



Transformer 是时下最强大的 seq2seq 架构。预训练 transformer 通常具有 512(例如 BERT)或 1024 个(例如 BART)token 的个上下文窗口,这对于目前许多文本摘要数据集(XSum、CNN/DM)来说是足够长的。
但 16384 并不是生成所需上下文长度的上限:涉及长篇叙事的任务,如书籍摘要(Krys-´cinski et al.,2021)或叙事问答(Kociskýet al.,2018),通常输入超过 10 万个 token。维基百科文章生成的挑战集(Liu*et al.,2018)包含超过 50 万个 token 的输入。生成式问答中的开放域任务可以从更大的输入中综合信息,例如回答关于维基百科上所有健在作者的文章的聚合属性的问题。图 1 根据常见的上下文窗口长度绘制了几个流行的摘要和问答数据集的大小;最长的输入比 Longformer 的上下文窗口长 34 倍以上。
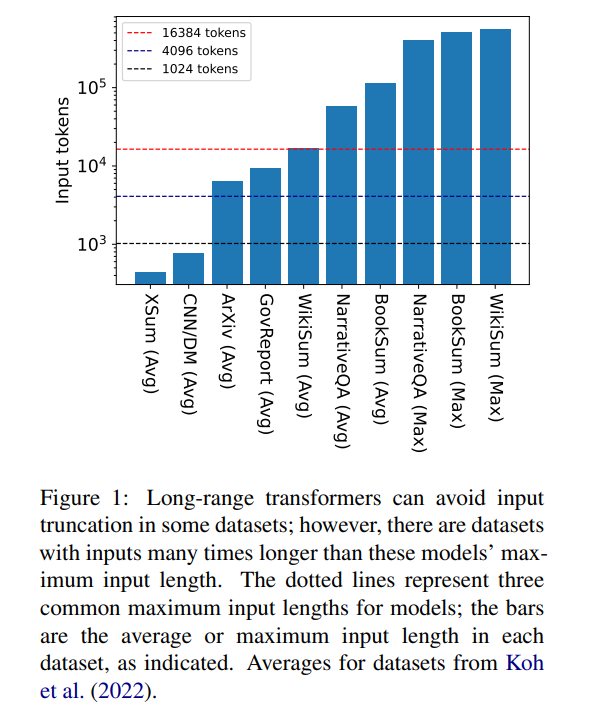
在这些超长输入的情况下,vanilla transformer 无法进行缩放,因为原生注意力机制具有平方级的复杂度。长输入 transformer 虽然比标准 transformer 更高效,但仍需要大量的计算资源,这些资源随着上下文窗口大小的增加而增加。此外,增加上下文窗口需要用新的上下文窗口大小从头开始重新训练模型,计算上和环境上的代价都不小。
在「Unlimiformer: Long-Range Transformers with Unlimited Length Input」一文中,来自卡内基梅隆大学的研究者引入了 Unlimiformer。这是一种基于检索的方法,这种方法增强了预训练的语言模型,以在测试时接受无限长度的输入。

论文链接:https://arxiv.org/pdf/2305.01625v1.pdf
