



写在前面&个人理解
近年来,自动驾驶技术中以视觉为中心的3D感知得到了迅猛发展。尽管3D感知模型在结构和概念上相似,但在特征表示、数据格式和目标方面仍存在差距,这对设计统一高效的3D感知框架提出了挑战。因此,研究人员需要努力解决这些差距,以实现更准确、可靠的自动驾驶系统。通过合作和创新,我们有望进一步提升自动驾驶的安全性和性能。
特别是在BEV下的检测任务和Occupancy任务方面,要想实现联合训练并取得良好效果是非常困难的。由于不稳定性和效果难以控制,这给许多应用带来了很大的困扰。然而,UniVision是一个简单高效的框架,它统一了以视觉为中心的3D感知的两个主要任务,即占用预测和目标检测。该框架的核心是一个显式-隐式视图变换模块,用于互补2D-3D特征转换。此外,UniVision还提出了一个局部全局特征提取和融合模块,用于高效和自适应的体素和BEV特征的提取、增强和交互。通过采用这些方法,UniVision能够在BEV下的检测任务和Occupancy任务中取得令人满意的结果。
UniVision提出了一种联合占用检测数据增强策略和渐进式loss weight调整策略,以提高多任务框架训练的效率和稳定性。在四个公共基准上进行了广泛的实验,包括无场景激光雷达分割、无场景检测、OpenOccupancy和Occ3D。实验结果显示,UniVision在每个基准上分别实现了+1.5 mIoU、+1.8 NDS、+1.5 mIoU和+1.8 mIoU的增益,达到了SOTA水平。因此,UniVision框架可以作为统一的以视觉为中心的3D感知任务的高性能基线。
当前3D感知领域的状态
3D感知是自动驾驶系统的首要任务,其目的是利用一系列传感器(如激光雷达、雷达和相机)获得的数据来全面了解驾驶场景,用于后续的规划和决策。过去,由于来自点云数据的精确3D信息,3D感知领域一直由基于激光雷达的模型主导。然而,基于激光雷达的系统成本高昂,容易受到恶劣天气的影响,而且部署起来不方便。相比之下,基于视觉的系统具有许多优点,如低成本、易于部署和良好的可扩展性。因此,以视觉为中心的三维感知引起了研究者的广泛关注。
最近,通过改进特征表示变换、时间融合和监督信号设计等方面,基于视觉的3D检测取得了显著进展,与基于激光雷达的模型的差距不断缩小。此外,基于视觉的占用任务近年来也得到了快速发展。与使用3D box来表示目标不同,占用率可以更全面地描述驾驶场景的几何和语义特征,且不受目标形状和类别的局限。
虽然检测方法和占用方法在结构和概念上有相似之处,但对于同时处理这两个任务并探索它们之间相互关系的研究还不充分。占用模型和检测模型通常提取不同的特征表示。占用预测任务需要进行详尽的语义和几何判断,因此广泛使用体素表示来保存细粒度的3D信息。然而,在检测任务中,BEV表示更为优选,因为大多数对象位于相同的水平水平面上,且有较小的重叠。
与BEV表示相比,体素表示在精细度方面更高,但效率较低。此外,许多高级算子主要针对2D特征进行设计和优化,使其与3D体素表示的集成不那么简单。BEV表示在时间效率和内存效率方面更具优势,但对于密集空间预测来说,它是次优的,因为在高度维度上丢失了结构信息。除了特征表示,不同的感知任务在数据格式和目标方面也有所不同。因此,确保训练多任务3D感知框架的统一性和效率是一项巨大的挑战。
UniVision网络结构

