



写在前面&笔者的个人理解
目前,随着自动驾驶技术的越发成熟以及自动驾驶感知任务需求的日益增多,工业界和学术界非常希望一个理想的感知算法模型,可以同时完成三维目标检测以及基于BEV空间的语义分割任务。对于一辆能够实现自动驾驶功能的车辆而言,其通常会配备环视相机传感器、激光雷达传感器以及毫米波雷达传感器来采集不同模态的数据信息。从而充分利用不同模态数据之间的互补优势,使得不同模态之间的数据补充优势,比如三维点云数据可以为3D目标检测任务提供信息,而彩色图像数据则可以为语义分割任务提供更加准确的信息。 针对于不同模态数据之间的互补优势,通过将不同模态数据的有效信息转化到同一个坐标系中,便于之后的联合处理以及决策。比如三维点云数据可以转化到基于BEV空间的点云数据,而环视摄像头的图像数据可以通过相机内外参的标定将其投影到3D空间中,从而实现不同模态数据的统一处理。通过利用不同模态数据的优势,可以得到比单一模态数据更为准确的感知结果。 现在,我们已经可以部署在车上的多模态感知算法模型输出更加鲁棒准确的空间感知结果,通过精确的空间感知结果,可以为自动驾驶功能的实现提供更加可靠和安全的保障。
虽然最近在学术界和工业界提出了许多基于Transformer网络框架的多传感、多模态数据融合的3D感知算法,但均采用了Transformer中的交叉注意力机制来实现多模态数据之间的融合,以实现比较理想的3D目标检测结果。但是这类多模态的特征融合方法并不完全适用于基于BEV空间的语义分割任务。此外,除了采用交叉注意力机制来完成不同模态之间信息融合的方法外,很多算法采用基于LSA中前向向量转换方式来构建融合后的特征,但也存在着如下的一些问题:(限制字数,接下来进行具体描述)。
- 由于目前提出的相关多模态融合的3D感知算法,对于不同模态数据特征的融合方式设计的还不够充分,造成感知算法模型无法准确捕获到传感器数据之间的复杂连接关系,进而影响模型的最终感知性能。
- 不同传感器采集数据的过程中难免会引入无关的噪声信息,这种不同模态之间的内在噪声,也会导致不同模态特征融合的过程中会混入噪声,从而造成多模态特征融合的不准确,影响后续的感知任务。
针对上述提到的在多模态融合过程中存在的诸多可能会影响到最终模型感知能力的问题,同时考虑到生成模型最近展现出来的强大性能,我们对生成模型进行了探索,用于实现多传感器之间的多模态融合和去噪任务。基于此,我们提出了一种基于条件扩散的生成模型感知算法DifFUSER,用于实现多模态的感知任务。通过下图可以看出,我们提出的DifFUSER多模态数据融合算法可以实现更加有效的多模态融合过程。  DifFUSER多模态数据融合算法可以实现更加有效的多模态融合过程,方法主要包括两个阶段。首先,我们使用生成模型对输入数据进行降噪和增强,生成干净且丰富的多模态数据。然后,利用生成模型生成的数据进行多模态融合,达到更好的感知效果。 通过DifFUSER算法的实验结果显示,我们提出的多模态数据融合算法可以实现更加有效的多模态融合过程。该算法在实现多模态感知任务时,能够实现更加有效的多模态融合过程,提升模型的感知能力。此外,该算法的多模态数据融合算法可以实现更加有效的多模态融合过程。总而言之
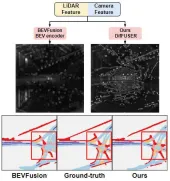
提出的算法模型与其它算法模型的结果可视化对比图
论文链接:https://arxiv.org/pdf/2404.04629.pdf
网络模型的整体架构&细节梳理
"DifFUSER算法的模块细节,基于条件扩散模型的多任务感知算法"是一种用于解决任务感知问题的算法。下图展示了我们提出的DifFUSER算法的整体网络结构。 在这个模块中,我们提出了一种基于条件扩散模型的多任务感知算法,用于解决任务感知问题。该算法的目标是通过在网络中传播和聚合任务特定的信息来提高多任务学习的性能。 DifFUSER算法的整
 提出的DifFUSER感知算法模型网络结构图
提出的DifFUSER感知算法模型网络结构图
通过上图可以看出,我们提出的DifFUSER网络结构主要包括三个子网络,分别是主干网络部分、DifFUSER的多模态数据融合部分以及最终的BEV语义分割任务头部分。3D目标检测感知任务头部分。 在主干网络部分,我们使用了现有的深度学习网络架构,如ResNet或VGG等,通过提取输入数据的高级特征。 DifFUSER的多模态数据融合部分使用了多个并行的分支,每个分支用于处理不同的传感器数据类型(如图像、激光雷达和雷达等)。每个分支都有自
- 主干网络部分:该部分主要对网络模型输入的2D图像数据以及3D的激光雷达点云数据进行特征提取用于输出相对应的BEV语义特征。对于提取图像特征的主干网络而言,主要包括2D的图像主干网络以及视角转换模块。对于提取3D的激光雷达点云特征的主干网络而言,主要包括3D的点云主干网络以及特征Flatten模块。
- DifFUSER多模态数据融合部分:我们提出的DifFUSER模块以层级的双向特征金字塔网络的形式链接在一起,我们把这样的结构称为cMini-BiFPN。该结构为潜在的扩散提供了可以替代的结构,可以更好的处理来自不同传感器数据中的多尺度和宽高详细特征信息。
- BEV语义分割、3D目标检测感知任务头部分:由于我们的算法模型可以同时输出3D目标检测结果以及BEV空间的语义分割结果,所以3D感知任务头包括3D检测头以及语义分割头。此外,我们提出的算法模型涉及到的损失则包括扩散损失、检测损失和语义分割损失,通过将所有损失进行求和,并通过反向传播的方式来更新网络模型的参数。
接下来,我们会仔细介绍模型中各个主要子部分的实现细节。
融合架构设计(Conditional-Mini-BiFPN,cMini-BiFPN)
对于自动驾驶系统中的感知任务而言,算法模型能够对当前的外部环境进行实时的感知是至关重要的,所以确保扩散模块的性能和效率是非常重要的。因此,我们从双向特征金字塔网络中得到启发,引入一种条件类似的BiFPN扩散架构,我们称之为Conditional-Mini-BiFPN,其具体的网络结构如上图所示。


