
Google推出Mirasol:30億參數,將多模態理解擴展至長視頻

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-11-17 23:39:011182瀏覽

11 月 16 日消息,Google公司最近發布新聞稿,介紹了小型人工智慧模型 Mirasol,可以回答有關影片的問題並創造新的記錄。
AI 模型目前很難處理不同的資料流,如果要讓AI 理解視頻,需要整合視頻、音頻和文字等不同模態的信息,這大大增加了難度。
Google和Google Deepmind 的研究人員提出了新的方法,將多模態理解擴展到長影片領域。
借助Mirasol AI模型,團隊努力解決兩個關鍵挑戰:
- 需要以高頻採樣同步視頻和音頻,但要異步處理標題和視頻描述。
- 視訊和音訊會產生大量數據,這會讓模型的容量緊張。
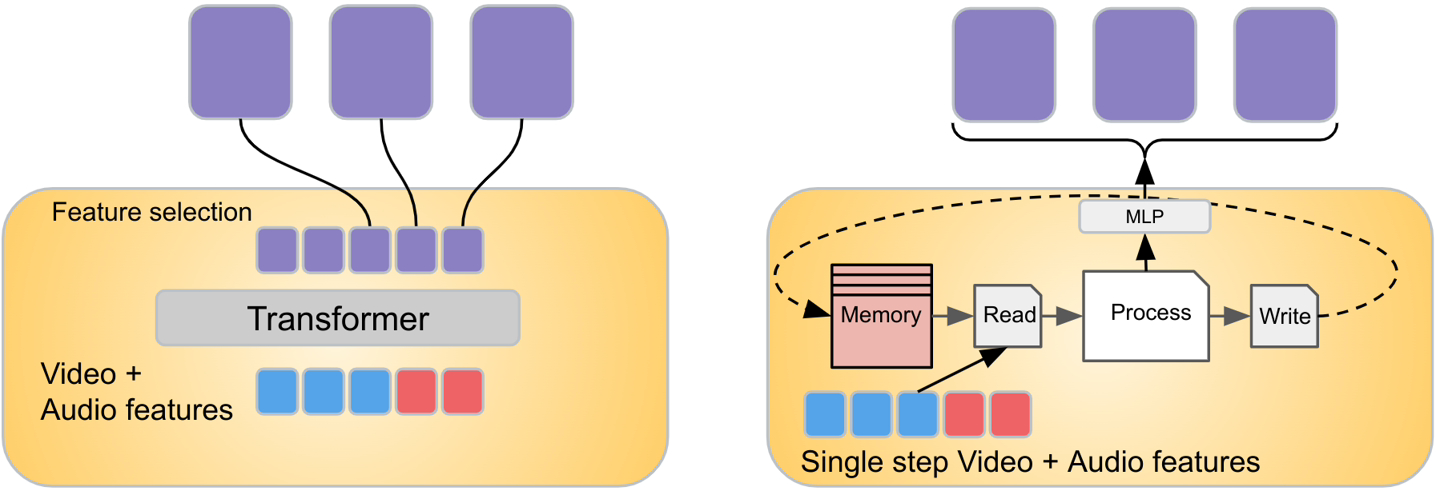
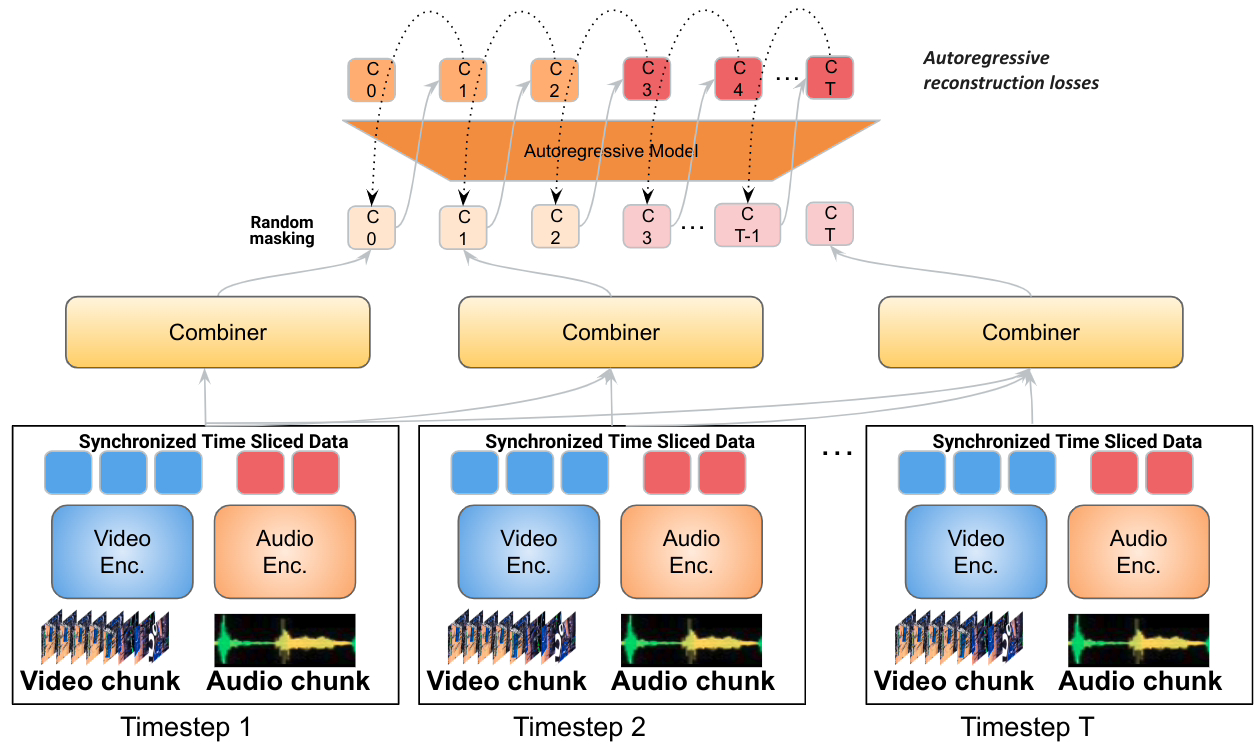
在Mirasol中,Google採用了合路器和自回歸轉換器模型
此模型元件將處理時間同步的視訊和音訊訊號,然後將視訊拆分成獨立的片段
轉換器處理每個片段,並學習每個片段之間的聯繫,然後使用另一個轉換器處理上下文文本,這兩個組件交換有關其各自輸入的資訊。
