
不如GAN! Google、DeepMind等發文:擴散模型直接從訓練集「抄」

- PHPz轉載
- 2023-04-16 14:10:031333瀏覽
去年,影像生成模型大火,在一場大眾藝術狂歡後,接踵而來的還有版權問題。
類似DALL-E 2, Imagen和Stable Diffusion等深度學習模型的訓練都是在上億的資料上進行訓練的,根本無法擺脫訓練集的影響,但是否某些生成的圖像就完全來自於訓練集? 如果生成影像與原圖十分類似的話,其版權又歸誰所有?
最近來自Google、Deepmind、蘇黎世聯邦理工學院等多所知名大學和企業的研究人員們聯合發表了一篇論文,他們發現擴散模型確實可以記住訓練集的樣本,並在生成過程中進行複現。

論文連結:https://arxiv.org/abs/2301.13188
在這項工作中,研究人員展示了擴散模型如何在其訓練資料中記憶單一影像,並在生成時將其重新復現出來。

文中提出一個產生和過濾(generate-and-filter)的pipeline,從最先進的模型中提取了一千多個訓練實例,涵蓋範圍包含人物的照片、商標的公司標誌等等。並且還在不同的環境中訓練了數百個擴散模型,以分析不同的建模和資料決定如何影響隱私。
總的來說,實驗結果顯示,擴散模型對訓練集的隱私保護比之前的生成模型(如GANs)要差得多。
記了,但記得不多
去噪擴散模型(denoising diffusion model)是近期興起的新型生成式神經網絡,透過迭代去噪的過程從訓練分佈中生成圖像,比之前常用的GAN或VAE模型生成效果更好,並且更容易擴展模型和控制圖像生成,所以也迅速成為了各種高分辨率圖像生成的主流方法。
尤其是OpenAI發布DALL-E 2之後,擴散模型迅速火爆了整個AI生成領域。
生成式擴散模型的吸引力源於其合成表面上與訓練集中的任何東西都不同的新圖像的能力,事實上,過去的大規模訓練工作「沒有發現過擬合的問題」,而隱私敏感領域(privacy sensitive domain)的研究人員甚至提出,擴散模型可以透過合成影像來「保護真實影像的隱私」。
不過這些工作都依賴於一個假設:即擴散模型不會記憶並再次產生訓練資料,否則就會違反隱私保證,並引起諸多關於模型泛化和數位偽造(digital forgery)的問題。

但事實果真如此嗎?
要想判斷產生的影像是否來自於訓練集,首先需要定義什麼是「記憶」(memorization)。
先前的相關工作主要集中在文字語言模型上,如果模型能夠逐字從訓練集中恢復一個逐字記錄的序列,那麼這個序列就被稱為「提取」和「記憶」了;但因為這項工作是基於高解析度的圖像,所以逐字逐句匹配的記憶定義並不適合。
以下是研究者定義的一個基於影像相似性測量的記憶。
如果一個產生的圖像x,並且與訓練集中多個樣本之間的距離(distance)小於給定閾值,那麼該樣本就被視為從訓練集中得到的,即Eidetic Memorization.
#然後,文中設計了一個兩階段的資料抽取攻擊(data extraction attack)方法:
##1 . 產生大量圖像
第一步雖然很簡單,但計算成本很高:使用選定的prompt作為輸入,以黑盒子的方式產生圖像。
研究人員為每個文字提示產生500張候選圖像以增加發現記憶的幾率。
2. 進行Membership Inference
把那些疑似是根據訓練集記憶生成的圖像標記出來。
研究人員設計的成員推理攻擊策略基於以下想法:對於兩個不同的隨機初始種子,擴散模型產生的兩張圖像相似機率會很大,並且有可能在距離測量下被認為是根據記憶產生的。
抽取結果為了評估攻擊效果,研究人員從訓練資料集中選擇了35萬個重複率最高的例子,並為每個提示產生500張候選圖像(總共生成了1.75億張圖像)。
首先對所有這些生成的圖像進行排序,透過在團(clique)中的圖像之間的平均距離來識別那些可能透過記憶訓練資料生成的圖像。
然後把這些生成的圖像與訓練圖像進行比較,將每張圖像標註為“extracted”和“not extracted”,最終發現了94張疑似從訓練集中抽取的圖像。
透過視覺分析,將排名top 1000的圖片手動標註為「memorized」或「not memorized」,其中發現還有13張圖片是透過複製訓練樣本產生的。
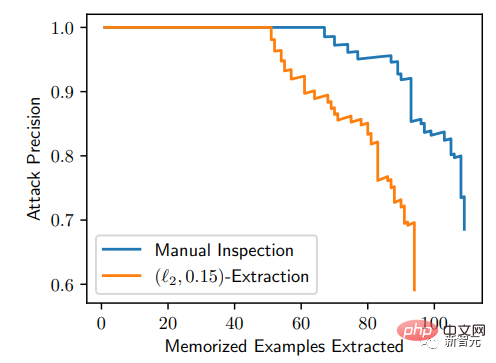
從P-R曲線來看,這種攻擊方式是非常精確的:在1.75億張產生的影像中,可以辨識出50張被記住的圖像,而假陽性率為0;並且所有根據記憶生成的圖像都可以被提取出來,精確度高於50%
為了更好地理解記憶是如何以及為什麼會發生的,研究人員還在CIFAR10上訓練了數百個較小擴散模型,以分析模型精確度、超參數、增強和重複資料刪除對隱私的影響。

