



一个多月前,OpenAI 的 GPT-4 问世。除了各种出色的直观演示外,它还实现了一个重要更新:可以处理的上下文 token 长度默认为 8k,但最长可达 32K(大约 50 页文本)。这意味着,在向 GPT-4 提问时,我们可以输入比之前长得多的文本。这使得 GPT-4 的应用场景大大扩展,能更好地处理长对话、长文本以及文件搜索和分析。
不过,这一记录很快就被打破了:来自谷歌研究院的 CoLT5 将模型可以处理的上下文 token 长度扩展到了 64k。
这样的突破并不容易,因为这些使用 Transformer 架构的模型都要面临一个问题:Transformer 处理长文档在计算上是非常昂贵的,因为注意力成本随输入长度呈二次增长,这使得大型模型越来越难以应用于更长的输入。
尽管如此,研究者依然在此方向上不断突破。前几天,一篇来自开源对话 AI 技术栈 DeepPavlov 等机构的研究表明:通过采用一种名为 Recurrent Memory Transformer(RMT)的架构,他们可以将 BERT 模型的有效上下文长度增加到 200 万个 token(按照 OpenAI 的计算方式,大约相当于 3200 页文本),同时保持了较高的记忆检索准确性(注:Recurrent Memory Transformer 是 Aydar Bulatov 等人在 NeurIPS 2022 的一篇论文中提出的方法)。新方法允许存储和处理局部和全局信息,并通过使用 recurrence 使信息在输入序列的各 segment 之间流动。

作者表示,通过使用 Bulatov 等人在「Recurrent Memory Transformer」一文中介绍的简单的基于 token 的记忆机制,他们可以将 RMT 与 BERT 这样的预训练 Transformer 模型结合起来,用一个 Nvidia GTX 1080Ti GPU 就可以对超过 100 万个 token 的序列进行全注意和全精度操作。

论文地址:https://arxiv.org/pdf/2304.11062.pdf
