


目录:
- Multiscale Positive-Unlabeled Detection of AI-Generated Texts
- Towards Revealing the Mystery behind Chain of Thought: a Theoretical Perspective
- Large Language Models as Tool Makers
- SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification
- Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
- mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video
- Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited
论文 1:Multiscale Positive-Unlabeled Detection of AI-Generated Texts
- 作者:Yuchuan Tian, Hanting Chen 等
- 论文地址:https://arxiv.org/abs/2305.18149
摘要:AI 造假的成功率很高,前几天「10 分钟骗 430 万」还上了热搜。在最热门的大语言模型上,北大、华为的研究者们最近探索了一种识别方法。如下列举了几个人和 AI 分别对同一问题做出回答的例子:

推荐:识别「ChatGPT 造假」,效果超越 OpenAI:北大、华为的 AI 生成检测器来了
论文 2:Towards Revealing the Mystery behind Chain of Thought: a Theoretical Perspective
- 作者:Guhao Feng、Bohang Zhang 等
- 论文地址:https://arxiv.org/abs/2305.15408
摘要:思维链提示(CoT)是大模型涌现中最神秘的现象之一,尤其在解决数学推理和决策问题中取得了惊艳效果。CoT 到底有多重要呢?它背后成功的机制是什么?本文中,北大的几位研究者证明了 CoT 在实现大语言模型(LLM)推理中是不可或缺的,并从理论和实验角度揭示了 CoT 如何释放 LLM 的巨大潜力。
本文选取了两个非常基础但核心的数学任务:算术和方程(下图给出了这两个任务的输入输出示例)

推荐:思维链如何释放语言模型的隐藏能力?最新理论研究揭示其背后奥秘
论文 3:Large Language Models as Tool Makers
- 作者:Tianle Cai、 Xuezhi Wang 等
- 论文地址:https://arxiv.org/pdf/2305.17126.pdf
摘要:受到制造工具对人类重要性的启发,在本文中,Google Deepmind、普林斯顿和斯坦福大学的研究者将这种「进化」的概念应用于 LLM 领域,进行了初步探索。他们提出了一个闭环框架,在这个框架中 LLM 作为工具制作者(LLMs As Tool Makers ,LATM),使其能够生成自己的可重新使用的工具来处理新任务。

