
Heim >Technologie-Peripheriegeräte >KI >LLM |. Yuan 2.0-M32: Expertenmischungsmodell mit Aufmerksamkeitsrouting
LLM |. Yuan 2.0-M32: Expertenmischungsmodell mit Aufmerksamkeitsrouting

- PHPzOriginal
- 2024-06-07 09:06:30703Durchsuche
 Bilder
Bilder
1. Fazit vorab geschrieben
Yuan+2.0-M32 ist eine Infrastruktur, ähnlich Yuan-2.0+2B, die eine Experten-Hybridarchitektur mit 32 Experten verwendet. 2 dieser Experten sind aktiv. Es wird eine Experten-Hybridarchitektur mit 32 Experten vorgeschlagen und übernommen, um Experten effizienter auszuwählen. Im Vergleich zum Modell mit dem klassischen Routing-Netzwerk wird die Genauigkeitsrate um 3,8 % verbessert. Yuan+2.0-M32 wird von Grund auf mit 2000B-Tokens trainiert und sein Trainingsverbrauch beträgt nur 9,25 % des eines dichten Ensemble-Modells mit der gleichen Parametergröße. Um Experten besser auswählen zu können, wird der Aufmerksamkeitsrouter eingeführt, der über die Fähigkeit verfügt, schnell zu erkennen und so eine bessere Auswahl von Experten zu ermöglichen.
Yuan 2.0-M32 hat seine Wettbewerbsfähigkeit in den Bereichen Codierung, Mathematik und mehreren Berufsfeldern unter Beweis gestellt, indem es nur 3,7 Milliarden aktive Parameter von 40 Milliarden Gesamtparametern verwendet und 7,4 GFlops pro Token vorwärts berechnet. Alle Indikatoren betragen nur 1/. 19 von Lama3-70B. Yuan 2.0-M32 übertraf Llama3-70B in den MATH- und ARC-Challenge-Benchmarks mit Genauigkeitsraten von 55,89 % bzw. 95,8 %. Das Modell und der Quellcode von Yuan 2.0-M32 sind auf GitHub: https://github.com/IEIT-Yuan/Yuan2.0-M32. 2. Kurze Einleitung des Papiers Leicht zu konstruieren, indem die Anzahl der Experten erhöht wird. Größerer Maßstab als Modelle mit dichter Menge, was zu einer höheren Genauigkeitsleistung führt. Tatsächlich gilt MoE beim Training von Modellen mit begrenzten Rechenressourcen als hervorragende Option, um die mit Modell, Datensatzgröße und begrenzter Rechenleistung verbundenen Kosten zu senken.
Das Konzept von MoE (Mixture of Experts) geht auf das Jahr 1991 zurück. Der Gesamtverlust ist eine Kombination der gewichteten Verluste jedes Experten, der über die Fähigkeit verfügt, unabhängige Urteile zu fällen. Das Konzept des spärlich gesteuerten MoE wurde ursprünglich von Shazeer et al. (2017) in Übersetzungsmodellen vorgeschlagen. Bei dieser Routing-Strategie werden beim Stellen von Fragen nur wenige Experten aktiviert und nicht alle Experten gleichzeitig angerufen. Diese Sparsität ermöglicht eine bis zu 1000-fache Skalierung des Modells zwischen gestapelten LSTM-Schichten mit minimalem Verlust an Recheneffizienz. Das durch Rauschen einstellbare Top-K-Gating-Routing führt einstellbares Rauschen aus dem Netzwerk in die Softmax-Funktion ein und behält den K-Wert bei, um die Expertenauslastung auszugleichen. In den letzten Jahren haben Routing-Strategien mit der kontinuierlichen Erweiterung des Modellmaßstabs mehr Aufmerksamkeit für die effiziente Zuweisung von Rechenressourcen erhalten.Das Experten-Routing-Netzwerk ist der Kern der MoE-Struktur. Diese Struktur wählt Kandidatenexperten aus, die an der Berechnung teilnehmen sollen, indem sie die Wahrscheinlichkeit der Token-Zuweisung zu jedem Experten berechnet. Derzeit wird in den meisten gängigen MoE-Strukturen häufig der klassische Routing-Algorithmus verwendet, der das Skalarprodukt zwischen dem Token und dem Merkmalsvektor jedes Experten durchführt und den Experten mit dem größten Skalarprodukt als Gewinner auswählt. Bei dieser Wahl sind die Merkmalsvektoren der Experten unabhängig und die Korrelation zwischen Experten wird ignoriert. Allerdings wählt die MoE-Struktur in der Regel mehr