




适应大型低秩模型是一种降低复杂性的方法,通过用低维结构近似大型模型的高维结构。其目的是创建一个更小、更易于管理的模型表示,仍能保持良好的性能。在许多任务中,大型模型的高维结构可能存在冗余或不相关的信息。通过识别和删除这些冗余,可以创建一个更高效的模型,同时保持原始性能,并且可以使用更少的资源来训练和部署。
低秩适应是一种能够加速大型模型训练的方法,同时还能够降低内存消耗。它的原理是将预训练模型的权重冻结,并将可训练的秩分解矩阵引入到Transformer架构的每一层中,从而显着减少下游任务的可训练参数数量。这种方法通过将原始矩阵分解为两个秩不同的矩阵的乘积来实现。只需使用低秩矩阵进行计算,就可以减少模型参数数量,提高训练速度,并且在模型质量方面表现出色,而且不会增加推理延迟。
低秩适应示例
以GPT-3模型为例,适应大型低秩模型(LoRA)是一种通过优化密集层中的秩分解矩阵来间接训练神经网络中的一些密集层的方法。 LoRA的优势在于只需对部分参数进行微调,而不是对整个模型进行全参数训练,从而提高了部署时的操作效率。在GPT-3模型中,LoRA只需要对一个秩极低的分解矩阵进行优化,就能够达到与全参数微调相当的性能。这种方法不仅在存储和计算方面非常高效,而且能够有效地减少过拟合问题,提高模型的泛化能力。通过LoRA,大模型可以更加灵活地应用于各种场景,为深度学习的发展带来了更多的可能性。
此外,低秩适应的思想很简单。它通过在原始PLM(预训练语言模型)旁边增加一个旁路来实现,这个旁路执行降维再升维的操作,以模拟所谓的内在维度。在训练过程中,固定PLM的参数,只训练降维矩阵A和升维矩阵B。模型的输入输出维度不变,但在输出时将BA与PLM的参数叠加。降维矩阵A使用随机高斯分布初始化,而升维矩阵B则使用0矩阵初始化,这样可以确保在训练开始时旁路矩阵仍然是0矩阵。
这种思想与残差连接有一些相似之处,它通过使用旁路的更新来模拟full finetuning的过程。事实上,full finetuning可以被看作是LoRA的一个特例,即当r等于k时。这意味着,通过将LoRA应用于所有权重矩阵并训练所有偏置项,同时将LoRA的秩r设置为预训练权重矩阵的秩k,我们大致可以恢复full finetuning的表达能力。换句话说,随着可训练参数数量的增加,LoRA的训练趋向于原始模型的训练,而adapter-based方法则趋向于一个MLP,prefix-based方法则趋向于一个无法处理长输入序列的模型。因此,LoRA提供了一种灵活的方式来平衡可训练参数数量和模型的表达能力。
低秩适应和神经网络压缩有何不同?
低秩适应和神经网络压缩在目标和方法上有一些不同。
神经网络压缩的目标是减少参数和存储空间,降低计算代价和存储需求,同时保持性能。方法包括改变网络结构、量化和近似等。
神经网络压缩可以分为近似、量化和裁剪三类方法。
近似类方法利用矩阵或张量分解,重构少量参数,减少网络存储开销。
2)量化方法的主要思想是将网络参数的可能值从实数域映射到有限数集,或将网络参数用更少的比特数来表示,以减少网络存储开销。
3)裁剪方法会直接改变网络的结构,按粒度可以分为层级裁剪、神经元级裁剪和神经连接级裁剪。
而低秩适应则是指通过降低模型参数的维度,从而减少模型的复杂性,并且通常利用矩阵分解等技术来实现。这种方法通常用于减少模型的计算成本和存储需求,同时保持模型的预测能力。
总的来说,神经网络压缩是一种更广泛的概念,涵盖了多种方法来减少神经网络的参数和存储空间。而低秩适应是一种特定的技术,旨在通过用低维结构近似大型模型来降低其复杂性。
以上是适应大型低秩模型的详细内容。更多信息请关注PHP中文网其他相关文章!

