
揭開LLM巫師的魔杖,UIUC華人團隊揭示程式碼資料的三大優勢

- 王林轉載
- 2024-01-29 09:24:16786瀏覽
大模型時代的語言模型(LLM)尺寸和訓練資料都增加了,包括自然語言和程式碼。
程式碼是人類和電腦之間的媒介,將高階目標轉換為可執行的中間步驟。它具有語法標準、邏輯一致、抽象化和模組化的特徵。
伊利諾大學香檳分校的研究團隊最近發布了一篇綜述報告,總結了將程式碼融入LLM訓練資料的多種益處。

論文連結:https://arxiv.org/abs/2401.00812v1
#具體來說,除了可以提升LLM在程式碼產生上的能力外,好處還包括以下三點:
1. 有助於解鎖LLM的推理能力,使能夠應用於一系列更複雜的自然語言任務上;
2. 引導LLM產生結構化且精確的中間步驟,之後可以透過函數呼叫的方式連接到外部執行終端(external execution ends) ;
3. 可以利用程式碼編譯和執行環境為模型的進一步改進提供了更多樣化的回饋訊號。
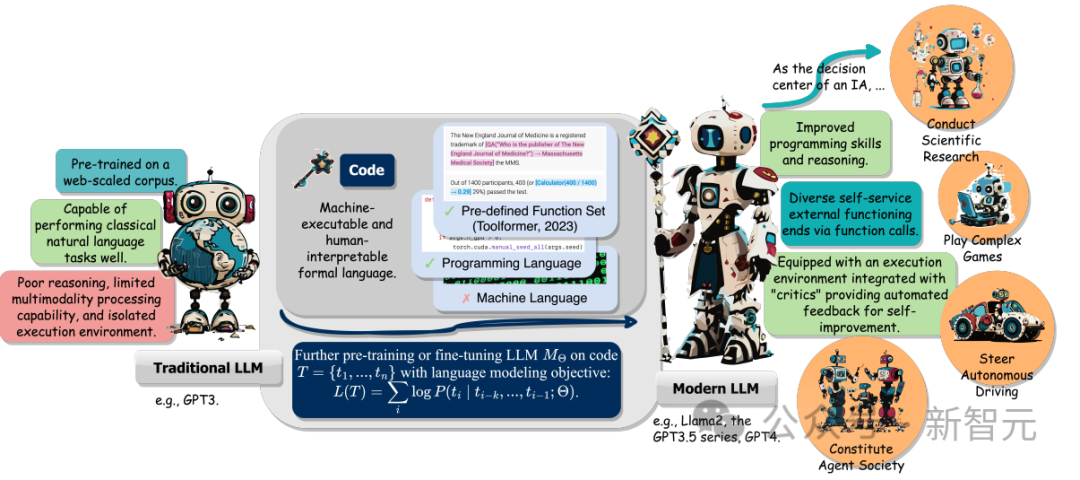
此外,研究人員也追蹤了LLM作為智慧智能體(intelligent agents,IA)時,在理解指令、分解目標、規劃和執行行動(execute actions)以及從回饋中提煉的能力如何在下游任務中起到關鍵作用。
最後,文中也提出了「使用程式碼增強LLM」領域中關鍵的挑戰以及未來的研究方向。
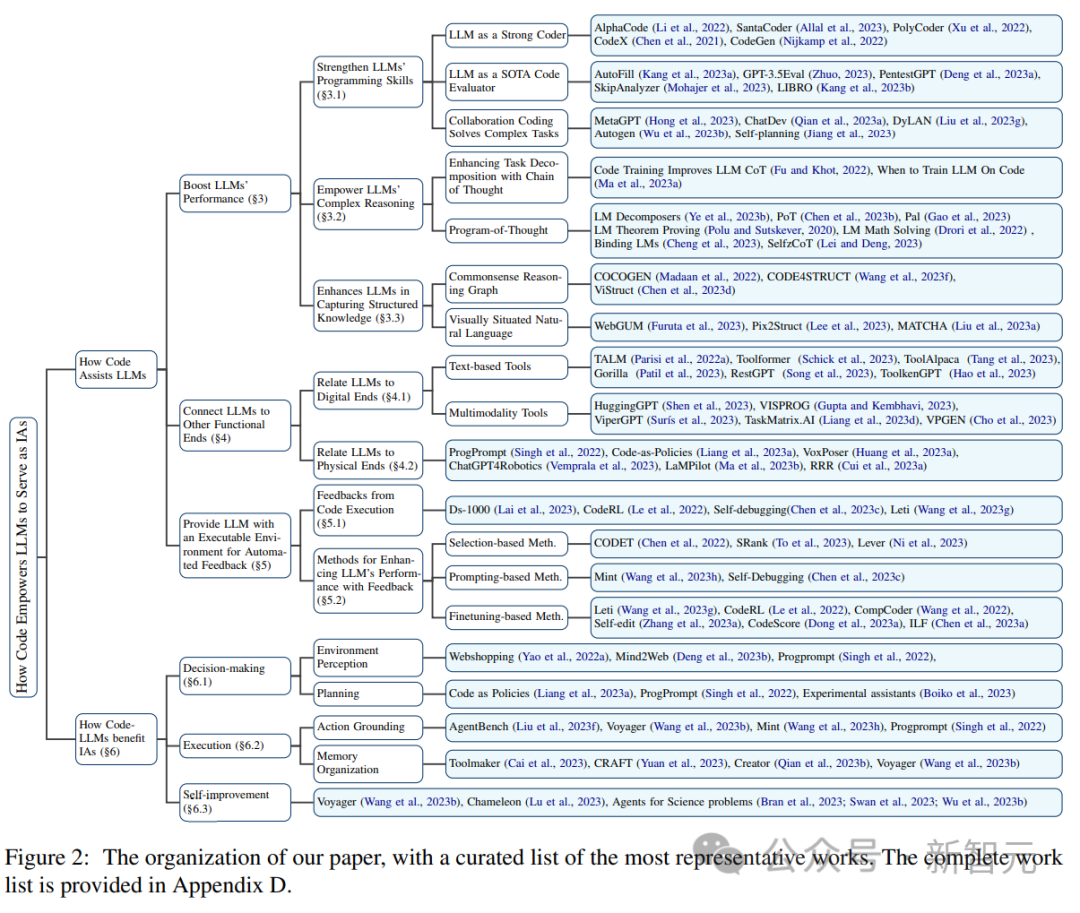
程式碼預訓練提升LLM效能
以OpenAI的GPT Codex 為例,對LLM 進行程式碼預訓練後,可以擴大LLM的任務範圍,除了自然語言處理外,模型還可以為數學理論產生程式碼、執行通用程式設計任務、資料檢索等。
