



寫在前面&筆者的個人理解
目前,隨著自動駕駛技術的越發成熟以及自動駕駛感知任務需求的日益增多,工業界和學術界非常希望一個理想的感知演算法模型,可以同時完成三維目標偵測以及基於BEV空間的語意分割任務。對於一輛能夠實現自動駕駛功能的車輛而言,其通常配備環視相機感測器、光達感測器以及毫米波雷達感測器來採集不同模態的數據資訊。從而充分利用不同模態資料之間的互補優勢,使得不同模態之間的資料補充優勢,例如三維點雲資料可以為3D目標檢測任務提供信息,而彩色影像資料則可以為語義分割任務提供更加準確的資訊。 針對不同模態資料之間的互補優勢,透過將不同模態資料的有效資訊轉換到同一個座標系中,便於之後的聯合處理以及決策。例如三維點雲數據可以轉換到基於BEV空間的點雲數據,而環景攝影機的影像數據可以透過相機內外參的標定將其投影到3D空間中,從而實現不同模態數據的統一處理。透過利用不同模態資料的優勢,可以得到比單一模態資料更為準確的感知結果。 現在,我們已經可以部署在車上的多模態感知演算法模型輸出更穩健且準確的空間感知結果,透過精確的空間感知結果,可以為自動駕駛功能的實現提供更可靠和安全的保障。
雖然最近在學術界和工業界提出了許多基於Transformer網路框架的多感測、多模態資料融合的3D感知演算法,但均採用了Transformer中的交叉注意力機制來實現多模態資料之間的融合,以實現比較理想的3D目標偵測結果。但是這類多模態的特徵融合方法並不完全適用於基於BEV空間的語意分割任務。此外,除了採用交叉注意力機制來完成不同模態之間資訊融合的方法外,許多演算法採用基於LSA中前向向量轉換方式來建構融合後的特徵,但也存在如下的一些問題:(限制字數,接下來進行具體描述)。
- 由於目前提出的相關多模態融合的3D感知演算法,對於不同模態資料特徵的融合方式設計的還不夠充分,造成感知演算法模型無法準確捕捉感測器資料之間的複雜連結關係,進而影響模型的最終感知性能。
- 不同感測器擷取資料的過程中難免會引入無關的雜訊訊息,這種不同模態之間的內在噪聲,也會導致不同模態特徵融合的過程中會混入噪聲,造成多模態特徵融合的不準確,影響後續的知覺任務。
針對上述提到的在多模態融合過程中存在的諸多可能會影響到最終模型感知能力的問題,同時考慮到生成模型最近展現出來的強大性能,我們對生成模型進行了探索,用於實現多感測器之間的多模態融合和去雜訊任務。基於此,我們提出了一種基於條件擴散的生成模型感知演算法DifFUSER,用於實現多模態的感知任務。透過下圖可以看出,我們提出的DifFUSER多模態資料融合演算法可以實現更有效的多模態融合過程。  DifFUSER多模態資料融合演算法可以實現更有效的多模態融合過程,方法主要包括兩個階段。首先,我們使用生成模型對輸入資料進行降噪和增強,產生乾淨且豐富的多模態資料。然後,利用生成模型產生的資料進行多模態融合,達到更好的感知效果。 透過DifFUSER演算法的實驗結果顯示,我們提出的多模態資料融合演算法可以實現更有效的多模態融合過程。此演算法在實現多模態感知任務時,能夠實現更有效的多模態融合過程,提升模型的感知能力。此外,此演算法的多模態資料融合演算法可以實現更有效的多模態融合過程。總而言之
提出的演算法模型與其它演算法模型的結果視覺化對比圖
論文連結:https://arxiv.org/pdf/2404.04629. pdf
網路模型的整體架構&細節梳理
"DifFUSER演算法的模組細節,基於條件擴散模型的多任務感知演算法"是一種用於解決任務感知問題的演算法。下圖展示了我們提出的DifFUSER演算法的整體網路結構。 在這個模組中,我們提出了一種基於條件擴散模型的多任務感知演算法,用於解決任務感知問題。該演算法的目標是透過在網路中傳播和聚合任務特定的資訊來提高多任務學習的效能。 DifFUSER演算法的整
 提出的DifFUSER感知演算法模型網絡結構圖
提出的DifFUSER感知演算法模型網絡結構圖
透過上圖可以看出,我們提出的DifFUSER網絡結構主要包括三個子網絡,分別是主幹網絡部分、DifFUSER的多模態資料融合部分以及最終的BEV語意分割任務頭部分。 3D目標偵測感知任務頭部分。 在主幹網路部分,我們使用了現有的深度學習網路架構,如ResNet或VGG等,透過提取輸入資料的高級特徵。 DifFUSER的多模態資料融合部分使用了多個並行的分支,每個分支用於處理不同的感測器資料類型(如影像、雷射雷達和雷達等)。每個分支都有自
- 主幹網路部分:此部分主要對網路模型輸入的2D影像資料以及3D的光達點雲資料進行特徵擷取用於輸出相對應的BEV語意特徵。對於擷取影像特徵的主幹網路而言,主要包括2D的影像主幹網路以及視角轉換模組。對於提取3D的雷射雷達點雲特徵的主幹網路而言,主要包括3D的點雲主幹網路以及特徵Flatten模組。
- DifFUSER多模態資料融合部分:我們提出的DifFUSER模組以層級的雙向特徵金字塔網絡的形式連結在一起,我們把這樣的結構稱為cMini-BiFPN。該結構為潛在的擴散提供了可以替代的結構,可以更好的處理來自不同感測器資料中的多尺度和寬高詳細特徵資訊。
- BEV語意分割、3D目標偵測感知任務頭部分:由於我們的演算法模型可以同時輸出3D目標偵測結果以及BEV空間的語意分割結果,所以3D感知任務頭包括3D檢測頭以及語意分割頭。此外,我們提出的演算法模型涉及的損失則包括擴散損失、偵測損失和語意分割損失,透過將所有損失進行求和,並透過反向傳播的方式來更新網路模型的參數。
接下來,我們會仔細介紹模型中各個主要子部分的實作細節。
融合架構設計(Conditional-Mini-BiFPN,cMini-BiFPN)
對於自動駕駛系統中的感知任務而言,演算法模型能夠對當前的外部環境進行即時的感知是至關重要的,所以確保擴散模組的性能和效率是非常重要的。因此,我們從雙向特徵金字塔網路中得到啟發,引入一種條件類似的BiFPN擴散架構,我們稱之為Conditional-Mini-BiFPN,其具體的網路結構如上圖所示。


