig detaillierte regionale Informationen erforderlich sind. Für Untertitelungsaufgaben auf Regionsebene und dichte Untertitel ist eine kontextreiche Ansicht (
). Dies lässt sich dadurch erklären, dass für solche Aufgaben häufig detaillierte regionale Informationen erforderlich sind. Für Untertitelungsaufgaben auf Regionsebene und dichte Untertitel ist eine kontextreiche Ansicht ( ) erforderlich, um die Referenzregion vollständig zu verstehen. Es ist wichtig zu beachten, dass Ansichten mit zu viel Kontext (
) erforderlich, um die Referenzregion vollständig zu verstehen. Es ist wichtig zu beachten, dass Ansichten mit zu viel Kontext ( ) die Leistung bei allen Aufgaben beeinträchtigen, weil sie zu viele Informationen einbringen, die für die Region nicht relevant sind. Wenn der Aufgabentyp bekannt ist, können wir anhand der Aufgabenmerkmale geeignete Ansichten testen. Wenn der Aufgabentyp unbekannt ist, erstellen wir zunächst eine Reihe von Kandidatenansichten unter verschiedenen Interpolationskoeffizienten t,
) die Leistung bei allen Aufgaben beeinträchtigen, weil sie zu viele Informationen einbringen, die für die Region nicht relevant sind. Wenn der Aufgabentyp bekannt ist, können wir anhand der Aufgabenmerkmale geeignete Ansichten testen. Wenn der Aufgabentyp unbekannt ist, erstellen wir zunächst eine Reihe von Kandidatenansichten unter verschiedenen Interpolationskoeffizienten t,  . Aus der Kandidatenmenge werden n Ansichten über einen Greedy-Suchalgorithmus abgetastet. Die Zielfunktion der Suche ist definiert als:
. Aus der Kandidatenmenge werden n Ansichten über einen Greedy-Suchalgorithmus abgetastet. Die Zielfunktion der Suche ist definiert als:  wobei
wobei  den Interpolationskoeffizienten der i-ten Ansicht darstellt,
den Interpolationskoeffizienten der i-ten Ansicht darstellt,  die i-te Ansicht darstellt, pHASH (・) die Wahrnehmungsbild-Hash-Funktion darstellt und
die i-te Ansicht darstellt, pHASH (・) die Wahrnehmungsbild-Hash-Funktion darstellt und  das XOR darstellt Betrieb. Um die Informationen von Ansichten aus einer globalen Perspektive zu vergleichen, verwenden wir die Funktion „pHASH (・)“, um die Ansichten aus dem räumlichen Bereich in den Frequenzbereich umzuwandeln und sie anschließend in Hash-Codes zu kodieren. Für diesen Artikel
das XOR darstellt Betrieb. Um die Informationen von Ansichten aus einer globalen Perspektive zu vergleichen, verwenden wir die Funktion „pHASH (・)“, um die Ansichten aus dem räumlichen Bereich in den Frequenzbereich umzuwandeln und sie anschließend in Hash-Codes zu kodieren. Für diesen Artikel  reduzieren wir die Gewichtung kontextreicher Ansichten, um zu vermeiden, dass zu viele redundante Informationen eingefügt werden.
reduzieren wir die Gewichtung kontextreicher Ansichten, um zu vermeiden, dass zu viele redundante Informationen eingefügt werden.





Zeile 1-6: Zufällige dynamische Mehrfachansicht ist besser als feste Ansicht. Zeile 6-10: Die Auswahl von Ansichten durch Maximierung der Informationen ist besser als die zufällige Auswahl von Ansichten. Zeile 10-13: Durch Multitasking-Training können bessere regionale Darstellungen erlernt werden.


Das obige ist der detaillierte Inhalt vonDynRefer übertrifft die CVPR 2024-Methode und erreicht mehrere SOTAs bei multimodalen Erkennungsaufgaben auf regionaler Ebene. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Mit dem „Exhibition Express' erkundet der Qingdao Artificial Intelligence Industrial Park neue Wege, um Investitionen anzuziehen
- Leitartikel|Der Bedarf an Rechenleistung explodiert unter dem Boom großer KI-Modelle: Lingang will eine zig-Milliarden-Industrie aufbauen, und SenseTime wird der „Kettenmeister'
- Inländische humanoide Allzweckroboter werden auf den Markt kommen und die Branche wird Durchbrüche beschleunigen
- Liu Qiang: Aufbau der nächsten Generation des Content-Ökosystems der Metaverse-Branche für den Internet-Kulturtourismus
- Die rasante Entwicklung des Hongmeng-Betriebssystems auf verschiedenen Geräten wird eine neue Industrie im Wert von Billionen eröffnen