
Heim >Technologie-Peripheriegeräte >KI >Geben Sie alles, um den Kreislauf zu schließen! DriveMLM: LLM perfekt mit autonomer Fahrverhaltensplanung kombinieren!
Geben Sie alles, um den Kreislauf zu schließen! DriveMLM: LLM perfekt mit autonomer Fahrverhaltensplanung kombinieren!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2024-01-05 09:50:191405Durchsuche
Oben geschrieben und das persönliche Verständnis des Autors
Groß angelegte Sprachmodelle haben eine neue Landschaft für intelligentes Fahren eröffnet und ihnen menschenähnliches Denken und kognitive Fähigkeiten verliehen. Dieser Artikel befasst sich eingehend mit dem Potenzial großer Sprachmodelle (LLMs) beim autonomen Fahren (AD). Dann wird DriveMLM vorgeschlagen, ein auf LLM basierendes AD-Framework, das autonomes Fahren mit geschlossenem Regelkreis in der Simulationsumgebung realisieren kann. Im Einzelnen gibt es folgende Punkte:
- (1) Dieses Papier schließt die Lücke zwischen Sprachentscheidungen und Fahrzeugsteuerungsbefehlen, indem es Entscheidungszustände auf der Grundlage vorgefertigter Bewegungsplanungsmodule standardisiert.
- (2) Verwendung von multimodalem LLM ( MLLM) Modellieren Sie das Verhaltensplanungsmodul des Modul-AD-Systems, das Fahrregeln, Benutzerbefehle und Eingaben von verschiedenen Sensoren (z. B. Kameras, Lidar) als Eingabe verwendet, Fahrentscheidungen trifft und Erklärungen liefert. Das Modell kann angeschlossen werden in bestehende AD-Systeme (wie Apollo) für Closed-Loop-Fahren
- (3) Eine effektive Daten-Engine ist darauf ausgelegt, einen Datensatz zu sammeln, der Entscheidungszustände und entsprechende interpretierbare Anmerkungen für das Modelltraining und die Auswertung enthält.
Schließlich haben wir umfangreiche Experimente mit DriveMLM durchgeführt und die Ergebnisse zeigten, dass DriveMLM auf CARLA Town05 Long eine Fahrbewertung von 76,1 erreichte und die Apollo-Basislinie bei denselben Einstellungen um 4,7 Punkte übertraf, was die Wirksamkeit von DriveMLM beweist. Wir hoffen, dass diese Arbeit als Grundlage für das autonome Fahren im LLM dienen kann.
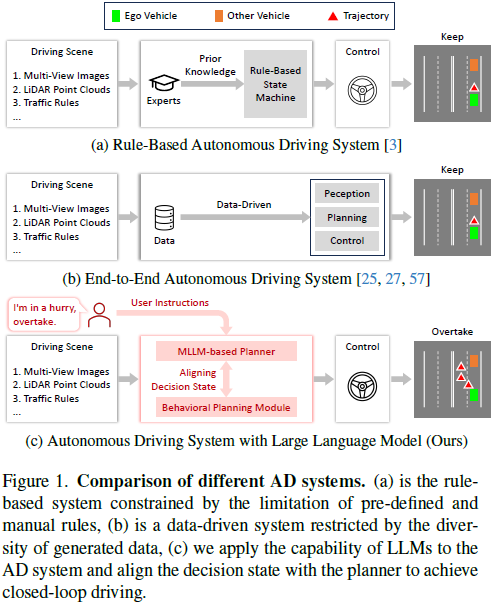
Verwandte Einführung in DriveMLM
In den letzten Jahren hat das autonome Fahren (AD) erhebliche Fortschritte gemacht, wie in Abbildung 1b dargestellt, von einem traditionellen regelbasierten System zu einem datengesteuerten End-to-End-System . Das traditionelle Regelsystem basiert auf einem vordefinierten Regelsatz, der durch A-priori-Wissen bereitgestellt wird (siehe Abbildung 1a). Trotz der Fortschritte dieser Systeme stoßen sie immer noch auf Einschränkungen aufgrund von Einschränkungen im Expertenwissen oder der Vielfalt der Trainingsdaten. Dies macht es für sie schwierig, Kurvensituationen zu bewältigen, auch wenn menschliche Fahrer den Umgang mit solchen Situationen möglicherweise intuitiv finden. Im Vergleich zu diesen herkömmlichen regelbasierten oder datengesteuerten AD-Planern verfügen große Sprachmodelle (LLMs), die mithilfe von Textkorpora im Webmaßstab trainiert werden, über umfangreiches Weltwissen, robustes logisches Denken und fortgeschrittene kognitive Fähigkeiten. Diese Fähigkeiten positionieren sie als potenzielle Planer in AD-Systemen und bieten einen menschenähnlichen Ansatz für autonomes Fahren.