als einen Experten gleichzeitig aus, und es kann Korrelationen zwischen den Merkmalen verschiedener Experten geben. Daher können in diesem Fall die ausgewählten Merkmalsvektoren Überlappungen und Konflikte für die Skalarprodukte zwischen den einzelnen an der Berechnung beteiligten Experten aufweisen, was wiederum Auswirkungen auf die Genauigkeit der Ergebnisse hat. Die MoE-Struktur wählt jedoch normalerweise mehr als einen Experten gleichzeitig aus, und es kann zu Korrelationen zwischen den Merkmalen verschiedener Experten kommen. Daher können sich in diesem Fall die vom klassischen Routing-Algorithmus ausgewählten Merkmalsvektoren überschneiden und in Konflikt geraten, was sich auf die Berechnung auswirkt Genauigkeit. Um dieses Problem zu lösen, verwenden MoE-Strukturen häufig Merkmalsvektoren unabhängiger Experten, was bedeutet, dass jeder Experte als völlig unabhängig behandelt wird, während die Korrelation zwischen Experten ignoriert wird. Dieser Ansatz kann jedoch einige Probleme verursachen. Daher wählt die MoE-Struktur bei der Auswahl von Experten normalerweise mehr als einen Experten aus, und es kann zu Korrelationen zwischen den Merkmalen verschiedener Experten kommen. In diesem Fall können die ausgewählten Merkmalsvektoren Überlappungen und Konflikte für die Skalarprodukte zwischen den einzelnen an der Berechnung beteiligten Experten aufweisen, was wiederum Auswirkungen auf die Genauigkeit der Ergebnisse hat. Daher erfordert die MoE-Struktur einen genaueren Routing-Algorithmus, um die besten Experten auszuwählen, und die Auswahl muss berücksichtigt werden. 2B-Modellstruktur, Yuan 2.0 führt lokale filterbasierte Aufmerksamkeit (LFA) ein, um die lokale Abhängigkeit von Eingabe-Tokens zu berücksichtigen und dadurch die Genauigkeit des Modells zu verbessern. In Yuan 2.0-M32 wird das dichte Feed-Forward-Netzwerk (FFN) jeder Schicht durch MoE-Komponenten ersetzt.
Abbildung 1 zeigt die Architektur der im Papiermodell angewendeten MoE-Schicht. Am Beispiel von vier FFNs (eigentlich gibt es 32 Experten) besteht jede MoE-Schicht aus einem unabhängigen FFN als Experten. Da das Expertenpfadnetzwerk den relevanten Experten Eingabetoken zuweist, erstellt das klassische Pfadnetzwerk für jeden Experten einen Merkmalsvektor. Und berechnen Sie das Skalarprodukt zwischen dem Eingabe-Token und jedem Experten-Merkmalsvektor, um die Ähnlichkeit zwischen dem Token und jedem Experten zu erhalten. Der Experte mit der höchsten Ähnlichkeit wird zur Berechnung der Ausgabe herangezogen. Der Experte mit der stärksten Ähnlichkeit wird zur Aktivierung ausgewählt und nimmt an den nachfolgenden Berechnungen teil.
Bild 1 Abbildung 1: Erklärung von Yuan 2,0-M32. Das Bild links zeigt die Erweiterung der MoE-Schicht in der Yuan 2.0-Architektur. Die MoE-Schicht ersetzt die Feedforward-Schicht in Yuan 2.0. Die Abbildung rechts zeigt den Aufbau der MoE-Schicht. Im Modell des Aufsatzes wird jedes Eingabe-Token zwei von insgesamt 32 Experten zugewiesen, und in der Abbildung werden im Aufsatz 4 Experten als Beispiel verwendet. Der Output des MoE ist die gewichtete Summe der ausgewählten Experten. N steht für die Anzahl der Schichten. Die Merkmalsvektoren jedes Experten sind unabhängig voneinander und die Korrelation zwischen Experten wird bei der Berechnung der Wahrscheinlichkeit ignoriert. Tatsächlich werden in den meisten MoE-Modellen normalerweise zwei oder mehr Experten ausgewählt, um an nachfolgenden Berechnungen teilzunehmen, was natürlich zu einer starken Korrelation zwischen Experten führt. Die Berücksichtigung von Korrelationen zwischen Experten trägt sicherlich zur Verbesserung der Genauigkeit bei.
