這是作者 Sebastian Raschka 經過數百次實驗得出的經驗,值得一讀。
增加資料量和模型的參數量是公認的提升神經網路效能最直接的方法。目前主流的大模型的參數量已擴展至千億級,「大模型」越來越大的趨勢也將愈演愈烈。 這種趨勢帶來了多方面的算力挑戰。想要微調參數量達千億等級的大語言模型,不僅訓練時間長,還需佔用大量高效能的記憶體資源。 為了讓大模型微調的成本「打下來」,微軟的研究人員開發了低秩自適應(LoRA)技術。 LoRA 的精妙之處在於,它相當於在原有大模型的基礎上增加了一個可拆卸的插件,模型主體保持不變。 LoRA 隨插隨用,輕巧方便。 對於高效能微調出一個定製版的大語言模型來說,LoRA 是最廣泛運用的方法之一,同時也是最有效的方法之一。 如果你對開源 LLM 感興趣,LoRA 是值得學習的基本技術,不容錯過。 來自威斯康辛大學麥迪遜分校的資料科學教授 Sebastian Raschka 也對 LoRA 進行了全方位探索。在機器學習領域探索多年,他非常熱衷於拆解複雜的技術概念。在經歷數百次實驗後,Sebastian Raschka 總結了使用 LoRA 微調大模型的經驗,並發佈在 Ahead of AI 雜誌上。 
在保留作者原意的基礎上,本站對這篇文章進行了編譯:上個月,我分享了一篇有關LoRA 實驗的文章,主要基於我和同事在Lightning AI 共同維護的開源Lit-GPT 庫,討論了我從實驗中得出的主要經驗和教訓。此外,我還將解答一些與 LoRA 技術相關的常見問題。如果你對於微調客製化的大語言模型感興趣,我希望這些見解能幫助你快速起步。
- ##雖然LLM 訓練(或在GPU 上訓練出的所有模型)有著不可避免的隨機性,但多lun 訓練的結果仍非常一致。
- 如果受 GPU 記憶體的限制,QLoRA 提供了一個高性價比的折衷方案。它以運行時間增長 39% 的代價,節省了 33% 的記憶體。
- 在微調 LLM 時,最佳化器的選擇並不是影響結果的主要因素。無論是 AdamW、具有調度器 scheduler 的 SGD ,或是具有 scheduler 的 AdamW,對結果的影響都微乎其微。
- 雖然Adam 經常被認為是需要大量記憶體的最佳化器,因為它為每個模型參數引入了兩個新參數,但這並不會顯著影響LLM 的峰值內存需求。這是因為大部分記憶體將被分配用於大型矩陣的乘法,而不是用來保留額外的參數。
- 對於靜態資料集,像多輪訓練中多次迭代可能效果不佳。這通常會導致過擬和,使訓練結果惡化。
- 如果要結合 LoRA,請確保它在所有層上應用,而不僅僅是 Key 和 Value 矩陣中,這樣才能最大限度地提升模型的性能。
- 調整 LoRA rank 和選擇合適的 α 值至關重要。提供一個小技巧,試試把 α 值設定成 rank 值的兩倍。
