


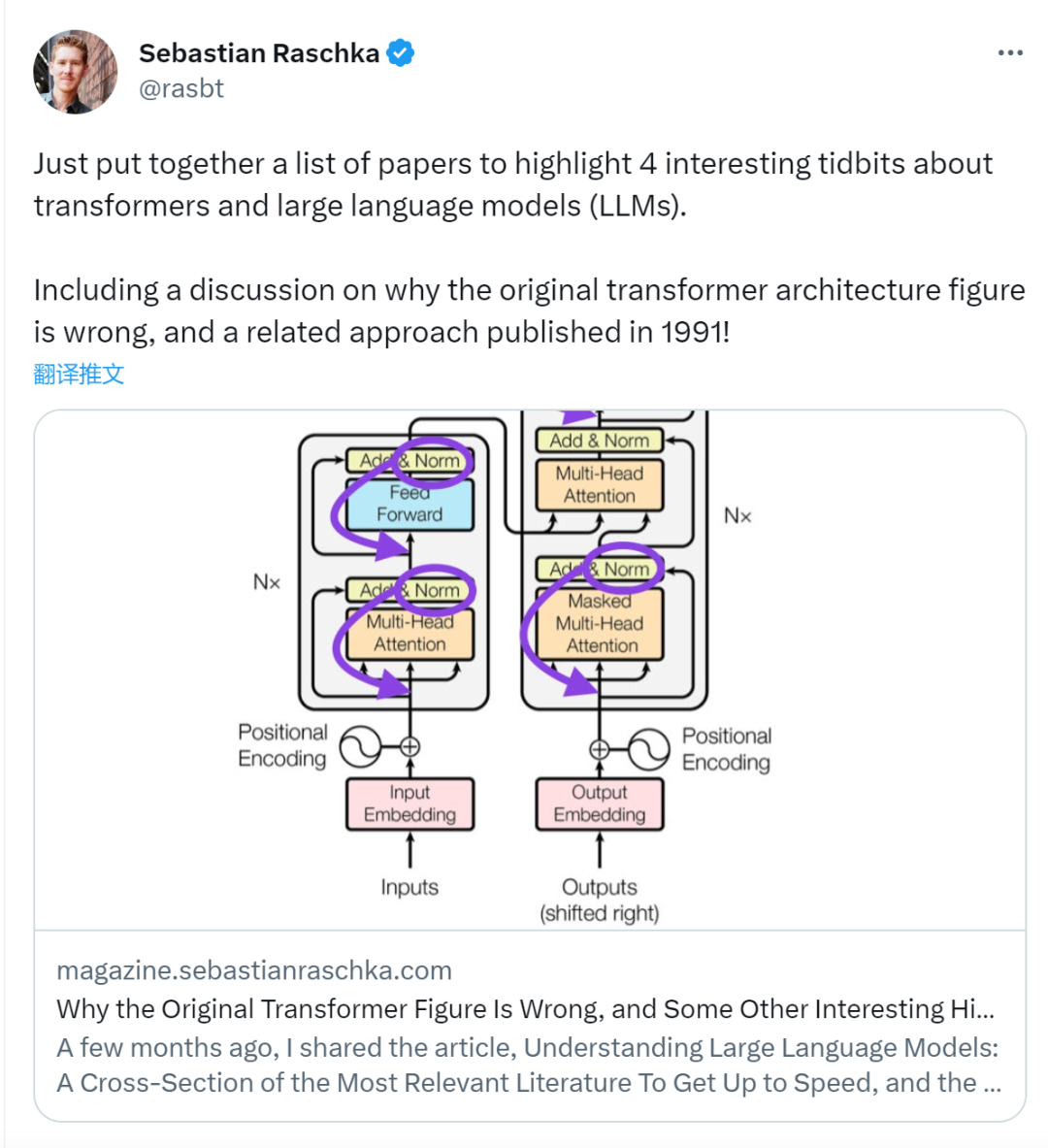
前段时间,一条指出谷歌大脑团队论文《Attention Is All You Need》中 Transformer 构架图与代码不一致的推文引发了大量的讨论。
对于 Sebastian 的这一发现,有人认为属于无心之过,但同时也会令人感到奇怪。毕竟,考虑到 Transformer 论文的流行程度,这个不一致问题早就应该被提及 1000 次。
Sebastian Raschka 在回答网友评论时说,「最最原始」的代码确实与架构图一致,但 2017 年提交的代码版本进行了修改,但同时没有更新架构图。这也是造成「不一致」讨论的根本原因。
随后,Sebastian 在 Ahead of AI 发布文章专门讲述了为什么最初的 Transformer 构架图与代码不一致,并引用了多篇论文简要说明了 Transformer 的发展变化。
以下为文章原文,让我们一起看看文章到底讲述了什么:
几个月前,我分享了《Understanding Large Language Models: A Cross-Section of the Most Relevant Literature To Get Up to Speed》,积极的反馈非常鼓舞人心!因此,我添加了一些论文,以保持列表的新鲜感和相关性。
同时,保持列表简明扼要是至关重要的,这样大家就可以用合理的时间就跟上进度。还有一些论文,信息量很大,想来也应该包括在内。
我想分享四篇有用的论文,从历史的角度来理解 Transformer。虽然我只是直接将它们添加到理解大型语言模型的文章中,但我也在这篇文章中单独来分享它们,以便那些之前已经阅读过理解大型语言模型的人更容易找到它们。
On Layer Normalization in the Transformer Architecture (2020)
虽然下图(左)的 Transformer 原始图(https://arxiv.org/abs/1706.03762)是对原始编码器 - 解码器架构的有用总结,但该图有一个小小的差异。例如,它在残差块之间进行了层归一化,这与原始 Transformer 论文附带的官方 (更新后的) 代码实现不匹配。下图(中)所示的变体被称为 Post-LN Transformer。
Transformer 架构论文中的层归一化表明,Pre-LN 工作得更好,可以解决梯度问题,如下所示。许多体系架构在实践中采用了这种方法,但它可能导致表征的崩溃。