推荐:GPT-4 等大模型迎来进化转折点:不只是使用,还会自己制作工具了
论文 4:SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification
- 作者:Xupeng Miao、Gabriele Oliaro 等
- 论文地址:https://arxiv.org/abs/2305.09781
摘要:近日,来自卡耐基梅隆大学(CMU)的 Catalyst Group 团队发布了一款「投机式推理」引擎 SpecInfer,可以借助轻量化的小模型来帮助大模型,在完全不影响生成内容准确度的情况下,实现两到三倍的推理加速。
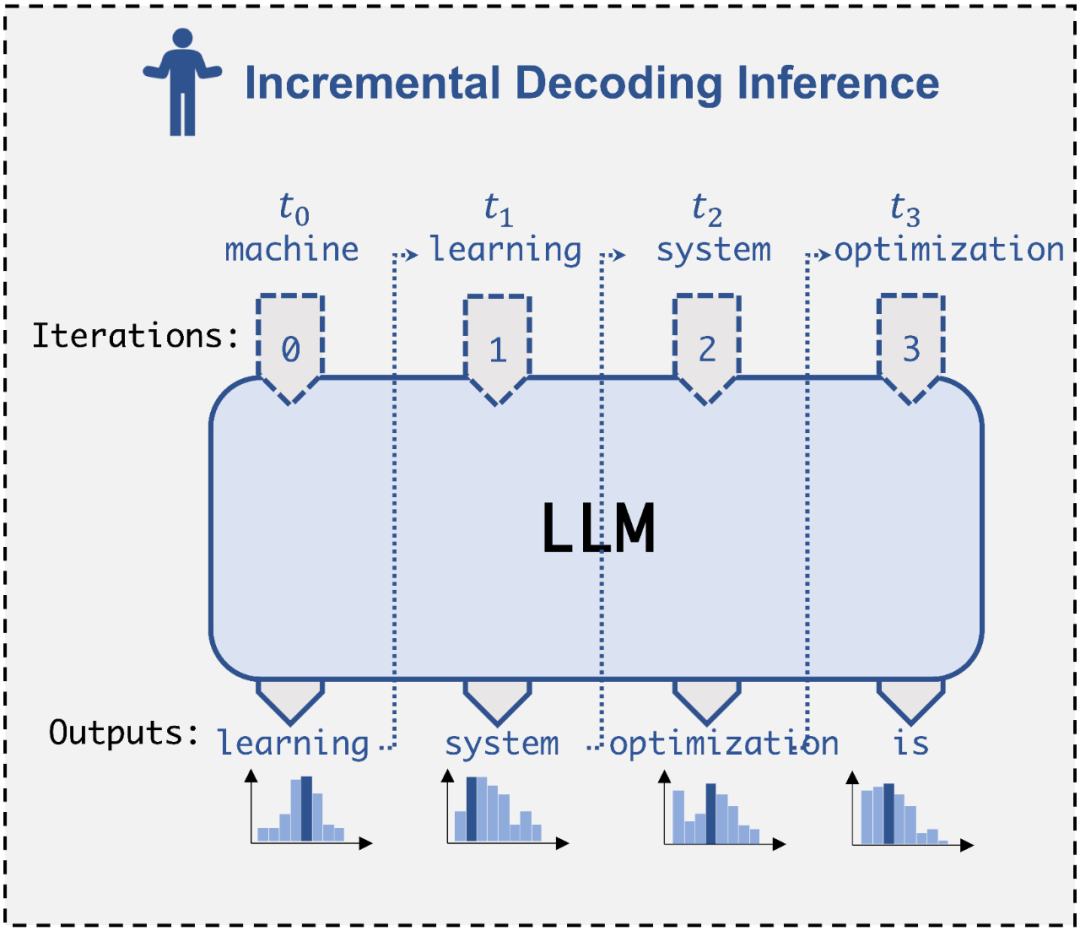
推荐:LLM 推理提速 2.8 倍,CMU 清华姚班校友提出「投机式推理」引擎 SpecInfer,小模型撬动大模型高效推理
论文 5:Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models
- 作者:Gen Luo、 Yiyi Zhou 等
- 论文地址:https://arxiv.org/pdf/2305.15023.pdf
摘要:本文提出了一种新颖且经济实惠的解决方案,用于有效地将 LLMs 适应到 VL(视觉语言)任务中,称为 MMA。MMA 不使用大型神经网络来连接图像编码器和 LLM,而是采用轻量级模块,即适配器,来弥合 LLMs 和 VL 任务之间的差距,同时也实现了图像模型和语言模型的联合优化。同时,MMA 还配备了一种路由算法,可以帮助 LLM 在不损害其自然语言理解能力的情况下,在单模态和多模态指令之间实现自动切换。
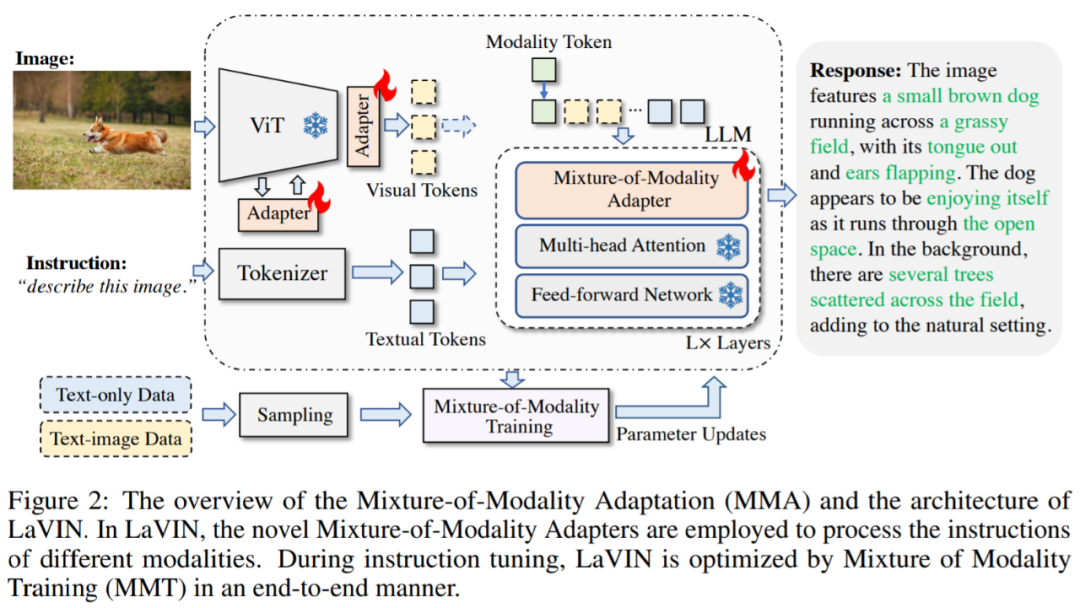
推荐:训练时间减少 71.4%,存储成本节省 99.9%,厦大指令调优新方案 MMA 让羊驼模型实现多模态
论文 6:mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video
- 作者:Haiyang Xu、 Qinghao Ye 等