漸進感測器Dropout訓練(PSDT)
對於一輛自動駕駛汽車而言,配備的自動駕駛採集感測器的性能至關重要,在自動駕駛車輛日常行駛的過程中,極有可能會出現相機感測器或光達感測器出現遮蔽或故障的問題,從而影響最終自動駕駛系統的安全性以及運作效率。基於這個考慮出發,我們提出了漸進式的感測器Dropout訓練範式,用於增強提出的演算法模型在感測器可能被遮蔽等情況下的穩健性和適應性。
透過我們提出的漸進感測器Dropout訓練範式,可以使得演算法模型透過利用相機感測器以及雷射雷達感測器擷取到的兩種模態資料的分佈,重建缺失的特徵,從而實現了在惡劣狀況下的出色適應性和魯棒性。具體而言,我們利用來自影像資料和光達點雲資料的特徵,以三種不同的方式進行使用,分別是作為訓練目標、擴散模組的雜訊輸入以及模擬感測器遺失或故障的條件,為了模擬感測器遺失或故障的條件,我們在訓練期間逐漸將相機感測器或光達感測器輸入的遺失率從0增加到預先定義的最大值a=25。整個過程可以用下面的公式來表示:
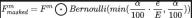
其中,代表目前模型所處的訓練輪數,透過定義dropout的機率用於表示特徵中每個特徵被丟棄的機率。透過這種漸進式的訓練過程,不僅訓練模型有效去噪並產生更具有表現力的特徵,而且還最大限度地減少其對任何單一感測器的依賴,從而增強其處理具有更大彈性的不完整感測器數據的能力。
閘控自條件調變擴散模組(GSM Diffusion Module)

