



任务通用是基础模型研究的核心目标之一,同时也是深度学习研究通向高级智能的必经之路。近年来,得益于注意力机制的通用关键建模能力,Transformer在众多领域中表现优异,逐渐呈现出通用架构的趋势。但是随着序列长度的增长,标准注意力机制的计算呈现二次复杂度,严重阻碍了其在长序列建模与大模型中的应用。
为此,来自清华大学软件学院的团队深入探索了这一关键问题,提出了任务通用的线性复杂度主干网络Flowformer,在保持标准Transformer的通用性的同时,将其复杂度降至线性,论文被ICML 2022接受。

作者列表:吴海旭,吴佳龙,徐介晖,王建民,龙明盛
链接:https://arxiv.org/pdf/2202.06258.pdf
代码:https://github.com/thuml/Flowformer
相比于标准Transformer,本文提出的Flowformer模型,具有以下特点:
- 线性复杂度,可以处理数千长度的输入序列;
- 没有引入新的归纳偏好,保持了原有注意力机制的通用建模能力;
- 任务通用,在长序列、视觉、自然语言、时间序列、强化学习五大任务上取得优秀效果。
1. 问题分析
标准的注意力机制输入包含queries(),keys()和values()三部分,,其计算方式如下:其中为注意力权重矩阵,最终计算结果为将进行加权融合所得,上述过程计算复杂度为。注意到,对于多项矩阵的连乘问题,在经典算法中已有较多研究。特别地,对于注意力机制,我们可以利用矩阵乘法的结合律来实现优化,如,即可将原本的二次复杂度降至线性。但是注意力机制中的函数使得无法直接应用结合律。因此,如何移除注意力机制中的函数是实现线性复杂度的关键。但是,近期的众多工作证明,函数在避免平凡注意力学习上起到了关键性作用。综上,我们期待一种模型设计方案,实现以下目标:(1)移除函数;(2)避免平凡注意力;(3)保持模型的通用性。
2. 动机
