



写在前面&个人理解
多视图深度估计在各种基准测试中都取得了较高性能。然而,目前几乎所有的多视图系统都依赖于给定的理想相机姿态,而这在许多现实世界的场景中是不可用的,例如自动驾驶。本工作提出了一种新的鲁棒性基准来评估各种噪声姿态设置下的深度估计系统。令人惊讶的是,发现当前的多视图深度估计方法或单视图和多视图融合方法在给定有噪声的姿态设置时会失败。为了应对这一挑战,这里提出了一种单视图和多视图融合的深度估计系统AFNet,该系统自适应地集成了高置信度的多视图和单视图结果,以实现稳健和准确的深度估计。自适应融合模块通过基于包裹置信度图在两个分支之间动态选择高置信度区域来执行融合。因此,当面对无纹理场景、不准确的校准、动态对象和其他退化或具有挑战性的条件时,系统倾向于选择更可靠的分支。在稳健性测试下,方法优于最先进的多视图和融合方法。此外,在具有挑战性的基准测试中实现了最先进的性能 (KITTI和DDAD)。
论文链接:https://arxiv.org/pdf/2403.07535.pdf
论文名称:Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
领域背景
图像深度估计一直是计算机视觉领域的一个挑战,具有广泛的应用。对于基于视觉的自动驾驶系统,深度感知是关键,它有助于理解道路上的物体并构建3D环境地图。随着深度神经网络在各种视觉问题中的应用,基于卷积神经网络(CNN)的方法已经成为深度估计任务的主流。
根据输入格式,主要分为多视角深度估计和单视角深度估计。多视图方法估计深度的假设是,给定正确的深度、相机标定和相机姿态,各个视图的像素应该相似。他们依靠极线几何来三角测量高质量的深度。然而,多视图方法的准确性和鲁棒性在很大程度上取决于相机的几何配置和视图之间的对应匹配。首先,摄像机需要进行足够的平移以进行三角测量。在自动驾驶场景中,自车可能会在红绿灯处停车或在不向前移动的情况下转弯,这会导致三角测量失败。此外,多视图方法存在动态目标和无纹理区域的问题,这些问题在自动驾驶场景中普遍存在。另一个问题是运动车辆上的SLAM姿态优化。在现有的SLAM方法中,噪声是不可避免的,更不用说具有挑战性和不可避免的情况了。例如,一个机器人或自动驾驶汽车可以在不重新校准的情况下部署数年,从而导致姿势嘈杂。相比之下,由于单视图方法依赖于对场景的语义理解和透视投影线索,因此它们对无纹理区域、动态对象更具鲁棒性,而不依赖于相机姿势。然而,由于尺度的模糊性,其性能与多视图方法相比仍有很大差距。在这里,我们倾向于考虑是否可以很好地结合这两种方法的优势,在自动驾驶场景中进行稳健和准确的单目视频深度估计。
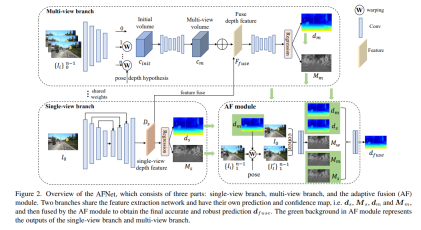
AFNet网络结构
AFNet结构如下所示,它由三个部分组成:单视图分支、多视图分支和自适应融合(AF)模块。两个分支共享特征提取网络,并具有自己的预测和置信度图,即、,和,然后由AF模块进行融合,以获得最终准确和稳健的预测,AF模块中的绿色背景表示单视图分支和多视图分支的输出。
损失函数:
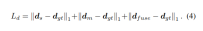
单视图和多视图深度模块
为了合并主干特征并获得深度特征Ds,AFNet构建了一个多尺度解码器。在这个过程中,对Ds的前256个通道进行softmax操作,得到深度概率体积Ps。而深度特征中的最后一个通道则被用作单视图深度的置信图Ms。最后,通过软加权的方式来计算单视图深度。
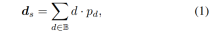
多视图分支
多视图分支与单视图分支共享主干,以提取参考图像和源图像的特征。我们采用去卷积将低分辨率特征去卷积为四分之一分辨率,并将它们与用于构建cost volume的初始四分之一特征相结合。通过将源特征wrap到参考相机跟随的假设平面中,形成特征volume。用于不需要太多的鲁棒匹配信息,在计算中保留了特征的通道维度并构建了4D cost volume,然后通过两个3D卷积层将通道数量减少到1。
深度假设的采样方法与单视图分支一致,但采样数量仅为128,然后使用堆叠的2D沙漏网络进行正则化,以获得最终的多视图cost volume。为了补充单视图特征的丰富语义信息和由于成本正则化而丢失的细节,使用残差结构来组合单视图深度特征Ds和cost volume,以获得融合深度特征,如下所示:
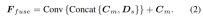
自适应融合模块
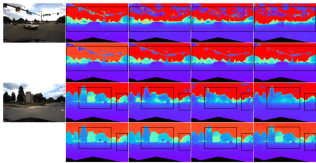
为了获得最终准确和稳健的预测,设计了AF模块,以自适应地选择两个分支之间最准确的深度作为最终输出,如图2所示。通过三个confidence进行融合映射,其中两个是由两个分支分别生成的置信图Ms和Mm,最关键的一个是通过前向wrapping生成的置信度图Mw,以判断多视图分支的预测是否可靠。
实验结果
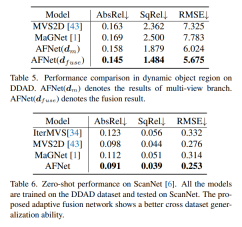
DDAD(自动驾驶的密集深度)是一种新的自动驾驶基准,用于在具有挑战性和多样化的城市条件下进行密集深度估计。它由6台同步相机拍摄,并包含高密度激光雷达生成的准确的地GT深度(整个360度视场)。它在单个相机视图中有12650个训练样本和3950个验证样本,其中分辨率为1936×1216。来自6台摄像机的全部数据用于训练和测试。KITTI数据集,提供运动车辆上拍摄的户外场景的立体图像和相应的3D激光scan,分辨率约为1241×376。
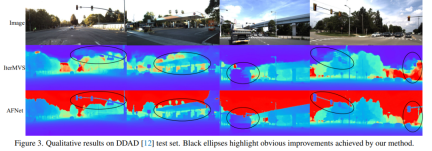
DDAD和KITTI上的评测结果对比。请注意,* 标记了使用其开源代码复制的结果,其他报告的数字来自相应的原始论文。
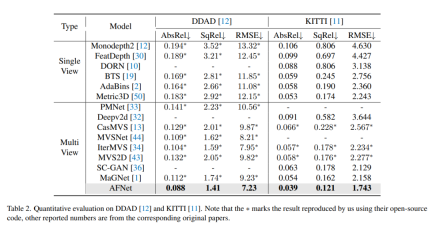
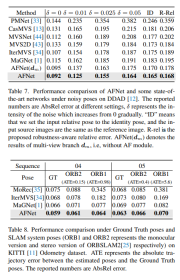
DDAD上方法中每种策略的消融实验结果。Single表示单视图分支预测的结果,Multi-表示多视图分支预测结果,Fuse表示融合结果dfuse。
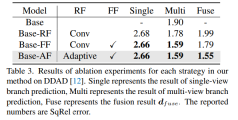
消融结果的特征提取网络参数共享和提取匹配信息的方法。
以上是深度估计SOTA!自动驾驶单目与环视深度的自适应融合的详细内容。更多信息请关注PHP中文网其他相关文章!