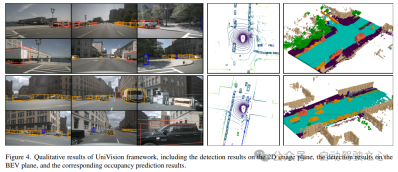
UniVision框架的总体架构如图1所示。该框架接收来自周围N个相机的多视角图像作为输入,并通过图像特征提取网络提取图像特征。接下来,利用Ex-Im视图变换模块将2D图像特征转化为3D体素特征。该模块融合了深度引导的显式特征提升和查询引导的隐式特征采样。 经过视图变换后,体素特征被送入局部全局特征提取和融合块,以分别提取局部上下文感知的体素特征和全局上下文感知的BEV特征。接下来,通过交叉表示特征交互模块,对用于不同下游感知任务的体素特征和BEV特征进行信息交换。 在训练过程中,UniVision框架采用联合Occ-Det数据增强和渐进loss weight调整策略进行有效训练。这些策略可以提高框架的训练效果和泛化能力。 总之,UniVision框架通过多视角图像和3D体素特征的处理,以及特征交互模块的应用,实现了对周围环境的感知任务。同时,通过数据增强和loss weight调整策略的应用,有效提高了框架的训练效果。
1)Ex-Im View Transform
深度导向显式特征提升。这里遵循LSS方法:
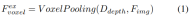
2)查询引导的隐式特征采样。然而,在表示3D信息方面存在一些缺陷。的精度与估计的深度分布的精度高度相关。此外,LSS生成的点分布不均匀。点在相机附近密集,在距离上稀疏。因此,我们进一步使用查询引导的特征采样来补偿的上述缺点。

与从LSS生成的点相比,体素查询在3D空间中均匀分布,并且它们是从所有训练样本的统计特性中学习的,这与LSS中使用的深度先验信息无关。因此,和相互补充,将它们连接起来作为视图变换模块的输出特征:

2)局部全局特征提取与融合
给定输入体素特征,首先将特征叠加在Z轴上,并使用卷积层来减少通道,以获得BEV特征:

然后,模型分成两个平行的分支进行特征提取和增强。局部特征提取+全局特征提取,以及最后的交叉表示特征交互!如图1(b)中所示。
3)损失函数与检测头
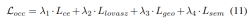
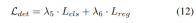

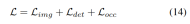
渐进式loss weight调整策略。在实践中,发现直接结合上述损失往往会导致训练过程失败,网络无法收敛。在训练的早期阶段,体素特征Fvoxel是随机分布的,并且占用头和检测头中的监督比收敛中的其他损失贡献更小。同时,检测任务中的分类损失Lcls等损失项目非常大,并且在训练过程中占主导地位,使得模型难以优化。为了克服这一问题,提出了渐进式损失权重调整策略来动态调整损失权重。具体而言,将控制参数δ添加到非图像级损失(即占用损失和检测损失)中,以调整不同训练周期中的损失权重。控制权重δ在开始时被设置为较小的值Vmin,并在N个训练时期中逐渐增加到Vmax:

4)联合Occ-Det空间数据增强
在3D检测任务中,除了常见的图像级数据增强之外,空间级数据增强在提高模型性能方面也是有效的。然而,在占用任务中应用空间级别增强并不简单。当我们将数据扩充(如随机缩放和旋转)应用于离散占用标签时,很难确定生成的体素语义。因此,现有的方法只应用简单的空间扩充,如占用任务中的随机翻转。
为了解决这个问题,UniVision提出了一种联合Occ-Det空间数据增强,以允许在框架中同时增强3D检测任务和占用任务。由于3D box标签是连续值,并且可以直接计算增强的3D box进行训练,因此遵循BEVDet中的增强方法进行检测。尽管占用标签是离散的并且难以操作,但体素特征可以被视为连续的,并且可以通过采样和插值等操作来处理。因此建议对体素特征进行变换,而不是直接对占用标签进行操作以进行数据扩充。
具体来说,首先对空间数据增强进行采样,并计算相应的3D变换矩阵。对于占有标签及其voxel indices ,我们计算了它们的三维坐标。然后,将应用于,并对其进行归一化,以获得增强体素特征中的 voxel indices :