- 14GB RAM 的單一 GPU 能夠在幾個小時內高效地微調參數規模達 70 億的大模型。對於靜態資料集,想要讓 LLM 強化成「全能選手」,在所有基準任務中都表現優異是不可能的。想要解決這個問題需要多樣化的資料來源,或使用 LoRA 以外的技術。
另外,我將回答與 LoRA 有關的十個常見問題。
如果讀者有興趣,我會再寫一篇對 LoRA 更全面的介紹,包含從頭開始實作 LoRA 的詳細程式碼。今天這篇文章主要分享的是 LoRA 使用的關鍵問題。在正式開始之前,我們先來補充一點基礎知識。
#由於GPU 記憶體的限制,在訓練過程中更新模型權重成本高昂。
例如,假設我們有一個 7B 參數的語言模型,用一個權重矩陣 W 表示。在反向傳播期間,模型需要學習一個 ΔW 矩陣,旨在更新原始權重,讓損失函數值最小。
權重更新如下:W_updated = W ΔW。
如果權重矩陣 W 包含 7B 個參數,則權重更新矩陣 ΔW 也包含 7B 個參數,計算矩陣 ΔW 非常耗費計算和記憶體。
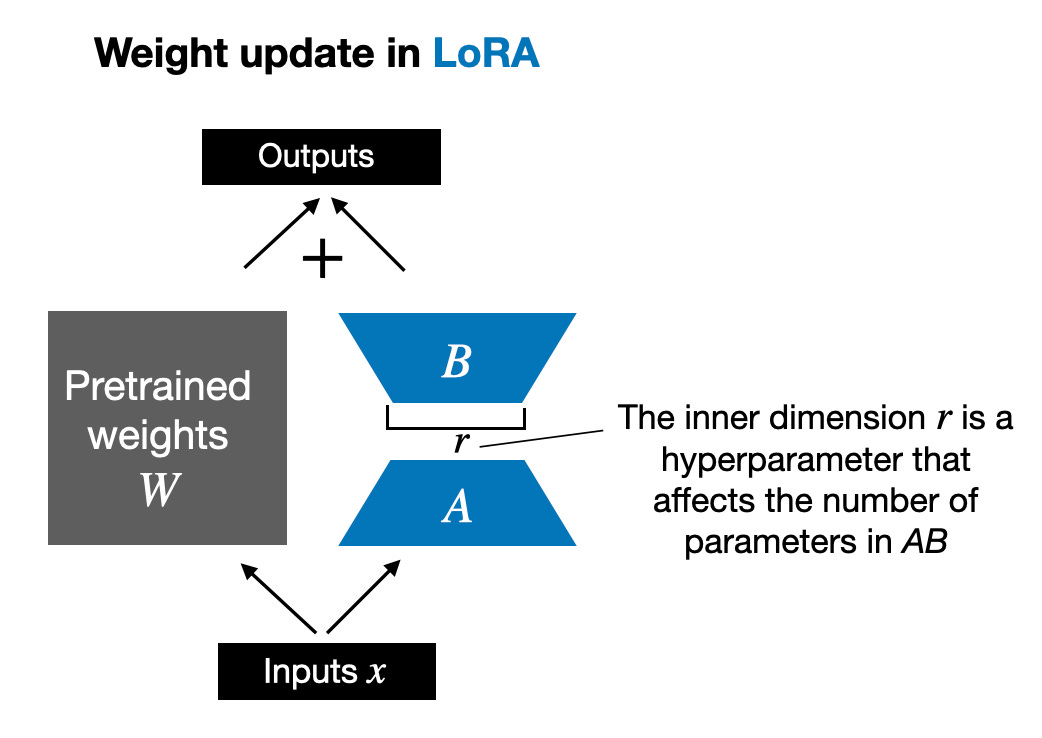
由 Edward Hu 等人提出的 LoRA 將權重變化的部分 ΔW 分解為低秩表示。確切地說,它不需要顯示計算 ΔW。相反,LoRA 在訓練期間學習 ΔW 的分解表示,如下圖所示,這就是 LoRA 節省計算資源的奧秘。
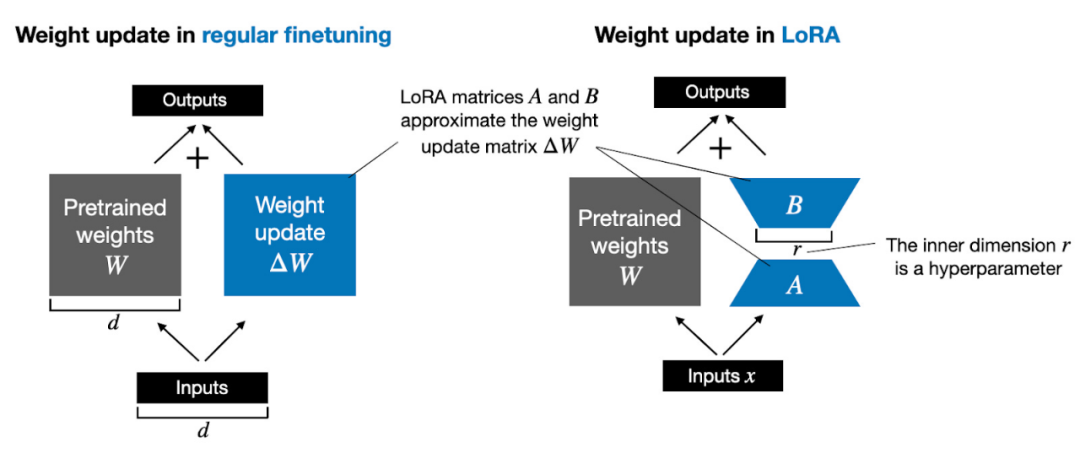 如上所示,ΔW 的分解意味著我們需要用兩個較小的 LoRA 矩陣 A 和 B 來表示較大的矩陣 ΔW。如果 A 的行數與 ΔW 相同,B 的列數與 ΔW 相同,我們可以將以上的分解記為 ΔW = AB。 (AB 是矩陣 A 和 B 之間的矩陣乘法結果。)這種方法節省了多少記憶體呢?還需要取決於秩 r,秩 r 是一個超參數。例如,如果 ΔW 有 10,000 行和 20,000 列,則需儲存 200,000,000 個參數。如果我們選擇 r=8 的 A 和 B,則 A 有 10,000 行和 8 列,B 有 8 行和 20,000 列,即 10,000×8 8×20,000 = 240,000 個參數,比 200,000,003 倍參數。 當然,A 和 B 無法捕捉到 ΔW 涵蓋的所有訊息,但這是 LoRA 的設計所決定的。在使用 LoRA 時,我們假設模型 W 是一個具有全秩的大矩陣,以收集預訓練資料集中的所有知識。當我們微調 LLM 時,不需要更新所有權重,只需要更新比 ΔW 更少的權重來捕捉核心信息,低秩更新就是這麼透過 AB 矩陣實現的。 #雖然LLM,或是說在GPU 上被訓練的模型的隨機性不可避免,但採用LoRA 進行多次實驗,LLM 最終的基準結果在不同測試集中都表現出了驚人的一致性。對於進行其他比較研究,這是一個很好的基礎。