不过,也有人提醒说,这并不是真正的「免费的午餐」,上述论文的提升是用「更长的推理时间 + 实质性的质量下降」换来的。因此,它还不能算是一次变革,但它可能成为下一个范式(token 可能无限长)的基础。
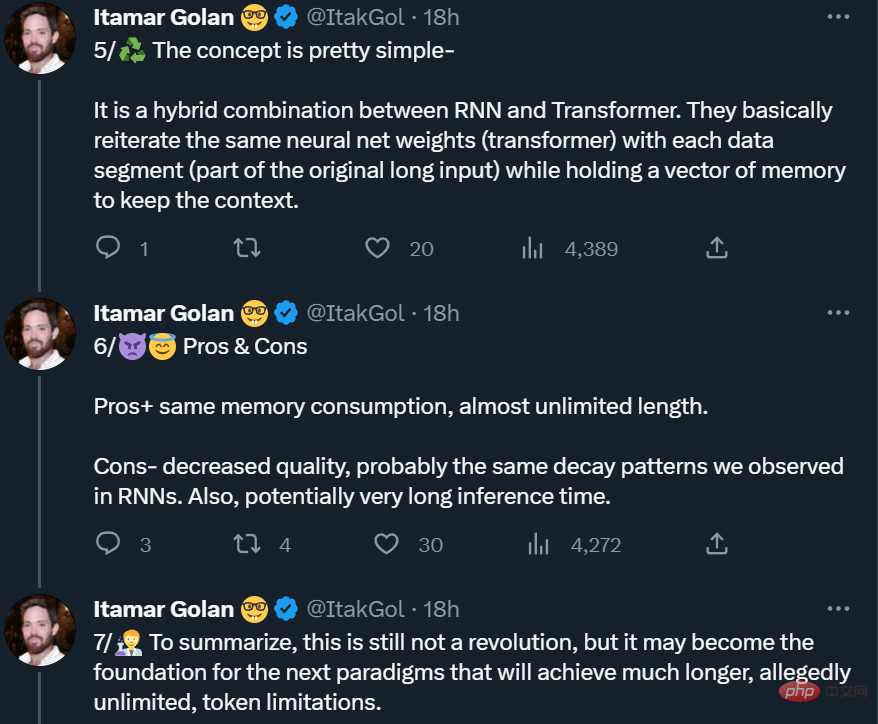
Recurrent Memory Transformer
该研究采用 Bulatov 等人 2022 年提出的方法 Recurrent Memory Transformer(RMT),并将其改成即插即用的方法,主要机制如下图所示:
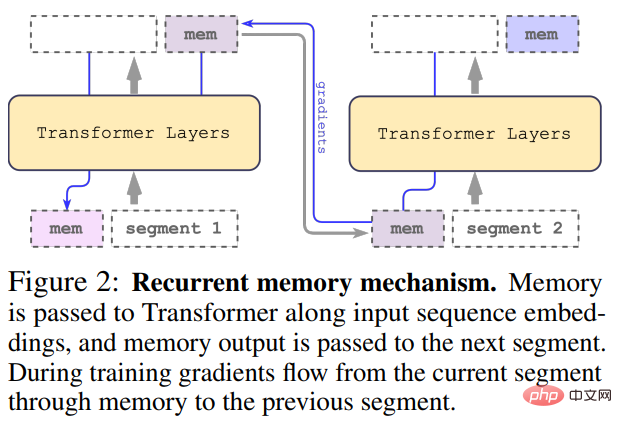
冗长的输入被分成多个 segment,记忆向量(memory vector)被添加到第一个 segment 嵌入之前,并与 segment token 一起处理。对于像 BERT 这样的纯编码器模型,记忆只在 segment 的开头添加一次,这一点与 (Bulatov et al., 2022) 不同,纯解码器模型将记忆分为读取和写入两部分。对于时间步长 τ 和 segment
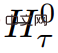
,循环按照如下步骤执行:

其中,N 是 Transformer 的层数。前向传播之后,
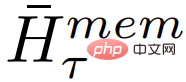
包含 segment τ 的更新记忆 token。
输入序列的 segment 按照顺序处理。为了启用循环连接,该研究将记忆 token 的输出从当前 segment 传递到下一个 segment 的输入:
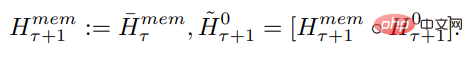
RMT 中的记忆和循环都仅基于全局记忆 token。这允许主干 Transformer 保持不变,从而使 RMT 的记忆增强能力与任何 Transformer 模型都兼容。
计算效率
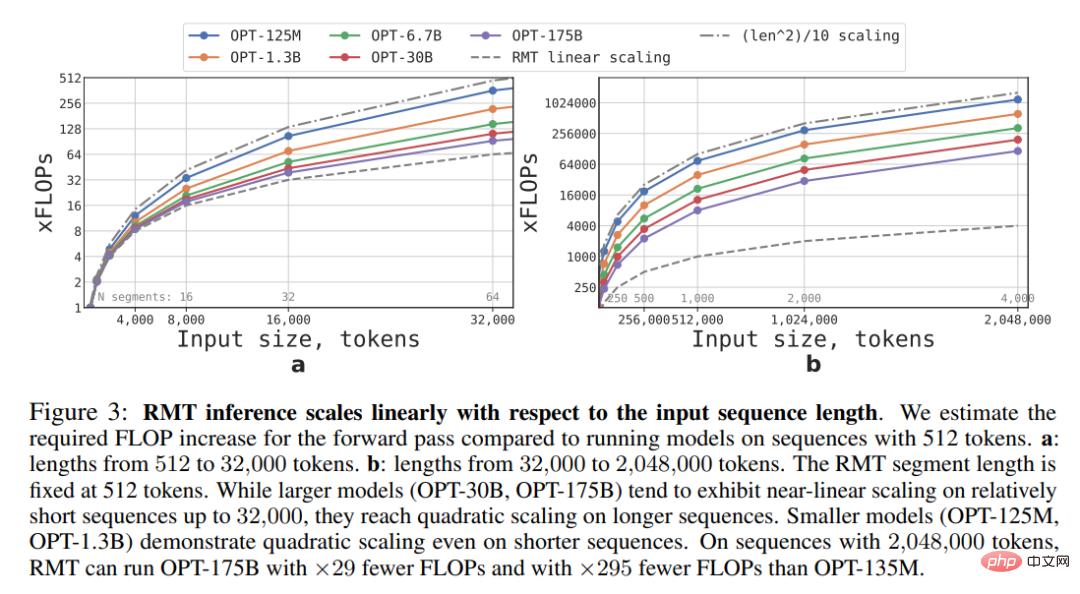