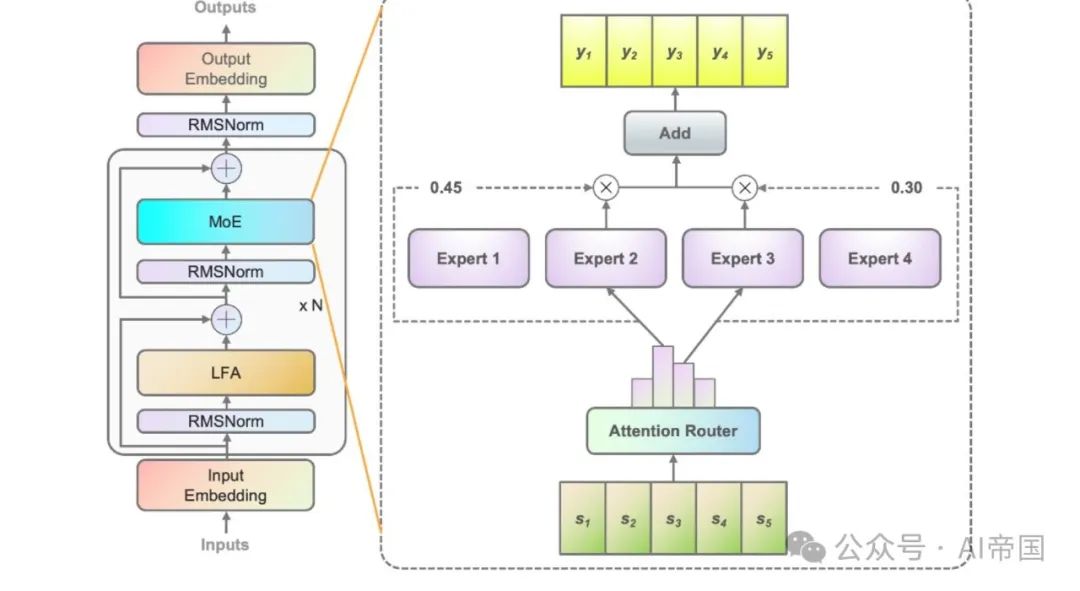 Abbildung 2(b) zeigt die Architektur des in dieser Arbeit vorgeschlagenen Aufmerksamkeitsrouters. Dieses neuartige Routing-Netzwerk integriert die Korrelation zwischen Experten durch die Übernahme des Aufmerksamkeitsmechanismus. Eine Koeffizientenmatrix, die die Korrelation zwischen Experten darstellt, wird erstellt und bei der Berechnung des endgültigen Wahrscheinlichkeitswerts angewendet.
Abbildung 2(b) zeigt die Architektur des in dieser Arbeit vorgeschlagenen Aufmerksamkeitsrouters. Dieses neuartige Routing-Netzwerk integriert die Korrelation zwischen Experten durch die Übernahme des Aufmerksamkeitsmechanismus. Eine Koeffizientenmatrix, die die Korrelation zwischen Experten darstellt, wird erstellt und bei der Berechnung des endgültigen Wahrscheinlichkeitswerts angewendet.
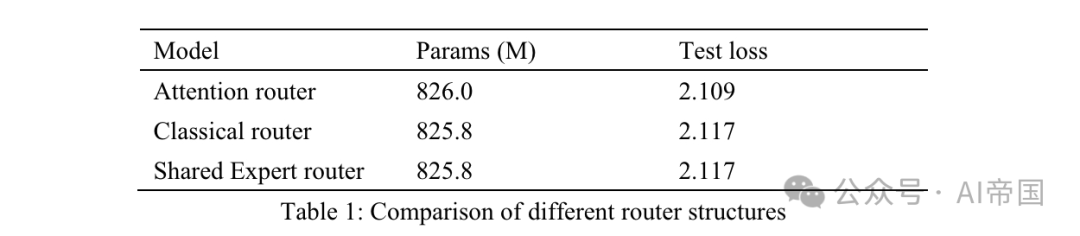
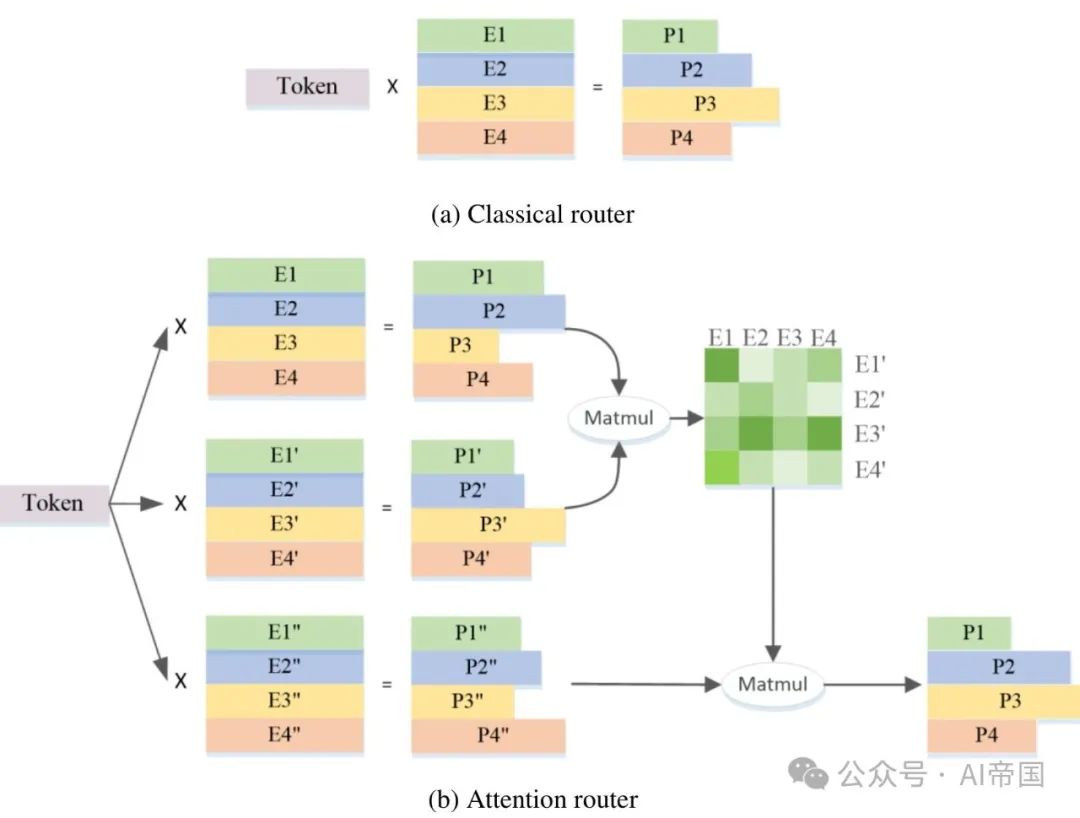 Tabelle 1: Vergleich verschiedener Routing-Strukturen
Tabelle 1: Vergleich verschiedener Routing-Strukturen
Tabelle 1 listet die Genauigkeitsergebnisse verschiedener Router auf. Das Modell des Papiers testete den Aufmerksamkeitsrouter an acht schulbaren Experten. Das klassische Router-Modell verfügt über 8 trainierbare Experten, um eine ähnliche Parameterskala sicherzustellen, und die Routing-Struktur ist dieselbe wie bei Mixtral 8*7B, d. h. Softmax auf einer linearen Ebene. Der Shared-Expert-Router übernimmt die Shared-Expert-Isolationsstrategie und die klassische Routing-Architektur. Es gibt zwei feste Experten, die Allgemeinwissen erfassen, und die ersten beiden der 14 optionalen Experten sind spezialisierte Experten.
Die Ausgabe von MoE ist eine Kombination aus festen Experten und vom Router ausgewählten Experten. Alle drei Modelle verwenden 30Btokens für das Training und weitere 10Btokens für Tests. Unter Berücksichtigung der Ergebnisse zwischen dem klassischen Router und dem Shared-Expert-Router kam das Papier zu dem Ergebnis, dass letzterer mit einer Steigerung der Trainingszeit um 7,35 % genau den gleichen Testverlust erzielte. Die Recheneffizienz gemeinsamer Experten ist relativ gering und führt nicht zu einer besseren Trainingsgenauigkeit als die klassische MOE-Strategie. Daher übernimmt das Papier im Modell des Papiers eine klassische Routing-Strategie ohne gemeinsame Experten. Im Vergleich zum klassischen gerouteten Netzwerk stieg der Aufmerksamkeitsverlust im Test-Router um 3,8 %.