因此,虽然仍然有关于使用 Post-LN 或前 Pre-LN 的讨论,也有一篇新论文提出了将两个一起应用:《 ResiDual: Transformer with Dual Residual Connections》(https://arxiv.org/abs/2304.14802),但它在实践中是否有用还有待观察。
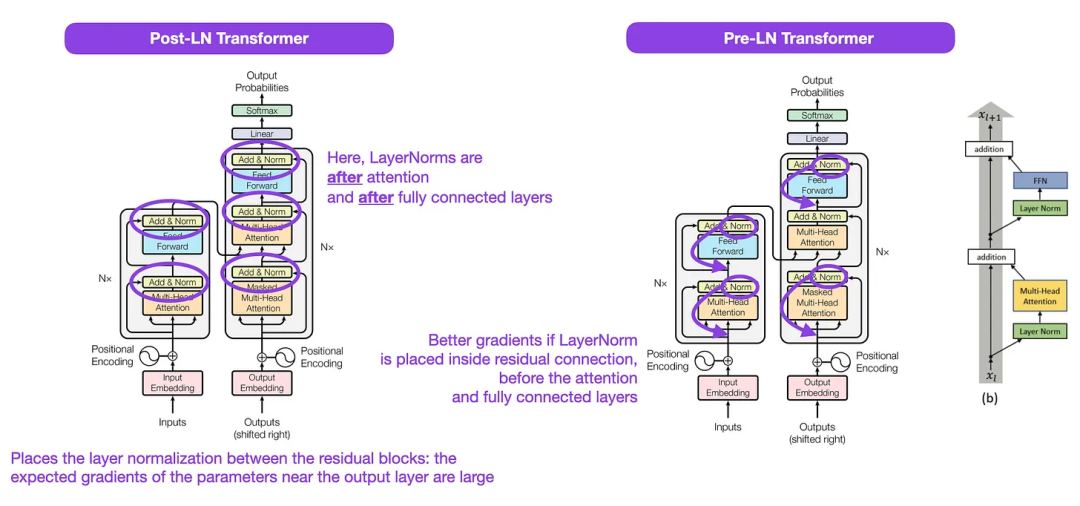
图注:图源 https://arxiv.org/abs/1706.03762 (左 & 中) and https://arxiv.org/abs/2002.04745 (右)
Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks (1991)
这篇文章推荐给那些对历史花絮和早期方法感兴趣的人,这些方法基本上类似于现代 Transformer。
例如,在比 Transformer 论文早 25 年的 1991 年,Juergen Schmidhuber 提出了一种递归神经网络的替代方案(https://www.semanticscholar.org/paper/Learning-to-Control-Fast-Weight-Memories%3A-An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922),称为 Fast Weight Programmers (FWP)。实现快速权值变化的另一个神经网络是通过使用梯度下降算法缓慢学习的 FWP 方法中所涉及的前馈神经网络。
这篇博客 (https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2) 将其与现代 Transformer 进行类比,如下所示:
在今天的 Transformer 术语中,FROM 和 TO 分别称为键 (key) 和值 (value)。应用快速网络的输入称为查询。本质上,查询由快速权重矩阵 (fast weight matrix) 处理,它是键和值的外积之和 (忽略归一化和投影)。我们可以使用加法外积或二阶张量积来实现端到端可微的主动控制权值快速变化,因为两个网络的所有操作都支持微分。在序列处理期间,梯度下降可以用于快速调整快速网络,从而应对慢速网络的问题。这在数学上等同于 (除了归一化之外) 后来被称为具有线性化自注意的 Transformer (或线性 Transformer)。