该研究估算了不同大小和序列长度的 RMT 和 Transformer 模型所需的 FLOP。
如下图 3 所示,如果 segment 的长度固定,RMT 可针对任何模型大小进行线性扩展。该研究通过将输入序列分成 segment,并仅在 segment 边界内计算完整的注意力矩阵来实现线性扩展。
由于 FFN 层的计算量很大,较大的 Transformer 模型往往会表现出较慢的随序列长度的二次扩展(quadratic scaling)。然而,对于大于 32000 的超长序列,它们会退回到二次扩展。对于多于一个 segment 的序列(本研究中 > 512),RMT 比非循环模型需要更少的 FLOP,并且可以将 FLOP 的数量减少多达 295 倍。RMT 为较小的模型提供了更大的 FLOP 相对减少,但在绝对数量上,OPT-175B 模型的 FLOP 减少了 29 倍是非常显著的。
记忆任务
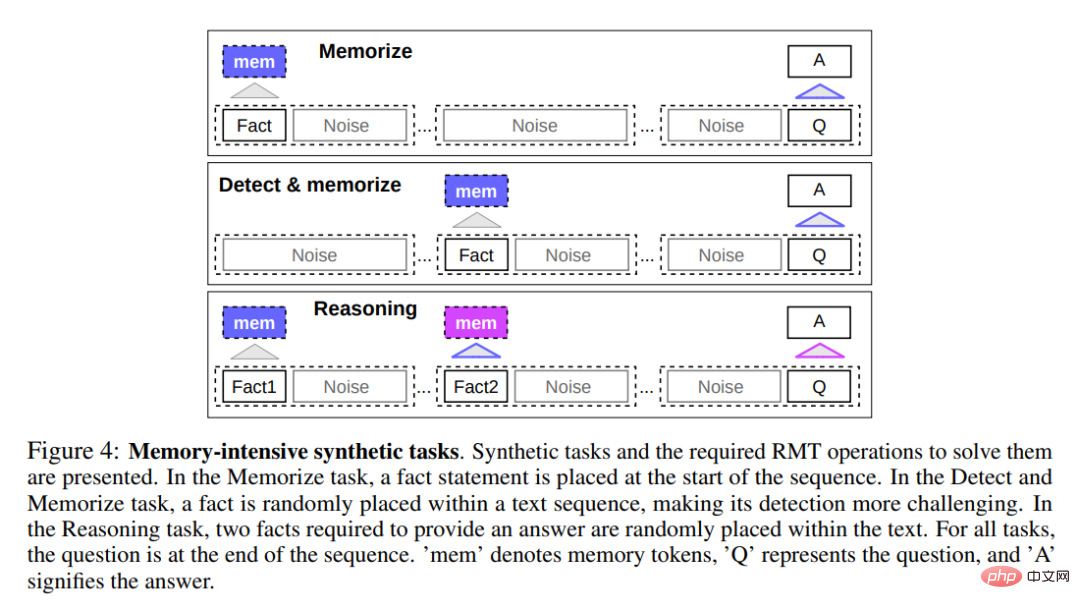
为了测试记忆能力,该研究构建了需要记忆简单事实和基本推理的合成数据集。任务输入由一个或多个事实和一个只有使用所有事实才能回答的问题组成。为了增加任务难度,该研究还添加了与问题或答案无关的自然语言文本来充当噪声,因此模型的任务是将事实与不相关的文本分开,并使用事实来回答问题。

事实记忆
第一项任务是检测 RMT 在记忆中长时间写入和存储信息的能力,如下图 4 顶部所示。在最简单的情况下,事实往往位于输入开头,而问题总是在末尾。问题和答案之间不相关文本的数量逐渐增加,以至于整个输入不适合单个模型输入。

事实检测与记忆
事实检测通过将一个事实移动到输入中的随机位置来增加任务难度,如上图 4 中部所示。这需要模型首先将事实与不相关文本区分开来,把事实写入记忆中,然后用它回答位于末尾的问题。
利用记忆事实进行推理
记忆的另一个操作是使用记忆事实和当前上下文进行推理。为了评估这一功能,研究者使用了一个更复杂的任务,其中生成了两个事实并将它们放置在了输入序列之中,如上图 4 底部所示。在序列末尾提出的问题是以一种「必须使用任意事实来正确回答问题」的方式来描述。