 Der Artikel testet die Skalierbarkeit des Modells, indem die Anzahl der Experten erhöht und die Parametergröße jedes Experten festgelegt wird. Durch die Erhöhung der Anzahl der Trainingsexperten ändert sich nur die Modellkapazität, nicht die tatsächlich aktivierten Modellparameter. Alle Modelle werden mit 50 Milliarden Token trainiert und mit weiteren 10 Milliarden Token getestet. Das Papier setzt die aktivierten Experten auf 2, und die Trainingshyperparameter der drei Modelle sind gleich. Der Expertenskalierungseffekt wird anhand des Testverlusts nach dem Training von 50 Milliarden Token gemessen (Tabelle 2). Im Vergleich zum Modell mit 8 trainierbaren Experten zeigte das Modell mit 16 Experten eine Verlustreduzierung von 2 %, während das Modell mit 32 Experten eine Verlustreduzierung von 3,6 % zeigte. Aufgrund seiner Genauigkeit wählte das Papier 32 Experten für Yuan 2,0-M32 aus. Tabelle 2: Erweiterte experimentelle Ergebnisse Abbildung 3 zeigt die Verlustkurve und der endgültige Trainingsverlust beträgt 1,22.
Der Artikel testet die Skalierbarkeit des Modells, indem die Anzahl der Experten erhöht und die Parametergröße jedes Experten festgelegt wird. Durch die Erhöhung der Anzahl der Trainingsexperten ändert sich nur die Modellkapazität, nicht die tatsächlich aktivierten Modellparameter. Alle Modelle werden mit 50 Milliarden Token trainiert und mit weiteren 10 Milliarden Token getestet. Das Papier setzt die aktivierten Experten auf 2, und die Trainingshyperparameter der drei Modelle sind gleich. Der Expertenskalierungseffekt wird anhand des Testverlusts nach dem Training von 50 Milliarden Token gemessen (Tabelle 2). Im Vergleich zum Modell mit 8 trainierbaren Experten zeigte das Modell mit 16 Experten eine Verlustreduzierung von 2 %, während das Modell mit 32 Experten eine Verlustreduzierung von 3,6 % zeigte. Aufgrund seiner Genauigkeit wählte das Papier 32 Experten für Yuan 2,0-M32 aus. Tabelle 2: Erweiterte experimentelle Ergebnisse Abbildung 3 zeigt die Verlustkurve und der endgültige Trainingsverlust beträgt 1,22.
