
Heim >Technologie-Peripheriegeräte >KI >Von der College-Aufnahmeprüfung bis zur Olympia-Arena: der ultimative Kampf zwischen großen Models und menschlicher Intelligenz
Von der College-Aufnahmeprüfung bis zur Olympia-Arena: der ultimative Kampf zwischen großen Models und menschlicher Intelligenz

- PHPzOriginal
- 2024-06-20 21:14:41730Durchsuche

Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Das Forschungsteam des Generative Artificial Intelligence Laboratory (GAIR Lab) der Shanghai Jiao Tong University ist: großes Modelltraining, Ausrichtung und Auswertung. Team-Homepage: https://plms.ai/
In den nächsten 20 Jahren wird die KI voraussichtlich die menschliche Intelligenz übertreffen. Turing-Award-Gewinner Hinton erwähnte in seinem Interview, dass „KI in den nächsten 20 Jahren voraussichtlich das Niveau menschlicher Intelligenz übertreffen wird“ und schlug vor, dass große Technologieunternehmen frühzeitig Vorbereitungen treffen, um die „Effizienz“ großer Modelle (einschließlich multimodaler Modelle) zu bewerten große Modelle) „Intelligenzniveau“ ist eine notwendige Voraussetzung für diese Vorbereitung.
Ein Benchmark zur Bewertung der kognitiven Denkfähigkeit mit einem interdisziplinären Problemsatz, der die KI aus mehreren Dimensionen rigoros bewerten kann, ist sehr dringend geworden.
2. Der höchste Palast des intellektuellen Wettbewerbs: von der KI-Hochschulaufnahmeprüfung bis zur KI-Olympiade



Papieradresse: https://arxiv.org/pdf/2406.12753 Projektadresse: https://gair-nlp.github.io/OlympicArena/ -
Codeadresse: https ://github.com/GAIR-NLP/OlympicArena die Bewertung von richtig und falsch und die Bewertung jedes einzelnen Argumentationsschrittes). Umfassend: OlympicArena umfasst insgesamt 11.163 Fragen aus 62 verschiedenen olympischen Wettbewerben, die sieben Kernfächer abdecken: Mathematik, Physik, Chemie, Biologie, Geographie, Astronomie und Computer, mit 34 Berufszweigen. Gleichzeitig unterstützt OlympicArena im Gegensatz zu früheren Benchmarks, die sich hauptsächlich auf objektive Fragen wie Multiple-Choice-Fragen konzentrierten, eine Vielzahl von Fragetypen, darunter Ausdrücke, Gleichungen, Intervalle, das Schreiben chemischer Gleichungen und sogar Programmierfragen. Darüber hinaus unterstützt OlympicArena Multimodalität (fast die Hälfte der Fragen enthält Bilder) und verwendet ein Eingabeformat (verschachteltes Text-Bild), das der Realität am besten entspricht, wodurch die Verwendung visueller Informationen zur Unterstützung großer Modelle bei der Erledigung