正如上文摘录所提到的,这种方法现在被称为线性 Transformer 或具有线性化自注意的 Transformer。它们来自于 2020 年出现在 arXiv 上的论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention 》(https://arxiv.org/abs/2006.16236)以及《Rethinking Attention with Performers》(https://arxiv.org/abs/2009.14794)。
2021 年,论文《Linear Transformers Are Secretly Fast Weight Programmers》(https://arxiv.org/abs/2102.11174)明确表明了线性化自注意力和 20 世纪 90 年代的快速权重编程器之间的等价性。
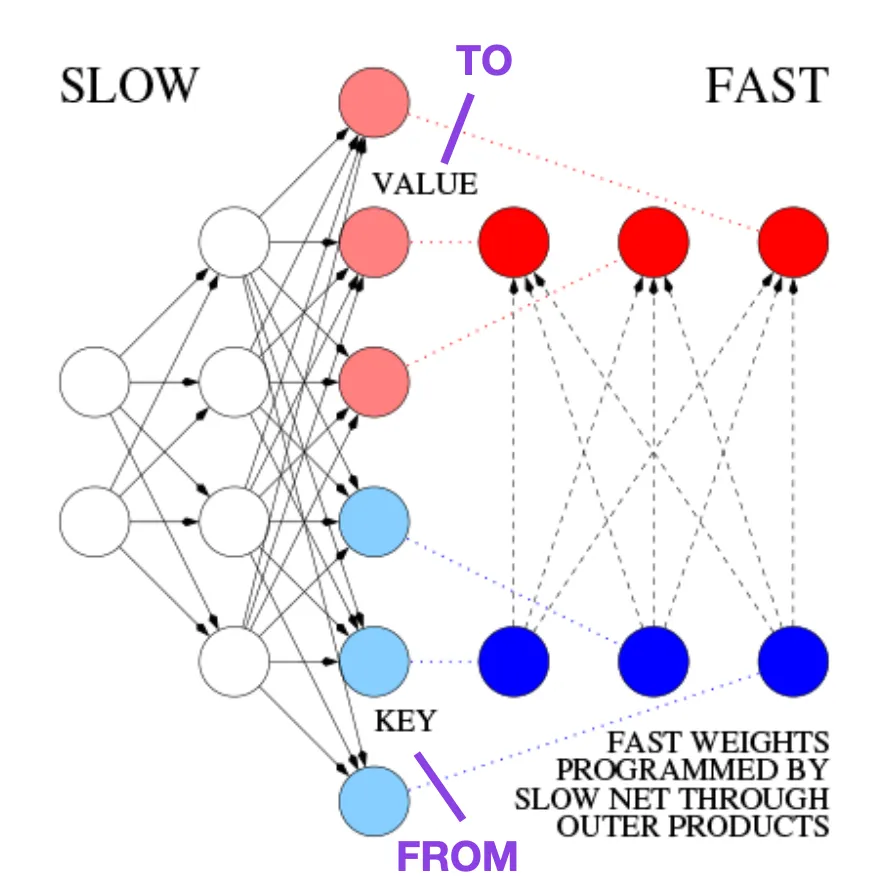
图源:https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2
Universal Language Model Fine-tuning for Text Classification (2018)
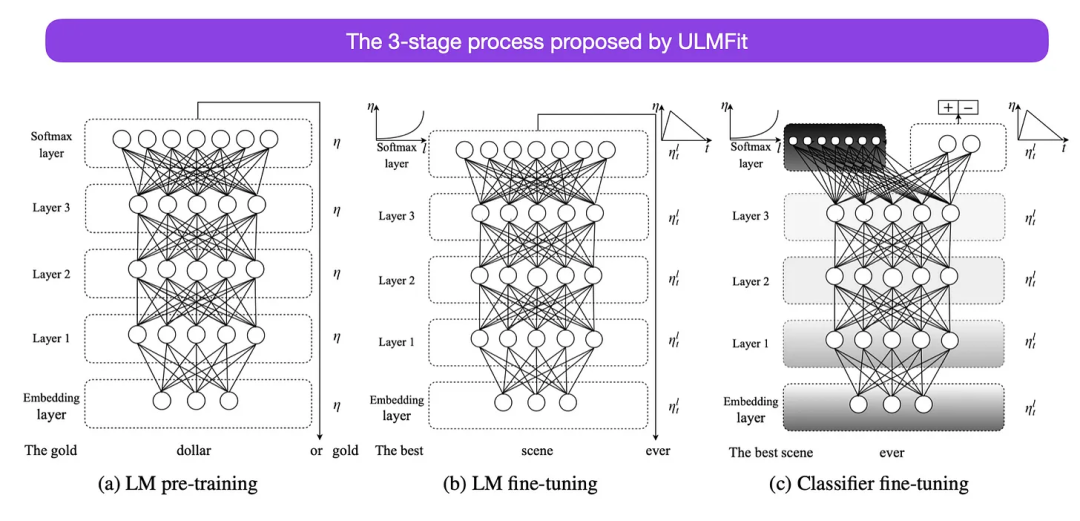
这是另一篇从历史角度来看非常有趣的论文。它是在原版《Attention Is All You Need》发布一年后写的,并没有涉及 transformer,而是专注于循环神经网络,但它仍然值得关注。因为它有效地提出了预训练语言模型和迁移学习的下游任务。虽然迁移学习已经在计算机视觉中确立,但在自然语言处理 (NLP) 领域还没有普及。ULMFit(https://arxiv.org/abs/1801.06146)是首批表明预训练语言模型在特定任务上对其进行微调后,可以在许多 NLP 任务中产生 SOTA 结果的论文之一。
ULMFit 建议的语言模型微调过程分为三个阶段:
- 1. 在大量的文本语料库上训练语言模型;
- 2. 根据任务特定的数据对预训练的语言模型进行微调,使其能够适应文本的特定风格和词汇;
- 3. 微调特定任务数据上的分类器,通过逐步解冻各层来避免灾难性遗忘。
在大型语料库上训练语言模型,然后在下游任务上对其进行微调的这种方法,是基于 Transformer 的模型和基础模型 (如 BERT、GPT-2/3/4、RoBERTa 等) 使用的核心方法。