实验结果对比
使用了多个数据集进行验证,NuScenes LiDAR Segmentation、NuScenes 3D Object Detection、OpenOccupancy和Occ3D。
NuScenes LiDAR Segmentation:根据最近的OccFormer和TPVFormer,使用相机图像作为激光雷达分割任务的输入,并且激光雷达数据仅用于提供用于查询输出特征的3D位置。使用mIoU作为评估度量。
NuScenes 3D Object Detection:对于检测任务,使用nuScenes的官方度量,即nuScene检测分数(NDS),它是平均mAP和几个度量的加权和,包括平均平移误差(ATE)、平均尺度误差(ASE)、平均方向误差(AOE)、平均速度误差(AVE)和平均属性误差(AAE)。
OpenOccupancy:OpenOccupancy基准基于nuScenes数据集,提供512×512×40分辨率的语义占用标签。标记的类与激光雷达分割任务中的类相同,使用mIoU作为评估度量!
Occ3D:Occ3D基准基于nuScenes数据集,提供200×200×16分辨率的语义占用标签。Occ3D进一步提供了用于训练和评估的可见mask。标记的类与激光雷达分割任务中的类相同,使用mIoU作为评估度量!
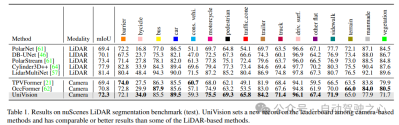
1)Nuscenes激光雷达分割
表1显示了nuScenes LiDAR分割基准的结果。UniVision显著超过了最先进的基于视觉的方法OccFormer 1.5% mIoU,并在排行榜上创下了基于视觉的模型的新纪录。值得注意的是,UniVision还优于一些基于激光雷达的模型,如PolarNe和DB-UNet。
2)NuScenes 3D目标检测任务
如表2所示,当使用相同的训练设置进行公平比较时,UniVision显示出优于其他方法。与512×1408图像分辨率的BEVDepth相比,UniVision在mAP和NDS方面分别获得2.4%和1.1%的增益。当放大模型并将UniVision与时间输入相结合时,它进一步以显著的优势优于基于SOTA的时序检测器。UniVision通过较小的输入分辨率实现了这一点,并且它不使用CBGS。

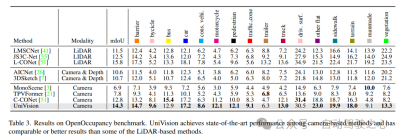
3)OpenOccupancy结果对比
OpenOccupancy基准测试的结果如表3所示。UniVision在mIoU方面分别显著超过了最近的基于视觉的占用方法,包括MonoScene、TPVFormer和C-CONet,分别为7.3%、6.5%和1.5%。此外,UniVision超越了一些基于激光雷达的方法,如LMSCNet和JS3C-Net。
4)Occ3D实验结果
表4列出了Occ3D基准测试的结果。在不同的输入图像分辨率下,UniVision在mIoU方面显著优于最近的基于视觉的方法,分别超过2.7%和1.8%。值得注意的是,BEVFormer和BEVDet-stereo加载预先训练的权重,并在推理中使用时间输入,而UniVision没有使用它们,但仍然实现了更好的性能。

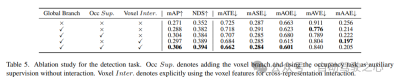
5)组件在检测任务中的有效性
在表5中显示了检测任务的消融研究。当将基于BEV的全局特征提取分支插入基线模型时,性能提高了1.7%mAP和3.0%NDS。当将基于体素的占用任务作为辅助任务添加到检测器时,该模型的mAP增益提高了1.6%。当从体素特征中明确引入交叉表示交互时,该模型实现了最佳性能,与基线相比,mAP和NDS分别提高了3.5%和4.2%;
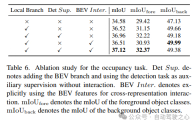
6)占用任务中组件的有效性
在表6中显示了占用任务的消融研究。基于体素的局部特征提取网络为基线模型带来了1.96%mIoU增益的改进。当检测任务被引入作为辅助监督信号时,模型性能提高了0.4%mIoU。
7)其它
表5和表6显示,在UniVision框架中,检测任务和占用任务都是相辅相成的。对于检测任务,占用监督可以提高mAP和mATE度量,这表明体素语义学习有效地提高了检测器对目标几何的感知,即中心度和尺度。对于占用任务,检测监督显著提高了前景类别(即检测类别)的性能,从而实现了整体改进。

