



Groß angelegte Sprachmodelle (LLM) haben den Bereich der Verarbeitung natürlicher Sprache revolutioniert. Mit zunehmender Größe und Komplexität dieser Modelle steigen auch die rechnerischen Anforderungen der Inferenz erheblich. Um dieser Herausforderung zu begegnen, ist die Nutzung mehrerer GPUs von entscheidender Bedeutung.

Daher werden in diesem Artikel Inferenzen auf mehreren GPUs gleichzeitig durchgeführt. Der Inhalt umfasst hauptsächlich: Einführung in die Accelerate-Bibliothek, einfache Methoden und funktionierende Codebeispiele sowie Leistungsbenchmarking mit mehreren GPUs
Dieser Artikel wird Skalieren Sie die Inferenz von llama2-7b auf mehreren GPUs mit mehreren 3090s.
Grundlegendes Beispiel
Wir stellen zunächst ein einfaches Beispiel vor, um die „Nachrichtenübermittlung“ mit mehreren GPUs mithilfe von Accelerate zu demonstrieren.
from accelerate import Accelerator from accelerate.utils import gather_object accelerator = Accelerator() # each GPU creates a string message=[ f"Hello this is GPU {accelerator.process_index}" ] # collect the messages from all GPUs messages=gather_object(message) # output the messages only on the main process with accelerator.print() accelerator.print(messages)
Die Ausgabe lautet wie folgt:
['Hello this is GPU 0', 'Hello this is GPU 1', 'Hello this is GPU 2', 'Hello this is GPU 3', 'Hello this is GPU 4']
Multi-GPU-Inferenz
Hier ist eine einfache Nicht-Batch-Inferenzmethode. Der Code ist sehr einfach, da die Accelerate-Bibliothek bereits viel Arbeit für uns erledigt hat, wir können ihn direkt verwenden:
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:# store output of generations in dictresults=dict(outputs=[], num_tokens=0) # have each GPU do inference, prompt by promptfor prompt in prompts:prompt_tokenized=tokenizer(prompt, return_tensors="pt").to("cuda")output_tokenized = model.generate(**prompt_tokenized, max_new_tokens=100)[0] # remove prompt from output output_tokenized=output_tokenized[len(prompt_tokenized["input_ids"][0]):] # store outputs and number of tokens in result{}results["outputs"].append( tokenizer.decode(output_tokenized) )results["num_tokens"] += len(output_tokenized) results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time {timediff}, total tokens {num_tokens}, total prompts {len(prompts_all)}")
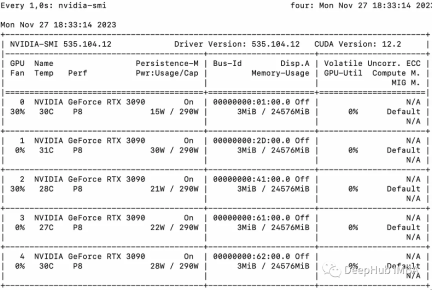
Die Verwendung mehrerer GPUs verursacht einen gewissen Kommunikationsaufwand: Die Leistung steigt linear bei 4 GPUs und dann hinein Dies ist in bestimmten Einstellungen tendenziell stabil. Natürlich hängt die Leistung hier von vielen Parametern wie Modellgröße und -quantisierung, Hinweislänge, Anzahl der generierten Token und Sampling-Strategie ab, daher diskutieren wir nur den allgemeinen Fall
1 GPU: 44 Token/Sek., Zeit: 225,5 s
2 GPUs: Verarbeitung von 88 Token pro Sekunde, eine Gesamtzeit von 112,9 Sekunden
3 GPUs: Verarbeitung von 128 Token pro Sekunde, eine Gesamtzeit von 77,6 Sekunden
4 GPUs: 137 Token/Sekunde, Zeit : 72,7 Sekunden
5 GPUs: 119 verarbeitete Token pro Sekunde, Gesamtzeit 83,8 Sekunden
Stapelverarbeitung auf mehreren GPUs
In der realen Welt können wir Batch-Inferenz verwenden, um Dinge zu beschleunigen hoch. Dies reduziert die Kommunikation zwischen GPUs und beschleunigt die Inferenz. Wir müssen nur die Funktion „prepare_prompts“ hinzufügen, um einen Datenstapel anstelle eines einzelnen Datenelements in das Modell einzugeben:
from accelerate import Accelerator from accelerate.utils import gather_object from transformers import AutoModelForCausalLM, AutoTokenizer from statistics import mean import torch, time, json accelerator = Accelerator() def write_pretty_json(file_path, data):import jsonwith open(file_path, "w") as write_file:json.dump(data, write_file, indent=4) # 10*10 Prompts. Source: https://www.penguin.co.uk/articles/2022/04/best-first-lines-in-books prompts_all=["The King is dead. Long live the Queen.","Once there were four children whose names were Peter, Susan, Edmund, and Lucy.","The story so far: in the beginning, the universe was created.","It was a bright cold day in April, and