实验结果
研究者使用 4 到 8 块英伟达 1080ti GPU 来训练和评估模型。对于更长的序列,他们则使用单个 40GB 的英伟达 A100 来加快评估速度。
课程学习
研究者观察到,使用训练计划能够显著提升解决方案的准确性和稳定性。最开始,RMT 在较短版本的任务上进行训练,并在训练收敛时通过添加另一个 segment 来增加任务长度。课程学习过程一直持续,直到达到所需的输入长度。
在实验中,研究者首先从适合单个 segment 的序列开始。实际 segment 的大小为 499,但由于 BERT 的 3 个特殊 token 和 10 个记忆占位符从模型输入中保留下来,大小为 512。他们注意到, 在较短任务上训练后,RMT 更容易解决更长版本任务,这得益于它使用更少训练步收敛到完美的解决方案。
外推能力
RMT 对不同序列长度的泛化能力如何呢?为了回答这个问题,研究者评估了在不同数量 segment 上训练的模型,以解决更长的任务,具体如下图 5 所示。
他们观察到,模型往往在较短任务上表现更好,唯一的例外是单 segment 推理任务,一旦模型在更长序列上训练,则该任务变得很难解决。一个可能的解释是:由于任务大小超过了一个 segment,则模型不再「期待」第一个 segment 中的问题,导致质量下降。
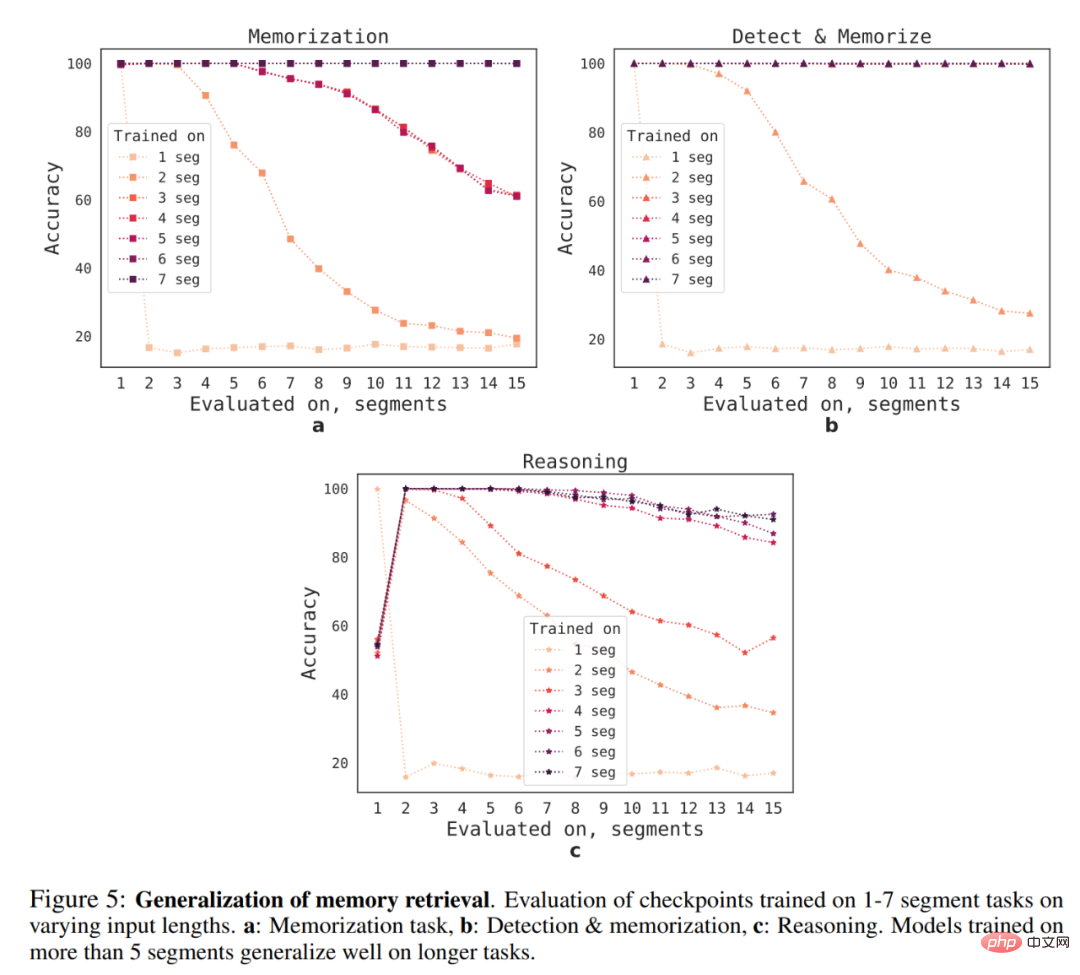
有趣的是,RMT 泛化到更长序列的能力也随着训练 segment 的增加而出现。在 5 个或更多 segment 上训练后,RMT 可以近乎完美地泛化到两倍长的任务。
为了测试泛化的局限性,研究者将验证任务大小增至 4096 个 segment 或 2,043,904 个 token(如上图 1 所示),RMT 在如此长的序列上表现得出奇的好。检测和记忆任务最简单,推理任务最复杂。
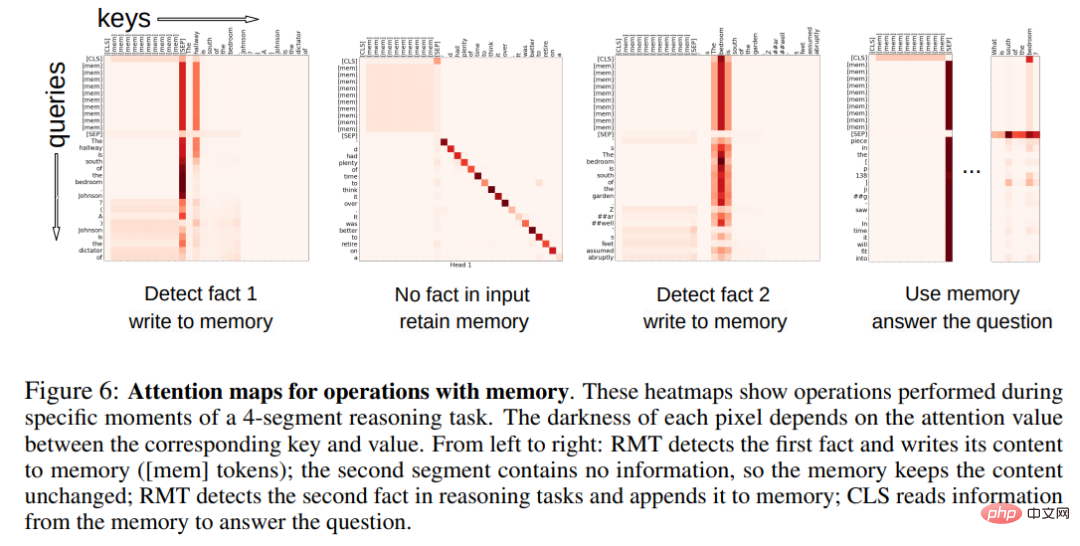
记忆操作的注意力模式
