



Sora 在 2024 年初的惊艳表现成为了新的标杆,激励着所有研究文生视频的人士争相追赶。每个研究者都怀着复现 Sora 成果的渴望,争分夺秒地努力着。
根据 OpenAI 披露的技术报告,Sora 的一个重要创新点是将视觉数据转换为 patch 的统一表示形式,并通过 Transformer 和扩散模型相结合,展现了出色的扩展性。随着报告的发布,Sora 的核心研发人员 William Peebles 和纽约大学计算机科学助理教授谢赛宁合作撰写的《Scalable Diffusion Models with Transformers》论文备受研究者关注。研究界希望通过论文中提出的 DiT 架构,探索再现 Sora 的可行性途径。
最近,新加坡国立大学尤洋团队开源的一个名为 OpenDiT 的项目为训练和部署 DiT 模型打开了新思路。
OpenDiT是一个专为提升DiT应用程序的训练和推理效率而设计的系统,它不仅易于操作,而且速度快且内存利用高效。该系统涵盖了文本到视频生成和文本到图像生成等功能,旨在为用户提供高效、便捷的体验。
项目地址:https://github.com/NUS-HPC-AI-Lab/OpenDiT
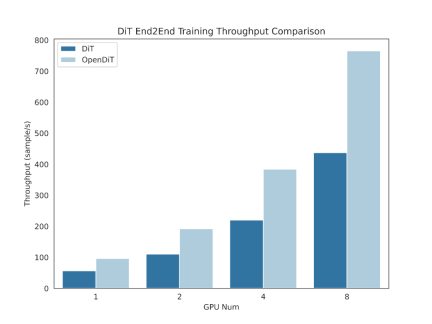
OpenDiT 方法介绍
OpenDiT 提供由 Colossal-AI 支持的 Diffusion Transformer (DiT) 的高性能实现。在训练时,视频和条件信息分别被输入到相应的编码器中,作为DiT模型的输入。随后,通过扩散方法进行训练和参数更新,最终将更新后的参数同步至EMA(Exponential Moving Average)模型。推理阶段则直接使用EMA模型,将条件信息作为输入,从而生成对应的结果。
图源:https://www.zhihu.com/people/berkeley-you-yang
OpenDiT 利用了 ZeRO 并行策略,将 DiT 模型参数分布到多台机器上,初步降低了显存压力。为了取得更好的性能与精度平衡,OpenDiT 还采用了混合精度的训练策略。具体而言,模型参数和优化器使用 float32 进行存储,以确保更新的准确性。在模型计算的过程中,研究团队为 DiT 模型设计了 float16 和 float32 的混合精度方法,以在维持模型精度的同时加速计算过程。
DiT 模型中使用的 EMA 方法是一种用于平滑模型参数更新的策略,可以有效提高模型的稳定性和泛化能力。但是会额外产生一份参数的拷贝,增加了显存的负担。为了进一步降低这部分显存,研究团队将 EMA 模型分片,并分别存储在不同的 GPU 上。在训练过程中,每个 GPU 只需计算和存储自己负责的部分 EMA 模型参数,并在每次 step 后等待 ZeRO 完成更新后进行同步更新。
FastSeq
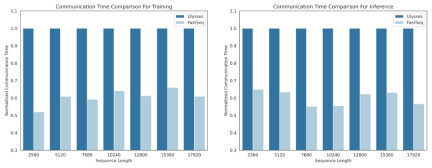
在 DiT 等视觉生成模型领域,序列并行性对于有效的长序列训练和低延迟推理是必不可少的。
然而,DeepSpeed-Ulysses、Megatron-LM Sequence Parallelism 等现有方法在应用于此类任务时面临局限性 —— 要么是引入过多的序列通信,要么是在处理小规模序列并行时缺乏效率。
为此,研究团队提出了 FastSeq,一种适用于大序列和小规模并行的新型序列并行。FastSeq 通过为每个 transformer 层仅使用两个通信运算符来最小化序列通信,利用 AllGather 来提高通信效率,并策略性地采用异步 ring 将 AllGather 通信与 qkv 计算重叠,进一步优化性能。
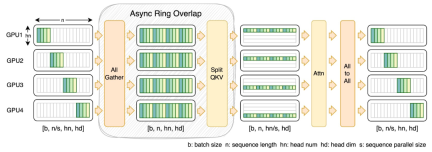
算子优化
在 DiT 模型中引入 adaLN 模块将条件信息融入视觉内容,虽然这一操作对模型的性能提升至关重要,但也带来了大量的逐元素操作,并且在模型中被频繁调用,降低了整体的计算效率。为了解决这个问题,研究团队提出了高效的 Fused adaLN Kernel,将多次操作合并成一次,从而增加了计算效率,并且减少了视觉信息的 I/O 消耗。
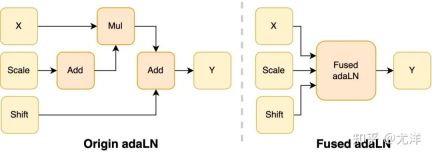
图源:https://www.zhihu.com/people/berkeley-you-yang
简单来说,OpenDiT 具有以下性能优势:
1、在 GPU 上加速高达 80%,50%的内存节省
- 设计了高效的算子,包括针对DiT设计的 Fused AdaLN,以及 FlashAttention、Fused Layernorm 和HybridAdam。
- 采用混合并行方法,包括 ZeRO、Gemini 和 DDP。对 ema 模型进行分片也进一步降低了内存成本。
2、FastSeq:一种新颖的序列并行方法
- 专为类似 DiT 的工作负载而设计,在这些应用中,序列通常较长,但参数相比于 LLM 较小。
- 节点内序列并行可节省高达 48% 的通信量。
- 打破单个 GPU 的内存限制,减少整体训练和推理时间。
3、易于使用
- 只需几行代码的修改,即可获得巨大的性能提升。
- 用户无需了解分布式训练的实现方式。
4、文本到图像和文本到视频生成完整 pipeline
- 研究人员和工程师可以轻松使用 OpenDiT pipeline 并将其应用于实际应用,而无需修改并行部分。
- 研究团队通过在 ImageNet 上进行文本到图像训练来验证 OpenDiT 的准确性,并发布了检查点(checkpoint)。
安装与使用
要使用 OpenDiT,首先要安装先决条件:
- Python >= 3.10
- PyTorch >= 1.13(建议使用 >2.0 版本)