 什么是数据库中的典型化?Apr 12, 2025 am 11:10 AM
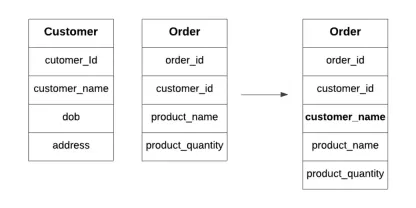
什么是数据库中的典型化?Apr 12, 2025 am 11:10 AM介绍 想象一下,经营一个繁忙的咖啡馆,其中每一秒钟都很重要。您没有不断检查单独的库存和订单列表,而是将所有关键详细信息整合到一个易于阅读的板上。这类似于Denormaliza
 构建用于内容审核的多模式模型Apr 12, 2025 am 10:51 AM
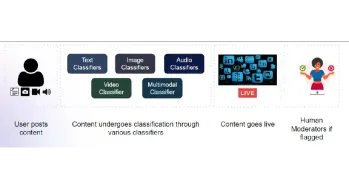
构建用于内容审核的多模式模型Apr 12, 2025 am 10:51 AM介绍 想象一下,当一条进攻性帖子突然出现时,您正在浏览自己喜欢的社交媒体平台。在您点击报告按钮之前,它已经消失了。那是内容主音
 与洞察员自动化数据见解Apr 12, 2025 am 10:44 AM
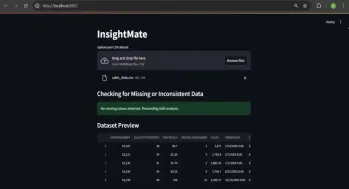
与洞察员自动化数据见解Apr 12, 2025 am 10:44 AM介绍 在当今数据繁多的世界中,处理庞大的数据集可能会令人不知所措。这就是洞察力的来源。它旨在使探索您的数据变得轻而易举。只需上传您的数据集,您就会获得Instan

 什么是补充代理? |入门指南-Analytics VidhyaApr 12, 2025 am 10:40 AM
什么是补充代理? |入门指南-Analytics VidhyaApr 12, 2025 am 10:40 AM介绍 想象一下,开发与对话相同的应用程序。将没有复杂的开发环境可以设置,也无需查看配置文件。将概念转换为有价值的应用程序
 使用Lamini-Analytics Vidhya微调开源LLMApr 12, 2025 am 10:20 AM
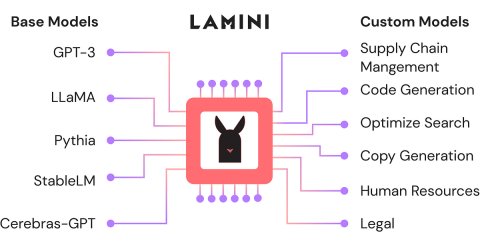
使用Lamini-Analytics Vidhya微调开源LLMApr 12, 2025 am 10:20 AM最近,随着大语言模型和AI的兴起,我们看到了自然语言处理方面的无数进步。文本,代码和图像/视频生成等域中的模型具有存档的人类的推理和P
 Python中使用OpenCV和Roboflow进行性别检测 - 分析VidhyaApr 12, 2025 am 10:19 AM
Python中使用OpenCV和Roboflow进行性别检测 - 分析VidhyaApr 12, 2025 am 10:19 AM介绍 从面部图像中检测性别是计算机视觉的众多迷人应用之一。在这个项目中,我们将OpenCV结合在一起,以解决位置与性别分类的Roboflow API
 生成AI在个性化广告内容中的作用是什么?Apr 12, 2025 am 10:18 AM
生成AI在个性化广告内容中的作用是什么?Apr 12, 2025 am 10:18 AM介绍 自易货系统概念以来,广告世界一直在进化。广告商找到了创造性的方法来引起我们的关注。在当前年龄,消费者期望BR


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

SublimeText3 Linux新版
SublimeText3 Linux最新版

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