Während des Feinabstimmungsprozesses erweiterte das Papier die Sequenzlänge auf 16384. In Anlehnung an die Arbeit von CodeLLama (Roziere et al., 2023) setzt das Papier den Grundfrequenzwert der gedrehten Positionseinbettung (RoPE) zurück, um die Abschwächung des Aufmerksamkeitswerts mit zunehmender Sequenzlänge zu vermeiden. Anstatt einfach den Basiswert von 1000 auf einen sehr großen Wert (z. B. 1000000) zu erhöhen, nutzt das Papier NTK-Bewusstsein (bloc97, 2023), um den neuen Basiswert zu berechnen.
Der Artikel vergleicht auch die Leistung des vorab trainierten Yuan 2.0-M32-Modells mit neuen Basen im NTK-Wahrnehmungsstil und mit anderen Basen bei Nadelrückholaufgaben mit Sequenzlängen von bis zu 16 KB. Das Papier stellt fest, dass der neue Basiswert von 40890 für den NTK-Wahrnehmungsstil eine bessere Leistung erbringt. Daher wird bei der Feinabstimmung 40890 angewendet.
2.2.4 Vortrainingsdatensatz
Yuan 2.0-M32 wird von Grund auf unter Verwendung eines zweisprachigen Datensatzes mit 2000B-Tokens vorab trainiert. Die vorab trainierten Rohdaten enthalten über 3400 Milliarden Token, und die Gewichtung jeder Kategorie wird basierend auf Datenqualität und -quantität angepasst.
Der umfassende Korpus vor dem Training besteht aus:
44 Unterdatensätzen, die im Internet gecrawlte Daten, Wikipedia, wissenschaftliche Arbeiten, Bücher, Code, Mathematik und Formeln sowie domänenspezifisches Fachwissen abdecken. Einige davon sind Open-Source-Datensätze und der Rest wurde von Yuan 2.0 erstellt.
Einige gängige Webcrawler-Daten, chinesische Bücher, Konversationen und chinesische Nachrichtendaten werden von Yuan 1.0 übernommen (Wu et al., 2021). Die meisten Vortrainingsdaten in Yuan 2.0 wurden ebenfalls wiederverwendet.
Details zum Aufbau und den Quellen jedes Datensatzes sind wie folgt:
Web (25,2 %): Website-Crawler-Daten wurden aus Open-Source-Datensätzen erhalten und öffentliche Crawler wurden aus den Daten früherer Arbeiten des Papiers (Yuan 1,0) verarbeitet gesammelt. Weitere Einzelheiten zum Massive Data Filtering System (MDFS) zum Extrahieren hochwertiger Inhalte aus dem Webkontext finden Sie in Yuan 1.0.
Enzyklopädien (1,2 %), Aufsätze (0,84 %), Bücher (6,49 %) und Übersetzungen (1,1 %): Die Daten werden aus den Datensätzen Yuan 1,0 und Yuan 2,0 übernommen.
Code (47,5 %): Der Codedatensatz ist im Vergleich zu Yuan 2.0 stark erweitert. Das Papier verwendet Code von Stack v2 (Lozhkov et al., 2024). Kommentare in Stack v2 werden ins Chinesische übersetzt. Codesynthesedaten wurden über einen ähnlichen Ansatz wie Yuan 2.0 generiert.
Mathe (6,36 %): Alle Mathematikdaten von Yuan 2.0 wurden wiederverwendet. Diese Daten stammen hauptsächlich aus Open-Source-Datensätzen, darunter Proof-Pile vl (Azerbayev, 2022) und v2 (Paster et al., 2023), AMPS (Hendrycks et al., 2021), MathPile (Wang, Xia und Liu, 2023). ) und StackMathQA (Zhang, 2024). Mit Python wurde ein synthetischer Datensatz für numerische Berechnungen erstellt, um vier arithmetische Operationen zu ermöglichen.
Spezifischer Bereich (1,93 %): Hierbei handelt es sich um einen Datensatz mit unterschiedlichem Hintergrundwissen.
2.2.5 Feinabstimmungsdatensatz
Der Feinabstimmungsdatensatz wird basierend auf dem in Yuan 2.0 angewendeten Datensatz erweitert.
Code-Anweisungsdatensatz. Alle Programmierdaten mit chinesischen Anweisungen und teilweise mit englischen Kommentaren werden von großen Sprachmodellen (LLMs) generiert. Etwa 30 % der Codeanweisungsdaten sind auf Englisch und der Rest auf Chinesisch. Die synthetischen Daten ahmen Python-Code mit chinesischen Anmerkungen in Strategien zur sofortigen Generierung und Datenbereinigung nach.