如上所示,ΔW 的分解意味著我們需要用兩個較小的 LoRA 矩陣 A 和 B 來表示較大的矩陣 ΔW。如果 A 的行數與 ΔW 相同,B 的列數與 ΔW 相同,我們可以將以上的分解記為 ΔW = AB。 (AB 是矩陣 A 和 B 之間的矩陣乘法結果。)這種方法節省了多少記憶體呢?還需要取決於秩 r,秩 r 是一個超參數。例如,如果 ΔW 有 10,000 行和 20,000 列,則需儲存 200,000,000 個參數。如果我們選擇 r=8 的 A 和 B,則 A 有 10,000 行和 8 列,B 有 8 行和 20,000 列,即 10,000×8 8×20,000 = 240,000 個參數,比 200,000,003 倍參數。 當然,A 和 B 無法捕捉到 ΔW 涵蓋的所有訊息,但這是 LoRA 的設計所決定的。在使用 LoRA 時,我們假設模型 W 是一個具有全秩的大矩陣,以收集預訓練資料集中的所有知識。當我們微調 LLM 時,不需要更新所有權重,只需要更新比 ΔW 更少的權重來捕捉核心信息,低秩更新就是這麼透過 AB 矩陣實現的。 #雖然LLM,或是說在GPU 上被訓練的模型的隨機性不可避免,但採用LoRA 進行多次實驗,LLM 最終的基準結果在不同測試集中都表現出了驚人的一致性。對於進行其他比較研究,這是一個很好的基礎。
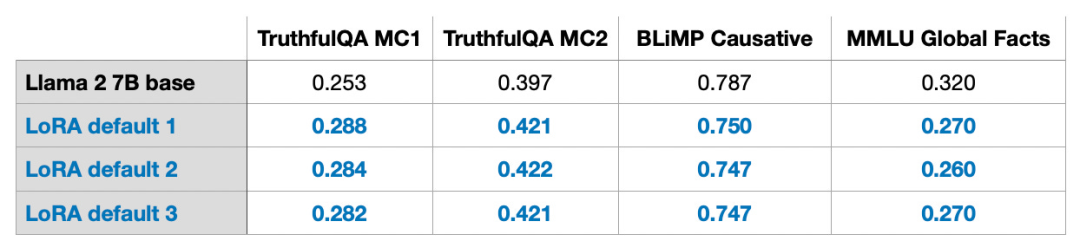
請注意,這些結果是在預設設定下,使用較小的值 r=8 獲得的。實驗細節可以在我的另一篇文章中找到。 文章連結:https://lightning.ai/pages/community/lora-insights/QLoRA 是由Tim Dettmers 等人提出的量化LoRA 的縮寫。 QLoRA 是一種在微調過程中進一步減少記憶體佔用的技術。在反向傳播過程中,QLoRA 將預先訓練的權重量化為 4-bit,並使用分頁優化器來處理記憶體峰值。
我發現使用 LoRA 時可以節省 33% 的 GPU 記憶體。然而,由於 QLoRA 中預訓練模型權重的額外量化和去量化,訓練時間增加了 39%。
預設LoRA 具有16 bit 浮點數精度:
- 訓練時間:1.85 小時
- 記憶體佔用:21.33GB
#有4 位元正常浮點數的QLoRA
- #訓練時間為:2.79h
- 記憶體佔用為:14.18GB
#此外,我發現模型的效能幾乎不受影響,這說明QLoRA 可以作為LoRA 訓練的替代方案,更進一步解決常見GPU 記憶體瓶頸問題。

#學習率調度器會在整個訓練過程中降低學習率,進而最佳化模型的收斂程度,避免loss 值過大。
餘弦退火(Cosine annealing)是一種遵循餘弦曲線調整學習率的調度器。它以較高的學習率作為起點,然後平滑下降,以類似餘弦的模式逐漸接近 0。常見的餘弦退火變體是半週期變體,在訓練過程中只完成半個餘弦週期,如下圖所示。