程式碼產生任務有兩個特性:1)程式碼序列需要有效執行,所以必須具有連貫的邏輯,2)每個中間步驟都可以進行逐步邏輯驗證(step- by-step logic verification)。
在預訓練中利用和嵌入程式碼的這兩種特性,可以提高LLM思維鏈(CoT)技術在傳統自然語言下游任務中的效能,顯示程式碼訓練能夠提高LLM進行複雜推理的能力。
透過從程式碼的結構化形式進行隱式學習,程式碼LLM 在常識結構推理任務中也表現出更優的效能,例如與markup、HTML和圖表理解相關的任務。
支援功能/函數終端(function ends)
#最近的研究結果表明,將LLMs連接到其他功能終端(即,使用外部工具和執行模組增強LLMs)有助於LLMs更準確可靠地執行任務。
這些功能性目的使LLMs能夠獲取外部知識、參與多種模態資料中,並與環境進行有效互動。

從相關工作中,研究人員觀察到一個普遍的趨勢,即LLMs產生程式語言或利用預先定義的函數來建立與其他功能終端的連接,即「以代碼為中心」的範式。
與LLM推理機制中嚴格硬編碼工具調用的固定實踐流程相反,以代碼為中心的範式允許LLM動態生成tokens,並使用可適應的參數(adaptable parameters)呼叫執行模組,為LLM與其他功能終端互動提供了一種簡單明了的方法,增強了其應用程式的靈活性和可擴展性。
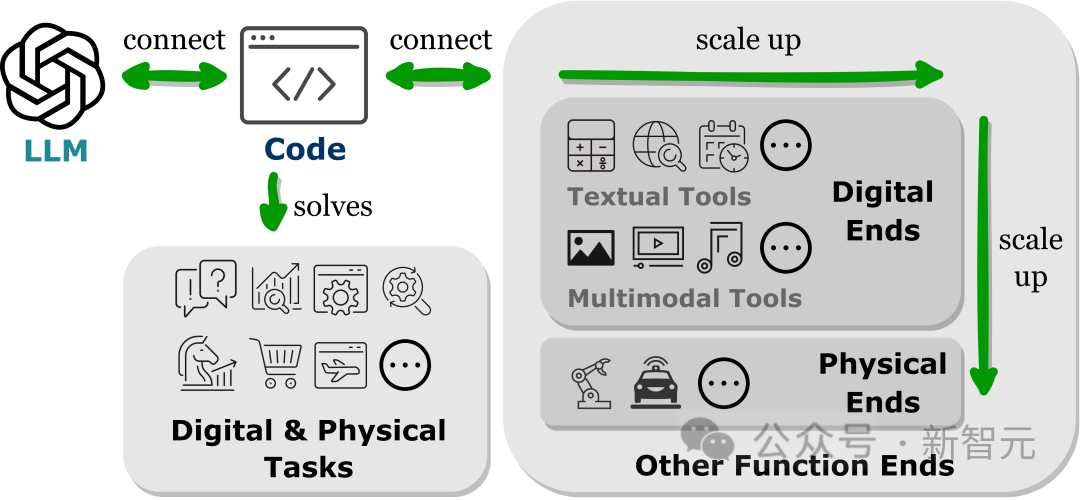
重要的是,這種範式可以讓LLM與跨越不同模態和領域的眾多功能終端進行互動;透過擴展可存取的功能終端的數量和種類,LLM可以處理更複雜的任務。
本文中主要研究了與LLM連結的文字和多模態工具,以及物理世界的功能端,包括機器人和自動駕駛,展現了LLM在解決各種模式和領域問題方面的多功能性。
提供自動回饋的可執行環境