Python-Code mit englischen Kommentaren, gesammelt von Magicoder-Evol-Instruct-110K und CodeFeedback-Filtered-Instruction. Extrahieren Sie Anweisungsdaten mit Sprach-Tags (z. B. „Python“) aus dem Datensatz.
Code in anderen Sprachen wie C/C++/Go/Java/SQL/Shell, mit englischen Kommentaren, stammt aus Open-Source-Datensätzen und wird auf ähnliche Weise wie Python-Code verarbeitet. Die Reinigungsstrategie ähnelt der Methode in Yuan 2.0. Eine Sandbox dient dazu, kompilierbare und ausführbare Zeilen aus dem generierten Code zu extrahieren und Zeilen beizubehalten, die mindestens einen Komponententest bestehen.
Mathe-Anweisungsdatensatz. Die Mathematikanweisungsdatensätze werden alle vom Feinabstimmungsdatensatz in Yuan 2.0 geerbt. Um die Fähigkeit des Modells zur Lösung mathematischer Probleme durch Programmiermethoden zu verbessern, wurden in der Arbeit mathematische Daten erstellt, die durch Thoughts (PoT) angeregt wurden. PoT wandelt mathematische Probleme in Codegenerierungsaufgaben um, die Berechnungen in Python durchführen.
Datensatz mit Sicherheitshinweisen. Zusätzlich zum Yuan 2.0-Chat-Datensatz erstellt das Papier auch einen zweisprachigen Sicherheitsausrichtungsdatensatz, der auf einem Open-Source-Sicherheitsausrichtungsdatensatz basiert. Das Papier extrahiert nur Fragen aus öffentlichen Datensätzen, erhöht die Vielfalt der Fragen und verwendet große Sprachmodelle, um chinesische und englische Antworten neu zu generieren.
2.2.6 Tokenizer
Für Yuan 2.0-M32 werden die englischen und chinesischen Tokenizer vom in Yuan 2.0 angewendeten Tokenizer übernommen.
2.3 Die Wirkung des Papiers
Das Papier bewertet die Codegenerierungsfähigkeit von Yuan 2.0-M32 bei HumanEval, die Fähigkeit zur mathematischen Problemlösung bei GSM8K und MATH sowie das wissenschaftliche Wissen und die Denkfähigkeit bei ARC. und auf MMLU als umfassenden Benchmark bewertet.
2.3.1 Codegenerierung
Die Fähigkeiten zur Codegenerierung werden anhand des HumanEval-Benchmarks bewertet. Bewertungsmethoden und Tipps ähneln denen in Meta 2.0.
 Tabelle 3: Vergleich zwischen Yuan 2.0-M32 und anderen Modellen im HumanEval-Pass @1
Tabelle 3: Vergleich zwischen Yuan 2.0-M32 und anderen Modellen im HumanEval-Pass @1
Es wird erwartet, dass das Modell die Funktion danach abschließt. Die generierten Funktionen werden durch Unit-Tests evaluiert. Tabelle 3 zeigt die Ergebnisse von Yuan 2.0-M32 beim Zero-Shot-Lernen und vergleicht sie mit anderen Modellen. Die Ergebnisse von Yuan 2.0-M32 übertreffen nur DeepseekV2 und Llama3-70B und übertreffen andere Modelle bei weitem, obwohl seine aktiven Parameter und sein Rechenverbrauch viel geringer sind als bei anderen Modellen.
Im Vergleich zu DeepseekV2 verwendet das Modell des Papiers weniger als ein Viertel der aktiven Parameter und erfordert weniger als ein Fünftel der Berechnungen pro Token, während es eine Genauigkeit von über 90 % erreicht. Im Vergleich zu Llama3-70B ist die Lücke zwischen Modellparametern und Berechnungsaufwand noch größer, aber das Papier kann immer noch 91 % seines Niveaus erreichen. Yuan 2.0-M32 zeigte solide Programmierfähigkeiten und bestand drei von vier Fragen. Yuan 2.0-M32 zeichnet sich durch das Lernen kleiner Stichproben aus und erhöht die Genauigkeit von HumanEval in 14 Versuchen auf 78,0.
2.3.2 Mathematik
Die mathematischen Fähigkeiten von Yuan 2.0-M32 werden durch GSM8K- und MATH-Benchmarks bewertet. Die Eingabeaufforderungen und Teststrategien für GSM8K ähneln denen für Yuan 2.0, mit dem einzigen Unterschied, dass das Papier 8 Versuche verwendet (Tabelle 4).