the clocks were striking thirteen.","It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife.","The sweat wis lashing oafay Sick Boy; he wis trembling.","124 was spiteful. Full of Baby's venom.","As Gregor Samsa awoke one morning from uneasy dreams he found himself transformed in his bed into a gigantic insect.","I write this sitting in the kitchen sink.","We were somewhere around Barstow on the edge of the desert when the drugs began to take hold.", ] * 10 # load a base model and tokenizer model_path="models/llama2-7b" model = AutoModelForCausalLM.from_pretrained(model_path,device_map={"": accelerator.process_index},torch_dtype=torch.bfloat16, ) tokenizer = AutoTokenizer.from_pretrained(model_path) tokenizer.pad_token = tokenizer.eos_token # batch, left pad (for inference), and tokenize def prepare_prompts(prompts, tokenizer, batch_size=16):batches=[prompts[i:i + batch_size] for i in range(0, len(prompts), batch_size)]batches_tok=[]tokenizer.padding_side="left" for prompt_batch in batches:batches_tok.append(tokenizer(prompt_batch, return_tensors="pt", padding='longest', truncatinotallow=False, pad_to_multiple_of=8,add_special_tokens=False).to("cuda") )tokenizer.padding_side="right"return batches_tok # sync GPUs and start the timer accelerator.wait_for_everyone() start=time.time() # divide the prompt list onto the available GPUs with accelerator.split_between_processes(prompts_all) as prompts:results=dict(outputs=[], num_tokens=0) # have each GPU do inference in batchesprompt_batches=prepare_prompts(prompts, tokenizer, batch_size=16) for prompts_tokenized in prompt_batches:outputs_tokenized=model.generate(**prompts_tokenized, max_new_tokens=100) # remove prompt from gen. tokensoutputs_tokenized=[ tok_out[len(tok_in):] for tok_in, tok_out in zip(prompts_tokenized["input_ids"], outputs_tokenized) ] # count and decode gen. tokens num_tokens=sum([ len(t) for t in outputs_tokenized ])outputs=tokenizer.batch_decode(outputs_tokenized) # store in results{} to be gathered by accelerateresults["outputs"].extend(outputs)results["num_tokens"] += num_tokens results=[ results ] # transform to list, otherwise gather_object() will not collect correctly # collect results from all the GPUs results_gathered=gather_object(results) if accelerator.is_main_process:timediff=time.time()-startnum_tokens=sum([r["num_tokens"] for r in results_gathered ]) print(f"tokens/sec: {num_tokens//timediff}, time elapsed: {timediff}, num_tokens {num_tokens}")
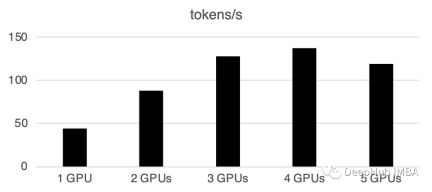
Sie können sehen, dass die Stapelverarbeitung die Geschwindigkeit erheblich beschleunigt.
Was neu geschrieben werden muss, ist: 1 GPU: 520 Token/Sekunde, Zeit: 19,2 Sekunden
Zwei GPUs haben eine Rechenleistung von 900 Token pro Sekunde und die Berechnungszeit beträgt 11,1 Sekunden
3 GPUs: 1205 Token/Sekunde, Zeit: 8,2 s
Vier GPUs: 1655 Token/Sekunde, benötigte Zeit: 6,0 Sekunden
5 GPUs: 1658 Token pro Sekunde Karte, Zeit: 6,0 Sekunden
Zusammenfassung
Zum Zeitpunkt dieses Artikels unterstützen llama.cpp und ctransformer keine Multi-GPU-Inferenz. Es scheint, dass llama.cpp im Juni eine Multi-GPU-Zusammenführung durchgeführt hat, aber ich habe kein offizielles Update gesehen Daher bin ich mir sicher, dass mehrere GPUs hier vorerst nicht unterstützt werden. Wenn jemand bestätigt, dass es mehrere GPUs unterstützt, hinterlassen Sie bitte eine Nachricht. Das Accelerate-Paket von
huggingface bietet uns eine sehr praktische Möglichkeit, mehrere GPUs für die Inferenz zu verwenden, aber die Kosten für die Kommunikation zwischen GPUs steigen erheblich, wenn die Anzahl der GPUs steigt.
Das obige ist der detaillierte Inhalt vonLLM-Inferenz auf mehreren GPUs mithilfe der Accelerate-Bibliothek. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Was ist Denkdiagramm in der schnellen IngenieurwesenApr 13, 2025 am 11:53 AM
Was ist Denkdiagramm in der schnellen IngenieurwesenApr 13, 2025 am 11:53 AMEinführung In prompt Engineering bezieht sich „Graph of Denk“ auf einen neuartigen Ansatz, der die Grafik Theorie verwendet, um die Argumentationsprozess von AI zu strukturieren und zu leiten. Im Gegensatz zu herkömmlichen Methoden, bei denen es sich häufig um lineare handelt