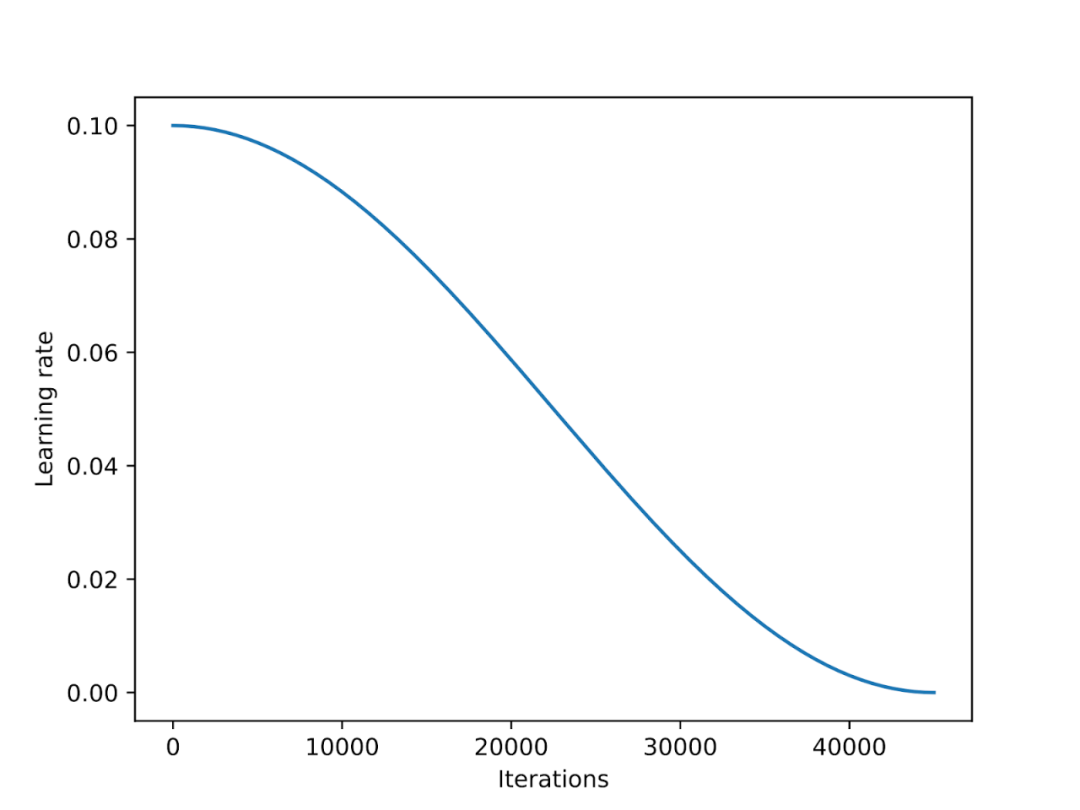
在實驗中,我在 LoRA 微調腳本中加入了一個餘弦退火調度器,它顯著地提高了 SGD 的效能。但它對 Adam 和 AdamW 優化器的增益較小,添加後幾乎沒有任何變化。
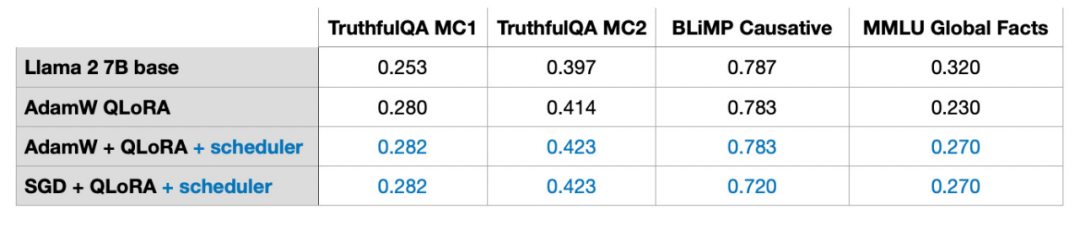 在下一節中,將討論 SGD 相對於 Adam 的潛在優勢。 Adam 和 AdamW 最佳化器在深度學習中很受歡迎。如果我們正在訓練一個 7B 參數的模型,那麼使用 Adam 就能夠在訓練的過程中追蹤額外的 14B 參數,相當於在其他條件不變的情況下,模型的參數量翻了一番。 SGD 無法在訓練過程中追蹤附加的參數,所以比起 Adam,SGD 在峰值記憶體方面有什麼優勢呢? 在我的實驗中,使用 AdamW 和 LoRA(預設值 r=8)訓練一個 7B 參數的 Llama 2 模型需要 14.18 GB 的 GPU 記憶體。用 SGD 訓練同一型號需要 14.15 GB 的 GPU 記憶體。相較於 AdamW,SGD 只節省了 0.03 GB 的內存,作用微乎其微。 為什麼只省了這麼一點記憶體呢?這是因為使用 LoRA 時,LoRA 已經大大降低了模型的參數量。例如,如果 r=8,在 7B 的 Llama 2 模型的所有 6,738,415,616 個參數,只有 4,194,304 個可訓練的 LoRA 參數。 只看數字,4,194,304 個參數可能還是很多,但其實這麼多參數只佔 4,194,304 × 2 × 16 位元 = 134.22 兆位元 = 16.78 兆位元組。 (我們觀察到了存在0.03 Gb = 30 Mb 的差異,這是由於在存儲和復制優化器狀態時,存在額外的開銷。) 2 代表Adam 存儲的額外參數的數量,而16 位指的是模型權重的預設精度。
在下一節中,將討論 SGD 相對於 Adam 的潛在優勢。 Adam 和 AdamW 最佳化器在深度學習中很受歡迎。如果我們正在訓練一個 7B 參數的模型,那麼使用 Adam 就能夠在訓練的過程中追蹤額外的 14B 參數,相當於在其他條件不變的情況下,模型的參數量翻了一番。 SGD 無法在訓練過程中追蹤附加的參數,所以比起 Adam,SGD 在峰值記憶體方面有什麼優勢呢? 在我的實驗中,使用 AdamW 和 LoRA(預設值 r=8)訓練一個 7B 參數的 Llama 2 模型需要 14.18 GB 的 GPU 記憶體。用 SGD 訓練同一型號需要 14.15 GB 的 GPU 記憶體。相較於 AdamW,SGD 只節省了 0.03 GB 的內存,作用微乎其微。 為什麼只省了這麼一點記憶體呢?