渐进传感器Dropout训练(PSDT)
对于一辆自动驾驶汽车而言,配备的自动驾驶采集传感器的性能至关重要,在自动驾驶车辆日常行驶的过程中,极有可能会出现相机传感器或者激光雷达传感器出现遮挡或者故障的问题,从而影响最终自动驾驶系统的安全性以及运行效率。基于这一考虑出发,我们提出了渐进式的传感器Dropout训练范式,用于增强提出的算法模型在传感器可能被遮挡等情况下的鲁棒性和适应性。
通过我们提出的渐进传感器Dropout训练范式,可以使得算法模型通过利用相机传感器以及激光雷达传感器采集到的两种模态数据的分布,重建缺失的特征,从而实现了在恶劣状况下的出色适应性和鲁棒性。具体而言,我们利用来自图像数据和激光雷达点云数据的特征,以三种不同的方式进行使用,分别是作为训练目标、扩散模块的噪声输入以及模拟传感器丢失或故障的条件,为了模拟传感器丢失或故障的条件,我们在训练期间逐渐将相机传感器或激光雷达传感器输入的丢失率从0增加到预定义的最大值a=25。整个过程可以用下面的公式进行表示:
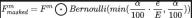
其中,代表当前模型所处的训练轮数,通过定义dropout的概率用于表示特征中每个特征被丢弃的概率。通过这种渐进式的训练过程,不仅训练模型有效去噪并生成更具有表现力的特征,而且还最大限度地减少其对任何单个传感器的依赖,从而增强其处理具有更大弹性的不完整传感器数据的能力。
门控自条件调制扩散模块(GSM Diffusion Module)

具体而言,门控自条件调制扩散模块的网络结构如下图所示

门控自条件调制扩散模块网络结构示意图

实验结果&评价指标
定量分析部分
为了验证我们提出的算法模型DifFUSER在多任务上的感知结果,我们主要在nuScenes数据集上进行了3D目标检测以及基于BEV空间的语义分割实验。
首先,我们比较了提出的算法模型DifFUSER与其它的多模态融合算法在语义分割任务上的性能对比情况,具体的实验结果如下表所示:
 不同算法模型在nuScenes数据集上的基于BEV空间的语义分割任务的实验结果对比情况
不同算法模型在nuScenes数据集上的基于BEV空间的语义分割任务的实验结果对比情况
通过实验结果可以看出,我们提出的算法模型相比于基线模型而言在性能上有着显著的提高。具体而言,BEVFusion模型的mIoU值只有62.7%,而我们提出的算法模型已经达到了69.1%,具有6.4%个点的提升,这表明我们提出的算法在不同类别上都更有优势。此外,下图也更加直观的说明了我们提出的算法模型更具有优势。具体而言,BEVFusion算法会输出较差的分割结果,尤其在远距离的场景下,传感器错位的情况更加明显。与之相比,我们的算法模型具有更加准确的分割结果,细节更加明显,噪声更少。