Einige neuere Forschungsarbeiten haben LLM in AD-Systeme integriert und konzentrieren sich dabei auf die Generierung sprachbasierter Entscheidungen für Fahrszenarien. Diese Methoden weisen jedoch Einschränkungen auf, wenn es darum geht, das Fahren im geschlossenen Regelkreis in realen Umgebungen oder realen Simulationen durchzuführen. Dies liegt daran, dass die Ausgabe von LLM hauptsächlich aus Sprache und Konzepten besteht und nicht für die Fahrzeugsteuerung verwendet werden kann. In herkömmlichen modularen AD-Systemen wird die Lücke zwischen strategischen Zielen auf hoher Ebene und Kontrollverhalten auf niedriger Ebene durch das Verhaltensplanungsmodul geschlossen, und der Entscheidungsstatus dieses Moduls kann durch anschließende Bewegungsplanung und -steuerung problemlos in Fahrzeugsteuersignale umgewandelt werden Kontrolle. Dies motiviert uns, das LLM an dem Entscheidungsstand des Verhaltensplanungsmoduls auszurichten und weiter ein LLM-basiertes AD-System mit geschlossenem Regelkreis zu entwerfen, indem wir das ausgerichtete LLM für die Verhaltensplanung verwenden, das in einer realen Umgebung oder in einer Umgebung ausgeführt werden kann realistische Simulationsumgebung.
Auf dieser Grundlage haben wir DriveMLM vorgeschlagen, das erste LLM-basierte AD-Framework, das autonomes Fahren mit geschlossenem Regelkreis in einer realistischen Simulationsumgebung erreichen kann. Um dies zu erreichen, haben wir drei Schlüsseldesigns: (1) Wir untersuchen die Entscheidungszustände des Verhaltensplanungsmoduls des Apollo-Systems und wandeln sie in eine Form um, die LLM leicht verarbeiten kann. (2) Es wird ein multimodaler LLM-Planer (MLLM) entwickelt, der aktuelle multimodale Eingaben, einschließlich Mehransichtsbilder, LIDAR-Punktwolken, Verkehrsregeln, Systemmeldungen und Benutzeranweisungen, akzeptieren und den Entscheidungsstatus vorhersagen kann Um ausreichend Trainingsdaten für die Abstimmung zwischen Verhaltensplanung und Zustand zu erhalten, haben wir manuell 280 Stunden Fahrdaten auf CARLA gesammelt und diese über eine effiziente Daten-Engine in Entscheidungszustände und entsprechende Erklärungsanmerkungen umgewandelt. Durch diese Entwürfe können wir einen MLLM-Planer erhalten, der Entscheidungen auf der Grundlage von Fahrszenarien und Benutzeranforderungen treffen kann und dessen Entscheidungen leicht in Fahrzeugsteuersignale für das Fahren mit geschlossenem Regelkreis umgewandelt werden können.
DriveMLM bietet folgende Vorteile: (1) Dank des konsistenten Entscheidungsstands kann DriveMLM problemlos in bestehende modulare AD-Systeme (wie Apollo) integriert werden, um ein Fahren im geschlossenen Regelkreis ohne größere Änderungen oder Modifikationen zu erreichen. (2) Durch die Verwendung von Sprachanweisungen als Eingabe kann unser Modell Benutzeranforderungen (z. B. das Überholen des Autos) und Systemmeldungen auf hoher Ebene (z. B. die Definition grundlegender Fahrlogik) verarbeiten. Dadurch wird DriveMLM flexibler und kann sich an unterschiedliche Fahrsituationen und Kurven anpassen. (3) Es kann für Interpretierbarkeit sorgen und unterschiedliche Entscheidungen erklären. Dies erhöht die Transparenz und Vertrauenswürdigkeit unseres Modells, da es den Benutzern seine Aktionen und Entscheidungen erklären kann.
