
首篇僅使用2D標籤訓練多視圖3D佔用模型的新範式

- 王林轉載
- 2023-09-30 08:49:061615瀏覽
本文經自動駕駛之心公眾號授權轉載,轉載請聯絡來源。
【RenderOcc,首篇僅使用2D標籤訓練多視圖3D佔用模型的新範式】作者從多視圖圖像中提取NeRF風格的3D體積表示,並使用體積渲染技術來建立2D重建,從而實現從2D語意和深度標籤的直接3D監督,減少了對昂貴的3D佔用標註的依賴。大量實驗表明,RenderOcc的性能與使用3D標籤完全監督的模型相當,突顯了這種方法在現實世界應用中的重要性。已開源。
主題: RenderOcc: Vision-Centric 3D Occupancy Prediction with 2DRendering Supervision
作者單位: 北京大學,小米汽車,港中文MMLAB
需要重寫的內容是:開源位址:GitHub - pmj110119/RenderOcc
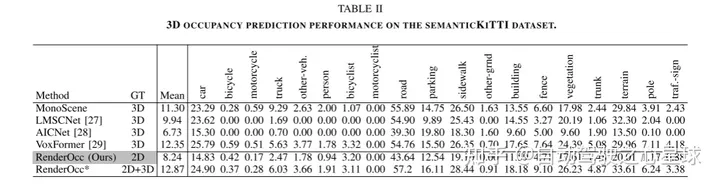
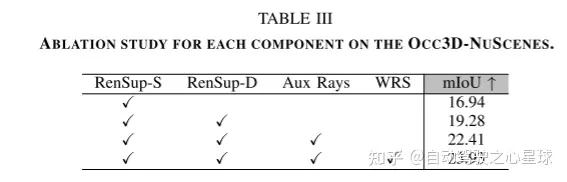
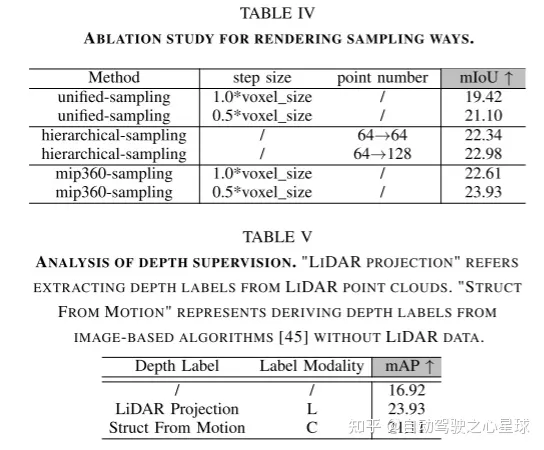
3D佔用預測在機器人感知和自動駕駛領域具有重要前景,它將3D場景量化為帶有語義標籤的網格單元。最近的工作主要利用3D體素空間中的完整佔用標籤進行監督。然而,昂貴的標註過程和有時模糊的標籤嚴重限制了3D佔用模型的可用性和可擴展性。為了解決這個問題,作者提出了RenderOcc,這是一個僅使用2D標籤訓練3D佔用模型的新範式。具體而言,作者從多視圖影像中提取NeRF風格的3D體積表示,並使用體積渲染技術來建立2D重建,從而實現從2D語義和深度標籤的直接3D監督。此外,作者引入了一種輔助光線方法來解決自動駕駛場景中的稀疏視點問題,該方法利用順序幀為每個目標建立全面的2D渲染。 RenderOcc是第一次嘗試只使用2D標籤來訓練多視圖3D佔用模型,從而減少了對昂貴的3D佔用標註的依賴。大量實驗表明,RenderOcc的性能與使用3D標籤完全監督的模型相當,突顯了這種方法在現實世界應用中的重要性。