Unlimiformer 可以被注入到任何现有的编码器 - 解码器 transformer 中,能够处理长度不限的输入。给定一个长的输入序列,Unlimiformer 可以在所有输入 token 的隐藏状态上构建一个数据存储。然后,解码器的标准交叉注意力机制能够查询数据存储,并关注前 k 个输入 token。数据存储可以存储在 GPU 或 CPU 内存中,能够次线性查询。
Unlimiformer 可以直接应用于经过训练的模型,并且可以在没有任何进一步训练的情况下改进现有的 checkpoint。Unlimiformer 经过微调后,性能会得到进一步提高。本文证明,Unlimiformer 可以应用于多个基础模型,如 BART(Lewis et al.,2020a)或 PRIMERA(Xiao et al.,2022),且无需添加权重和重新训练。在各种长程 seq2seq 数据集中,Unlimiformer 不仅在这些数据集上比 Longformer(Beltagy et al.,2020b)、SLED(Ivgi et al.,2022)和 Memorizing transformers(Wu et al.,2021)等强长程 Transformer 表现更好,而且本文还发现 Unlimiform 可以应用于 Longformer 编码器模型之上,以进行进一步改进。
Unlimiformer 技术原理
由于编码器上下文窗口的大小是固定的,Transformer 的最大输入长度受到限制。然而,在解码过程中,不同的信息可能是相关的;此外,不同的注意力头可能会关注不同类型的信息(Clark et al.,2019)。因此,固定的上下文窗口可能会在注意力不那么关注的 token 上浪费精力。
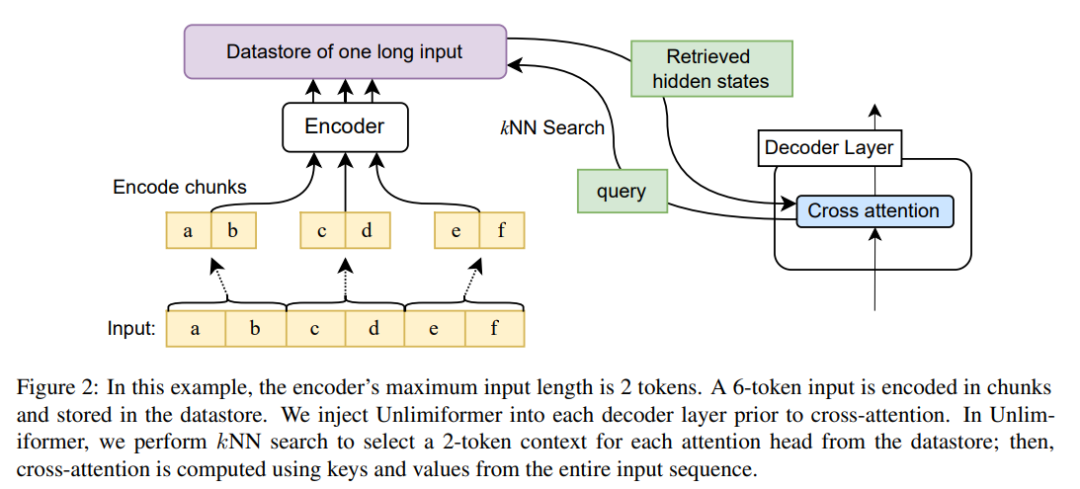
在每个解码步骤中,Unlimiformer 中每个注意力头都会从全部输入中选择一个单独的上下文窗口。通过将 Unlimiformer 查找注入解码器来实现:在进入交叉注意力模块之前,该模型在外部数据存储中执行 k 最近邻 (kNN) 搜索,在每个解码器层中的每个注意力头中选一组 token 来参与。
编码