Zusammenfassend sind die Hauptbeiträge von DriveMLM wie folgt:
- Vorschlag eines AD-Frameworks auf Basis von LLM, um die Lücke zwischen LLM und Fahren im geschlossenen Regelkreis zu schließen, indem die Ausgabe von LLM an den Entscheidungsstand der Verhaltensplanung angepasst wird Modul.
- Um dieses Framework zu implementieren, haben wir eine Reihe von Entscheidungszuständen in einer Form angepasst, die von LLM leicht verarbeitet werden kann, einen MLLM-Planer für die Entscheidungsvorhersage entworfen und eine Daten-Engine entwickelt, die Entscheidungszustände und entsprechende erklärende Anmerkungen für das Modell effizient generieren kann Schulung und Bewertung.
- Um die Wirksamkeit von DriveMLM zu überprüfen, bewerten wir unsere Methode nicht nur anhand von Fahrkennzahlen im geschlossenen Regelkreis, einschließlich Driving Score (DS) und Miles Per Intervention (MPI), sondern verwenden auch Verständnismetriken wie Genauigkeit, F1-Indikatoren für Entscheidungszustände, Entscheidungserklärung (BLEU-4, CIDEr und METEOR), um die Fahrverständnisfähigkeit des Modells zu bewerten. Es ist erwähnenswert, dass unsere Methode 76,1 DS, 0,955 MPI-Ergebnisse für CARLA Town05 Long erzielt, was 4,7 Punkte und 1,25-mal höher als Apollo ist. Darüber hinaus können wir die Entscheidungsfindung des MLLM-Planers ändern, indem wir spezielle Anforderungen mit Sprachanweisungen beschreiben, wie in Abbildung 2 dargestellt, z. B. Platz für einen Krankenwagen oder Verkehrsregeln

DriveMLM-Ansatz im Detail
Übersicht
Das DriveMLM-Framework integriert das Weltwissen und die Argumentationsfähigkeiten großer Sprachmodelle (LLM) in autonome Fahrsysteme (AD), um ein Fahren mit geschlossenem Regelkreis in einer realistischen Simulationsumgebung zu erreichen. Wie in Abbildung 3 dargestellt, weist dieses Framework drei Hauptdesigns auf: (1) Zustandsausrichtung der Verhaltensplanung. In diesem Teil wird die sprachliche Entscheidungsausgabe von LLM mit dem Verhaltensplanungsmodul ausgereifter modularer AD-Systeme wie Apollo abgeglichen. Auf diese Weise kann die Ausgabe des LLM einfach in Fahrzeugsteuersignale umgewandelt werden. (2) MLLM-Planer. Es handelt sich um eine Kombination aus einem multimodalen Marker und einem multimodalen LLM-Decoder (MLLM). Der multimodale Tagger wandelt verschiedene Eingaben (z. B. Bilder mit mehreren Ansichten, LIDAR, Verkehrsregeln und Benutzeranforderungen) in einheitliche Tags um, und der MLLM-Decoder trifft Entscheidungen auf der Grundlage der einheitlichen Tags. (3) Effiziente Datenerfassungsstrategie. Es führt eine maßgeschneiderte Datenerfassungsmethode für LLM-basiertes autonomes Fahren ein und stellt einen umfassenden Datensatz einschließlich Entscheidungsstatus, Entscheidungserklärungen und Benutzerbefehlen sicher.
Während des Inferenzprozesses nutzt das DriveMLM-Framework multimodale Daten, um Fahrentscheidungen zu treffen. Zu diesen Daten gehören: Umgebungsbilder und Punktwolken. Systemmeldungen sind eine Sammlung von Aufgabendefinitionen, Verkehrsregeln und Entscheidungsstatusdefinitionen. Diese Token werden in den MLLM-Decoder eingegeben, der Entscheidungsstatus-Token zusammen mit entsprechenden Erläuterungen generiert. Schließlich wird der Entscheidungszustand in das Bewegungsplanungs- und Steuerungsmodul eingegeben. Dieses Modul berechnet die endgültige Trajektorie der Fahrzeugsteuerung.
Ausrichtung der Verhaltensplanungszustände
Die Übersetzung der Sprachauswahl von Large Language Models (LLM) in umsetzbare Steuersignale ist für die Fahrzeugsteuerung von entscheidender Bedeutung. Um dies zu erreichen, haben wir die Ausgabe des LLM mit der Entscheidungsphase des Verhaltensplanungsmoduls im beliebten Apollo-System abgeglichen. Basierend auf gängigen Ansätzen unterteilen wir den Entscheidungsprozess in zwei Kategorien: schnelle Entscheidungsfindung und Pfadentscheidungsfindung. Insbesondere umfasst der Geschwindigkeitsentscheidungsstatus (Beibehalten, Beschleunigen, Verlangsamen, Stoppen) und der Pfadentscheidungsstatus umfasst (FOLGEN, LINKS ÄNDERN, RECHTS ÄNDERN, LINKS BORROW, RECHTS BORROW).