von Aufgaben umfassend getestet wird . Die Fähigkeit zur Vernunft. Extrem anspruchsvoll: Im Gegensatz zu früheren Benchmarks, die sich entweder auf Fragen zur High-School-Aufnahmeprüfung oder auf College-Fragen konzentrierten, konzentriert sich OlympicArena eher auf die reine Prüfung komplexer Denkfähigkeiten als auf das massive Wissen großer Gedächtnismodelle , Rückruffähigkeit oder einfache Anwendungsfähigkeit. Daher haben alle Fragen in der OlympicArena den Schwierigkeitsgrad „Olympiade“. Um die Leistung großer Modelle in Bezug auf verschiedene Arten von Denkfähigkeiten feinkörnig zu bewerten, fasste das Forschungsteam außerdem acht Arten logischer Denkfähigkeiten und fünf Arten visueller Denkfähigkeiten zusammen und analysierte anschließend speziell die Leistung bestehender großer Modelle Modelle in verschiedenen Arten von Denkfähigkeiten. Strenge: Die Rolle, die die Wissenschaft bei öffentlichen Benchmarks spielen sollte, ist die Steuerung der gesunden Entwicklung großer Modelle. Derzeit treten bei vielen beliebten großen Modellen Probleme mit Datenlecks auf (d. h. die Testdaten des Benchmarks werden durchgesickert). großes Modell) in den Trainingsdaten). Daher testete das Forschungsteam speziell die Datenlecks von OlympicArena bei einigen beliebten Großmodellen, um die Wirksamkeit des Benchmarks genauer zu überprüfen. Feinkörnige Bewertung: Bisherige Benchmarks bewerten häufig nur, ob die endgültige Antwort eines großen Modells mit der richtigen Antwort übereinstimmt. Dies ist einseitig bei der Bewertung sehr komplexer Argumentationsprobleme und kann das aktuelle Modell nicht gut widerspiegeln . Realistischere Denkfähigkeiten. Daher umfasste das Forschungsteam neben der Bewertung der Antworten auch eine Bewertung der Korrektheit des Frageprozesses (Schritte). Gleichzeitig analysierte das Forschungsteam auch unterschiedliche Ergebnisse aus mehreren verschiedenen Dimensionen, beispielsweise die Analyse der Leistungsunterschiede von Modellen in verschiedenen Disziplinen, unterschiedlichen Modalitäten und unterschiedlichen Argumentationsfähigkeiten.
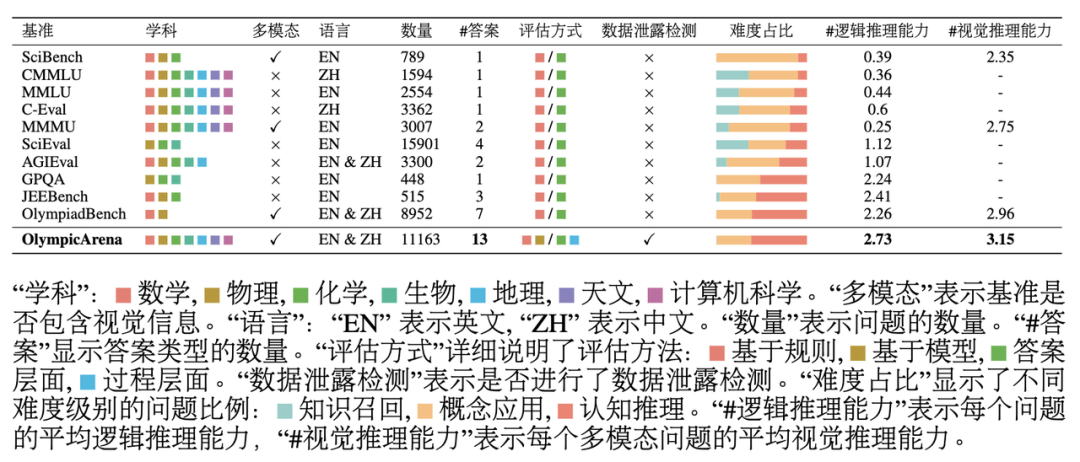
Vergleich mit verwandten Benchmarks 
Wie aus der obigen Tabelle ersichtlich ist: OlympicArena hat großen Einfluss auf die Denkfähigkeit in Bezug auf die Abdeckung von Themen, Sprachen und Modalitäten sowie die Die Vielfalt der Fragetypen unterscheidet sich deutlich von anderen bestehenden Benchmarks, die sich auf die Bewertung wissenschaftlicher Fragestellungen konzentrieren.