#具體而言,閘控自條件調變擴散模組的網路結構如下圖所示

門控自條件調變擴散模組網路結構示意圖

實驗結果&評估指標
定量分析部分
為了驗證我們提出的演算法模型DifFUSER在多任務上的感知結果,我們主要在nuScenes數據集上進行了3D目標偵測以及基於BEV空間的語意分割實驗。
首先,我們比較了所提出的演算法模型DifFUSER與其它的多模態融合演算法在語意分割任務上的效能比較情況,具體的實驗結果如下表所示:
 不同演算法模型在nuScenes資料集上的基於BEV空間的語意分割任務的實驗結果對比情況
不同演算法模型在nuScenes資料集上的基於BEV空間的語意分割任務的實驗結果對比情況
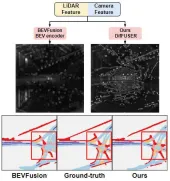
透過實驗結果可以看出,我們提出的演算法模型相比於基準模型而言在效能上有著顯著的提高。具體而言,BEVFusion模型的mIoU值只有62.7%,而我們提出的演算法模型已經達到了69.1%,具有6.4%個點的提升,這表明我們提出的演算法在不同類別上都更有優勢。此外,下圖也更直觀的說明了我們提出的演算法模型更具優勢。具體而言,BEVFusion演算法會輸出較差的分割結果,尤其在遠距離的場景下,感測器錯位的情況更加明顯。與之相比,我們的演算法模型具有更準確的分割結果,細節更加明顯,雜訊更少。

提出演算法模型與基準模型的分割視覺化結果比較
此外,我們也將提出的演算法模型與其它的3D目標偵測演算法模型進行對比,具體的實驗結果如下表所示

不同演算法模型在nuScenes資料集上的3D目標偵測任務的實驗結果對比情況
通過表格當中列出的結果可以看出,我們提出的演算法模型DifFUSER相比於基線模型在NDS和mAP指標上均有提高,相比於基線模型BEVFusion的72.9%NDS以及70.2%的mAP,我們的演算法模型分別高出1.8%以及1.0%。相關指標的提升表明,我們提出的多模態擴散融合模組對特徵的減少和特徵的細化過程是有效的。
此外,為了表明我們提出的演算法模型在感測器故障或遮蔽情況下的感知穩健性,我們進行了相關分割任務的結果比較,如下圖所示。

不同情況下的演算法效能比較
透過上圖可以看出,在取樣充足的情況下,我們提出的演算法模型可以有效的對缺失特徵進行補償,用於作為缺失感測器擷取資訊的替代內容。我們提出的DifFUSER演算法模型產生和利用合成特徵的能力,有效地減輕了對任何單一感測器模態的依賴,確保模型在多樣化和具有挑戰性的環境中能夠平穩運行。
定性分析部分
下圖展示了我們提出的DifFUSER演算法模型在3D目標偵測以及BEV空間的語意分割結果的可視化,透過視覺化結果可以看出,我們提出的演算法模型具有很好的檢測和分割效果。