與擴散模型不同的是,GANs並沒有明確地被訓練來記憶和重建其訓練資料集。
GANs由兩個相互競爭的神經網路組成:一個生成器和一個判別器。生成器同樣接收隨機雜訊作為輸入,但與擴散模型不同的是,它必須在一次前向傳遞中將這種雜訊轉換成有效影像。在
訓練GAN的過程中,判別器需要預測影像是否來自於生成器,而生成器需要提升自己以欺騙判別器。
因此,二者的不同之處在於,GAN的生成器只使用關於訓練資料的間接資訊進行訓練(即使用來自判別器的梯度),並沒有直接接收訓練資料作為輸入。

不同的預訓練產生模型中抽取的100萬個無條件產生的訓練影像,然後按FID排序的GAN模型(越低越好)放在上面,把擴散模型放在下面。
結果顯示,擴散模型比GAN模型記憶得更多,更好的生成模型(較低的FID)往往能記住更多的數據,也就是說,擴散模型是最不隱私的圖像模型形式,其洩漏的訓練資料是GANs的兩倍以上。

並且從上面的結果還可以發現,現有的隱私增強技術並不能提供一個可接受的隱私-效能權衡,想提高生成質量,就需要記住更多訓練集中的數據。

總的來說,這篇論文強調了日益強大的生成模型和資料隱私之間的矛盾,並提出了關於擴散模型如何運作以及如何負責任地部署它們的問題。
版權問題
從技術上來講,重建(reconstruction)正是擴散模型的優勢;但從版權上來說,重建就是軟肋。
由於擴散模型產生的圖像與訓練資料之間的過於相似,藝術家們對自己的版權問題進行了各種爭論。
例如禁止AI使用自己的作品進行訓練,發布的作品添加大量水印等等;並且Stable Diffusion也已經宣布,它計劃下一步只使用包含已授權內容的訓練數據集,並提供了一個藝術家退出機制。
在NLP領域同樣面臨這個問題,有網友表示自1993年以來已經發布了數百萬字的文本,而包括ChatGPT-3等所有AI都是在「被偷走的內容」上訓練的,使用基於AI的生成模式都是不道德的。
雖然天下文章一大抄,但對一般人來說,抄襲只是一種可有可無的捷徑;而對創造者來說,被抄襲的內容卻是他們的心血。
在未來,擴散模型還會有優勢嗎?
以上是不如GAN! Google、DeepMind等發文:擴散模型直接從訓練集「抄」的詳細內容。更多資訊請關注PHP中文網其他相關文章!