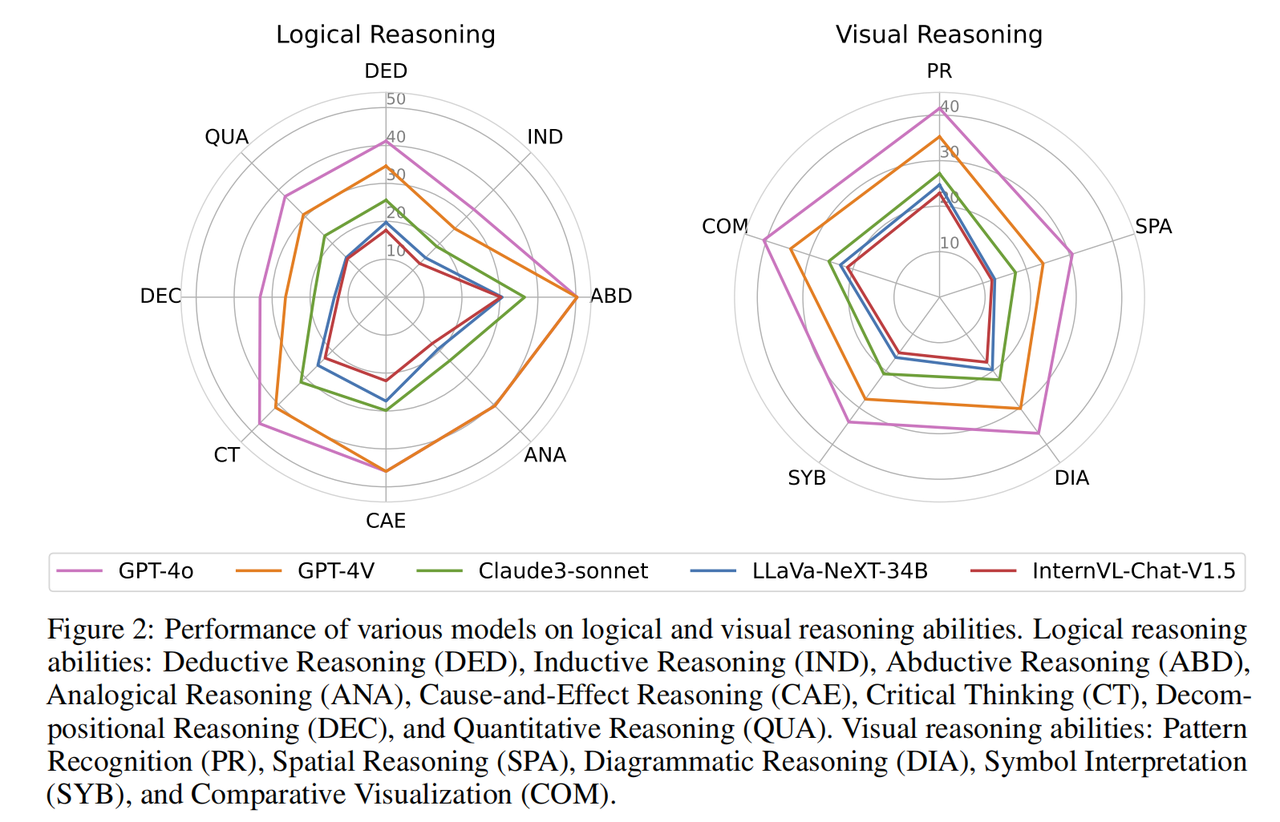
... . Für das multimodale große Modell wurde die Eingabeform „Interleaved Text-Image“ verwendet; für das große Klartextmodell wurden Tests unter zwei Einstellungen durchgeführt, nämlich der Klartexteingabe ohne Bildinformationen (nur Text-LLMs). Texteingabe mit Bildbeschreibungsinformationen (Bildunterschrift + LLMs). Der Zweck des Hinzufügens von Klartext-Großmodelltests besteht nicht nur darin, den Anwendungsbereich dieses Benchmarks zu erweitern (so dass alle LLMs an der Rangliste teilnehmen können), sondern auch darin, die Leistung bestehender multimodaler Großmodelle besser zu verstehen und zu analysieren Ob es im Vergleich zu großen reinen Textmodellen Bildinformationen vollständig nutzen kann, um seine Problemlösungsfähigkeiten zu verbessern. Bei allen Experimenten wurden Zero-Shot-CoT-Eingabeaufforderungen verwendet, die das Forschungsteam für jeden Antworttyp anpasste und das Ausgabeformat festlegte, um die Antwortextraktion und den regelbasierten Abgleich zu erleichtern.Experimentelle Ergebnisse Die Genauigkeit verschiedener Modelle in verschiedenen Fächern von OlympicArena verwendet den unvoreingenommenen pass@k-Index und der Rest den Genauigkeitsindex. Aus den experimentellen Ergebnissen in der Tabelle geht hervor, dass alle derzeit auf dem Markt befindlichen Mainstream-Großmodelle kein hohes Niveau aufweisen. Selbst das fortschrittlichste Großmodell GPT-4o weist eine Gesamtgenauigkeit von nur 39,97 % auf, während andere Die Gesamtgenauigkeit des Open-Source-Modells ist schwierig, 20 % zu erreichen. Dieser offensichtliche Unterschied unterstreicht die Herausforderung dieses Benchmarks und beweist, dass er eine große Rolle dabei gespielt hat, die Obergrenze der aktuellen KI-Folgefähigkeiten zu erweitern. Darüber hinaus stellte das Forschungsteam fest, dass Mathematik und Physik immer noch die beiden schwierigsten Fächer sind, da sie stärker auf komplexe und flexible Denkfähigkeiten angewiesen sind, mehr Denkschritte aufweisen und umfassendere und angewandte Denkfähigkeiten erfordern. Vielfältig. In Fächern wie Biologie und Geographie ist die Genauigkeitsrate relativ hoch, da diese Fächer mehr Wert auf die Fähigkeit legen, umfangreiche wissenschaftliche Erkenntnisse zur Lösung und Analyse praktischer Probleme zu nutzen, wobei der Schwerpunkt auf der Untersuchung von Abduktions- und Kausalschlussfähigkeiten liegt, im Vergleich zu komplexen Fächern Induktion, deduktives Denken und große Modelle sind bei der Analyse solcher Themen mit Hilfe des umfangreichen Wissens, das sie während ihrer eigenen Ausbildungsphase erworben haben, besser in der Lage. Computerprogrammierungswettbewerbe haben sich ebenfalls als sehr schwierig erwiesen, da