網路結構:
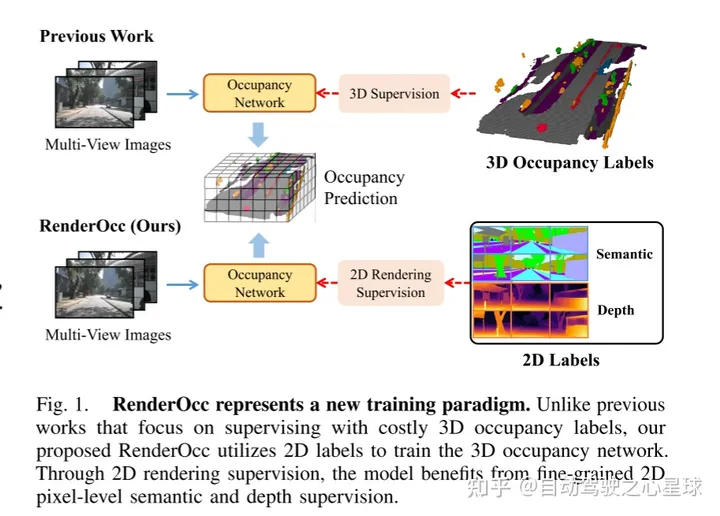
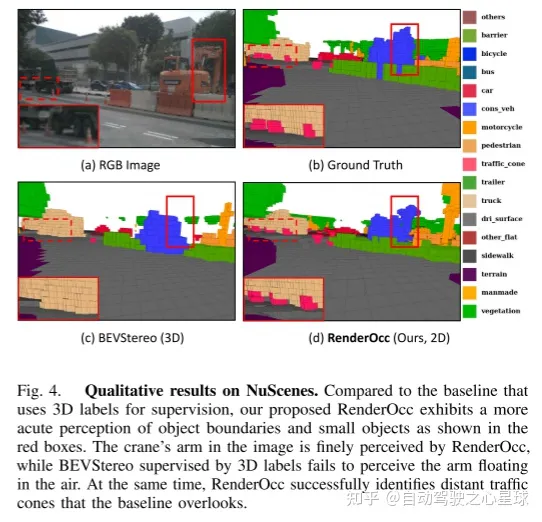
圖1展示了RenderOcc的一種新的訓練方法。與以往依賴昂貴的3D佔用標籤進行監督的方法不同,本文提出的RenderOcc利用2D標籤來訓練3D佔用網路。透過2D渲染監督,該模型能夠受益於細粒度的2D像素級語義和深度監督
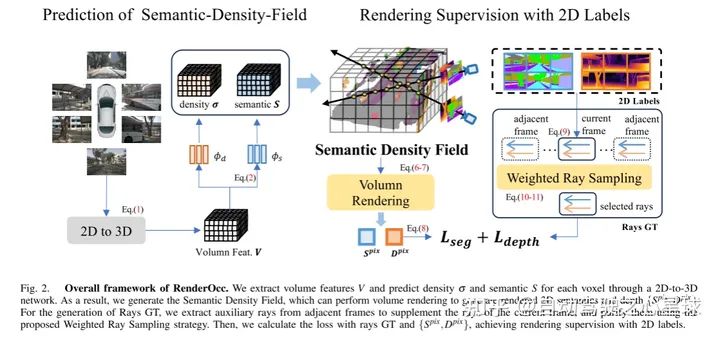
#圖2.RenderOcc的整體框架。本文透過2D到3D網路提取體積特徵並預測每個體素的密度和語義。因此,本文產生了語意密度場(Semantic Density Field),它可以執行體積渲染來產生渲染的2D語意和深度。對於Rays GT的生成,本文從相鄰幀中提取輔助光線來補充當前幀的光線,並使用所提出的加權光線採樣策略來淨化它們。然後,本文以光線GT和{}計算損失,實現2D標籤的渲染監督
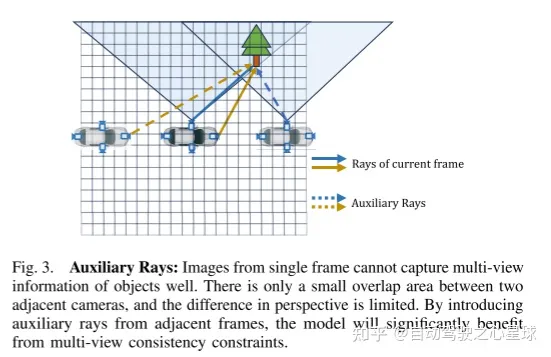
#重寫後的內容:圖3。輔助光線:單幀影像無法很好地捕捉物體的多視圖資訊。相鄰相機之間只有很小的重疊區域,視角差異有限。透過引入來自相鄰幀的輔助光線,該模型可以顯著受益於多視圖一致性約束
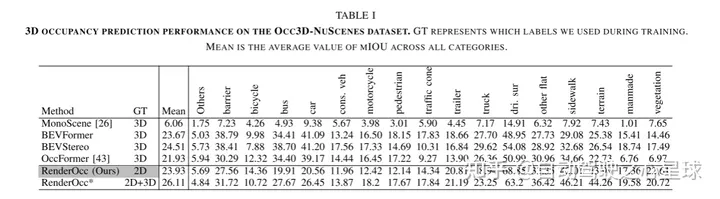
實驗結果:
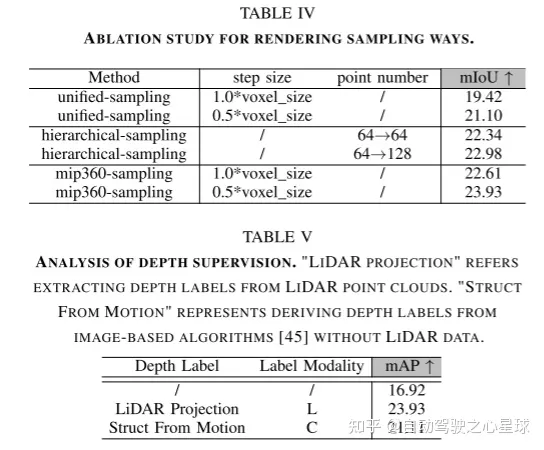
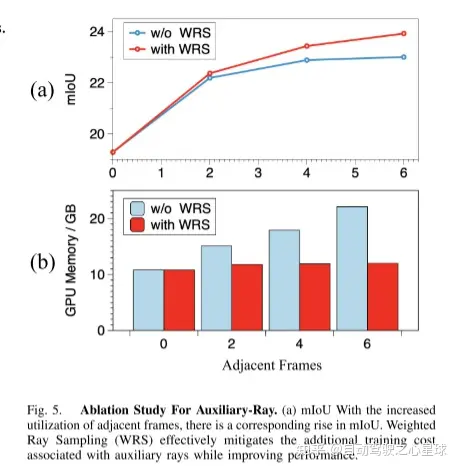

需要進行改寫的內容是:原文連結:https://mp.weixin.qq.com/s/WzI8mGoIOTOdL8irXrbSPQ
#以上是首篇僅使用2D標籤訓練多視圖3D佔用模型的新範式的詳細內容。更多資訊請關注PHP中文網其他相關文章!