這是因為使用 LoRA 時,LoRA 已經大大降低了模型的參數量。例如,如果 r=8,在 7B 的 Llama 2 模型的所有 6,738,415,616 個參數,只有 4,194,304 個可訓練的 LoRA 參數。 只看數字,4,194,304 個參數可能還是很多,但其實這麼多參數只佔 4,194,304 × 2 × 16 位元 = 134.22 兆位元 = 16.78 兆位元組。 (我們觀察到了存在0.03 Gb = 30 Mb 的差異,這是由於在存儲和復制優化器狀態時,存在額外的開銷。) 2 代表Adam 存儲的額外參數的數量,而16 位指的是模型權重的預設精度。
如果我們把LoRA 矩陣的r 從8 拓展到256,那麼SGD 相較於AdamW 的優勢就會顯現:
因此,當矩陣規模擴大時,SGD 節省的記憶體將發揮重要作用。由於 SGD 不需要儲存額外的優化器參數,因此在處理大型模型時,SGD 相比 Adam 等其他優化器可以節省更多的記憶體。這對於記憶體有限的訓練任務來說是非常重要的優勢。 #在傳統的深度學習中,我們經常對訓練集進行多次迭代,每次迭代稱為一個epoch。例如,在訓練卷積神經網路時,通常會運行數百個 epoch。那麼,多輪迭代訓練對於指令微調也有效果嗎? 答案是否定的,當我將資料量為 50k 的 Alpaca 範例指令微調資料集的迭代次數增加一倍,模型的效能下降了。 
因此,我得出的結論是,多輪迭代可能不利於指令微調。我在 1k 的範例 LIMA 指令微調集中也觀察到了相同的狀況。模型表現的下降可能是由過度擬合造成的,具體原因仍需進一步探討。 #下表顯示了LoRA 僅對選定矩陣(即每個Transformer 中的Key 和Value 矩陣)起效的實驗。此外,我們還可以在查詢權重矩陣、投影層、多頭注意力模組之間的其他線性層以及輸出層啟用 LoRA。 
如果我們在這些附加層上加入 LoRA,那麼對於 7B 的 Llama 2 模型,可訓練參數的數量將從 4,194,304 增加到 20,277,248,增加五倍。在更多層應用 LoRA,能夠顯著提高模型效能,但也對記憶體空間的需求量更高。 此外,我只對(1)僅啟用查詢和權重矩陣的LoRA,(2)啟用所有層的LoRA,這兩種設定進行了探索,在在更多層的組合中使用LoRA 會產生何種效果,值得深入研究。如果能知道在投影層使用 LoRA 對訓練結果是否有益,那麼我們就可以更好地優化模型,並提高其性能。 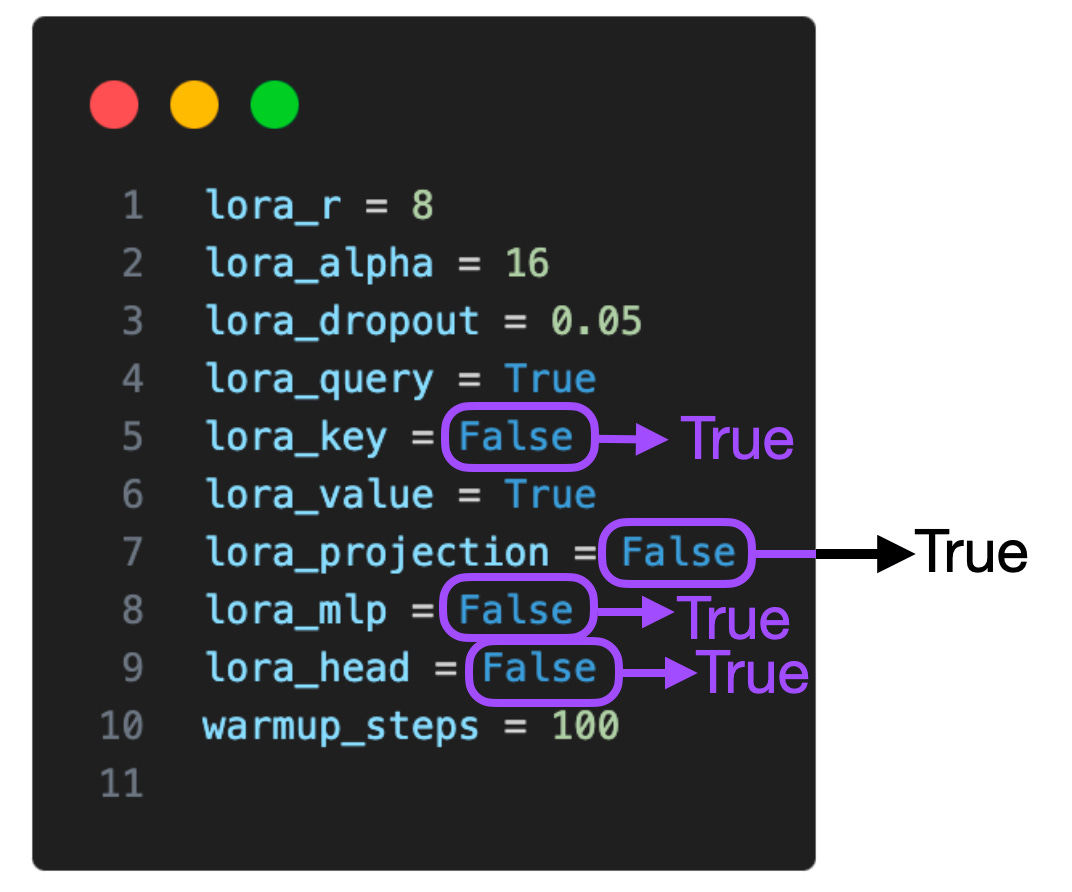
#正如提出 LoRA 的論文中所述,LoRA 引入了一個額外的擴展係數。這個係數用於在前向傳播過程中將 LoRA 權重應用於預訓練之中。擴展涉及先前討論過的秩參數r,以及另一個超參數α(alpha),其應用如下:
#如上圖中的公式所示,LoRA 權重的值越大,影響就越大。 在先前的實驗中,我採用的參數是 r=8,alpha=16,這導致了 2 倍的擴展。在用 LoRA 為大模型減重時,將 alpha 設定為 r 的兩倍是常見的經驗法則。但我很好奇這條規則對於較大的 r 值是否仍然適用。 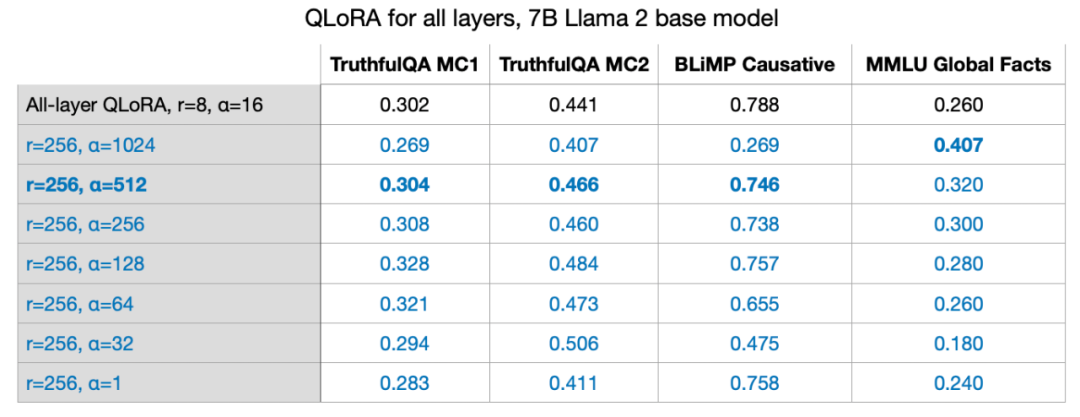
我還嘗試了r=32, r=64, r=128, and r=512,但為了清晰起見省略了此過程,不過r=256 時,的確效果最佳。事實上,選擇 alpha=2r 確實提供了最優結果。 LoRA 允許我們在單一GPU上微調7B 參數規模的大語言模型。在這個特定情況下,採用最佳設定過的QLoRA(r=256,alpha=512),使用AdamW 優化器處理17.86 GB(50k 訓練範例)的資料在A100 上大約需要3 小時(此處為Alpaca 資料集)。 
在本文的其餘部分中,我將回答你可能遇到的其他問題。 資料集至關重要。我使用的是包含 50k 訓練範例的 Alpaca 資料集。我選擇 Alpaca 是因為它非常受歡迎。由於本文篇幅已經很長,所以在更多資料集上的測試結果本文暫不討論。 Alpaca 是一個合成資料集,按照如今的標準,它可以已經有點落伍了。數據品質非常關鍵。例如,在六月份,我在一篇文章中討論了 LIMA 資料集,這是一個僅由一千個範例組成的精選資料集。 文章連結:https://magazine.sebastianraschka.com/p/ahead-of-ai-9-llm-tuning-and-dataset#正如提出LIMA 的論文的標題所說:對於對齊來說,少即是多,雖然LIMA 的數據量少於Alpaca,但根據LIMA 微調出的65B Llama 模型優於Alpaca 的結果。採用相同的配置 (r=256, alpha=512) ,在 LIMA 上,我獲得了與資料量級是其 50 倍大的 Alpaca 類似的模型表現。 對於這個問題,我目前還沒有一個明確的答案。根據經驗,知識通常是從預訓練資料集中提取的。通常情況下,語言模型通常會從預訓練資料集中吸收知識,而指令微調的作用主要是幫助 LLM 更好地遵循指令。 既然算力緊張是限制大語言模型訓練的關鍵因素,LoRA 也可以被用於在特定領域的專用資料集,進一步預訓練現有的預訓練LLM。 另外,值得注意的是,我的實驗中包含兩個算術基準測試。在這兩個基準測試中,使用 LoRA 進行微調的模型表現明顯比預訓練的基礎模型差。我推測這是由於 Alpaca 資料集沒有缺少相應的算術範例,導致模型「忘記了」算術知識。我們還需要進一步的研究來確定模型是「忘記」了算術知識,還是它對對應指令停止了回應。然而,在這裡可以得出一條結論:「在微調LLM 時,讓資料集包含我們所關心的每個任務的範例是一個好主意。」