在下图 6 中,通过检查特定 segment 上的 RMT 注意力,研究者观察到了记忆操作对应特定的注意力模式。此外 5.2 节中极长序列上的高外推性能证明了学得记忆操作的有效性,即使使用数千次也是如此。
更多技术与实验细节请参阅原论文。
以上是真·量子速读:突破GPT-4一次只能理解50页文本限制,新研究扩展到百万token的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何使用Huggingface Smollm建立个人AI助手Apr 18, 2025 am 11:52 AM
如何使用Huggingface Smollm建立个人AI助手Apr 18, 2025 am 11:52 AM利用“设备” AI的力量:建立个人聊天机器人CLI 在最近的过去,个人AI助手的概念似乎是科幻小说。 想象一下科技爱好者亚历克斯(Alex)梦见一个聪明的本地AI同伴 - 不依赖
 通过斯坦福大学激动人心的新计划,精神健康的AI专心分析Apr 18, 2025 am 11:49 AM
通过斯坦福大学激动人心的新计划,精神健康的AI专心分析Apr 18, 2025 am 11:49 AM他们的首届AI4MH发射于2025年4月15日举行,著名的精神科医生兼神经科学家汤姆·因斯尔(Tom Insel)博士曾担任开幕式演讲者。 Insel博士因其在心理健康研究和技术方面的杰出工作而闻名
 2025年WNBA选秀课程进入联盟成长并与在线骚扰作斗争Apr 18, 2025 am 11:44 AM
2025年WNBA选秀课程进入联盟成长并与在线骚扰作斗争Apr 18, 2025 am 11:44 AM恩格伯特说:“我们要确保WNBA仍然是每个人,球员,粉丝和公司合作伙伴,感到安全,重视和授权的空间。” anno
 Python内置数据结构的综合指南 - 分析VidhyaApr 18, 2025 am 11:43 AM
Python内置数据结构的综合指南 - 分析VidhyaApr 18, 2025 am 11:43 AM介绍 Python擅长使用编程语言,尤其是在数据科学和生成AI中。 在处理大型数据集时,有效的数据操作(存储,管理和访问)至关重要。 我们以前涵盖了数字和ST