针对目标(1),在之前的工作中,往往使用核方法来替代函数,即通过近似注意力计算(为非线性函数),但直接去掉会造成平凡注意力。为此,针对目标(2),之前工作不得不引入一些归纳偏好,这限制了模型的通用性,因此不满足目标(3),比如cosFormer中的局部性假设等。
Softmax中的竞争机制
为满足上述目标,我们从的基本性质出发进行分析。我们注意到,最初被提出是用于:将「赢者通吃」的取极大值操作扩展为可微分形式。因此,得益于其内在的「竞争」机制,它可以使各个token之间的注意力权重差异化,从而避免了平凡的注意力的问题。基于以上考虑,我们试图将竞争机制引入注意力机制设计,从而避免核方法分解带来平凡注意力问题。
网络流中的竞争机制
我们关注到在图论中的经典网络流(Flow network)模型中,「守恒」(Conservation)是一个重要现象,即每个节点的流入量等于流出量。受到「固定资源情况下,必定引起竞争」的启发,在本文中,我们试图从网络流视角重新分析经典注意力机制中的信息流动,并通过守恒性质将竞争引入注意力机制设计,以避免平凡注意力问题。
3. Flowformer
3.1 网络流视角下的注意力机制
在注意力机制内部:信息流动可以表示为:从源(source,对应)基于学习到的流容量(flow capacity,对应注意力权重)汇聚至汇(sink,对应)。
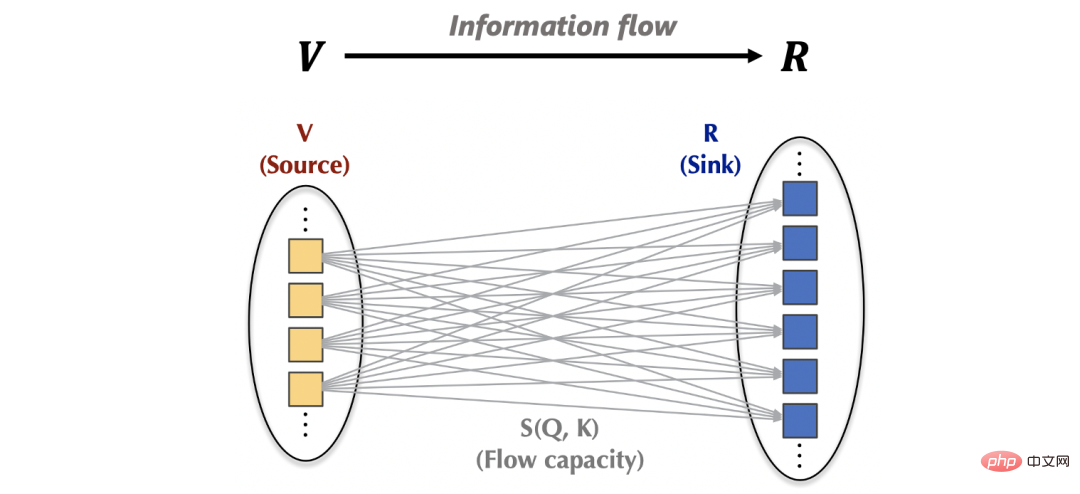
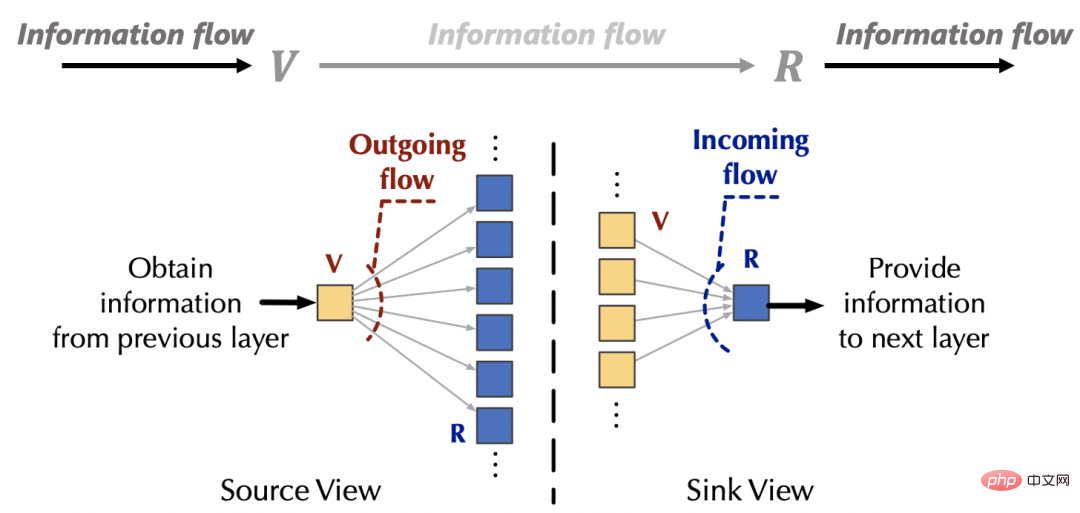
在注意力机制外部,源(v)的信息来自于上一层网络,汇(R)的信息也将提供给下面的前馈层。
3.2 Flow-Attention
基于上述观察,我们可以通过分别从流入和流出两个角度,控制注意力机制与外部网络的交互,来实现「固定资源」,从而分别引起源和汇内部的竞争,以避免平凡注意力。不失一般性,我们将注意力机制与外部网络的交互信息量设置为默认值1.