LLMs表現出超出其訓練參數的效能,部分原因是模型能夠吸收回饋訊號,特別是在非靜態的現實世界應用中。
不過回饋訊號的選擇必須謹慎,因為吵雜的提示可能會阻礙LLM在下游任務上的表現。
此外,由於人力成本高昂,因此在保持忠誠度(faithful)的同時自動收集回饋至關重要。
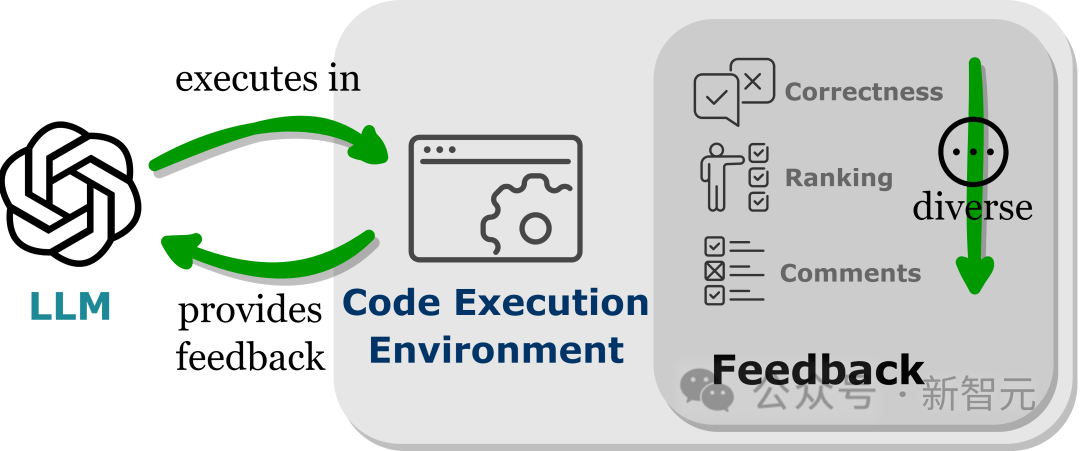
將LLMs嵌入到程式碼執行環境中可以實現上述條件的自動回饋。
由於程式碼執行在很大程度上是確定性的,LLMs從執行程式碼的結果中獲得的回饋仍然忠實於目標任務;程式碼解釋器也為LLMs查詢內部回饋提供了一個自動路徑,無需人工標註即可對LLMs產生的錯誤程式碼進行偵錯和最佳化。
此外,程式碼環境允許LLMs整合各種各樣的外部回饋形式,包括但不限於二元正確性回饋,對結果的自然語言解釋,以及獎勵值排序,從而實現一個高度可自訂的方法來提高性能。

當下的挑戰
#程式碼預訓練與LLMs推理增強的因果關係
雖然從直覺來看,程式碼資料的某些屬性可能有助於LLMs的推理能力,但其對增強推理技能影響的確切程度仍然模糊不清。
在下一步的研究工作中,重要的是要研究在訓練資料中加強認識:這些程式碼屬性是否真的可以增強訓練的LLMs的推理能力。
如果確實如此,對程式碼的特定屬性進行預訓練可以直接提高LLMs的推理能力,那麼理解這種現象將是進一步提高當前模型複雜推理能力的關鍵。
不限於程式碼的推理能力
#儘管透過程式碼預訓練實現了對推理能力的增強,但基礎模型仍然缺乏真正通用人工智慧所期望的類似人類的推理能力。
除了程式碼之外,大量其他文字資料來源也有可能增強LLM推理能力,其中程式碼的內在特徵,如缺乏歧義、可執行性和邏輯順序結構,為收集或創建這些資料集提供了指導原則。