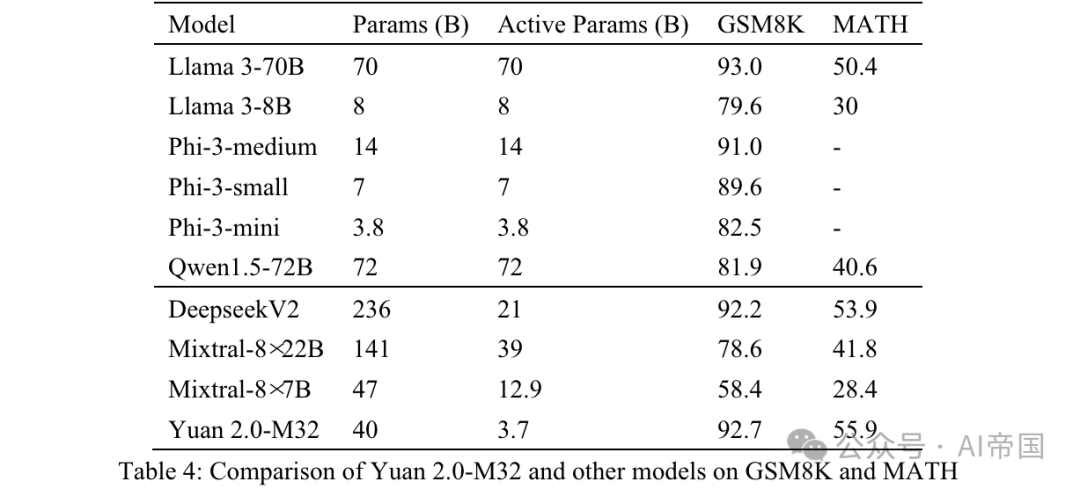 Tabelle 4: Vergleich von Yuan 2.0-M32 mit anderen Modellen auf GSM8K und MATH
Tabelle 4: Vergleich von Yuan 2.0-M32 mit anderen Modellen auf GSM8K und MATH
MATH ist ein Datensatz mit 12.500 anspruchsvollen Frage- und Antwortfragen für Mathematikwettbewerbe. Für jede Frage in diesem Datensatz gibt es eine vollständige Schritt-für-Schritt-Lösung, die das Modell bei der Generierung von Antwortableitungen und Erklärungen anleitet. Die Antwort auf die Frage kann ein numerischer Wert oder ein mathematischer Ausdruck sein (z. B. y=2x+5, x-+2x-1, 2a+b usw.). Yuan 2.0-M32 verwendet die Chain of Thinking (CoT)-Methode, um die endgültige Antwort durch 4 Versuche zu generieren. Die Antworten werden aus der Analyse extrahiert und in ein einheitliches Format umgewandelt.
Für numerische Ergebnisse werden mathematisch äquivalente Ausgaben in allen Formaten akzeptiert. Beispielsweise werden die Brüche 1/2, 12, 0,5, 0,50 alle in 0,5 umgewandelt und als dasselbe Ergebnis behandelt. Für mathematische Ausdrücke entfernt das Papier Tabulator- und Leerzeichen und vereinheitlicht reguläre Ausdrücke für Rhythmus oder Musiknoten. 55 „5“ werden alle als dieselbe Antwort akzeptiert. Das Endergebnis nach der Verarbeitung wird mit der Standardantwort verglichen und anhand des EM-Scores (Exact Match) bewertet.
Wie aus den in Tabelle 4 gezeigten Ergebnissen ersichtlich ist, hat Yuan 2.0-M32 die höchste Punktzahl im MATH-Benchmark. Im Vergleich zu Mixtral-8x7B sind die aktiven Parameter des letzteren 3,48-mal höher als die von Yuan 2.0-M32, der Wert von Yuan ist jedoch fast doppelt so hoch. Bei GSM8K liegt die Punktzahl des Yuan 2.0-M32 ebenfalls sehr nahe an der des Llama 3-70B und ist besser als die der anderen Modelle. 2.3.3 MMLU Alle Fragen in MMLU sind Multiple-Choice-QA-Fragen auf Englisch. Vom Modell wird erwartet, dass es die richtigen Optionen bzw. entsprechenden Analysen generiert.
Die Eingabedatenorganisation von Yuan 2.0-M32 ist in Anhang B dargestellt. Der vorherige Text wird an das Modell gesendet und alle Antworten, die sich auf die richtige Antwort oder Optionsbezeichnung beziehen, werden als richtig betrachtet.
Die endgültige Genauigkeit wird mit MC1 gemessen (Tabelle 5). Die Ergebnisse zu MMLU zeigen die Leistungsfähigkeit des Papiermodells in verschiedenen Bereichen. Yuan 2.0-M32 übertrifft Mixtral-8x7B, Phi-3-mini und Llama 3-8B in der Leistung. Tabelle 5: Vergleich von Yuan 2.0-M32 mit anderen Modellen auf MMLU Fragen aus dem naturwissenschaftlichen Test für die Klassen 9 bis 9. Es ist in zwei Teile gegliedert, „Einfach“ und „Herausforderung“, wobei letzterer komplexere Teile enthält, die einer weiteren Begründung bedürfen. Der Artikel testet das Modell des Artikels im Abschnitt „Herausforderungen“.