 Optimieren Sie die E -Mail -Marketing Ihres Unternehmens mit Genai -AgentenApr 13, 2025 am 11:44 AM
Optimieren Sie die E -Mail -Marketing Ihres Unternehmens mit Genai -AgentenApr 13, 2025 am 11:44 AMEinführung Glückwunsch! Sie führen ein erfolgreiches Geschäft. Über Ihre Webseiten, Social -Media -Kampagnen, Webinare, Konferenzen, kostenlose Ressourcen und andere Quellen sammeln Sie täglich 5000 E -Mail -IDs. Der nächste offensichtliche Schritt ist
 Echtzeit-App-Leistungsüberwachung mit Apache PinotApr 13, 2025 am 11:40 AM
Echtzeit-App-Leistungsüberwachung mit Apache PinotApr 13, 2025 am 11:40 AMEinführung In der heutigen schnelllebigen Softwareentwicklungsumgebung ist die Gewährleistung einer optimalen Anwendungsleistung von entscheidender Bedeutung. Die Überwachung von Echtzeitmetriken wie Antwortzeiten, Fehlerraten und Ressourcenauslastung kann die Hauptstufe unterstützen
 Chatgpt trifft 1 Milliarde Benutzer? 'In nur wenigen Wochen verdoppelt', sagt OpenAI -CEOApr 13, 2025 am 11:23 AM
Chatgpt trifft 1 Milliarde Benutzer? 'In nur wenigen Wochen verdoppelt', sagt OpenAI -CEOApr 13, 2025 am 11:23 AM"Wie viele Benutzer haben Sie?" er stapte. "Ich denke, das letzte Mal, als wir sagten, wächst 500 Millionen wöchentliche Wirkstoffe, und es wächst sehr schnell", antwortete Altman. "Du hast mir gesagt, dass es sich in nur wenigen Wochen verdoppelt hat", fuhr Anderson fort. „Ich habe das Privat gesagt
 Pixtral -12b: Mistral AIs erstes multimodales Modell - Analytics VidhyaApr 13, 2025 am 11:20 AM
Pixtral -12b: Mistral AIs erstes multimodales Modell - Analytics VidhyaApr 13, 2025 am 11:20 AMEinführung Mistral hat sein erstes multimodales Modell veröffentlicht, nämlich den Pixtral-12b-2409. Dieses Modell basiert auf dem 12 -Milliarden -Parameter von Mistral, NEMO 12b. Was unterscheidet dieses Modell? Es kann jetzt sowohl Bilder als auch Tex aufnehmen
 Agentenrahmen für generative KI -Anwendungen - Analytics VidhyaApr 13, 2025 am 11:13 AM
Agentenrahmen für generative KI -Anwendungen - Analytics VidhyaApr 13, 2025 am 11:13 AMStellen Sie sich vor, Sie hätten einen AS-Assistenten mit KI, der nicht nur auf Ihre Abfragen reagiert, sondern auch autonom Informationen sammelt, Aufgaben ausführt und sogar mehrere Arten von Daten ausführt-Text, Bilder und Code. Klingt futuristisch? In diesem a
 Anwendungen der Generativen KI im FinanzsektorApr 13, 2025 am 11:12 AM
Anwendungen der Generativen KI im FinanzsektorApr 13, 2025 am 11:12 AMEinführung Die Finanzbranche ist der Eckpfeiler der Entwicklung eines Landes, da sie das Wirtschaftswachstum fördert, indem sie effiziente Transaktionen und Kreditverfügbarkeit erleichtert. Die Leichtigkeit, mit der Transaktionen auftreten und Krediten auftreten
 Leitfaden für Online-Lernen und passiv-aggressive AlgorithmenApr 13, 2025 am 11:09 AM
Leitfaden für Online-Lernen und passiv-aggressive AlgorithmenApr 13, 2025 am 11:09 AMEinführung Daten werden mit beispielloser Geschwindigkeit aus Quellen wie Social Media, Finanztransaktionen und E-Commerce-Plattformen generiert. Der Umgang mit diesem kontinuierlichen Informationsstrom ist eine Herausforderung, aber sie bietet eine


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

DVWA
Damn Vulnerable Web App (DVWA) ist eine PHP/MySQL-Webanwendung, die sehr anfällig ist. Seine Hauptziele bestehen darin, Sicherheitsexperten dabei zu helfen, ihre Fähigkeiten und Tools in einem rechtlichen Umfeld zu testen, Webentwicklern dabei zu helfen, den Prozess der Sicherung von Webanwendungen besser zu verstehen, und Lehrern/Schülern dabei zu helfen, in einer Unterrichtsumgebung Webanwendungen zu lehren/lernen Sicherheit. Das Ziel von DVWA besteht darin, einige der häufigsten Web-Schwachstellen über eine einfache und unkomplizierte Benutzeroberfläche mit unterschiedlichen Schwierigkeitsgraden zu üben. Bitte beachten Sie, dass diese Software

Herunterladen der Mac-Version des Atom-Editors
Der beliebteste Open-Source-Editor

Dreamweaver CS6
Visuelle Webentwicklungstools