但如果繼續堅持在具有語言建模目標的大型語料庫上訓練語言模型的範式,很難有一種順序可讀的語言比形式語言更抽象:高度結構化,與符號語言密切相關,並且在數位網路環境中大量存在。
研究人員設想,探索可替代的資料模式、多樣化的訓練目標和新穎的架構將為進一步增強模型推理能力提供更多的機會。
以程式碼為中心範式在應用上的挑戰
#在LLMs中,使用程式碼連接到不同的功能終端的主要挑戰是學習不同功能的正確呼叫方法,包括選擇正確的功能(函數)終端以及在適當的時候傳遞正確的參數。
比如說一個簡單的任務(網頁導航),給定一組有限的動作原語後,如滑鼠移動、點擊和頁面滾動,再給一些例子(few -shot),一個強大的基礎LLM往往需要LLM精確地掌握這些原語的使用。
對於資料密集型領域中更複雜的任務,如化學、生物學和天文學,這些任務涉及對特定領域python庫的調用,其中包含許多不同功能的複雜函數,增強LLMs正確調用這些功能函數的學習能力是一個前瞻性的方向,可以使LLMs在細粒度領域中執行專家級任務。
從多輪互動和回饋中學習
#LLMs通常需要與使用者和環境進行多次交互,不斷糾正自己以改善複雜任務的完成。
雖然程式碼執行提供了可靠且可自訂的回饋,但尚未建立一種完全利用這種回饋的完美方法。
當下基於選擇的方法雖然有用,但不能保證提高性能,而且效率低下;基於遞歸的方法嚴重依賴LLM的上下文學習能力,這可能會限制其適用性;微調方法雖然做出了持續的改進,但資料收集和微調是資源密集的,實際使用時很困難。
研究人員認為強化學習可能是一種更有效的利用回饋和改進的方法,可以提供一種動態的方式來適應回饋,透過精心設計的獎勵功能,潛在地解決目前技術的限制。
但仍需要大量的研究來了解如何設計獎勵函數,以及如何將強化學習與LLMs最佳地整合以完成複雜的任務。
以上是揭開LLM巫師的魔杖,UIUC華人團隊揭示程式碼資料的三大優勢的詳細內容。更多資訊請關注PHP中文網其他相關文章!