为了将比模型的上下文窗口长度更长的输入序列进行编码,本文按照 Ivgi et al. (2022) 的方法对输入的重叠块进行编码 (Ivgi et al. ,2022),只保留每个 chunk 的输出的中间一半,以确保编码过程前后都有足够的上下文。最后,本文使用 Faiss (Johnson et al., 2019) 等库对数据存储中的编码输入进行索引(Johnson et al.,2019)。
检索增强的交叉注意力机制
在标准的交叉注意力机制中,transformer 的解码器关注编码器的最终隐状态,编码器通常截断输入,并仅对输入序列中的前 k 个 token 进行编码。
本文不是只关注输入的这前 k 个 token,对于每个交叉注意头,都检索更长的输入系列的前 k 个隐状态,并只关注这前 k 个。这样就能从整个输入序列中检索关键字,而不是截断关键字。在计算和 GPU 内存方面,本文的方法也比处理所有输入 token 更便宜,同时通常还能保留 99% 以上的注意力性能。
图 2 显示了本文对 seq2seq transformer 架构的更改。使用编码器对完整输入进行块编码,并将其存储在数据存储中;然后,解码时查询编码的隐状态数据存储。kNN 搜索是非参数的,并且可以被注入到任何预训练的 seq2seq transformer 中,详情如下。
实验结果
长文档摘要
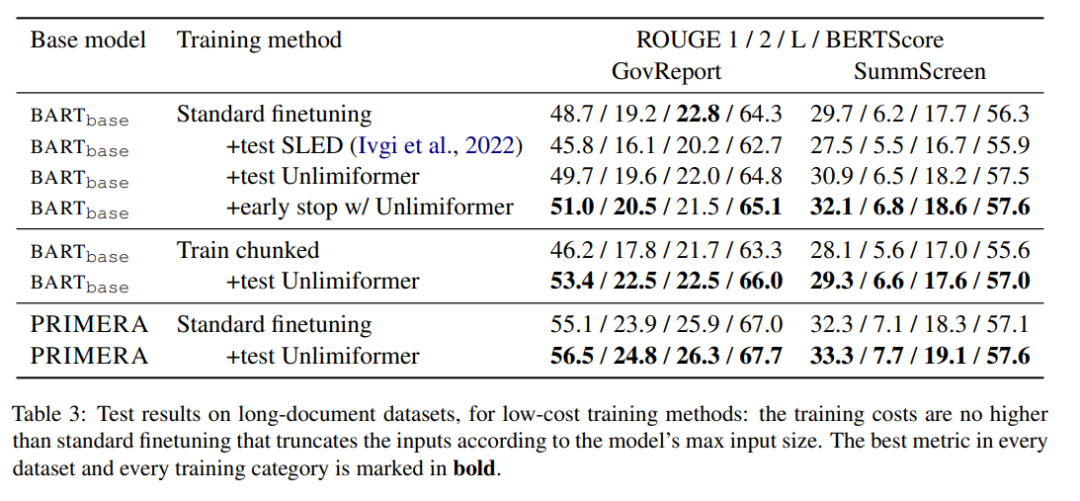
表 3 显示了长文本(4k 及 16k 的 token 输入)摘要数据集中的结果。
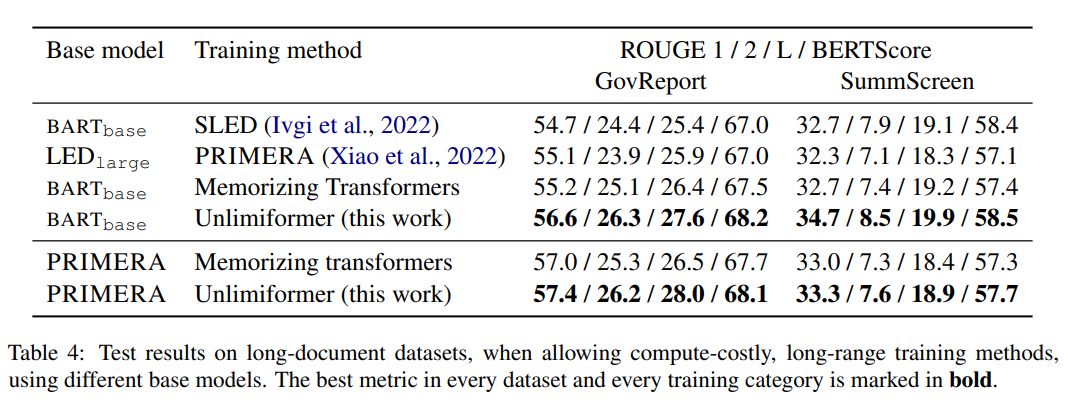
在表 4 的训练方法中,Unlimiformer 能够在各项指标上达到最优。
书籍摘要
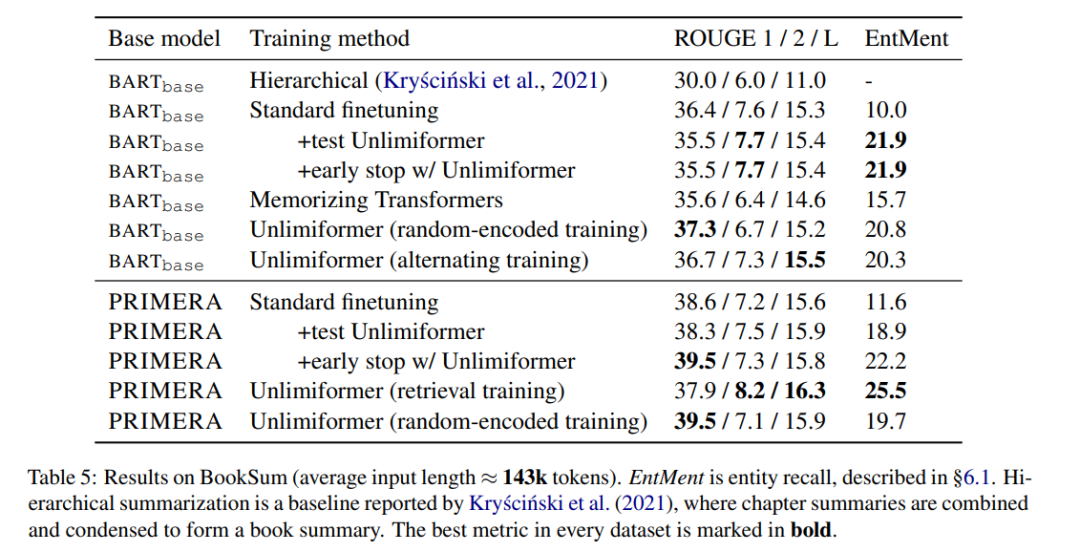
表 5 显示了在书籍摘要上的结果。可以看到,基于 BARTbase 和 PRIMERA,应用 Unlimiformer 都能取得一定的改进效果。
以上是GPT-4的32k输入框还是不够用?Unlimiformer把上下文长度拉到无限长的详细内容。更多信息请关注PHP中文网其他相关文章!

