



在自然語言生成任務中,取樣方法是從生成模型中獲得文字輸出的一種技術。這篇文章將討論5種常用方法,並使用PyTorch進行實作。
1、Greedy Decoding
在貪婪解碼中,產生模型根據輸入序列逐個時間步驟預測輸出序列的單字。在每個時間步,模型會計算每個單字的條件機率分佈,然後選擇具有最高條件機率的單字作為當前時間步的輸出。這個單字成為下一個時間步的輸入,生成過程會持續直到滿足某種終止條件,例如產生了指定長度的序列或產生了特殊的結束標記。 Greedy Decoding的特點是每次選擇當前條件機率最高的單字作為輸出,而不考慮全局最優解。這種方法簡單且高效,但可能導致產生的序列不夠準確或多樣化。 Greedy Decoding適用於一些簡單的序列生成任務,但對於複雜任務,可能需要使用更複雜的解碼策略來提高生成品質。
儘管這種方法計算速度較快,但由於貪婪解碼只關注局部最優解,可能導致生成的文本缺乏多樣性或不準確,無法獲得全局最優解。
雖然貪婪解碼有其局限性,但在許多序列生成任務中仍然被廣泛使用,尤其是在需要快速執行或任務相對簡單的情況下。
def greedy_decoding(input_ids, max_tokens=300): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] next_token = torch.argmax(next_token_logits, dim=-1) if next_token == tokenizer.eos_token_id: break input_ids = torch.cat([input_ids, rearrange(next_token, 'c -> 1 c')], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
2、Beam Search
束搜尋(Beam Search)是貪婪解碼的擴展,透過在每個時間步驟保留多個候選序列來克服貪婪解碼的局部最優問題。
束搜尋是一種生成文字的方法,它在每個時間步保留機率最高的候選詞語,然後在下一個時間步驟基於這些候選詞語繼續擴展,直到生成結束。這種方法透過考慮多個候選詞語路徑,可以提高生成文字的多樣性。
在束搜尋中,模型會同時產生多個候選序列,而不是只選擇一個最佳序列。它根據目前已產生的部分序列和隱藏狀態,預測下一個時間步可能的詞語,並計算每個詞語的條件機率分佈。這種並行產生多個候選序列的方法有助於提高搜尋效率,使得模型能夠更快找到整體機率最高的序列。
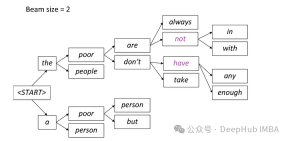
在每個步驟中,只保留兩條最有可能的路徑,根據beam = 2的設置,其餘路徑被丟棄。這個過程會持續,直到滿足停止條件,可以是產生序列結束令牌或達到模型設定的最大序列長度。最終輸出將是最後一組路徑中具有最高總體機率的序列。
from einops import rearrange import torch.nn.functional as F def beam_search(input_ids, max_tokens=100, beam_size=2): beam_scores = torch.zeros(beam_size).to(device) beam_sequences = input_ids.clone() active_beams = torch.ones(beam_size, dtype=torch.bool) for step in range(max_tokens): outputs = model(beam_sequences) logits = outputs.logits[:, -1, :] probs = F.softmax(logits, dim=-1) top_scores, top_indices = torch.topk(probs.flatten(), k=beam_size, sorted=False) beam_indices = top_indices // probs.shape[-1] token_indices = top_indices % probs.shape[-1] beam_sequences = torch.cat([ beam_sequences[beam_indices], token_indices.unsqueeze(-1)], dim=-1) beam_scores = top_scores active_beams = ~(token_indices == tokenizer.eos_token_id) if not active_beams.any(): print("no active beams") break best_beam = beam_scores.argmax() best_sequence = beam_sequences[best_beam] generated_text = tokenizer.decode(best_sequence) return generated_text3、Temperature Sampling
溫度參數取樣(Temperature Sampling)常用於基於機率的生成模型,如語言模型。它透過引入一個稱為「溫度」(Temperature)的參數來調整模型輸出的機率分佈,從而控制生成文字的多樣性。
在溫度參數取樣中,模型在每個時間步驟產生字詞時,會計算出字詞的條件機率分佈。然後模型將這個條件機率分佈中的每個字詞的機率值除以溫度參數,對結果進行歸一化處理,以獲得新的歸一化機率分佈。較高的溫度值會使機率分佈更平滑,從而增加生成文字的多樣性。低機率的詞語也有較高的可能性被選擇;而較低的溫度值則會使機率分佈更集中,更傾向於選擇高機率的詞語,因此生成的文本更加確定性。最後模型根據這個新的歸一化機率分佈進行隨機取樣,選擇產生的詞語。
import torch import torch.nn.functional as F def temperature_sampling(logits, temperature=1.0): logits = logits / temperature probabilities = F.softmax(logits, dim=-1) sampled_token = torch.multinomial(probabilities, 1) return sampled_token.item()
4、Top-K Sampling
Top-K 取樣(在每個時間步選擇條件機率排名前K 的詞語,然後在這K 個詞語中進行隨機採樣。這種方法既能保持一定的生成質量,又能增加文本的多樣性,並且可以通過限制候選詞語的數量來控制生成文本的多樣性。
這個過程使得生成的文本在保持一定的生成品質的同時,也具有一定的多樣性,因為在候選詞語中仍然存在一定的競爭性。
def top_k_sampling(input_ids, max_tokens=100, top_k=50, temperature=1.0):for _ in range(max_tokens): with torch.inference_mode(): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] top_k_logits, top_k_indices = torch.topk(next_token_logits, top_k) top_k_probs = F.softmax(top_k_logits / temperature, dim=-1) next_token_index = torch.multinomial(top_k_probs, num_samples=1) next_token = top_k_indices.gather(-1, next_token_index) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
5、Top-P (Nucleus) Sampling:
Nucleus Sampling(核采样),也被称为Top-p Sampling旨在在保持生成文本质量的同时增加多样性。这种方法可以视作是Top-K Sampling的一种变体,它在每个时间步根据模型输出的概率分布选择概率累积超过给定阈值p的词语集合,然后在这个词语集合中进行随机采样。这种方法会动态调整候选词语的数量,以保持一定的文本多样性。