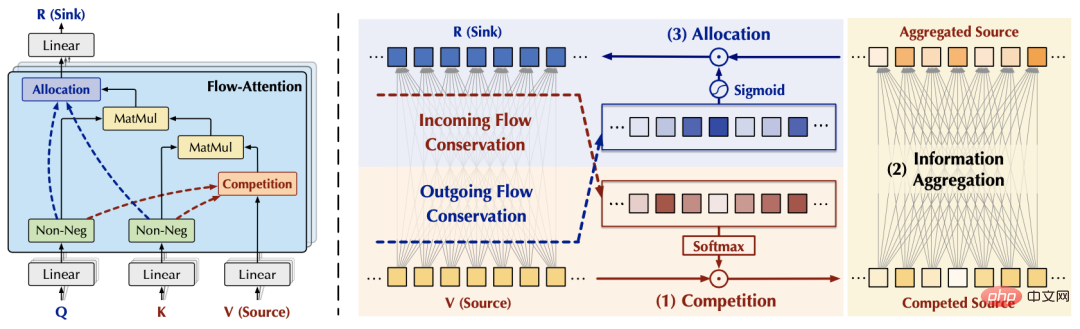
(1)汇(R)的流入守恒:
不难得到,未经过守恒之前,对于第个汇,其流入的信息量为: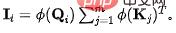 。为了固定每个汇流入的信息量为单位1,我们将
。为了固定每个汇流入的信息量为单位1,我们将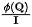 作为归一化引入信息流(注意力权重)的计算。经过归一化之后,第个汇的流入信息量为:
作为归一化引入信息流(注意力权重)的计算。经过归一化之后,第个汇的流入信息量为: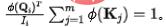
此时,由于汇的流入守恒,各个源(V)之间存在天然的竞争关系,我们计算此时每个源(V)给出的信息量,即可得到:竞争情况下,每个源所提供的信息量,这也代表着每个源的重要性。
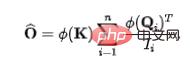
(2)源(V)的流出守恒:与前述过程类似,未经过守恒之前,对于第个源,其流出的信息量为: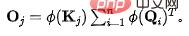 。为了固定每个源流出的信息量为单位1,我们将作为归一化引入信息流(注意力权重)的计算。经过归一化之后,第j个源的流出信息量为:
。为了固定每个源流出的信息量为单位1,我们将作为归一化引入信息流(注意力权重)的计算。经过归一化之后,第j个源的流出信息量为: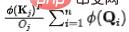 。此时,由于源的流出守恒,各个汇()之间存在天然的竞争关系,我们计算此时每个汇()接受的信息量,即可得到:竞争情况下,每个结果所需要最终所接受的信息量。
。此时,由于源的流出守恒,各个汇()之间存在天然的竞争关系,我们计算此时每个汇()接受的信息量,即可得到:竞争情况下,每个结果所需要最终所接受的信息量。
(3)整体设计
基于上述结果,我们设计如下Flow-Attention机制,具体包含竞争(Competition)、聚合(Aggregation)、分配(Allocation)三部分:其中Competition将竞争机制引入中,突出重要的信息;Aggregation基于矩阵结合律实现线性复杂度;Allocation通过将竞争机制引入,控制传递到下一层的信息量。上述过程中的所有操作均为线性复杂度。同时,Flow-Attention的设计仅仅依赖于网络流中的守恒原理,对信息流的重新整合,因此并没有引入新的归纳偏好,保证了模型的通用性。将标准Transformer中的二次复杂度Attention替换为Flow-Attention,即得到了Flowformer。
4. 实验
本文在标准数据集上进行了广泛的实验:
- 覆盖了长序列、视觉、自然语言、时间序列、强化学习五大任务;
- 考察了标准(Normal)和自回归任务(Causal)两种注意力机制类型。
