



导读
如何基于向量数据库+LLM(大语言模型),打造更懂你的企业专属Chatbot?
1、为什么Chatbot需要大语言模型+向量数据库?
这个春天,最让人震感的科技产品莫过于ChatGPT的横空出世,通过大语言模型(LLM)让人们看到了生成式AI能实现到和人类语言高度相仿的语言表达能力,AI不再遥不可及而已经可以走进人类的工作和生活,这使得沉寂一段时间的AI领域重新焕发了能量,无数的从业者正趋之若鹜地投身于下一个改变时代的机会;据不完全统计,在短短的4个月时间内,美国已经完成了超4000笔的生成式AI的行业融资。下一代技术中,生成式AI已成为资本和企业不容忽视的一部分,越来越需要更高水平的基础设施能力来支持其发展。
大模型能够回答较为普世的问题,但是若要服务于垂直专业领域,会存在知识深度和时效性不足的问题,那么企业如何抓住机会并构建垂直领域服务?目前有两种模式,第一种是基于大模型之上做垂直领域模型的Fine Tune,这个综合投入成本较大,更新的频率也较低,并不适用于所有的企业;第二种就是在向量数据库中构建企业自有的知识资产,通过大模型 + 向量数据库来搭建垂直领域的深度服务,本质是使用数据库进行提示工程(Prompt Engineering)。企业可以借助垂直类别的法律条文和先例,在法律行业等特定领域构建法律科技服务。如法律科技公司Harvey,正在构建“律师的副驾驶”(Copilot for Lawyer)以提高法律条文的起草和研究服务。将企业知识库文档和实时信息通过向量特征提取然后存储到向量数据库,结合LLM大语言模型可以让Chatbot(问答机器人)的回答更具专业性和时效性,构建企业专属Chatbot。
如何基于大语言模型让Chatbot更好地回答时事问题?欢迎移步“阿里云瑶池数据库”视频号观看演示Demo。
本文接下来将重点介绍基于大语言模型(LLM)+向量数据库打造企业专属Chatbot的原理和流程,以及ADB-PG构建该场景的核心能力。
2、什么是向量数据库?
现实世界中,大部分数据呈非结构化形式,如图像、音频、视频和文本。随着智慧城市、短视频、个性化商品推荐、视觉商品搜索等应用的出现,这些非结构化的数据呈现爆发式增长。为了能够处理这些非结构化的数据,我们通常会使用人工智能技术提取这些非结构化数据的特征,并将其转化为特征向量,再对这些特征向量进行分析和检索以实现对非结构化数据的处理。因此,我们称可以存储、分析和检索特征向量的数据库为向量数据库。
向量数据库对于特征向量的快速检索,一般会采用构建向量索引的技术手段,我们通常说的向量索引都属于ANNS(Approximate Nearest Neighbors Search,近似最近邻搜索),它的核心思想是不再局限于只返回最精确的结果项,而是仅搜索可能是近邻的数据项,也就是通过牺牲可接受范围内的一点精确度来换取检索效率的提高。这也是向量数据库与传统数据库最大的差别。
目前在实际生产环境中,业界有两种主要实践方式,以更方便地应用ANNS向量索引。一种是单独将ANNS向量索引服务化,以提供向量索引创建和检索的能力,从而形成一种专有的向量数据库;另一种是将ANNS向量索引融合到传统结构化数据库中,形成一种具有向量检索功能的DBMS。在实际的业务场景中,专有的向量数据库往往都需要和其他传统数据库配合起来一起使用,这样会造成一些比较常见的问题,如数据冗余、数据迁移过多、数据一致性问题等,与真正的DBMS相比,专有的向量数据库需要额外的专业人员维护、额外的成本,以及非常有限的查询语言能力、可编程性、可扩展性和工具集成。
而融合了向量检索功能的DBMS则不同,它首先是一个非常完备的现代数据库平台,能满足应用程序开发人员的数据库功能需求;然后它集成的向量检索能力一样也可以实现专有的向量数据库的功能,并且使向量存储和检索继承了DBMS的优秀能力,如易用性(直接使用SQL的方式处理向量)、事务、高可用性、高可扩展性等等。
本文介绍的ADB-PG即是具有向量检索功能的DBMS,在包含向量检索功能的同时,还具备一站式的数据库能力。在介绍ADB-PG的具体能力之前,我们先来看一下Demo视频中Chatbot的创建流程和相关原理。
3、LLM大语言模型+ADB-PG:打造企业专属Chatbot
案例-本地知识问答系统