einige Open-Source-Modelle nicht einmal in der Lage waren, eines der darin enthaltenen Probleme zu lösen (Genauigkeit 0), was zeigt, wie leistungsfähig aktuelle Modelle bei der Entwicklung effektiver Algorithmen zur Lösung sind Komplexe Probleme programmgesteuert lösen Es gibt noch viel Raum für Verbesserungen. Es ist erwähnenswert, dass die ursprüngliche Absicht von OlympicArena nicht darin bestand, die Schwierigkeit der Fragen blind zu verfolgen, sondern die Fähigkeit großer Modelle, disziplinübergreifend zu arbeiten und die Fähigkeit zum mehrfachen Denken zu nutzen, um praktische wissenschaftliche Probleme zu lösen, voll auszuschöpfen. Die oben erwähnte Denkfähigkeit unter Verwendung komplexer Argumente, die Fähigkeit, umfassende wissenschaftliche Erkenntnisse zur Lösung und Analyse praktischer Probleme zu nutzen und die Fähigkeit, effiziente und genaue Programme zur Lösung von Problemen zu schreiben, sind im Bereich der wissenschaftlichen Forschung seit jeher unverzichtbar der Maßstab für diesen Benchmark. Feinkörnige experimentelle Analyse Um eine detailliertere Analyse der experimentellen Ergebnisse zu erreichen, führte das Forschungsteam eine weitere Auswertung auf der Grundlage verschiedener Modalitäten und Argumentationsfähigkeiten durch. Darüber hinaus führte das Forschungsteam auch eine Bewertung und Analyse des Argumentationsprozesses des Modells für Fragen durch. Die wichtigsten Erkenntnisse lauten wie folgt: Die Modelle schneiden bei unterschiedlichen logischen und visuellen Denkfähigkeiten unterschiedlich ab. Zu den Fähigkeiten des logischen Denkens gehören: deduktives Denken (DED), induktives Denken (IND), abduktives Denken (ABD), analoges Denken (ANA), kausales Denken (CAE), kritisches Denken (CT), Dekompositionsdenken (DEC) und quantitatives Denken ( QUA). Zu den Fähigkeiten zum visuellen Denken gehören: Mustererkennung (PR), räumliches Denken (SPA), schematisches Denken (DIA), symbolische Interpretation (SYB) und visueller Vergleich (COM). Fast alle Modelle weisen ähnliche Leistungstrends bei unterschiedlichen logischen Denkfähigkeiten auf. Sie zeichnen sich durch abduktives und kausales Denken aus und sind gut in der Lage, Ursache-Wirkungs-Beziehungen anhand der bereitgestellten Informationen zu erkennen. Im Gegensatz dazu schneidet das Modell beim induktiven Denken und beim Zerlegungsdenken schlecht ab. Dies ist auf die Vielfältigkeit und den nicht routinemäßigen Charakter von Problemen auf Olympia-Ebene zurückzuführen, die die Fähigkeit erfordern, komplexe Probleme in kleinere Teilprobleme zu zerlegen, was darauf beruht, dass das Modell jedes Teilproblem erfolgreich löst und die Teilprobleme kombiniert das größere Problem lösen. In Bezug auf die visuellen