
一文總結擴散模型(Diffusion Model)在時間序列中的應用

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2024-03-07 10:30:041334瀏覽
擴散模型是目前生成式AI中最核心的模組,在Sora、DALL-E、Imagen等生成式AI大模型中都取得了廣泛的應用。同時,擴散模型也被越來越多的應用到了時間序列中。這篇文章為大家介紹了擴散模型的基本思路,以及幾篇擴散模型用於時間序列的典型工作,帶你理解擴散模型在時間序列中的應用原理。

1.擴散模型建模想法
生成模型的核心是,能夠從隨機簡單分佈中取樣一個點,並透過一系列變換將這個點映射到目標空間的圖像或樣本上。擴散模型的做法是,在取樣的樣本點上,不斷的去噪聲,經過多個去除噪聲的步驟,產生最終的資料。這個過程很像雕塑的過程,一開始從高斯分佈取樣的雜訊就是最開始的原料,去雜訊的過程就是不斷在這個材料上鑿掉多餘部分的過程。
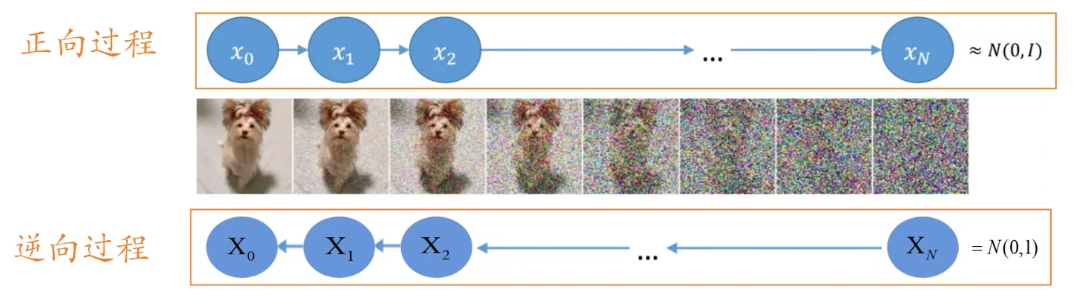
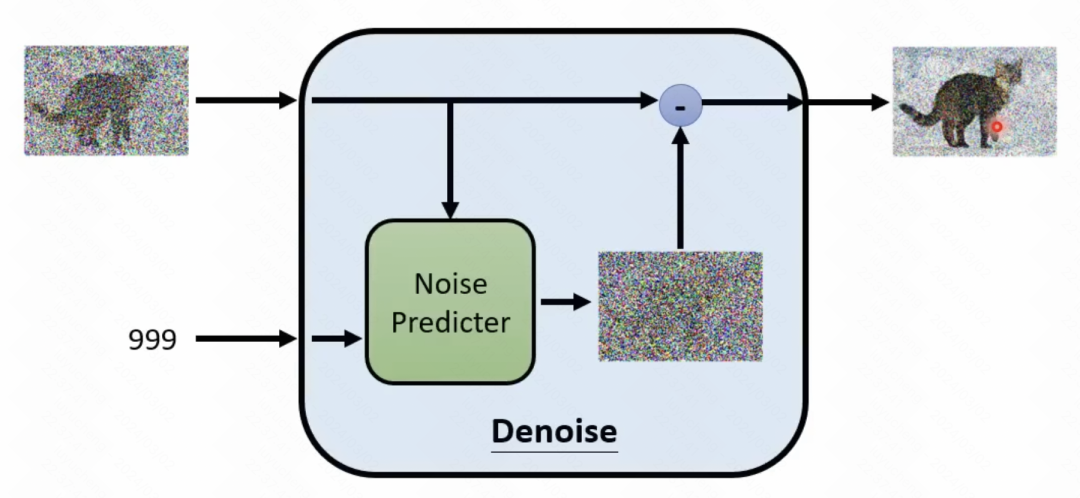
上面所說的就是逆向過程,也就是從一個噪聲中逐漸去掉噪聲,得到圖像。這個過程是一個迭代的過程,要經歷T次的去噪,一點點從原始取樣點中把雜訊去掉。在每個步驟中,輸入上一個步驟產生的結果,並且需要預測噪聲,再用輸入減去噪聲,得到當前時間步的輸出。
這裡就需要訓練一個預測目前步驟雜訊的模組(去雜訊模組),這個模組輸入目前的步驟t,以及目前步驟的輸入,預測雜訊是什麼。這個預測雜訊的模組,是透過正向過程進行的,和VAE中的Encoder部分比較像。在正向過程中,輸入一個影像,每個步驟取樣一個噪聲,將雜訊加到原始影像上,得到產生的結果。然後再以產生的結果和目前步驟t的embedding為輸入,預測產生的噪聲,以此達到訓練去噪模組的作用。
2.擴散模型在時間序列中的應用