Damit das Sprachmodell genaue Vorhersagen zwischen diesen Zuständen treffen kann, stellen wir eine umfassende Verbindung zwischen der Sprachbeschreibung und dem Entscheidungszustand her, wie in den Systeminformationen in Tabelle 1 dargestellt. Diese Korrelation wird als Teil der Systemmeldungen verwendet und in den MLLM-Planer integriert. Sobald das LLM bestimmte Situationen beschreibt, werden die Vorhersagen daher zu klaren Entscheidungen innerhalb des Entscheidungsraums konvergieren. Dabei werden jeweils eine Geschwindigkeitsentscheidung und eine Pfadentscheidung voneinander abgeleitet und an das Bewegungsplanungs-Framework gesendet. Eine detailliertere Definition von Entscheidungszuständen finden Sie im Zusatzmaterial.

MLLM-Planer
Der MLLM-Planer von DriveMLM besteht aus zwei Komponenten: multimodaler Tokenizer und MLLM-Decoder. Die beiden Module arbeiten eng zusammen und verarbeiten verschiedene Eingaben, um Fahrentscheidungen genau zu ermitteln und Erklärungen für diese Entscheidungen bereitzustellen.
Multimodaler Tokenizer. Dieser Tokenizer wurde entwickelt, um verschiedene Eingabeformen effizient zu verarbeiten: Für zeitliche Lookaround-Bilder: Verwenden Sie einen temporalen QFormer, um das Lookaround-Bild vom Zeitstempel −T bis 0 (dem aktuellen Zeitstempel) zu verarbeiten. Für LIDAR-Daten geben wir zunächst die Punktwolke als Eingabe in das SPT-Backbone (Sparse Pyramid Transformer) ein, um LIDAR-Features zu extrahieren. Systemmeldungen und Benutzeranweisungen behandeln wir einfach als gewöhnliche Textdaten und verwenden die Token-Einbettungsschicht von LLM, um ihre Einbettungen zu extrahieren.
MLLM-Decoder. Der Decoder ist das Herzstück der Umwandlung tokenisierter Eingaben in Entscheidungszustände und Entscheidungsinterpretationen. Zu diesem Zweck haben wir eine Systemnachrichtenvorlage für LLM-basiertes AD entworfen, wie in Tabelle 1 dargestellt. Wie zu sehen ist, enthält die Systemnachricht eine Beschreibung der AD-Aufgabe, Verkehrsregeln, Definition von Entscheidungszuständen und Platzhalter, die angeben, wo die einzelnen Modalinformationen zusammengeführt werden. Dieser Ansatz gewährleistet eine nahtlose Integration von Eingaben aus verschiedenen Modalitäten und Quellen.
Die Ausgabe ist so formatiert, dass sie den Entscheidungsstatus (siehe Frage 2 in Tabelle 1) und eine Entscheidungserklärung (siehe Frage 3 in Tabelle 1) bereitstellt und so für Transparenz und Klarheit im Entscheidungsprozess sorgt. In Bezug auf überwachte Methoden folgt unser Framework der gängigen Praxis, Kreuzentropieverluste bei der Vorhersage des nächsten Tokens zu verwenden. Auf diese Weise können MLLM-Planer ein detailliertes Verständnis und eine Verarbeitung der Daten verschiedener Sensoren und Quellen entwickeln und diese in geeignete Entscheidungen und Interpretationen übersetzen.
Effiziente Datenmaschine
Wir schlagen ein Datengenerierungsparadigma vor, mit dem Entscheidungszustände und Erklärungsanmerkungen aus verschiedenen Szenarien im CARLA-Simulator erstellt werden können. Diese Pipeline kann die Einschränkungen vorhandener Fahrdaten beheben, denen es an Entscheidungszuständen und detaillierten Erklärungen für das Training LLM-basierter AD-Systeme mangelt. Unsere Pipeline besteht aus zwei Hauptkomponenten: Datenerfassung und Datenannotation.