 与替代方案相比,Openai新型号的第一印象Apr 18, 2025 am 11:41 AM
与替代方案相比,Openai新型号的第一印象Apr 18, 2025 am 11:41 AM潜水之前,一个重要的警告:AI性能是非确定性的,并且特定于高度用法。简而言之,您的里程可能会有所不同。不要将此文章(或任何其他)文章作为最后一句话 - 目的是在您自己的情况下测试这些模型
 AI投资组合|如何为AI职业建立投资组合?Apr 18, 2025 am 11:40 AM
AI投资组合|如何为AI职业建立投资组合?Apr 18, 2025 am 11:40 AM建立杰出的AI/ML投资组合:初学者和专业人士指南 创建引人注目的投资组合对于确保在人工智能(AI)和机器学习(ML)中的角色至关重要。 本指南为建立投资组合提供了建议
 代理AI对安全操作可能意味着什么Apr 18, 2025 am 11:36 AM
代理AI对安全操作可能意味着什么Apr 18, 2025 am 11:36 AM结果?倦怠,效率低下以及检测和作用之间的差距扩大。这一切都不应该令任何从事网络安全工作的人感到震惊。 不过,代理AI的承诺已成为一个潜在的转折点。这个新课
 Google与Openai:AI为学生打架Apr 18, 2025 am 11:31 AM
Google与Openai:AI为学生打架Apr 18, 2025 am 11:31 AM直接影响与长期伙伴关系? 两周前,Openai提出了强大的短期优惠,在2025年5月底之前授予美国和加拿大大学生免费访问Chatgpt Plus。此工具包括GPT-4O,A A A A A


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

Atom编辑器mac版下载
最流行的的开源编辑器

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