TimeGrad是最早採用擴散模型進行時間序列預測的方法之一。與傳統擴散模型不同的是,TimeGrad在基礎擴散模型的基礎上引入了一個去噪模組,並為每個時間步額外提供了一個隱藏狀態。這個隱藏狀態是透過RNN模型對歷史序列和外部變數進行編碼得到的,用來指導擴散模型產生序列。總體邏輯如下圖所示。
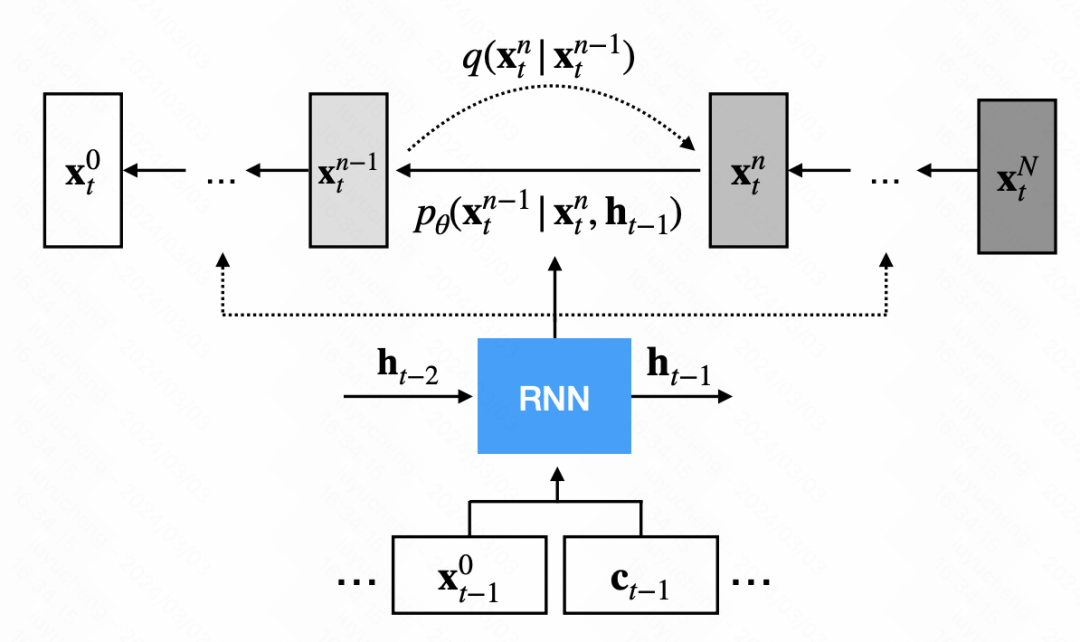
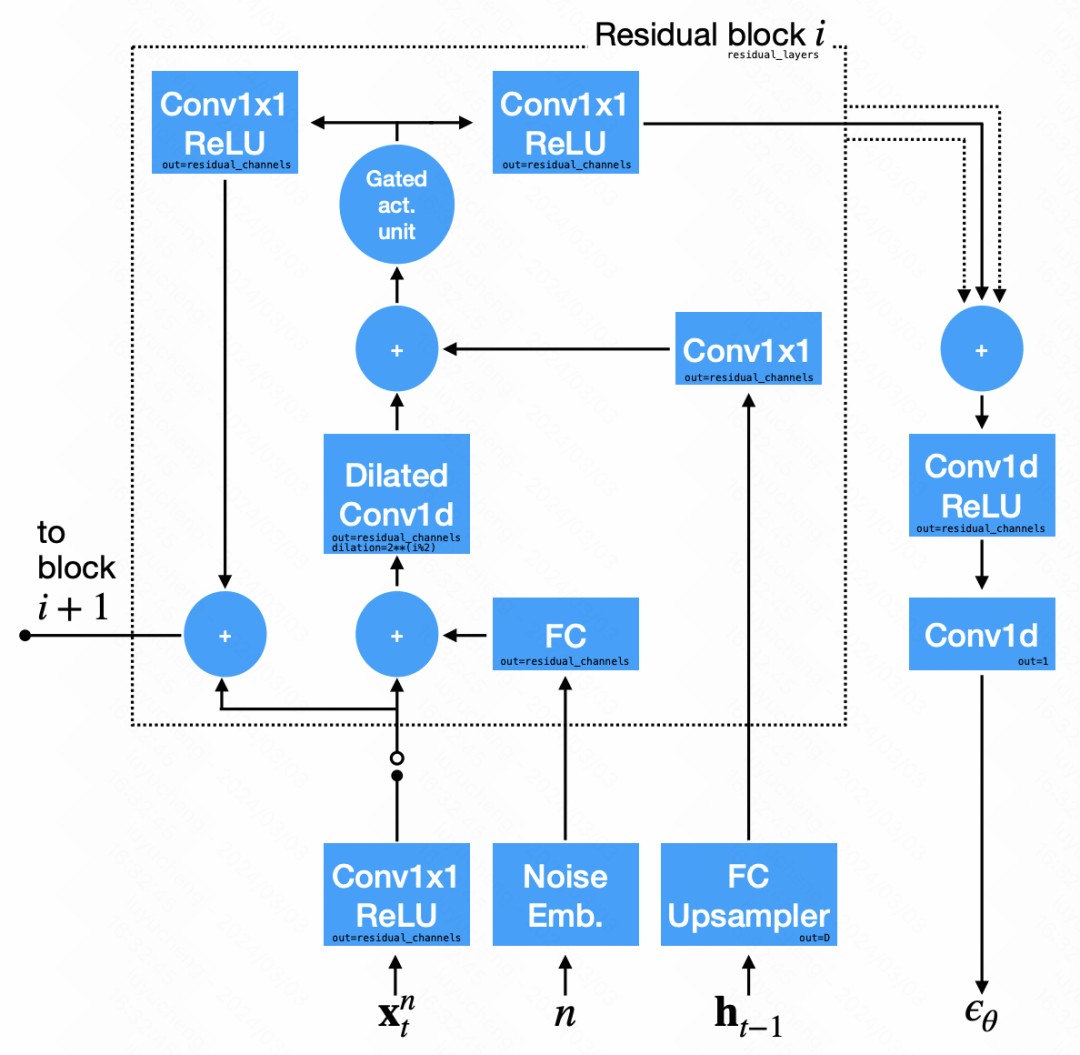
在去雜訊模組的網路結構中,主要運用了卷積神經網路。輸入訊號分為兩部分:第一部分是上一個步驟的輸出序列,第二部分是RNN輸出的隱藏狀態,經過上取樣後得到的結果。這兩部分分別經過卷積處理後相加,用於雜訊的預測。
這篇文章使用擴散模型建立模時間序列填充任務,整體建模方式和TimeGrad比較像。如下圖所示,最開始時間序列是有缺失值的,首先對其填充上噪聲,然後使用擴散模型逐漸預測噪聲實現去噪,經過多個步驟後最終得到填充結果。
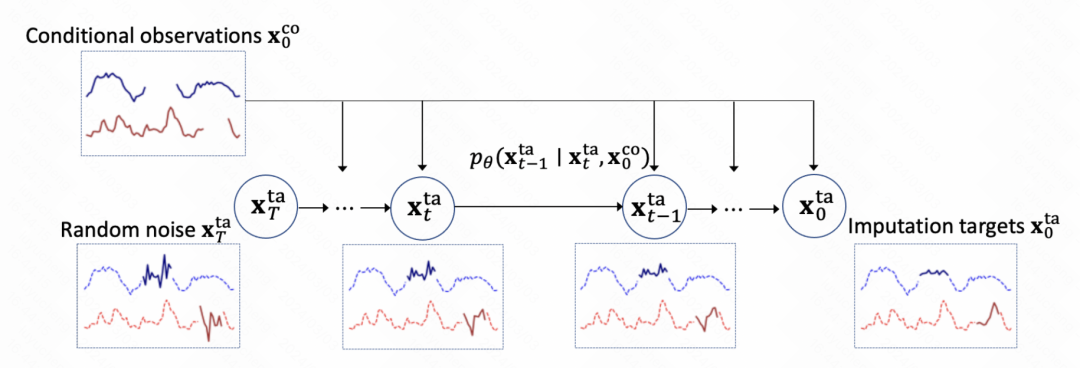