Denkfähigkeiten schnitt das Modell bei der Mustererkennung und dem visuellen Vergleich besser ab. Sie haben jedoch Schwierigkeiten, Aufgaben auszuführen, die räumliches und geometrisches Denken erfordern, sowie Aufgaben, die das Verständnis abstrakter Symbole erfordern. Aus der feinkörnigen Analyse verschiedener Denkfähigkeiten sind die Fähigkeiten, die großen Modellen fehlen (z. B. die Zerlegung komplexer Probleme, das visuelle Denken geometrischer Figuren usw.), unverzichtbare und entscheidende Fähigkeiten in der wissenschaftlichen Forschung, was darauf hinweist, dass es noch eine lange Zeit ist Es ist noch ein langer Weg, bis KI den Menschen in der wissenschaftlichen Forschung in allen Aspekten wirklich unterstützen kann. Vergleich verschiedener multimodaler Modelle (LMMs) und ihrer entsprechenden Nur-Text-Modelle (LLMs) in drei verschiedenen experimentellen Umgebungen.
Die meisten multimodalen Modelle (LMMs) sind immer noch nicht gut darin, visuelle Informationen als Argumentationshilfe zu nutzen Wie oben in (a) gezeigt, gibt es nur wenige große multimodale Modelle (wie GPT -4o und Qwen-VL -Chat) zeigt bei Bildeingabe deutliche Leistungsverbesserungen im Vergleich zu seinem Nur-Text-Pendant. Viele große multimodale Modelle zeigen keine Leistungsverbesserung bei der Eingabe von Bildern oder zeigen sogar Leistungseinbußen bei der Verarbeitung von Bildern. Mögliche Gründe sind: Wenn Text und Bilder zusammen eingegeben werden, achten LMMs möglicherweise mehr auf den Text und ignorieren die Informationen im Bild. Einige LMMs verlieren möglicherweise einige ihrer inhärenten Sprachfähigkeiten (z. B. Denkfähigkeiten), wenn sie visuelle Fähigkeiten basierend auf ihren Textmodellen trainieren, was in den komplexen Szenarien dieses Projekts besonders deutlich wird. Diese Benchmark-Frage verwendet ein komplexes Text-Bild-Umbruch-Eingabeformat. Einige Modelle unterstützen dieses Format nicht gut, was dazu führt, dass sie in Text eingebettete Bildpositionsinformationen nicht verarbeiten und verstehen können.
In der wissenschaftlichen Forschung wird sie oft von einer sehr großen Menge visueller Informationen wie Diagrammen, geometrischen Figuren und visuellen Daten begleitet. Nur wenn die KI ihre visuellen Fähigkeiten geschickt zur Unterstützung des Denkens einsetzen kann, kann sie zur Förderung beitragen Die Effizienz und Innovation der wissenschaftlichen Forschung sind zu leistungsstarken Werkzeugen zur Lösung komplexer wissenschaftlicher Probleme geworden. Linkes Bild: Die Korrelation zwischen der Richtigkeit der Antworten und der Richtigkeit des Prozesses für alle Modelle in allen Fragen, bei denen der Inferenzprozess bewertet wird. Rechts: Verteilung der Orte fehlerhafter Prozessschritte.