然而,作为 ULMFiT 的关键部分,逐步解冻通常在实践中不进行,因为 Transformer 架构通常一次性对所有层进行微调。
Gopher 是一篇特别好的论文(https://arxiv.org/abs/2112.11446),包括大量的分析来理解 LLM 训练。研究人员在 3000 亿个 token 上训练了一个 80 层的 2800 亿参数模型。其中包括一些有趣的架构修改,比如使用 RMSNorm (均方根归一化) 而不是 LayerNorm (层归一化)。LayerNorm 和 RMSNorm 都优于 BatchNorm,因为它们不局限于批处理大小,也不需要同步,这在批大小较小的分布式设置中是一个优势。RMSNorm 通常被认为在更深的体系架构中会稳定训练。
除了上面这些有趣的花絮之外,本文的主要重点是分析不同规模下的任务性能分析。对 152 个不同任务的评估显示,增加模型大小对理解、事实核查和识别有毒语言等任务最有利,而架构扩展对与逻辑和数学推理相关的任务从益处不大。
图注:图源 https://arxiv.org/abs/2112.11446
以上是此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何使用Huggingface Smollm建立个人AI助手Apr 18, 2025 am 11:52 AM
如何使用Huggingface Smollm建立个人AI助手Apr 18, 2025 am 11:52 AM利用“设备” AI的力量:建立个人聊天机器人CLI 在最近的过去,个人AI助手的概念似乎是科幻小说。 想象一下科技爱好者亚历克斯(Alex)梦见一个聪明的本地AI同伴 - 不依赖
 通过斯坦福大学激动人心的新计划,精神健康的AI专心分析Apr 18, 2025 am 11:49 AM
通过斯坦福大学激动人心的新计划,精神健康的AI专心分析Apr 18, 2025 am 11:49 AM他们的首届AI4MH发射于2025年4月15日举行,著名的精神科医生兼神经科学家汤姆·因斯尔(Tom Insel)博士曾担任开幕式演讲者。 Insel博士因其在心理健康研究和技术方面的杰出工作而闻名
 2025年WNBA选秀课程进入联盟成长并与在线骚扰作斗争Apr 18, 2025 am 11:44 AM
2025年WNBA选秀课程进入联盟成长并与在线骚扰作斗争Apr 18, 2025 am 11:44 AM恩格伯特说:“我们要确保WNBA仍然是每个人,球员,粉丝和公司合作伙伴,感到安全,重视和授权的空间。” anno