Tabelle 6: Vergleich von Yuan 2.0-M32 und anderen Modellen auf ARC-Challenge
Fragen und Optionen sind direkt verbunden und durch getrennt. Der vorherige Text wird an das Modell gesendet, von dem erwartet wird, dass es eine Beschriftung oder eine entsprechende Antwort generiert. Die generierten Antworten werden mit den realen Antworten verglichen und die Ergebnisse anhand des MC1-Ziels berechnet.
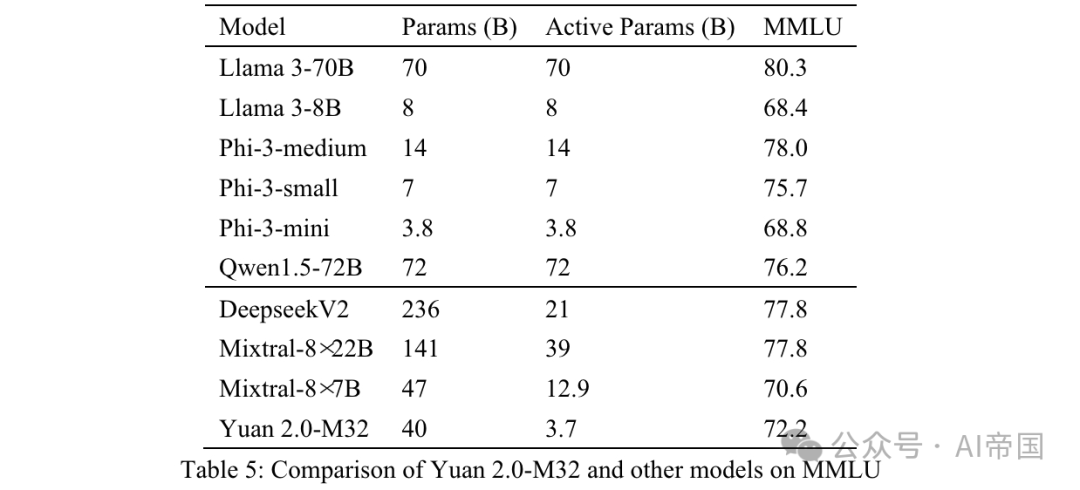 Tabelle 6 zeigt die Ergebnisse für ARC-C und zeigt, dass Yuan 2.0-M32 bei der Lösung komplexer wissenschaftlicher Probleme hervorragend ist – es übertrifft Llama3-70B bei diesem Benchmark.
Tabelle 6 zeigt die Ergebnisse für ARC-C und zeigt, dass Yuan 2.0-M32 bei der Lösung komplexer wissenschaftlicher Probleme hervorragend ist – es übertrifft Llama3-70B bei diesem Benchmark.
Bilder
Tabelle 7: Vergleich von Qualität und Größe zwischen Yuan 2.0-M32 und anderen Modellen. Die durchschnittliche Genauigkeit wird basierend auf den Ergebnissen von GSM-8K, Mathematik, Humaneval, MMLU und ARC-C gemittelt
Das Papier vergleicht die Leistung des Papiers mit drei MoE-Modellen (Mixtral-Familie, Deepseek) und sechs dichten Modellen (Qwen (Bai et al., 2023), Llama-Familie und Phi-3-Familie (Abdin et al., 2024). )), um die Leistung von Yuan 2.0-M32 in verschiedenen Bereichen zu bewerten. Tabelle 7 zeigt den Vergleich zwischen Genauigkeit und Rechenaufwand zwischen Yuan 2.0-M32 und anderen Modellen. Yuan 2.0-M32 wird mit nur 3,7 Milliarden aktiven Parametern und 22,2 GFlops pro Token feinabgestimmt. Dies ist die wirtschaftlichste Methode, um Ergebnisse zu erzielen, die mit den anderen in der Tabelle aufgeführten Modellen vergleichbar sind oder diese sogar übertreffen. Tabelle 7 weist auf die hervorragende Recheneffizienz und Leistung des Papiermodells während des Inferenzprozesses hin. Der Yuan 2.0-M32 hat eine durchschnittliche Genauigkeit von 79,15, was mit dem Llama3-70B vergleichbar ist. Die durchschnittliche Genauigkeit/GFlops pro Token-Wert beträgt 10,69, was dem 18,9-fachen von Llama3-70B entspricht.
Papiertitel: Yuan 2.0-M32: Mixture of Experts with Attention Router
Papierlink: https://www.php.cn/link/cc7d159d6ff3ea6f39b9419877dfc81f
Das obige ist der detaillierte Inhalt vonLLM |. Yuan 2.0-M32: Expertenmischungsmodell mit Aufmerksamkeitsrouting. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie Mathe-Objekte in JavaScript
- Wie importiere ich eine Mathematikbibliothek in Python?
- Implementierung des Client-Server-Diffie-Hellman-Algorithmus in Java
- LLM-Inferenz auf mehreren GPUs mithilfe der Accelerate-Bibliothek
- Geben Sie alles, um den Kreislauf zu schließen! DriveMLM: LLM perfekt mit autonomer Fahrverhaltensplanung kombinieren!