Analyse der Bewertungsergebnisse des Inferenzschritts Durch die Durchführung einer feinkörnigen Bewertung der Korrektheit des Modellinferenzschritts stellte das Forschungsteam Folgendes fest: Wie in (b ) oben, Bewertung auf Stufenebene. Normalerweise besteht ein hohes Maß an Übereinstimmung zwischen den Ergebnissen und Bewertungen, die ausschließlich auf Antworten basieren. Wenn ein Modell korrekte Antworten generiert, ist die Qualität seines Inferenzprozesses meist höher. Die Genauigkeit des Argumentationsprozesses ist normalerweise höher als die Genauigkeit, die sich nur durch das Betrachten der Antworten ergibt. Dies zeigt, dass das Modell auch bei sehr komplexen Problemen einige Zwischenschritte korrekt ausführen kann. Daher können Modelle ein erhebliches Potenzial für das kognitive Denken haben, was Forschern neue Forschungsrichtungen eröffnet. Das Forschungsteam stellte außerdem fest, dass in einigen Disziplinen einige Modelle, die gut abschnitten, wenn sie ausschließlich anhand von Antworten bewertet wurden, beim Inferenzprozess schlecht abschnitten. Das Forschungsteam vermutet, dass dies daran liegt, dass Modelle bei der Generierung von Antworten manchmal die Plausibilität von Zwischenschritten ignorieren, obwohl diese Schritte für das Endergebnis möglicherweise nicht entscheidend sind. Darüber hinaus führte das Forschungsteam eine statistische Analyse der Ortsverteilung von Fehlerschritten durch (siehe Abbildung c) und stellte fest, dass in den späteren Argumentationsschritten einer Frage ein höherer Anteil an Fehlern auftrat. Dies zeigt, dass das Modell mit der Akkumulation des Argumentationsprozesses anfälliger für Fehler ist und eine Anhäufung von Fehlern erzeugt, was zeigt, dass das Modell beim Umgang mit langkettigem logischen Denken noch viel Raum für Verbesserungen bietet.
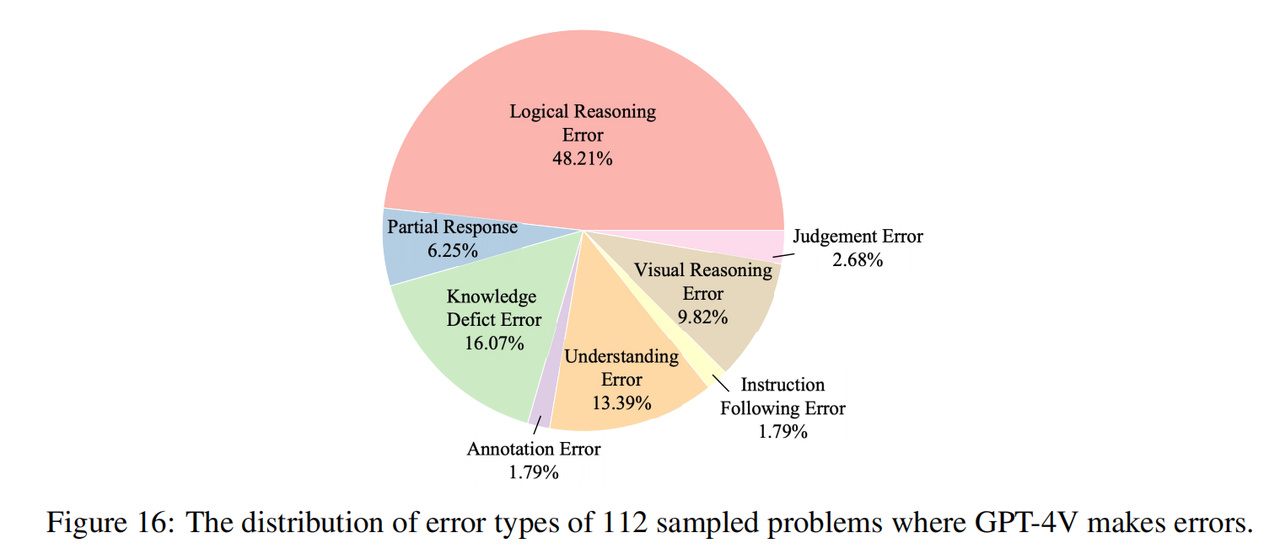
Das Team fordert außerdem alle Forscher auf, der Überwachung und Bewertung des Modellinferenzprozesses bei KI-Inferenzaufgaben mehr Aufmerksamkeit zu schenken. Dies kann nicht nur die Glaubwürdigkeit und Transparenz des KI-Systems verbessern und dazu beitragen, den Argumentationspfad des Modells besser zu verstehen, sondern auch die Schwachstellen des Modells in komplexen Überlegungen identifizieren