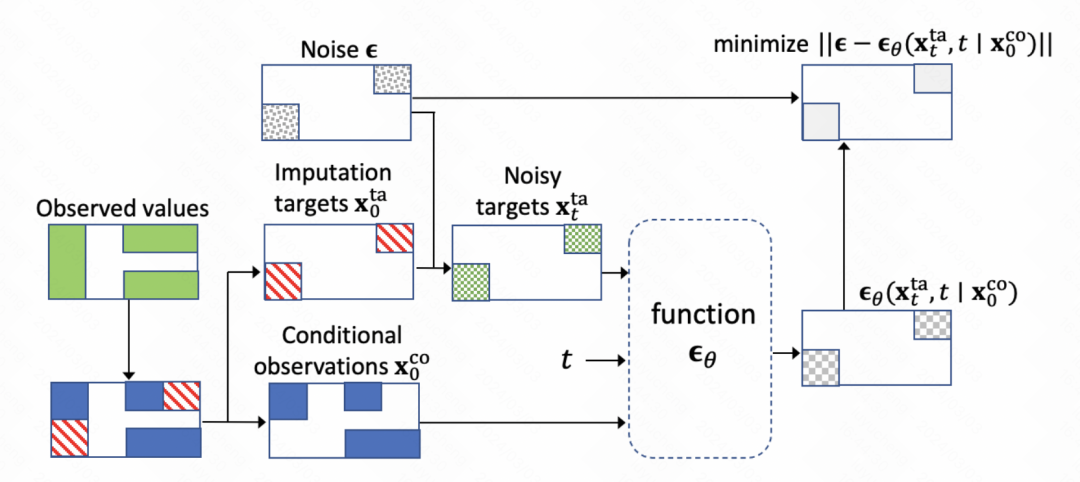
整個模型的核心也是擴散模型訓練去噪模組。核心是訓練噪音預測網絡,每個步驟輸入當前的步驟embedding、歷史的觀測結果以及上一個時刻的輸出,預測噪音結果。
網路結構上使用Transformer,包含時間維度上的Transformer和變數維度的Transformer兩個部分。

本文提出的方法相比TimeGrad上升了一個層次,是透過擴散模型直接建模產生時間序列的函數本身。這裡假設每一個觀測點都是從一個函數產生的,然後直接建模這個函數的分佈,而不是建模時間序列中資料點的分佈。因此,文中將擴散模型中添加的獨立噪聲改成隨時間變化的噪聲,並訓練擴散模型中的去噪模組實現對函數的去噪。
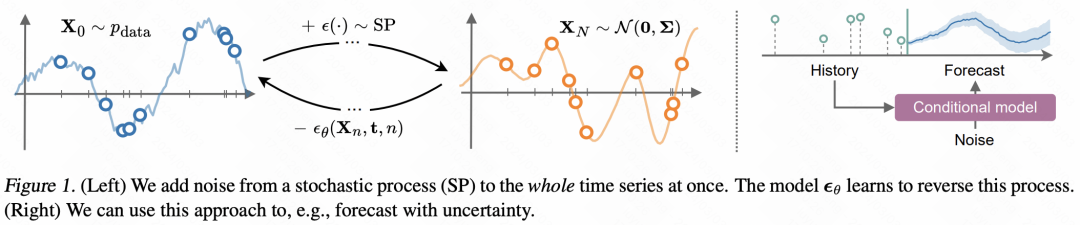
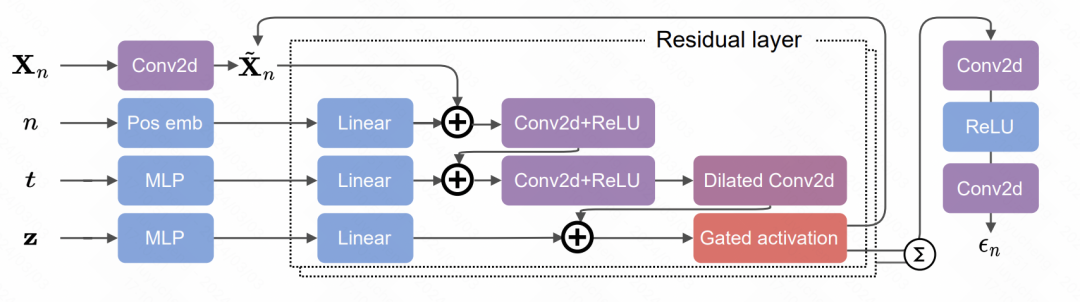
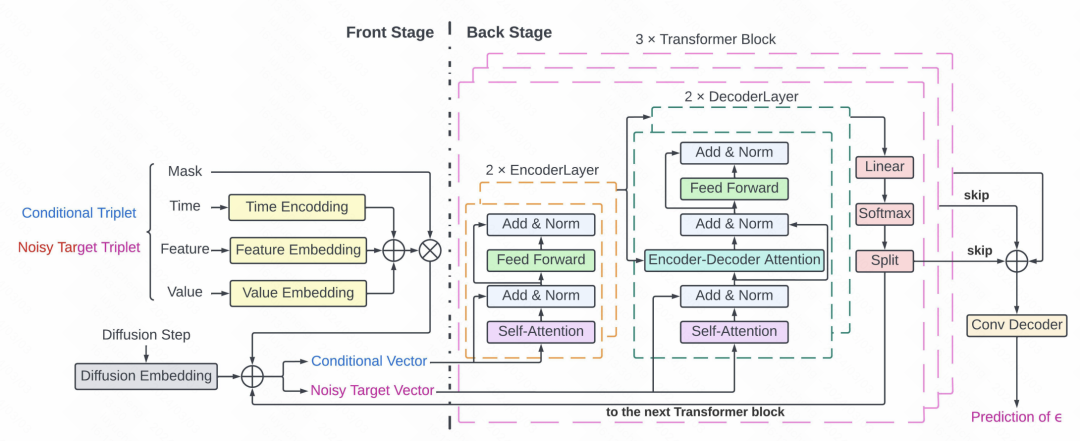
#這篇文章將擴散模型應用到ICU中的關鍵訊號擷取。文中的核心一方面是對於稀疏不規則的醫療時序資料的處理,使用value、feature、time三元組表示序列中的每個點,對確實值部分使用mask。另一方面是基於Transformer和擴散模型的預測方法。整體的擴散模型過程如圖,跟影像的生成模型原理是類似的,根據歷史的時間序列訓練去雜訊模型,然後在前向傳播中逐漸從初始雜訊序列中減掉雜訊。

具體的擴散模型中雜訊預測的部分所採用的是Transformer結構。每個時間點由mask以及三元組組成,輸入到Transformer中,作為去噪模組預測雜訊。詳細結構包括3層Transformer,每個Transformer包括2層Encoder和2層Decoder網絡,Decoder的輸出使用殘差網絡連接,並輸入到卷積Decoder產生噪聲預測結果。
以上是一文總結擴散模型(Diffusion Model)在時間序列中的應用的詳細內容。更多資訊請關注PHP中文網其他相關文章!