- 涵盖了多种序列长度的输入情况(20-4000)。
- 对比了各领域经典模型、主流深度模型、Transformer及其变体等多种基线方法。
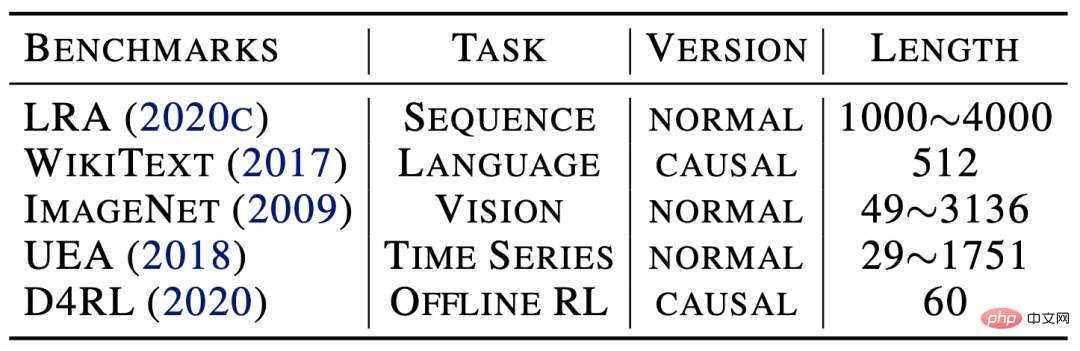
如下表所示,Flowformer在五大任务上均表现优秀,验证了模型的通用性。详细实验结果请见论文。
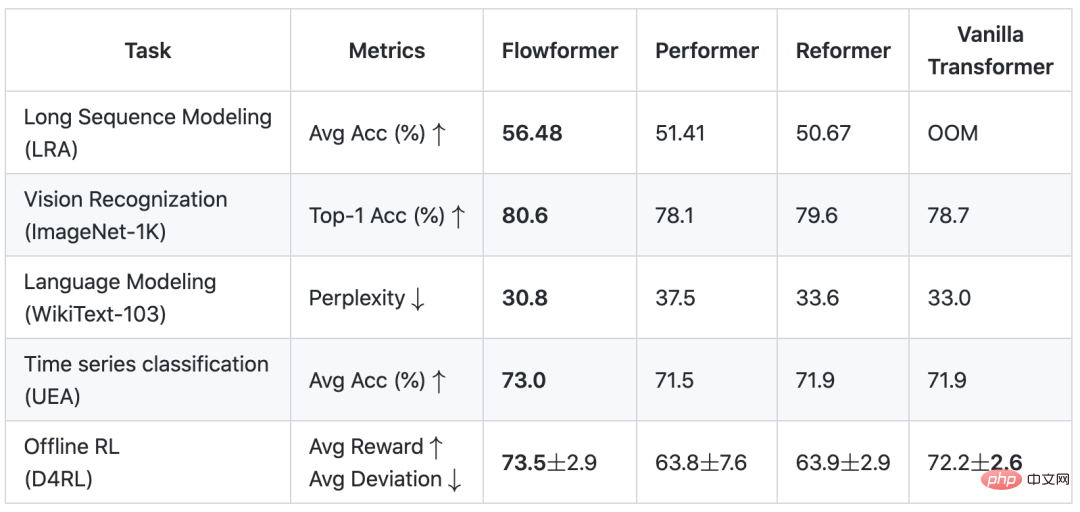
5. 分析
为了进一步说明Flowformer的工作原理,我们对ImageNet分类任务中的注意力(对应Flow-Attention中的)进行了可视化实验,从中可以发现:
- 如果仅仅使用核方法进行分解,如Linear Transformer,会造成模型注意力分散,无法有效捕捉到关键区域;
- 经典Transformer和Flowformer均可以准确捕捉到图像的关键位置,但是后者在计算复杂度上具有优势;
- cosFormer在注意力机制中引入一维局部性假设,在语言任务上效果突出。但是在图像(将2D数据展开成1D序列)中,如果不将局部性假设扩展至二维,则无法适配视觉任务。这也印证了Flowformer中「没有引入新的归纳偏好」设计方式的优势。
上述可视化表明,通过Flow-Attention将竞争引入注意力机制设计可以有效避免平凡注意力。更多可视化实验可见论文。
6. 总结
本文提出的Flowformer通过将网络流中的守恒原理引入设计,自然地将竞争机制引入到注意力计算中,有效避免了平凡注意力问题,在实现线性复杂度的同时,保持了标准Transformer的通用性。Flowformer在长序列、视觉、自然语言、时间序列、强化学习五大任务上取得优秀效果。此外,Flowformer中「无特殊归纳偏好」的设计理念也对通用基础架构的研究具有一定的启发性。在未来工作中,我们将进一步探索Flowformer在大规模预训练上的潜力。
以上是任务通用!清华提出主干网络Flowformer,实现线性复杂度|ICML2022的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何使用Huggingface Smollm建立个人AI助手Apr 18, 2025 am 11:52 AM
如何使用Huggingface Smollm建立个人AI助手Apr 18, 2025 am 11:52 AM利用“设备” AI的力量:建立个人聊天机器人CLI 在最近的过去,个人AI助手的概念似乎是科幻小说。 想象一下科技爱好者亚历克斯(Alex)梦见一个聪明的本地AI同伴 - 不依赖
 通过斯坦福大学激动人心的新计划,精神健康的AI专心分析Apr 18, 2025 am 11:49 AM
通过斯坦福大学激动人心的新计划,精神健康的AI专心分析Apr 18, 2025 am 11:49 AM他们的首届AI4MH发射于2025年4月15日举行,著名的精神科医生兼神经科学家汤姆·因斯尔(Tom Insel)博士曾担任开幕式演讲者。 Insel博士因其在心理健康研究和技术方面的杰出工作而闻名