- 论文地址:https://arxiv.org/pdf/2302.00402.pdf
摘要:对于多模态基础模型,我们希望其不仅可以处理特定的多模态相关任务,还希望其处理单模态任务时也具有优异的性能。阿⾥达摩院团队发现现有的模型往往不能很好的平衡模态协作和模态纠缠的问题,这限制了模型在各种单模态和跨模态下游任务的性能。
基于此,达摩院的研究者提出了 mPLUG-2,其通过模块化的⽹络结构设计来平衡多模态之间的协作和纠缠问题,mPLUG-2 在 30 + 多 / 单模态任务,取得同等数据量和模型规模 SOTA 或者 Comparable 效果,在 VideoQA 和 VideoCaption 上超越 Flamingo、VideoCoca、GITv2 等超⼤模型取得绝对 SOTA。此外,mPLUG-Owl 是阿⾥巴巴达摩院 mPLUG 系列的最新工作,延续了 mPLUG 系列的模块化训练思想,把 LLM 升级为⼀个多模态⼤模型。mPLUG-2 的研究论文已被 ICML 2023 接收。
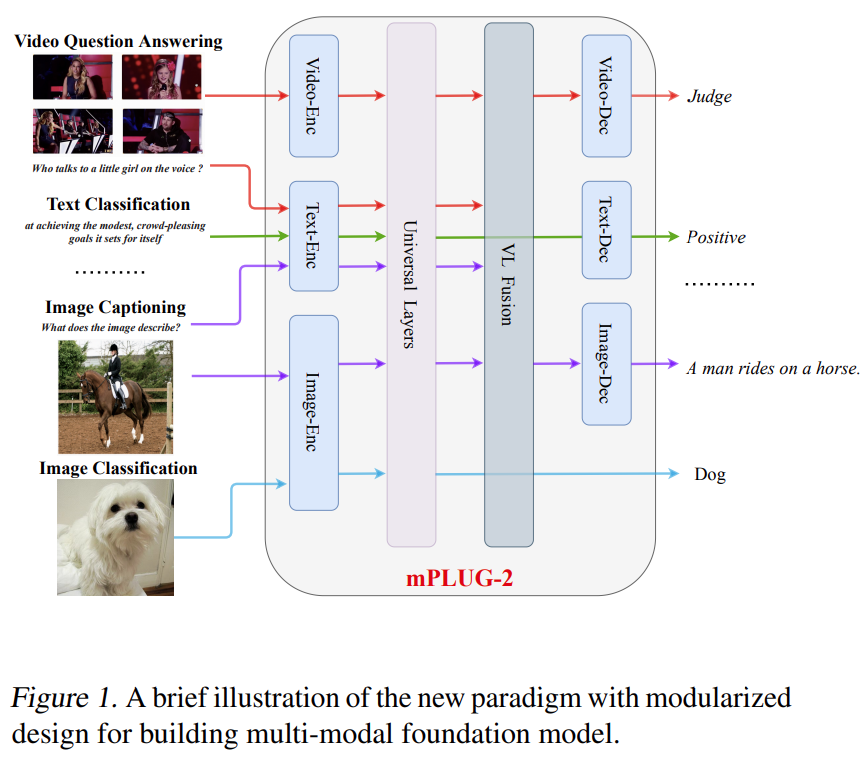
推荐:ICML 2023 | 基于模块化思想,阿里达摩院提出多模态基础模型 mPLUG-2
论文 7:Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited
- 作者:Zheng Yuan、Fajie Yuan 等
- 论文地址:https://arxiv.org/abs/2303.13835
摘要:本文调查了一个富有潜力的问题,即多模态推荐系统 MoRec 是否有望终结 IDRec 在推荐系统领域长达 10 年的主导地位,基于此,论文进行了深入研究。相关成果已被 SIGIR 2023 接收。下图为网络架构。
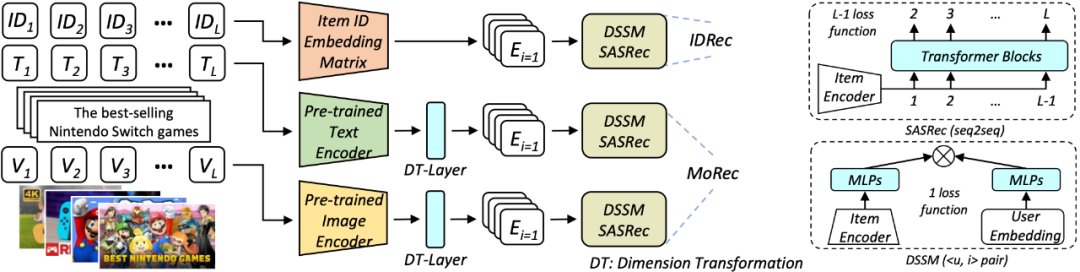
推荐:SIGIR 2023 | 推荐系统何去何从,经典 ID 范式要被颠覆?
以上是GPT-4等大模型自己制作工具,识别ChatGPT造假的详细内容。更多信息请关注PHP中文网其他相关文章!