在Nucleus Sampling中,模型在每个时间步生成词语时,首先按照概率从高到低对词汇表中的所有词语进行排序,然后模型计算累积概率,并找到累积概率超过给定阈值p的最小词语子集,这个子集就是所谓的“核”(nucleus)。模型在这个核中进行随机采样,根据词语的概率分布来选择最终输出的词语。这样做可以保证所选词语的总概率超过了阈值p,同时也保持了一定的多样性。
参数p是Nucleus Sampling中的重要参数,它决定了所选词语的概率总和。p的值会被设置在(0,1]之间,表示词语总概率的一个下界。
Nucleus Sampling 能够保持一定的生成质量,因为它在一定程度上考虑了概率分布。通过选择概率总和超过给定阈值p的词语子集进行随机采样,Nucleus Sampling 能够增加生成文本的多样性。
def top_p_sampling(input_ids, max_tokens=100, top_p=0.95): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] sorted_logits, sorted_indices = torch.sort(next_token_logits, descending=True) sorted_probabilities = F.softmax(sorted_logits, dim=-1) cumulative_probs = torch.cumsum(sorted_probabilities, dim=-1) sorted_indices_to_remove = cumulative_probs > top_p sorted_indices_to_remove[..., 0] = False indices_to_remove = sorted_indices[sorted_indices_to_remove] next_token_logits.scatter_(-1, indices_to_remove[None, :], float('-inf')) probs = F.softmax(next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text总结
自然语言生成任务中,采样方法是非常重要的。选择合适的采样方法可以在一定程度上影响生成文本的质量、多样性和效率。上面介绍的几种采样方法各有特点,适用于不同的应用场景和需求。
贪婪解码是一种简单直接的方法,适用于速度要求较高的情况,但可能导致生成文本缺乏多样性。束搜索通过保留多个候选序列来克服贪婪解码的局部最优问题,生成的文本质量更高,但计算开销较大。Top-K 采样和核采样可以控制生成文本的多样性,适用于需要平衡质量和多样性的场景。温度参数采样则可以根据温度参数灵活调节生成文本的多样性,适用于需要平衡多样性和质量的任务。
以上是自然語言生成任務中的五種採樣方法介紹和Pytorch程式碼實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 在LLMS中調用工具Apr 14, 2025 am 11:28 AM
在LLMS中調用工具Apr 14, 2025 am 11:28 AM大型語言模型(LLMS)的流行激增,工具稱呼功能極大地擴展了其功能,而不是簡單的文本生成。 現在,LLM可以處理複雜的自動化任務,例如Dynamic UI創建和自主a
 多動症遊戲,健康工具和AI聊天機器人如何改變全球健康Apr 14, 2025 am 11:27 AM
多動症遊戲,健康工具和AI聊天機器人如何改變全球健康Apr 14, 2025 am 11:27 AM視頻遊戲可以緩解焦慮,建立焦點或支持多動症的孩子嗎? 隨著醫療保健在全球範圍內挑戰,尤其是在青年中的挑戰,創新者正在轉向一種不太可能的工具:視頻遊戲。現在是世界上最大的娛樂印度河之一
 沒有關於AI的投入:獲勝者,失敗者和機遇Apr 14, 2025 am 11:25 AM
沒有關於AI的投入:獲勝者,失敗者和機遇Apr 14, 2025 am 11:25 AM“歷史表明,儘管技術進步推動了經濟增長,但它並不能自行確保公平的收入分配或促進包容性人類發展,”烏托德秘書長Rebeca Grynspan在序言中寫道。
 通過生成AI學習談判技巧Apr 14, 2025 am 11:23 AM
通過生成AI學習談判技巧Apr 14, 2025 am 11:23 AM易於使用,使用生成的AI作為您的談判導師和陪練夥伴。 讓我們來談談。 對創新AI突破的這種分析是我正在進行的《福布斯》列的最新覆蓋範圍的一部分,包括識別和解釋
 泰德(Ted)從Openai,Google,Meta透露出庭,與我自己自拍Apr 14, 2025 am 11:22 AM
泰德(Ted)從Openai,Google,Meta透露出庭,與我自己自拍Apr 14, 2025 am 11:22 AM在溫哥華舉行的TED2025會議昨天在4月11日舉行了第36版。它的特色是來自60多個國家 /地區的80個發言人,包括Sam Altman,Eric Schmidt和Palmer Luckey。泰德(Ted)的主題“人類重新構想”是量身定制的
 約瑟夫·斯蒂格利茲(Joseph StiglitzApr 14, 2025 am 11:21 AM
約瑟夫·斯蒂格利茲(Joseph StiglitzApr 14, 2025 am 11:21 AM約瑟夫·斯蒂格利茨(Joseph Stiglitz)是2001年著名的經濟學家,是諾貝爾經濟獎的獲得者。斯蒂格利茨認為,AI可能會使現有的不平等和合併權力惡化,並在一些主導公司手中加劇,最終破壞了經濟上的經濟。
 什麼是圖形數據庫?Apr 14, 2025 am 11:19 AM
什麼是圖形數據庫?Apr 14, 2025 am 11:19 AM圖數據庫:通過關係徹底改變數據管理 隨著數據的擴展及其特徵在各個字段中的發展,圖形數據庫正在作為管理互連數據的變革解決方案的出現。與傳統不同
 LLM路由:策略,技術和Python實施Apr 14, 2025 am 11:14 AM
LLM路由:策略,技術和Python實施Apr 14, 2025 am 11:14 AM大型語言模型(LLM)路由:通過智能任務分配優化性能 LLM的快速發展的景觀呈現出各種各樣的模型,每個模型都具有獨特的優勢和劣勢。 有些在創意內容gen上表現出色


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

Dreamweaver Mac版
視覺化網頁開發工具

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

SublimeText3 Linux新版
SublimeText3 Linux最新版

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