und so die Verbesserung der Modellstruktur und Trainingsmethoden steuern. Durch eine sorgfältige Prozessüberwachung können die Potenziale von KI weiter erforscht und ihr breiter Einsatz in der wissenschaftlichen Forschung und praktischen Anwendung gefördert werden. Analyse von Modellfehlertypen Das Forschungsteam hat 112 Fragen mit falschen Antworten in GPT-4V untersucht (16 Fragen in jedem Fach, davon 8 reine Textfragen und 8 multimodale Fragen) und die Gründe für diese Fehler manuell markiert. Wie in der Abbildung oben gezeigt, stellen Denkfehler (einschließlich logischer Denkfehler und visueller Denkfehler) die größte Fehlerursache dar. Dies zeigt, dass unser Benchmark die Mängel aktueller Modelle in Bezug auf kognitive Denkfähigkeiten effektiv hervorhebt, was mit der ursprünglichen Absicht übereinstimmt des Forschungsteams von. Darüber hinaus ist ein erheblicher Teil der Fehler auch auf mangelndes Wissen zurückzuführen (obwohl die Olympia-Fragen nur auf High-School-Wissen basieren), was zeigt, dass dem aktuellen Modell Domänenkenntnisse fehlen und es eher unbrauchbar ist Dieses Wissen hilft beim Denken. Eine weitere häufige Fehlerursache ist die Verzerrung des Verständnisses, die auf ein Missverständnis des Modells über den Kontext und Schwierigkeiten bei der Integration komplexer Sprachstrukturen und multimodaler Informationen zurückzuführen ist. Ein Beispiel dafür, wie GPT-4V bei einer Mathematikolympiade-Frage Fehler macht.
Erkennung von Datenlecks Machen Sie die richtige Menge. Da der Umfang des Pre-Training-Korpus immer größer wird, ist es von entscheidender Bedeutung, potenzielle Datenlecks im Benchmark zu erkennen. Die Undurchsichtigkeit des Pre-Training-Prozesses macht diese Aufgabe oft zu einer Herausforderung. Zu diesem Zweck hat das Forschungsteam eine neu vorgeschlagene Leckerkennungsmetrik auf Instanzebene namens „N-Gramm-Vorhersagegenauigkeit“ übernommen. Diese Metrik tastet gleichmäßig mehrere Startpunkte von jeder Instanz ab, sagt das nächste N-Gramm für jeden Startpunkt voraus und prüft, ob alle vorhergesagten N-Gramm korrekt sind, um festzustellen, ob das Modell möglicherweise während der Trainingsphase darauf gestoßen ist. Das Forschungsteam wandte diese Metrik auf alle verfügbaren Basismodelle an.