 大多数使用的10个功率BI图 - 分析VidhyaApr 16, 2025 pm 12:05 PM
大多数使用的10个功率BI图 - 分析VidhyaApr 16, 2025 pm 12:05 PM用Microsoft Power BI图来利用数据可视化的功能 在当今数据驱动的世界中,有效地将复杂信息传达给非技术观众至关重要。 数据可视化桥接此差距,转换原始数据i
 AI的专家系统Apr 16, 2025 pm 12:00 PM
AI的专家系统Apr 16, 2025 pm 12:00 PM专家系统:深入研究AI的决策能力 想象一下,从医疗诊断到财务计划,都可以访问任何事情的专家建议。 这就是人工智能专家系统的力量。 这些系统模仿Pro
 三个最好的氛围编码器分解了这项代码中的AI革命Apr 16, 2025 am 11:58 AM
三个最好的氛围编码器分解了这项代码中的AI革命Apr 16, 2025 am 11:58 AM首先,很明显,这种情况正在迅速发生。各种公司都在谈论AI目前撰写的代码的比例,并且这些代码的比例正在迅速地增加。已经有很多工作流离失所
 跑道AI的Gen-4:AI蒙太奇如何超越荒谬Apr 16, 2025 am 11:45 AM
跑道AI的Gen-4:AI蒙太奇如何超越荒谬Apr 16, 2025 am 11:45 AM从数字营销到社交媒体的所有创意领域,电影业都站在技术十字路口。随着人工智能开始重塑视觉讲故事的各个方面并改变娱乐的景观
 如何注册5天ISRO AI免费课程? - 分析VidhyaApr 16, 2025 am 11:43 AM
如何注册5天ISRO AI免费课程? - 分析VidhyaApr 16, 2025 am 11:43 AMISRO的免费AI/ML在线课程:通向地理空间技术创新的门户 印度太空研究组织(ISRO)通过其印度遥感研究所(IIR)为学生和专业人士提供了绝佳的机会
 AI中的本地搜索算法Apr 16, 2025 am 11:40 AM
AI中的本地搜索算法Apr 16, 2025 am 11:40 AM本地搜索算法:综合指南 规划大规模活动需要有效的工作量分布。 当传统方法失败时,本地搜索算法提供了强大的解决方案。 本文探讨了爬山和模拟
 OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑Apr 16, 2025 am 11:37 AM
OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑Apr 16, 2025 am 11:37 AM该版本包括三种不同的型号,GPT-4.1,GPT-4.1 MINI和GPT-4.1 NANO,标志着向大语言模型景观内的特定任务优化迈进。这些模型并未立即替换诸如
 提示:chatgpt生成假护照Apr 16, 2025 am 11:35 AM
提示:chatgpt生成假护照Apr 16, 2025 am 11:35 AMChip Giant Nvidia周一表示,它将开始制造AI超级计算机(可以处理大量数据并运行复杂算法的机器),完全是在美国首次在美国境内。这一消息是在特朗普总统SI之后发布的


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

SublimeText3 Linux新版
SublimeText3 Linux最新版

Atom编辑器mac版下载
最流行的的开源编辑器

SublimeText3汉化版
中文版,非常好用