結論
本文提出了一個基於擴散模型的多模態感知演算法模型DifFUSER,透過改進網路模型的融合架構以及利用擴散模型的去噪特性來提高網路模型的融合品質。透過在Nuscenes資料集上的實驗結果表明,我們提出的演算法模型在BEV空間的語義分割任務中實現了SOTA的分割性能,在3D目標檢測任務中可以和當前SOTA的演算法模型取得相近的檢測性能。
以上是超越BEVFusion! DifFUSER:擴散模型殺入自動駕駛多任務(BEV分割+偵測雙SOTA)的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 在LLMS中調用工具Apr 14, 2025 am 11:28 AM
在LLMS中調用工具Apr 14, 2025 am 11:28 AM大型語言模型(LLMS)的流行激增,工具稱呼功能極大地擴展了其功能,而不是簡單的文本生成。 現在,LLM可以處理複雜的自動化任務,例如Dynamic UI創建和自主a
 多動症遊戲,健康工具和AI聊天機器人如何改變全球健康Apr 14, 2025 am 11:27 AM
多動症遊戲,健康工具和AI聊天機器人如何改變全球健康Apr 14, 2025 am 11:27 AM視頻遊戲可以緩解焦慮,建立焦點或支持多動症的孩子嗎? 隨著醫療保健在全球範圍內挑戰,尤其是在青年中的挑戰,創新者正在轉向一種不太可能的工具:視頻遊戲。現在是世界上最大的娛樂印度河之一
 沒有關於AI的投入:獲勝者,失敗者和機遇Apr 14, 2025 am 11:25 AM
沒有關於AI的投入:獲勝者,失敗者和機遇Apr 14, 2025 am 11:25 AM“歷史表明,儘管技術進步推動了經濟增長,但它並不能自行確保公平的收入分配或促進包容性人類發展,”烏托德秘書長Rebeca Grynspan在序言中寫道。
 通過生成AI學習談判技巧Apr 14, 2025 am 11:23 AM
通過生成AI學習談判技巧Apr 14, 2025 am 11:23 AM易於使用,使用生成的AI作為您的談判導師和陪練夥伴。 讓我們來談談。 對創新AI突破的這種分析是我正在進行的《福布斯》列的最新覆蓋範圍的一部分,包括識別和解釋
 泰德(Ted)從Openai,Google,Meta透露出庭,與我自己自拍Apr 14, 2025 am 11:22 AM
泰德(Ted)從Openai,Google,Meta透露出庭,與我自己自拍Apr 14, 2025 am 11:22 AM在溫哥華舉行的TED2025會議昨天在4月11日舉行了第36版。它的特色是來自60多個國家 /地區的80個發言人,包括Sam Altman,Eric Schmidt和Palmer Luckey。泰德(Ted)的主題“人類重新構想”是量身定制的
 約瑟夫·斯蒂格利茲(Joseph StiglitzApr 14, 2025 am 11:21 AM
約瑟夫·斯蒂格利茲(Joseph StiglitzApr 14, 2025 am 11:21 AM約瑟夫·斯蒂格利茨(Joseph Stiglitz)是2001年著名的經濟學家,是諾貝爾經濟獎的獲得者。斯蒂格利茨認為,AI可能會使現有的不平等和合併權力惡化,並在一些主導公司手中加劇,最終破壞了經濟上的經濟。
 什麼是圖形數據庫?Apr 14, 2025 am 11:19 AM
什麼是圖形數據庫?Apr 14, 2025 am 11:19 AM圖數據庫:通過關係徹底改變數據管理 隨著數據的擴展及其特徵在各個字段中的發展,圖形數據庫正在作為管理互連數據的變革解決方案的出現。與傳統不同
 LLM路由:策略,技術和Python實施Apr 14, 2025 am 11:14 AM
LLM路由:策略,技術和Python實施Apr 14, 2025 am 11:14 AM大型語言模型(LLM)路由:通過智能任務分配優化性能 LLM的快速發展的景觀呈現出各種各樣的模型,每個模型都具有獨特的優勢和劣勢。 有些在創意內容gen上表現出色


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Dreamweaver CS6
視覺化網頁開發工具

VSCode Windows 64位元 下載
微軟推出的免費、功能強大的一款IDE編輯器

Dreamweaver Mac版
視覺化網頁開發工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

SAP NetWeaver Server Adapter for Eclipse
將Eclipse與SAP NetWeaver應用伺服器整合。