Die Datenerfassung soll die Diversität bei der Entscheidungsfindung erhöhen und gleichzeitig realistisch bleiben. Zunächst werden in einer Simulationsumgebung verschiedene anspruchsvolle Szenarien konstruiert. Sicheres Fahren erfordert komplexes Fahrverhalten. Experten, ob erfahrene Fahrer oder Agenten, werden dann gebeten, diese Szenarien, die an einem der vielen zugänglichen Orte ausgelöst werden, sicher zu durchfahren. Insbesondere werden Interaktionsdaten generiert, wenn Experten zufällig Fahranforderungen vorschlagen und entsprechend fahren. Sobald der Experte sicher zum Ziel fährt, werden die Daten aufgezeichnet.
Die Datenanmerkung konzentriert sich hauptsächlich auf die Entscheidungsfindung und Interpretation. Erstens werden Geschwindigkeits- und Pfadentscheidungszustände automatisch auf der Grundlage von Expertenfahrtrajektorien unter Verwendung handgefertigter Regeln kommentiert. Zweitens werden zunächst Erklärungsanmerkungen basierend auf der Szene generiert, die dynamisch durch nahegelegene aktuelle Elemente definiert wird. Drittens werden die generierten Erklärungsanmerkungen durch manuelle Annotationen verfeinert und ihre Vielfalt durch GPT-3.5 erweitert. Darüber hinaus wird der Interaktionsinhalt auch durch menschliche Annotatoren verfeinert, einschließlich der Ausführung oder Ablehnung menschlicher Anfragen. Auf diese Weise vermeiden wir die kostspielige Annotation des Entscheidungszustands Frame für Frame sowie das kostspielige manuelle Schreiben von Erklärungsanmerkungen von Grund auf, was unseren Datenannotationsprozess erheblich beschleunigt.
Experiment
Datenanalyse
Wir haben 280 Stunden Fahrdaten für das Training gesammelt. Die Daten umfassen 50 Kilometer Routen und 30 Fahrszenarien mit unterschiedlichen Wetter- und Lichtverhältnissen, die auf den 8 Karten von CARLA (Town01, Town02, Town03, Town04, Town06, Town07, Town10HD, Town12) gesammelt wurden. Im Durchschnitt verfügt jede Szene über etwa 200 Triggerpunkte auf jeder Karte, die zufällig ausgelöst werden. Bei jeder Situation handelt es sich um eine häufige oder seltene sicherheitskritische Situation beim Fahren. Einzelheiten zu diesen Szenarien finden Sie in den Ergänzenden Anmerkungen. Für jedes Bild sammeln wir Bilder von vier Kameras, vorne, hinten, links und rechts, sowie Punktwolken von einem Lidar-Sensor, der in der Mitte des Ego-Fahrzeugs angebracht ist. Alle von uns gesammelten Daten verfügen über entsprechende Interpretationen und genaue Entscheidungen, die das Szenario erfolgreich vorantreiben.
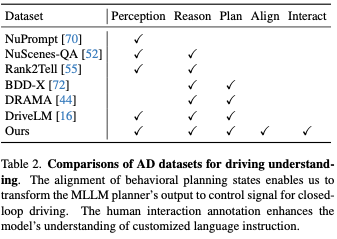
Tabelle 2 zeigt einen Vergleich mit früheren Datensätzen, die zur Förderung des Verständnisses mithilfe natürlicher Sprache entwickelt wurden. Unsere Daten weisen zwei einzigartige Merkmale auf. Der erste ist die Konsistenz der Verhaltensplanungszustände. Dadurch können wir die Ausgabe des MLLM-Planers in Steuersignale umwandeln, sodass unser Framework das Fahrzeug im geschlossenen Regelkreis steuern kann. Die zweite Möglichkeit besteht in der Anmerkung zur zwischenmenschlichen Interaktion. Es zeichnet sich durch natürlichsprachliche Anweisungen des Menschen und die entsprechenden Entscheidungen und Interpretationen aus. Ziel ist es, die Fähigkeit zu verbessern, menschliche Anweisungen zu verstehen und entsprechend zu reagieren.