- CUDA >= 11.6
建议使用 Anaconda 创建一个新环境(Python >= 3.10)来运行示例:
conda create -n opendit pythnotallow=3.10 -yconda activate opendit
安装 ColossalAI:
git clone https://github.com/hpcaitech/ColossalAI.gitcd ColossalAIgit checkout adae123df3badfb15d044bd416f0cf29f250bc86pip install -e .
安装 OpenDiT:
git clone https://github.com/oahzxl/OpenDiTcd OpenDiTpip install -e .
(可选但推荐)安装库以加快训练和推理速度:
# Install Triton for fused adaln kernelpip install triton# Install FlashAttentionpip install flash-attn# Install apex for fused layernorm kernelgit clone https://github.com/NVIDIA/apex.gitcd apexgit checkout 741bdf50825a97664db08574981962d66436d16apip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-optinotallow=--cpp_ext" --config-settings "--build-optinotallow=--cuda_ext" ./--global-optinotallow="--cuda_ext" --global-optinotallow="--cpp_ext"
图像生成
你可以通过执行以下命令来训练 DiT 模型:
# Use scriptbash train_img.sh# Use command linetorchrun --standalone --nproc_per_node=2 train.py \--model DiT-XL/2 \--batch_size 2
默认禁用所有加速方法。以下是训练过程中一些关键要素的详细信息:
- plugin: 支持 ColossalAI、zero2 和 ddp 使用的 booster 插件。默认是 zero2,建议启用 zero2。
- mixed_ precision:混合精度训练的数据类型,默认是 fp16。
- grad_checkpoint: 是否启用梯度检查点。这节省了训练过程的内存成本。默认值为 False。建议在内存足够的情况下禁用它。
- enable_modulate_kernel: 是否启用 modulate 内核优化,以加快训练过程。默认值为 False,建议在 GPU
- enable_layernorm_kernel: 是否启用 layernorm 内核优化,以加快训练过程。默认值为 False,建议启用它。
- enable_flashattn: 是否启用 FlashAttention,以加快训练过程。默认值为 False,建议启用。
- sequence_parallel_size:序列并行度大小。当设置值 > 1 时将启用序列并行。默认值为 1,如果内存足够,建议禁用它。
如果你想使用 DiT 模型进行推理,可以运行如下代码,需要将检查点路径替换为你自己训练的模型。
# Use scriptbash sample_img.sh# Use command linepython sample.py --model DiT-XL/2 --image_size 256 --ckpt ./model.pt
视频生成
你可以通过执行以下命令来训练视频 DiT 模型:
# train with sciptbash train_video.sh# train with command linetorchrun --standalone --nproc_per_node=2 train.py \--model vDiT-XL/222 \--use_video \--data_path ./videos/demo.csv \--batch_size 1 \--num_frames 16 \--image_size 256 \--frame_interval 3# preprocess# our code read video from csv as the demo shows# we provide a code to transfer ucf101 to csv formatpython preprocess.py
使用 DiT 模型执行视频推理的代码如下所示:
# Use scriptbash sample_video.sh# Use command linepython sample.py \--model vDiT-XL/222 \--use_video \--ckpt ckpt_path \--num_frames 16 \--image_size 256 \--frame_interval 3
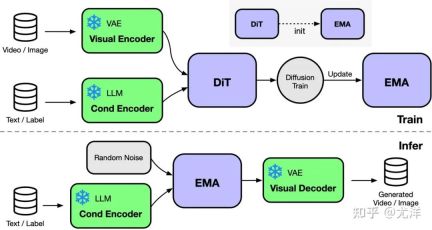
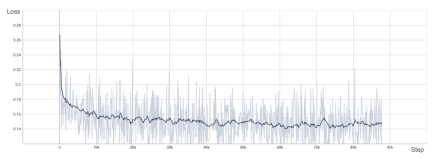
DiT 复现结果
为了验证 OpenDiT 的准确性,研究团队使用 OpenDiT 的 origin 方法对 DiT 进行了训练,在 ImageNet 上从头开始训练模型,在 8xA100 上执行 80k step。以下是经过训练的 DiT 生成的一些结果:

损失也与 DiT 论文中列出的结果一致:
要复现上述结果,需要更改 train_img.py 中的数据集并执行以下命令:
torchrun --standalone --nproc_per_node=8 train.py \--model DiT-XL/2 \--batch_size 180 \--enable_layernorm_kernel \--enable_flashattn \--mixed_precision fp16
感兴趣的读者可以查看项目主页,了解更多研究内容。
以上是想训练类Sora模型吗?尤洋团队OpenDiT实现80%加速的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何使用Huggingface Smollm建立个人AI助手Apr 18, 2025 am 11:52 AM
如何使用Huggingface Smollm建立个人AI助手Apr 18, 2025 am 11:52 AM利用“设备” AI的力量:建立个人聊天机器人CLI 在最近的过去,个人AI助手的概念似乎是科幻小说。 想象一下科技爱好者亚历克斯(Alex)梦见一个聪明的本地AI同伴 - 不依赖
 通过斯坦福大学激动人心的新计划,精神健康的AI专心分析Apr 18, 2025 am 11:49 AM
通过斯坦福大学激动人心的新计划,精神健康的AI专心分析Apr 18, 2025 am 11:49 AM他们的首届AI4MH发射于2025年4月15日举行,著名的精神科医生兼神经科学家汤姆·因斯尔(Tom Insel)博士曾担任开幕式演讲者。 Insel博士因其在心理健康研究和技术方面的杰出工作而闻名
 2025年WNBA选秀课程进入联盟成长并与在线骚扰作斗争Apr 18, 2025 am 11:44 AM
2025年WNBA选秀课程进入联盟成长并与在线骚扰作斗争Apr 18, 2025 am 11:44 AM恩格伯特说:“我们要确保WNBA仍然是每个人,球员,粉丝和公司合作伙伴,感到安全,重视和授权的空间。” anno
 Python内置数据结构的综合指南 - 分析VidhyaApr 18, 2025 am 11:43 AM
Python内置数据结构的综合指南 - 分析VidhyaApr 18, 2025 am 11:43 AM介绍 Python擅长使用编程语言,尤其是在数据科学和生成AI中。 在处理大型数据集时,有效的数据操作(存储,管理和访问)至关重要。 我们以前涵盖了数字和ST
 与替代方案相比,Openai新型号的第一印象Apr 18, 2025 am 11:41 AM
与替代方案相比,Openai新型号的第一印象Apr 18, 2025 am 11:41 AM潜水之前,一个重要的警告:AI性能是非确定性的,并且特定于高度用法。简而言之,您的里程可能会有所不同。不要将此文章(或任何其他)文章作为最后一句话 - 目的是在您自己的情况下测试这些模型
 AI投资组合|如何为AI职业建立投资组合?Apr 18, 2025 am 11:40 AM
AI投资组合|如何为AI职业建立投资组合?Apr 18, 2025 am 11:40 AM建立杰出的AI/ML投资组合:初学者和专业人士指南 创建引人注目的投资组合对于确保在人工智能(AI)和机器学习(ML)中的角色至关重要。 本指南为建立投资组合提供了建议
 代理AI对安全操作可能意味着什么Apr 18, 2025 am 11:36 AM
代理AI对安全操作可能意味着什么Apr 18, 2025 am 11:36 AM结果?倦怠,效率低下以及检测和作用之间的差距扩大。这一切都不应该令任何从事网络安全工作的人感到震惊。 不过,代理AI的承诺已成为一个潜在的转折点。这个新课
 Google与Openai:AI为学生打架Apr 18, 2025 am 11:31 AM
Google与Openai:AI为学生打架Apr 18, 2025 am 11:31 AM直接影响与长期伙伴关系? 两周前,Openai提出了强大的短期优惠,在2025年5月底之前授予美国和加拿大大学生免费访问Chatgpt Plus。此工具包括GPT-4O,A A A A A


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3汉化版
中文版,非常好用

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

Dreamweaver CS6
视觉化网页开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

禅工作室 13.0.1
功能强大的PHP集成开发环境