 在LLMS中调用工具Apr 14, 2025 am 11:28 AM
在LLMS中调用工具Apr 14, 2025 am 11:28 AM大型语言模型(LLMS)的流行激增,工具称呼功能极大地扩展了其功能,而不是简单的文本生成。 现在,LLM可以处理复杂的自动化任务,例如Dynamic UI创建和自主a
 多动症游戏,健康工具和AI聊天机器人如何改变全球健康Apr 14, 2025 am 11:27 AM
多动症游戏,健康工具和AI聊天机器人如何改变全球健康Apr 14, 2025 am 11:27 AM视频游戏可以缓解焦虑,建立焦点或支持多动症的孩子吗? 随着医疗保健在全球范围内挑战,尤其是在青年中的挑战,创新者正在转向一种不太可能的工具:视频游戏。现在是世界上最大的娱乐印度河之一
 没有关于AI的投入:获胜者,失败者和机遇Apr 14, 2025 am 11:25 AM
没有关于AI的投入:获胜者,失败者和机遇Apr 14, 2025 am 11:25 AM“历史表明,尽管技术进步推动了经济增长,但它并不能自行确保公平的收入分配或促进包容性人类发展,”乌托德秘书长Rebeca Grynspan在序言中写道。
 通过生成AI学习谈判技巧Apr 14, 2025 am 11:23 AM
通过生成AI学习谈判技巧Apr 14, 2025 am 11:23 AM易于使用,使用生成的AI作为您的谈判导师和陪练伙伴。 让我们来谈谈。 对创新AI突破的这种分析是我正在进行的《福布斯》列的最新覆盖范围的一部分,包括识别和解释
 泰德(Ted)从Openai,Google,Meta透露出庭,与我自己自拍Apr 14, 2025 am 11:22 AM
泰德(Ted)从Openai,Google,Meta透露出庭,与我自己自拍Apr 14, 2025 am 11:22 AM在温哥华举行的TED2025会议昨天在4月11日举行了第36版。它有来自60多个国家 /地区的80个发言人,包括Sam Altman,Eric Schmidt和Palmer Luckey。泰德(Ted)的主题“人类重新构想”是量身定制的
 约瑟夫·斯蒂格利兹(Joseph StiglitzApr 14, 2025 am 11:21 AM
约瑟夫·斯蒂格利兹(Joseph StiglitzApr 14, 2025 am 11:21 AM约瑟夫·斯蒂格利茨(Joseph Stiglitz)是2001年著名的经济学家,是诺贝尔经济奖的获得者。斯蒂格利茨认为,AI可能会使现有的不平等和合并权力恶化,并在几个主导公司的手中加剧,最终破坏了经济的经济。
 什么是图形数据库?Apr 14, 2025 am 11:19 AM
什么是图形数据库?Apr 14, 2025 am 11:19 AM图数据库:通过关系彻底改变数据管理 随着数据的扩展及其特征在各个字段中的发展,图形数据库正在作为管理互连数据的变革解决方案的出现。与传统不同
 LLM路由:策略,技术和Python实施Apr 14, 2025 am 11:14 AM
LLM路由:策略,技术和Python实施Apr 14, 2025 am 11:14 AM大型语言模型(LLM)路由:通过智能任务分配优化性能 LLM的快速发展的景观呈现出各种各样的模型,每个模型都具有独特的优势和劣势。 有些在创意内容gen上表现出色


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SublimeText3 Linux新版
SublimeText3 Linux最新版

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

Dreamweaver CS6
视觉化网页开发工具