Bewertung des autonomen Fahrens im geschlossenen Regelkreis
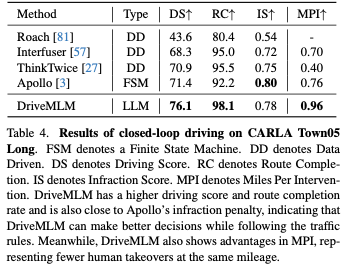
Wir bewerten das Fahren im geschlossenen Regelkreis in CARLA, dem am weitesten verbreiteten und realistischsten Simulations-Benchmark, der öffentlich verfügbar ist. Für den Leistungsvergleich sind modernste Methoden zur Durchführung des Closed-Loop-Fahrens in CARLA enthalten. Auch das Open-Source-Apollo wurde in CARLA als Baseline evaluiert. Abgesehen von unserem Ansatz hat kein anderer LLM-basierter Ansatz die Bereitschaft für den Einsatz und die Evaluierung gezeigt. Alle Methoden werden anhand des Town05-Langzeit-Benchmarks bewertet.
Tabelle 4 listet die Fahrbewertungen, die Routenbeendigung und die Verstöße auf. Beachten Sie, dass Apollo zwar ein regelbasierter Ansatz ist, seine Leistung jedoch fast mit aktuellen End-to-End-Ansätzen vergleichbar ist. DriveMLM übertrifft alle anderen Methoden bei der Fahrbewertung deutlich. Dies deutet darauf hin, dass DriveMLM besser geeignet ist, Zustandsübergänge so zu verarbeiten, dass sie die Festplatte sicher passieren. Die letzte Spalte in Tabelle 4 zeigt die Ergebnisse der MPI-Auswertung. Diese Metrik zeigt eine umfassendere Fahrleistung, da die Agenten alle Routen absolvieren müssen. Mit anderen Worten: Der getestete Agent wird auf alle Situationen auf allen Routen stoßen. Thinktwice implementiert einen besseren DS als Interfuser, weist jedoch aufgrund des häufigen Überquerens von Stopplinien einen niedrigeren MPI auf. Die Strafen von CARLA für dieses Verhalten sind jedoch minimal. Im Gegensatz dazu behandelt MPI jeden Verkehrsverstoß als Übernahme. DriveMLM erreicht außerdem den höchsten MPI unter allen anderen Methoden, was darauf hindeutet, dass es in der Lage ist, mehr Situationen zu vermeiden, was zu einem sichereren Fahrerlebnis führt.
Bewertung des Fahrwissens
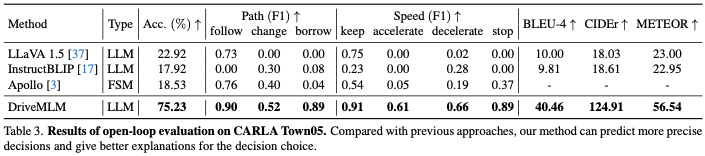
Wir verwenden eine Open-Loop-Bewertung, um das Fahrwissen zu bewerten, einschließlich Aufgaben zur Entscheidungsvorhersage und Erklärungsvorhersage. Tabelle 3 zeigt die Genauigkeit der vorhergesagten Entscheidungspaare, den F1-Score für jeden durch die Entscheidung vorhergesagten Entscheidungstyp und die durch die Vorhersage erklärten Werte BLEU-4, CIDEr und METEOR. Für Apollo werden manuell gesammelte Szenen auf Town05 als Eingabe für das Modell in Tabelle 3 wiedergegeben. Der entsprechende Modellstatus und die Ausgabe zu jedem Zeitstempel der Wiedergabe werden als Vorhersagen für Metrikberechnungen gespeichert. Für andere Methoden stellen wir ihnen entsprechende Bilder als Eingabe und entsprechende Eingabeaufforderungen zur Verfügung. Durch den Vergleich von Modellvorhersagen mit unserer manuell gesammelten Grundwahrheit offenbart die Genauigkeit die Richtigkeit von Entscheidungen und die Ähnlichkeit mit menschlichem Verhalten, und F1-Scores zeigen die Entscheidungsfähigkeit für jede Pfad- und Geschwindigkeitsentscheidung. DriveMLM erreichte insgesamt die höchste Genauigkeit und übertraf LLaVA mit einer Genauigkeit von 40,97 %. Im Vergleich zur Apollo-Basislinie erreicht DriveMLM einen höheren F1-Score, was darauf hindeutet, dass es regelbasierte Zustandsmaschinen bei der Lösung verschiedener Straßensituationen effektiver übertrifft. LLaVA, InstructionBLIP und unser vorgeschlagenes DriveMLM können Entscheidungserklärungen in Form von Fragen und Antworten ausgeben. In Bezug auf BLEU-4, CIDEr und METEOR kann DriveMLM die höchste Leistung erzielen, was darauf hinweist, dass DriveMLM die vernünftigste Erklärung für Entscheidungen liefern kann.