 大多数使用的10个功率BI图 - 分析VidhyaApr 16, 2025 pm 12:05 PM
大多数使用的10个功率BI图 - 分析VidhyaApr 16, 2025 pm 12:05 PM用Microsoft Power BI图来利用数据可视化的功能 在当今数据驱动的世界中,有效地将复杂信息传达给非技术观众至关重要。 数据可视化桥接此差距,转换原始数据i
 AI的专家系统Apr 16, 2025 pm 12:00 PM
AI的专家系统Apr 16, 2025 pm 12:00 PM专家系统:深入研究AI的决策能力 想象一下,从医疗诊断到财务计划,都可以访问任何事情的专家建议。 这就是人工智能专家系统的力量。 这些系统模仿Pro
 三个最好的氛围编码器分解了这项代码中的AI革命Apr 16, 2025 am 11:58 AM
三个最好的氛围编码器分解了这项代码中的AI革命Apr 16, 2025 am 11:58 AM首先,很明显,这种情况正在迅速发生。各种公司都在谈论AI目前撰写的代码的比例,并且这些代码的比例正在迅速地增加。已经有很多工作流离失所
 跑道AI的Gen-4:AI蒙太奇如何超越荒谬Apr 16, 2025 am 11:45 AM
跑道AI的Gen-4:AI蒙太奇如何超越荒谬Apr 16, 2025 am 11:45 AM从数字营销到社交媒体的所有创意领域,电影业都站在技术十字路口。随着人工智能开始重塑视觉讲故事的各个方面并改变娱乐的景观
 如何注册5天ISRO AI免费课程? - 分析VidhyaApr 16, 2025 am 11:43 AM
如何注册5天ISRO AI免费课程? - 分析VidhyaApr 16, 2025 am 11:43 AMISRO的免费AI/ML在线课程:通向地理空间技术创新的门户 印度太空研究组织(ISRO)通过其印度遥感研究所(IIR)为学生和专业人士提供了绝佳的机会
 AI中的本地搜索算法Apr 16, 2025 am 11:40 AM
AI中的本地搜索算法Apr 16, 2025 am 11:40 AM本地搜索算法:综合指南 规划大规模活动需要有效的工作量分布。 当传统方法失败时,本地搜索算法提供了强大的解决方案。 本文探讨了爬山和模拟
 OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑Apr 16, 2025 am 11:37 AM
OpenAI以GPT-4.1的重点转移,将编码和成本效率优先考虑Apr 16, 2025 am 11:37 AM该版本包括三种不同的型号,GPT-4.1,GPT-4.1 MINI和GPT-4.1 NANO,标志着向大语言模型景观内的特定任务优化迈进。这些模型并未立即替换诸如
 提示:chatgpt生成假护照Apr 16, 2025 am 11:35 AM
提示:chatgpt生成假护照Apr 16, 2025 am 11:35 AMChip Giant Nvidia周一表示,它将开始制造AI超级计算机(可以处理大量数据并运行复杂算法的机器),完全是在美国首次在美国境内。这一消息是在特朗普总统SI之后发布的


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

SublimeText3 Linux新版
SublimeText3 Linux最新版

Dreamweaver CS6
视觉化网页开发工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