对于前面Demo视频结合大语言模型LLM和ADB-PG进行时事新闻点评解答的例子,让LLM回答“通义千问是什么”。可以看到,如果我们让LLM直接回答,得到的答案没有意义,因为LLM的训练数据集里并不包含相关的内容。而当我们使用向量数据库作为本地知识存储,让LLM自动提取相关的知识之后,其正确地回答了“通义千问是什么”。
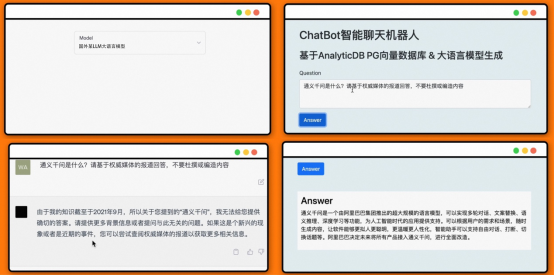
回答“通义千问是什么”
这种处理方式可以同样适用于处理未被LLM训练数据集涵盖的文档、PDF、电子邮件、网络信息等内容。比如:
- 结合最新的航班信息和最新的网红打卡地点等旅游攻略资源,打造旅游助手。比如回答下周最适合去哪里旅游,如何最经济实惠的问题。
- 体育赛事点评,时事热点新闻点评,总结。今天谁是NBA比赛的MVP。
- 教育行业,最新的教育热点解读,比如,告诉我什么是AIGC,什么是Stable Diffusion以及如何使用等等。
- 金融领域,快速分析各行业领域金融财报,打造金融咨询助手。
- 专业领域的客服机器人...
实现原理
本地知识问答系统(Local QA System)主要是通过结合了大语言模型的推理能力和向量数据库的存储和检索能力。通过向量检索获取最相关的语义片段,以此为基础让大语言模型结合相关片段上下文进行推理,从而得出正确的结论。在这个过程中主要有两个流程:
a. 后端数据处理和存储流程
b. 前端问答流程
同时其底层主要依赖两个模块:
1. 基于大语言模型的推理模块
2. 基于向量数据库的向量数据管理模块
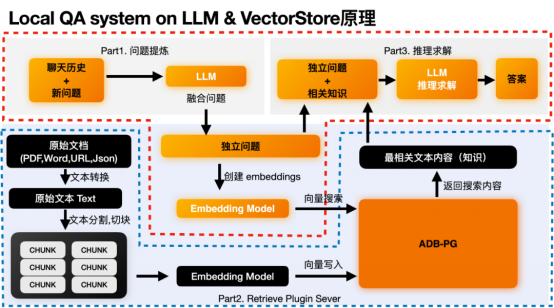
Local QA system on LLM & VectorStore原理
后端数据处理和存储流程
上图黑色的部分为后端的数据处理流程,主要是将我们的原始数据求解embedding,并和原始数据一起存入到向量数据库ADB-PG中。这里你只需要关注上图的蓝色虚线框部分。黑色的处理模块和ADB-PG向量数据库。
- Step1:先将原始文档中的文本内容全部提取出来。然后根据语义切块,切成多个chunk,可以理解为可以完整表达一段意思的文本段落。在这个过程中还可以额外做一些元数据抽取,敏感信息检测等行为。
- Step2:将这些Chunk都丢给embedding模型,来求取这些chunk的embedding。
- Step3:将embedding和原始chunk一起存入到向量数据库中。
前端问答流程
在这个过程中主要分为三个部分:1.问题提炼部分;2.向量检索提取最相关知识;3.推理求解部分。在这里我们需要关注橙色部分。单单说原理可能比较晦涩,我们还是用上面的例子来说明。
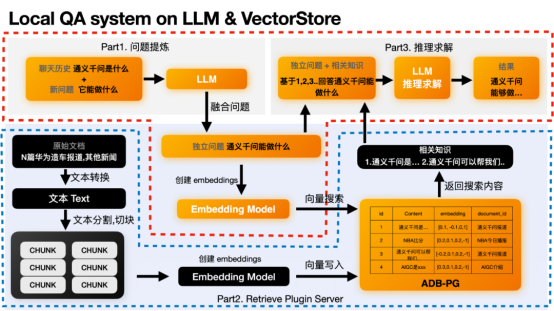
Local QA system on LLM & VectorStore
Part1 问题提炼
这个部分是可选的,之所以存在是因为有些问题是需要依赖于上下文的。因为用户问的新问题可能没办法让LLM理解这个用户的意图。
比如用户的新问题是“它能做什么”。LLM并不知道它指的是谁,需要结合之前的聊天历史,比如“通义千问是什么”来推理出用户需要求解答案的独立问题“通义千问能做什么”。LLM没法正确回答“它有什么用”这样的模糊问题,但是能正确回答“通义千问有什么用”这样的独立问题。如果你的问题本身就是独立的,则不需要这个部分。
得到独立问题后,我们可以基于这个独立问题,来求取这个独立问题的embedding。然后去向量数据库中搜索最相似的向量,找到最相关的内容。这个行为在Part2 Retrieval Plugin的功能中。
Part2 向量检索
独立问题求取embedding这个功能会在text2vec模型中进行。在获得embedding之后就可以通过这个embedding来搜索已经事先存储在向量数据库中的数据了。比如我们已经在ADB-PG中存储了下面内容。我们就可以通过求取的向量来获得最相近的内容或者知识,比如第一条和第三条。通义千问是...,通义千问可以帮助我们xxx。
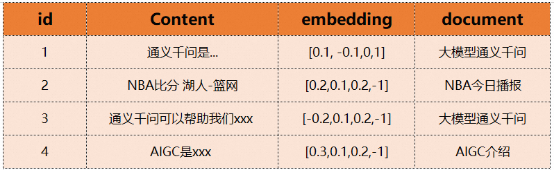
Part3 推理求解
在获得最相关的知识之后,我们就可以就可以让LLM基于最相关的知识和独立问题来进行求解推理,得到最终的答案了。这里就是结合“通义千问是...”,“通义千问可以帮助我们xxx”等等最有效的信息来回答“通义千问有什么用”这个问题了。最终让GPT的推理求解大致是这样:

4、ADB-PG:内置向量检索+全文检索的一站式企业知识数据库
为什么ADB-PG适合作为Chatbot的知识数据库?ADB-PG是一款具备大规模并行处理能力的云原生数据仓库。它支持行存储和列存储模式,既可以提供高性能的离线数据处理,也可以支持高并发的海量数据在线分析查询。因此我们可以说ADB-PG是一个支持分布式事务、混合负载的数据仓库平台,同时也支持处理多种非结构化和半结构化数据源。如通过向量检索插件实现了对图片、语言、视频、文本等非结构化数据的高性能向量检索分析,对JSON等半结构化数据的全文检索分析。
因此在AIGC场景下,ADB-PG既可以作为一款向量数据库满足其对向量存储和检索的需求,也可以满足其他结构化数据的存储和查询,同时也可以提供全文检索的能力,为AIGC场景下的业务应用提供一站式的解决方案。下面我们将对ADB-PG的向量检索、融合检索和全文检索这三方面的能力进行详细介绍。
ADB-PG向量检索和融合检索功能于2020年首次在公有云上线,目前已经在人脸识别领域得到了非常广泛的应用。ADB-PG的向量数据库继承自数据仓库平台,因此它几乎拥有DBMS的所有好处,如ANSISQL、ACID事务、高可用性、故障恢复、时间点恢复、可编程性、可扩展性等。同时它支持了点积距离、汉明距离和欧氏距离的向量和向量的相似度搜索。这些功能目前在人脸识别、商品识别和基于文本的语义搜索中得到了广泛应用。随着AIGC的爆炸式增长,这些功能为基于文本的Chatbot奠定了坚实的基础。另外,ADB-PG向量检索引擎也使用Intel SIMD指令极其有效地实现了向量相似性匹配。
下面我们用一个具体的例子来说明ADB-PG的向量检索和融合检索如何使用。假设有一个文本知识库,它是将一批文章分割成chunk再转换为embedding向量后入库的,其中chunks表包含以下字段:
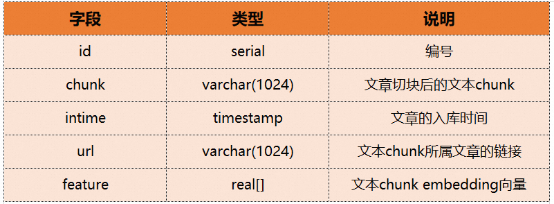
那么对应的建表DDL如下:

为了对向量检索进行加速,我们还需要建立一个向量索引:

同时为了对向量结构化融合查询提供加速,我们还需要为常用的结构化列建立索引:

在进行数据插入的时候,我们可以直接使用SQL中的insert语法:

在这个例子中,如果我们要通过文本搜索它的来源文章,那么我们就可以直接通过向量检索进行查找,具体SQL如下:

同样,如果我们的需求是查找最近一个月以内的某个文本的来源文章。那么我们就可以直接通过融合检索进行查找,具体SQL如下:

在看完上面的例子之后,我们可以很清楚地发现,在ADB-PG中使用向量检索和融合检索就跟使用传统数据库一样方便,没有任何的学习门槛。同时,我们对向量检索也有针对性地做了很多优化,如向量数据压缩、向量索引并行构建、向量多分区并行检索等等,这里不再详述。
ADB-PG同时也具有丰富的全文检索功能,支持复杂组合条件、结果排名等检索能力;另外对于中文数据集,ADB-PG也支持中文分词功能,能够高效、自定义地对中文文本加工分词;同时ADB-PG也支持使用索引加速全文检索分析性能。这些能力同样也可以在AIGC业务场景下得到充分的使用,如业务可以对知识库文档结合上述向量检索和全文检索能力进行双路召回。
知识数据库搜索部分包括传统的关键词全文检索和向量特征检索,关键词全文检索保证查询的精准性,向量特征检索提供泛化性和语义匹配,除字面匹配之外召回和语义匹配的知识,降低无结果率,为大模型提供更加丰富的上下文,有利于大语言模型进行总结归纳。
5、总结
结合本文前面所提到的内容,如果把满腹经纶的Chatbot比喻为人类,那么大语言模型可以看成是Chatbot在大学毕业前从所有书本和各领域公开资料所获得的知识和学习推理能力。所以基于大语言模型,Chatbot能够回答截止到其毕业前相关的问题,但如果问题涉及到特定专业领域(相关资料为企业组织专有,非公开)或者是新出现的物种概念(大学毕业时尚未诞生),仅靠在学校的知识所得(对应预训练的大语言模型)则无法从容应对,需要具备毕业后持续获得新知识的渠道(如工作相关专业学习资料库),结合本身的学习推理能力,来做出专业应对。
同样的Chatbot需要结合大语言模型的学习推理能力,和像ADB-PG这样包含向量检索和全文检索能力的一站式数据库(存储了企业组织专有的以及最新的知识文档和向量特征),在应对问题时具备基于该数据库中的知识内容来提供更专业更具时效性的回答。
以上是阿里云AnalyticDB(ADB) + LLM:构建AIGC时代下企业专属Chatbot的详细内容。更多信息请关注PHP中文网其他相关文章!

 大多数使用的10个功率BI图 - 分析VidhyaApr 16, 2025 pm 12:05 PM
大多数使用的10个功率BI图 - 分析VidhyaApr 16, 2025 pm 12:05 PM用Microsoft Power BI图来利用数据可视化的功能 在当今数据驱动的世界中,有效地将复杂信息传达给非技术观众至关重要。 数据可视化桥接此差距,转换原始数据i
 AI的专家系统Apr 16, 2025 pm 12:00 PM
AI的专家系统Apr 16, 2025 pm 12:00 PM专家系统:深入研究AI的决策能力 想象一下,从医疗诊断到财务计划,都可以访问任何事情的专家建议。 这就是人工智能专家系统的力量。 这些系统模仿Pro
 三个最好的氛围编码器分解了这项代码中的AI革命Apr 16, 2025 am 11:58 AM
三个最好的氛围编码器分解了这项代码中的AI革命Apr 16, 2025 am 11:58 AM首先,很明显,这种情况正在迅速发生。各种公司都在谈论AI目前撰写的代码的比例,并且这些代码的比例正在迅速地增加。已经有很多工作流离失所
 跑道AI的Gen-4:AI蒙太奇如何超越荒谬Apr 16, 2025 am 11:45 AM
跑道AI的Gen-4:AI蒙太奇如何超越荒谬Apr 16, 2025 am 11:45 AM从数字营销到社交媒体的所有创意领域,电影业都站在技术十字路口。随着人工智能开始重塑视觉讲故事的各个方面并改变娱乐的景观
 如何注册5天ISRO AI免费课程? - 分析VidhyaApr 16, 2025 am 11:43 AM
如何注册5天ISRO AI免费课程? - 分析VidhyaApr 16, 2025 am 11:43 AMISRO的免费AI/ML在线课程:通向地理空间技术创新的门户 印度太空研究组织(ISRO)通过其印度遥感研究所(IIR)为学生和专业人士提供了绝佳的机会
 AI中的本地搜索算法Apr 16, 2025 am 11:40 AM
AI中的本地搜索算法Apr 16, 2025 am 11:40 AM本地搜索算法:综合指南 规划大规模活动需要有效的工作量分布。 当传统方法失败时,本地搜索算法提供了强大的解决方案。 本文探讨了爬山和模拟
 OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑Apr 16, 2025 am 11:37 AM
OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑Apr 16, 2025 am 11:37 AM该版本包括三种不同的型号,GPT-4.1,GPT-4.1 MINI和GPT-4.1 NANO,标志着向大语言模型景观内的特定任务优化迈进。这些模型并未立即替换诸如
 提示:chatgpt生成假护照Apr 16, 2025 am 11:35 AM
提示:chatgpt生成假护照Apr 16, 2025 am 11:35 AMChip Giant Nvidia周一表示,它将开始制造AI超级计算机(可以处理大量数据并运行复杂算法的机器),完全是在美国首次在美国境内。这一消息是在特朗普总统SI之后发布的


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

SublimeText3 Linux新版
SublimeText3 Linux最新版

Atom编辑器mac版下载
最流行的的开源编辑器

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