 2025年WNBA选秀课程进入联盟成长并与在线骚扰作斗争Apr 18, 2025 am 11:44 AM
2025年WNBA选秀课程进入联盟成长并与在线骚扰作斗争Apr 18, 2025 am 11:44 AM恩格伯特说:“我们要确保WNBA仍然是每个人,球员,粉丝和公司合作伙伴,感到安全,重视和授权的空间。” anno
 Python内置数据结构的综合指南 - 分析VidhyaApr 18, 2025 am 11:43 AM
Python内置数据结构的综合指南 - 分析VidhyaApr 18, 2025 am 11:43 AM介绍 Python擅长使用编程语言,尤其是在数据科学和生成AI中。 在处理大型数据集时,有效的数据操作(存储,管理和访问)至关重要。 我们以前涵盖了数字和ST
 与替代方案相比,Openai新型号的第一印象Apr 18, 2025 am 11:41 AM
与替代方案相比,Openai新型号的第一印象Apr 18, 2025 am 11:41 AM潜水之前,一个重要的警告:AI性能是非确定性的,并且特定于高度用法。简而言之,您的里程可能会有所不同。不要将此文章(或任何其他)文章作为最后一句话 - 目的是在您自己的情况下测试这些模型
 AI投资组合|如何为AI职业建立投资组合?Apr 18, 2025 am 11:40 AM
AI投资组合|如何为AI职业建立投资组合?Apr 18, 2025 am 11:40 AM建立杰出的AI/ML投资组合:初学者和专业人士指南 创建引人注目的投资组合对于确保在人工智能(AI)和机器学习(ML)中的角色至关重要。 本指南为建立投资组合提供了建议
 代理AI对安全操作可能意味着什么Apr 18, 2025 am 11:36 AM
代理AI对安全操作可能意味着什么Apr 18, 2025 am 11:36 AM结果?倦怠,效率低下以及检测和作用之间的差距扩大。这一切都不应该令任何从事网络安全工作的人感到震惊。 不过,代理AI的承诺已成为一个潜在的转折点。这个新课
 Google与Openai:AI为学生打架Apr 18, 2025 am 11:31 AM
Google与Openai:AI为学生打架Apr 18, 2025 am 11:31 AM直接影响与长期伙伴关系? 两周前,Openai提出了强大的短期优惠,在2025年5月底之前授予美国和加拿大大学生免费访问Chatgpt Plus。此工具包括GPT-4O,A A A A A


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

记事本++7.3.1
好用且免费的代码编辑器

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

Dreamweaver CS6
视觉化网页开发工具