提出算法模型与基线模型的分割可视化结果对比
此外,我们也将提出的算法模型与其它的3D目标检测算法模型进行对比,具体的实验结果如下表所示

不同算法模型在nuScenes数据集上的3D目标检测任务的实验结果对比情况
通过表格当中列出的结果可以看出,我们提出的算法模型DifFUSER相比于基线模型在NDS和mAP指标上均有提高,相比于基线模型BEVFusion的72.9%NDS以及70.2%的mAP,我们的算法模型分别要高出1.8%以及1.0%。相关指标的提升表明,我们提出的多模态扩散融合模块对特征的减少和特征的细化过程是有效的。
此外,为了表明我们提出的算法模型在传感器故障或者遮挡情况下的感知鲁棒性,我们进行了相关分割任务的结果比较,如下图所示。

不同情况下的算法性能比较
通过上图可以看出,在采样充足的情况下,我们提出的算法模型可以有效的对缺失特征进行补偿,用于作为缺失传感器采集信息的替代内容。我们提出的DifFUSER算法模型生成和利用合成特征的能力,有效地减轻了对任何单一传感器模态的依赖,确保模型在多样化和具有挑战性的环境中能够平稳运行。
定性分析部分
下图展示了我们提出的DifFUSER算法模型在3D目标检测以及BEV空间的语义分割结果的可视化,通过可视化结果可以看出,我们提出的算法模型具有很好的检测和分割效果。

结论
本文提出了一个基于扩散模型的多模态感知算法模型DifFUSER,通过改进网络模型的融合架构以及利用扩散模型的去噪特性来提高网络模型的融合质量。通过在Nuscenes数据集上的实验结果表明,我们提出的算法模型在BEV空间的语义分割任务中实现了SOTA的分割性能,在3D目标检测任务中可以和当前SOTA的算法模型取得相近的检测性能。
以上是超越BEVFusion!DifFUSER:扩散模型杀入自动驾驶多任务(BEV分割+检测双SOTA)的详细内容。更多信息请关注PHP中文网其他相关文章!

 大多数使用的10个功率BI图 - 分析VidhyaApr 16, 2025 pm 12:05 PM
大多数使用的10个功率BI图 - 分析VidhyaApr 16, 2025 pm 12:05 PM用Microsoft Power BI图来利用数据可视化的功能 在当今数据驱动的世界中,有效地将复杂信息传达给非技术观众至关重要。 数据可视化桥接此差距,转换原始数据i
 AI的专家系统Apr 16, 2025 pm 12:00 PM
AI的专家系统Apr 16, 2025 pm 12:00 PM专家系统:深入研究AI的决策能力 想象一下,从医疗诊断到财务计划,都可以访问任何事情的专家建议。 这就是人工智能专家系统的力量。 这些系统模仿Pro
 三个最好的氛围编码器分解了这项代码中的AI革命Apr 16, 2025 am 11:58 AM
三个最好的氛围编码器分解了这项代码中的AI革命Apr 16, 2025 am 11:58 AM首先,很明显,这种情况正在迅速发生。各种公司都在谈论AI目前撰写的代码的比例,并且这些代码的比例正在迅速地增加。已经有很多工作流离失所
 跑道AI的Gen-4:AI蒙太奇如何超越荒谬Apr 16, 2025 am 11:45 AM
跑道AI的Gen-4:AI蒙太奇如何超越荒谬Apr 16, 2025 am 11:45 AM从数字营销到社交媒体的所有创意领域,电影业都站在技术十字路口。随着人工智能开始重塑视觉讲故事的各个方面并改变娱乐的景观
 如何注册5天ISRO AI免费课程? - 分析VidhyaApr 16, 2025 am 11:43 AM
如何注册5天ISRO AI免费课程? - 分析VidhyaApr 16, 2025 am 11:43 AMISRO的免费AI/ML在线课程:通向地理空间技术创新的门户 印度太空研究组织(ISRO)通过其印度遥感研究所(IIR)为学生和专业人士提供了绝佳的机会
 AI中的本地搜索算法Apr 16, 2025 am 11:40 AM
AI中的本地搜索算法Apr 16, 2025 am 11:40 AM本地搜索算法:综合指南 规划大规模活动需要有效的工作量分布。 当传统方法失败时,本地搜索算法提供了强大的解决方案。 本文探讨了爬山和模拟
 OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑Apr 16, 2025 am 11:37 AM
OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑Apr 16, 2025 am 11:37 AM该版本包括三种不同的型号,GPT-4.1,GPT-4.1 MINI和GPT-4.1 NANO,标志着向大语言模型景观内的特定任务优化迈进。这些模型并未立即替换诸如
 提示:chatgpt生成假护照Apr 16, 2025 am 11:35 AM
提示:chatgpt生成假护照Apr 16, 2025 am 11:35 AMChip Giant Nvidia周一表示,它将开始制造AI超级计算机(可以处理大量数据并运行复杂算法的机器),完全是在美国首次在美国境内。这一消息是在特朗普总统SI之后发布的


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

SublimeText3 Linux新版
SublimeText3 Linux最新版

Atom编辑器mac版下载
最流行的的开源编辑器

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