對於這個問題,目前我還沒有比較好的解決方法。最佳 r 值的決定,需要根據每個 LLM 和每個資料集的具體情況,具體問題具體分析。我推測 r 值過大將導致過擬和,而 r 值太小,模型可能無法捕捉資料集中多樣化的任務。我懷疑資料集中的任務類型越多,所需 r 值就越大。例如,如果我只需要模型執行基本的兩位數算術運算,那麼一個很小的 r 值可能就已經滿足需求了。然而,這只是我的假設,需要進一步的研究來驗證。 我只對(1)僅啟用查詢和權重矩陣的 LoRA,(2)啟用所有層的 LoRA,這兩種設定進行了探索。在更多層的組合中使用 LoRA 會產生何種效果,值得深入研究。如果能知道在投影層使用 LoRA 對訓練結果是否有益,那麼我們就可以更好地優化模型,並提高其性能。 如果我們考慮各種設定 (lora_query, lora_key, lora_value, lora_projection, lora_mlp, lora_head),就有 64 種組合可供探索。 一般來說,較大的 r 更可能導致過度擬合,因為 r 決定可訓練參數的數量。如果模型有擬合問題,首先要考慮降低 r 值或增加資料集大小。此外,可以嘗試增加 AdamW 或 SGD 優化器的權重衰減率,或增加 LoRA 層的 dropout 值。 我在實驗中沒有探索過 LoRA 的 dropout 參數(我使用了 0.05 的固定 dropout 率),LoRA 的 dropout 參數也是一個有研究價值的問題。 今年五月發布的 Sophia 值得嘗試,Sophia 是一種用於語言模型預訓練的可拓展的隨機二階優化器。根據以下這篇論文:《Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training》,與 Adam 相比,Sophia 的速度快兩倍,還能獲得更優的效能。簡而言之,Sophia 和 Adam 一樣,都透過梯度曲率而不是梯度方差來實現歸一化。 論文連結:https://arxiv.org/abs/2305.14342除了精確度和量化設定、模型大小、batch size 和可訓練 LoRA 參數數量之外,資料集也會影響記憶體使用。 Llama 2 的 區塊大小為 4048 個 token,這代表著 Llama 可以一次處理包含 4048 個 token 的序列。如果對後來的 token 加上掩碼,訓練序列就會變短,可以節省大量的記憶體。例如 Alpaca 資料集相對較小,最長的序列長度為 1304 個 token。 當我嘗試使用最長序列長度達 2048 個 token 的其他資料集時,記憶體使用量會從 17.86 GB 飆升至 26.96 GB。 Q8:與全微調、RLHF 相比,LoRA 有哪些優點? 我沒有進行 RLHF 實驗,但我嘗試了全微調。