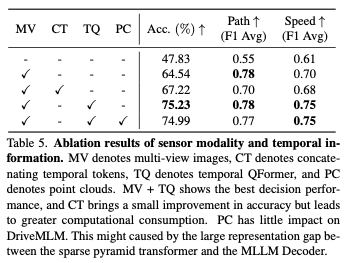
Ablationsexperiment
Sensormodalität: Tabelle 5 zeigt die Ergebnisse verschiedener Auswirkungen der Eingabesensormodalität auf DriveMLM. Multi-View-Bilder (MV) bringen erhebliche Leistungsverbesserungen sowohl bei der Pfad- als auch bei der Geschwindigkeits-F1-Bewertung mit einer Genauigkeitssteigerung von 18,19 %. Im Vergleich zur direkten Verbindung temporärer Token erzielt Temporal QFormer eine um 7,4 % größere Verbesserung und gewährleistet gleichzeitig multimodale Entscheidungsfähigkeiten, was zu einer durchschnittlichen F1-Score-Verbesserung von 0,05 für Geschwindigkeitsentscheidungen führt. Punktwolken zeigen keine Möglichkeit zur Leistungssteigerung.
Fallstudie und Visualisierung
Mensch-Computer-Interaktion: Abbildung 4 zeigt ein Beispiel dafür, wie die Fahrzeugsteuerung durch menschliche Anweisungen erreicht werden kann. Der Kontrollprozess umfasst die Analyse des Straßenzustands, die Entscheidungsfindung und die Bereitstellung erklärender Aussagen. Bei gleichem „Überhol“-Befehl zeigte DriveMLM aufgrund seiner Analyse der aktuellen Verkehrssituation unterschiedliche Reaktionen. In Situationen, in denen die rechte Spur besetzt und die linke Spur frei ist, entscheidet sich das System für das Überholen von links. In Situationen, in denen eine bestimmte Anweisung jedoch eine Gefahr darstellen könnte, beispielsweise wenn alle Fahrspuren belegt sind, verzichtet DriveMLM auf die Durchführung eines Überholmanövers und reagiert angemessen. DriveMLM ist in diesem Fall die Schnittstelle für die Mensch-Fahrzeug-Interaktion, die Anweisungen anhand der Verkehrsdynamik auf ihre Sinnhaftigkeit hin beurteilt und sicherstellt, dass diese den vordefinierten Regeln entsprechen, bevor sie schließlich eine Vorgehensweise auswählt.

Leistung in realen Szenarien: Wir wenden DriveMLM auf den nuScenes-Datensatz an, um die Zero-Shot-Leistung des entwickelten Fahrsystems zu testen. Wir haben 6019 Frames im Validierungssatz mit Anmerkungen versehen und eine Zero-Shot-Leistung von 0,395 für die Entscheidungsgenauigkeit erreicht. Abbildung 5 zeigt die Ergebnisse von zwei realen Fahrszenarien und demonstriert die Vielseitigkeit von DriveMLM.

Fazit
In dieser Arbeit haben wir DriveMLM vorgeschlagen, ein neues Framework, das große Sprachmodelle (LLM) für autonomes Fahren (AD) nutzt. DriveMLM kann Closed-Loop-AD in einer realistischen Simulationsumgebung implementieren, indem es das Verhaltensplanungsmodul eines modularen AD-Systems mithilfe von multimodalem LLM (MLLM) modelliert. DriveMLM kann außerdem Erklärungen in natürlicher Sprache für seine treibenden Entscheidungen generieren, was die Transparenz und Vertrauenswürdigkeit von AD-Systemen erhöhen kann. Wir haben gezeigt, dass DriveMLM den Apollo-Benchmark beim CARLA Town05 Long-Benchmark übertrifft. Wir glauben, dass unsere Arbeit weitere Forschung zur Integration von LLM und AD anregen kann.
Open-Source-Link: https://github.com/OpenGVLab/DriveMLM

Originallink: https://mp.weixin.qq.com/s/tQeERCbpD9H8oY8EvpZsDA
Das obige ist der detaillierte Inhalt vonGeben Sie alles, um den Kreislauf zu schließen! DriveMLM: LLM perfekt mit autonomer Fahrverhaltensplanung kombinieren!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!