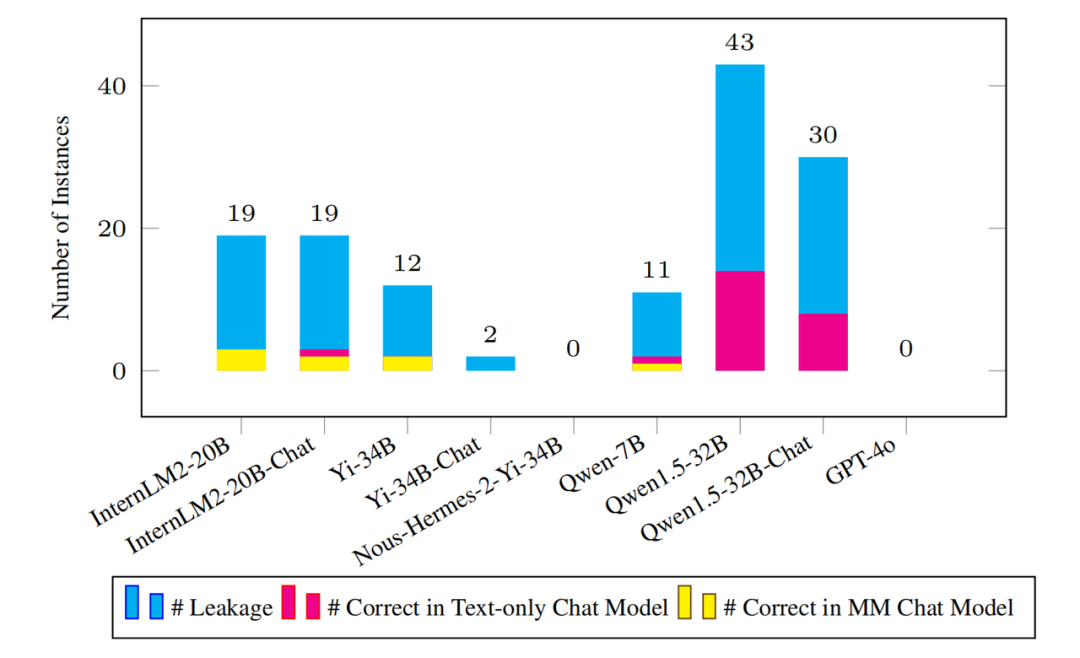
Wie in der Abbildung oben gezeigt, weist das Mainstream-Modell keine nennenswerten Datenverlustprobleme in der Olympic Arena auf. Selbst wenn es einen Verlust gibt, ist die Menge im Vergleich zum vollständigen Benchmark-Datensatz unbedeutend. Beispielsweise wurden beim Modell Qwen1.5-32B mit den meisten Lecks nur 43 mutmaßliche Lecks erkannt. Dies wirft natürlich die Frage auf: Kann das Modell diese durchgesickerten Instanzfragen richtig beantworten?Fazit Obwohl die OlympicArena einen sehr hohen Wert hat, gab das Forschungsteam an, dass es in Zukunft noch viel zu tun gibt. Erstens wird der OlympicArena-Benchmark unweigerlich einige verrauschte Daten einführen, und der Autor wird das Community-Feedback aktiv nutzen, um ihn kontinuierlich zu verbessern und zu verbessern. Darüber hinaus plant das Forschungsteam, jedes Jahr neue Versionen des Benchmarks zu veröffentlichen, um Probleme im Zusammenhang mit Datenschutzverletzungen weiter zu entschärfen. Darüber hinaus beschränken sich aktuelle Benchmarks auf längere Sicht auf die Bewertung der Fähigkeit eines Modells, komplexe Probleme zu lösen.
Abschließend sagte das Forschungsteam auch, dass die Olympischen Spiele nur der Anfang der OlympicArena sein werden und weitere Fähigkeiten der KI einer kontinuierlichen Erforschung wert sind. Beispielsweise wird die olympische Sportarena zu einer Arena der verkörperten Intelligenz in der Zukunft.[1] reStructured Pre-training, arXiv 2022, Weizhe Yuan, Pengfei Liu




Das obige ist der detaillierte Inhalt vonVon der College-Aufnahmeprüfung bis zur Olympia-Arena: der ultimative Kampf zwischen großen Models und menschlicher Intelligenz. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!