 Python内置数据结构的综合指南 - 分析VidhyaApr 18, 2025 am 11:43 AM
Python内置数据结构的综合指南 - 分析VidhyaApr 18, 2025 am 11:43 AM介绍 Python擅长使用编程语言,尤其是在数据科学和生成AI中。 在处理大型数据集时,有效的数据操作(存储,管理和访问)至关重要。 我们以前涵盖了数字和ST
 与替代方案相比,Openai新型号的第一印象Apr 18, 2025 am 11:41 AM
与替代方案相比,Openai新型号的第一印象Apr 18, 2025 am 11:41 AM潜水之前,一个重要的警告:AI性能是非确定性的,并且特定于高度用法。简而言之,您的里程可能会有所不同。不要将此文章(或任何其他)文章作为最后一句话 - 目的是在您自己的情况下测试这些模型
 AI投资组合|如何为AI职业建立投资组合?Apr 18, 2025 am 11:40 AM
AI投资组合|如何为AI职业建立投资组合?Apr 18, 2025 am 11:40 AM建立杰出的AI/ML投资组合:初学者和专业人士指南 创建引人注目的投资组合对于确保在人工智能(AI)和机器学习(ML)中的角色至关重要。 本指南为建立投资组合提供了建议
 代理AI对安全操作可能意味着什么Apr 18, 2025 am 11:36 AM
代理AI对安全操作可能意味着什么Apr 18, 2025 am 11:36 AM结果?倦怠,效率低下以及检测和作用之间的差距扩大。这一切都不应该令任何从事网络安全工作的人感到震惊。 不过,代理AI的承诺已成为一个潜在的转折点。这个新课
 Google与Openai:AI为学生打架Apr 18, 2025 am 11:31 AM
Google与Openai:AI为学生打架Apr 18, 2025 am 11:31 AM直接影响与长期伙伴关系? 两周前,Openai提出了强大的短期优惠,在2025年5月底之前授予美国和加拿大大学生免费访问Chatgpt Plus。此工具包括GPT-4O,A A A A A


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver Mac版
视觉化网页开发工具

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

WebStorm Mac版
好用的JavaScript开发工具