在表7中展示了联合Occ-Det空间增强、Ex-Im视图转换模块和渐进loss weight调整策略的有效性。通过所提出的空间增强和所提出的视图变换模块,它在mIoU、mAP和NDS度量上显示了检测任务和占用任务的显著改进。loss weight调整策略能够有效地训练多任务框架。如果没有这一点,统一框架的训练就无法收敛,性能也很低。
原文链接:https://mp.weixin.qq.com/s/8jpS_I-wn1-svR3UlCF7KQ
以上是UniVision引入新一代统一框架:BEV检测与Occupancy双任务达到最先进水平!的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何使用Huggingface Smollm建立个人AI助手Apr 18, 2025 am 11:52 AM
如何使用Huggingface Smollm建立个人AI助手Apr 18, 2025 am 11:52 AM利用“设备” AI的力量:建立个人聊天机器人CLI 在最近的过去,个人AI助手的概念似乎是科幻小说。 想象一下科技爱好者亚历克斯(Alex)梦见一个聪明的本地AI同伴 - 不依赖
 通过斯坦福大学激动人心的新计划,精神健康的AI专心分析Apr 18, 2025 am 11:49 AM
通过斯坦福大学激动人心的新计划,精神健康的AI专心分析Apr 18, 2025 am 11:49 AM他们的首届AI4MH发射于2025年4月15日举行,著名的精神科医生兼神经科学家汤姆·因斯尔(Tom Insel)博士曾担任开幕式演讲者。 Insel博士因其在心理健康研究和技术方面的杰出工作而闻名
 2025年WNBA选秀课程进入联盟成长并与在线骚扰作斗争Apr 18, 2025 am 11:44 AM
2025年WNBA选秀课程进入联盟成长并与在线骚扰作斗争Apr 18, 2025 am 11:44 AM恩格伯特说:“我们要确保WNBA仍然是每个人,球员,粉丝和公司合作伙伴,感到安全,重视和授权的空间。” anno
 Python内置数据结构的综合指南 - 分析VidhyaApr 18, 2025 am 11:43 AM
Python内置数据结构的综合指南 - 分析VidhyaApr 18, 2025 am 11:43 AM介绍 Python擅长使用编程语言,尤其是在数据科学和生成AI中。 在处理大型数据集时,有效的数据操作(存储,管理和访问)至关重要。 我们以前涵盖了数字和ST
 与替代方案相比,Openai新型号的第一印象Apr 18, 2025 am 11:41 AM
与替代方案相比,Openai新型号的第一印象Apr 18, 2025 am 11:41 AM潜水之前,一个重要的警告:AI性能是非确定性的,并且特定于高度用法。简而言之,您的里程可能会有所不同。不要将此文章(或任何其他)文章作为最后一句话 - 目的是在您自己的情况下测试这些模型
 AI投资组合|如何为AI职业建立投资组合?Apr 18, 2025 am 11:40 AM
AI投资组合|如何为AI职业建立投资组合?Apr 18, 2025 am 11:40 AM建立杰出的AI/ML投资组合:初学者和专业人士指南 创建引人注目的投资组合对于确保在人工智能(AI)和机器学习(ML)中的角色至关重要。 本指南为建立投资组合提供了建议
 代理AI对安全操作可能意味着什么Apr 18, 2025 am 11:36 AM
代理AI对安全操作可能意味着什么Apr 18, 2025 am 11:36 AM结果?倦怠,效率低下以及检测和作用之间的差距扩大。这一切都不应该令任何从事网络安全工作的人感到震惊。 不过,代理AI的承诺已成为一个潜在的转折点。这个新课
 Google与Openai:AI为学生打架Apr 18, 2025 am 11:31 AM
Google与Openai:AI为学生打架Apr 18, 2025 am 11:31 AM直接影响与长期伙伴关系? 两周前,Openai提出了强大的短期优惠,在2025年5月底之前授予美国和加拿大大学生免费访问Chatgpt Plus。此工具包括GPT-4O,A A A A A


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

SublimeText3汉化版
中文版,非常好用

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