全微調至少需要 2 個 GPU,每個 GPU 佔 36.66 GB,花了 3.5 小時才完成微調。然而,基線測試結果不好,可能是過度擬合或次超優參數導致的。 答案是肯定的。在訓練期間,我們將 LoRA 權重和預訓練權重分開,並在每次前向傳播時加入。 假設在現實世界中,存在一個具有多組LoRA 權重的應用程序,每組權重對應著一個應用的用戶,那麼單獨儲存這些權重,用來節省磁碟空間是很有意義的。同時,在訓練後也可以合併預訓練權重與 LoRA 權重,以建立單一模型。這樣,我們就不必在每次前向傳遞中應用 LoRA 權重。 weight += (lora_B @ lora_A) * scaling
我們可以採用如上所示的方法更新權重,並儲存合併的權重。 weight += (lora_B_set1 @ lora_A_set1) * scaling_set1weight += (lora_B_set2 @ lora_A_set2) * scaling_set2weight += (lora_B_set3 @ lora_A_set3) * scaling_set3...
##我還沒有做實驗來評估這個方法,但透過Lit-GPT 中提供的scripts/merge_lora.py 腳本已經可以實現。
腳本連結:https://github.com/Lightning-AI/lit-gpt/blob/main/scripts/merge_lora.py
為了簡單起見,在深度神經網路中我們通常將為每層設定相同的學習率。學習率是我們需要優化的超參數,更進一步,我們可以為每一層選擇不同的學習率(在 PyTorch 中,這不是非常複雜的事)。
然而在實踐中很少這樣做,因為這種方法增加了額外的成本,並且在深度神經網路中還有很多其他參數可調。類似於為不同層選擇不同的學習率,我們也可以為不同層選擇不同的 LoRA r 值。我還沒有動手嘗試,但有一篇詳細介紹這種方法的文獻:《LLM Optimization: Layer-wise Optimal Rank Adaptation (LORA)》。理論上,這種方法聽起來很有希望,為最佳化超參數提供了大量的拓展空間。
論文連結:https://medium.com/@tom_21755/llm-optimization-layer-wise-optimal-rank-adaptation-lora-1444dfbc8e6a
原文連結:https://magazine.sebastianraschka.com/p/practical-tips-for-finetuning-llms?continueFlag=0c2e38ff6893fba31f1492d815bf##以上是不是大模型全域微調不起,只是LoRA更有性價比,教學已經準備好了的詳細內容。更多資訊請關注PHP中文網其他相關文章!