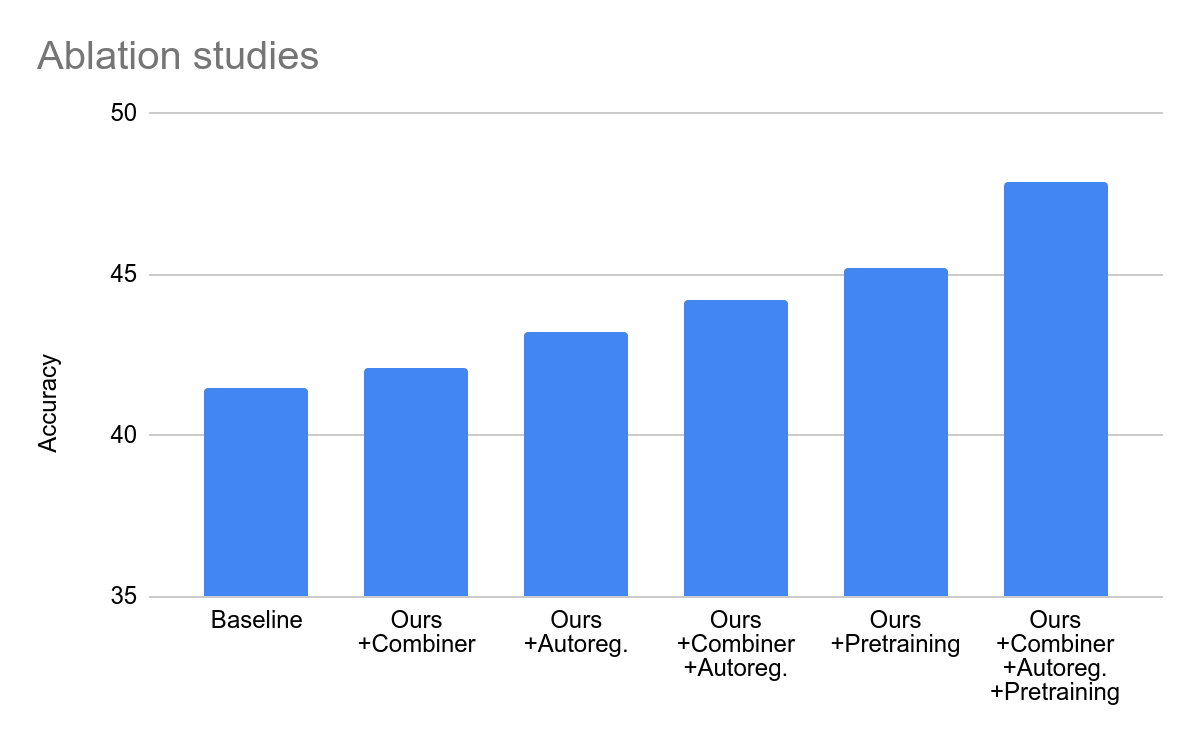
一個新的轉換模組名為Combiner,能夠從每個片段中提取通用表示,並透過降維來壓縮資料。每個片段包含4到64幀,該模型目前擁有30億個參數,能夠處理128到512幀的視頻
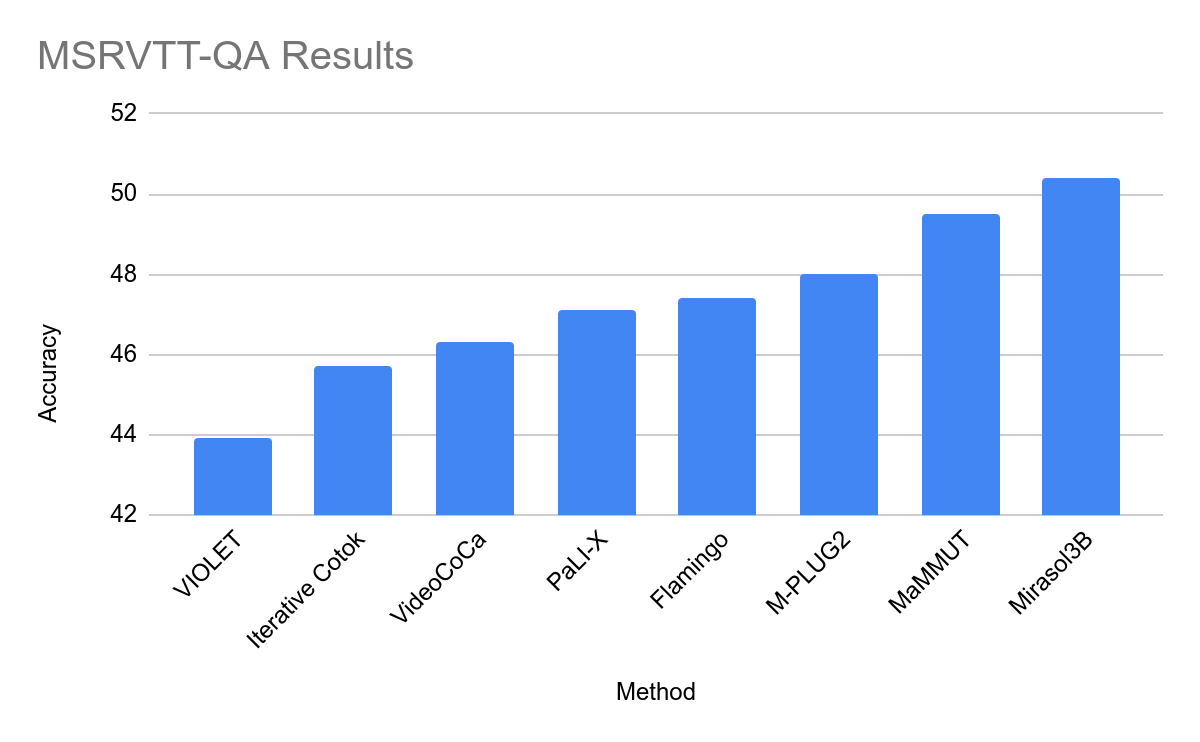
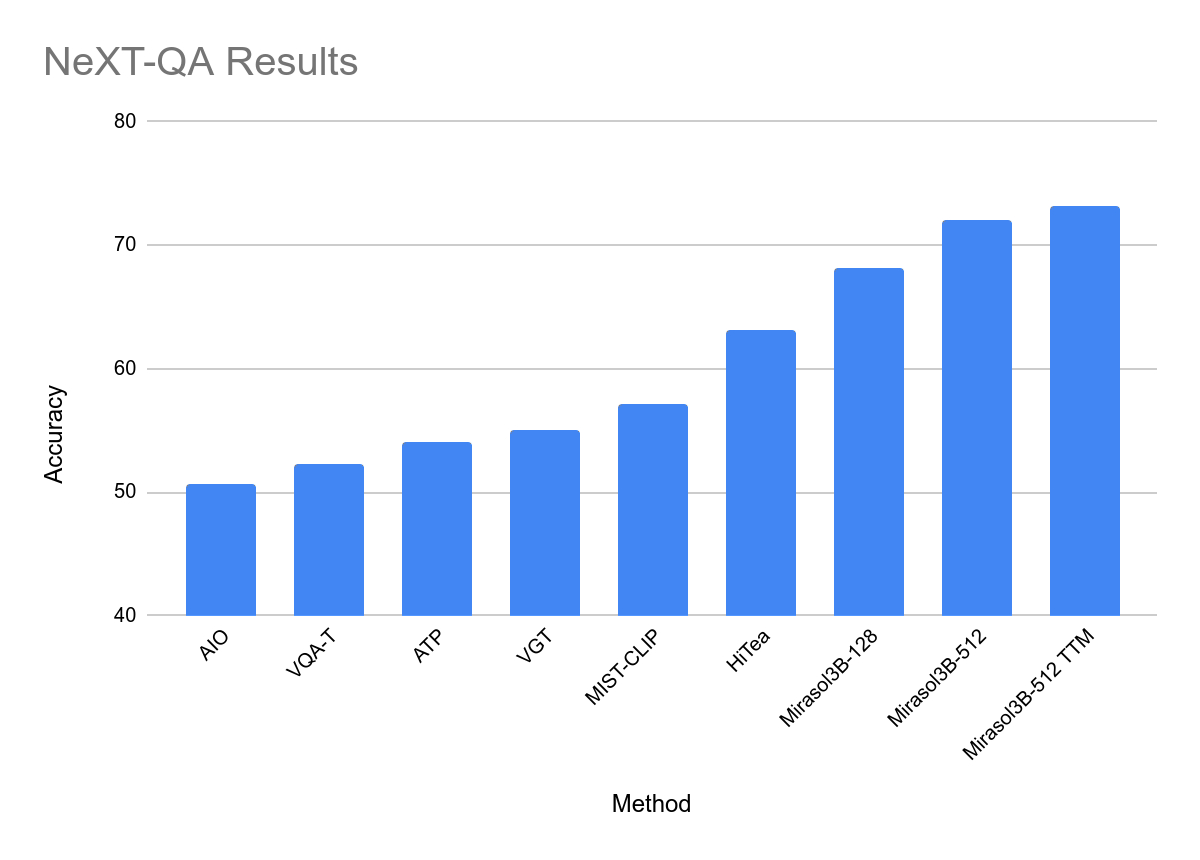
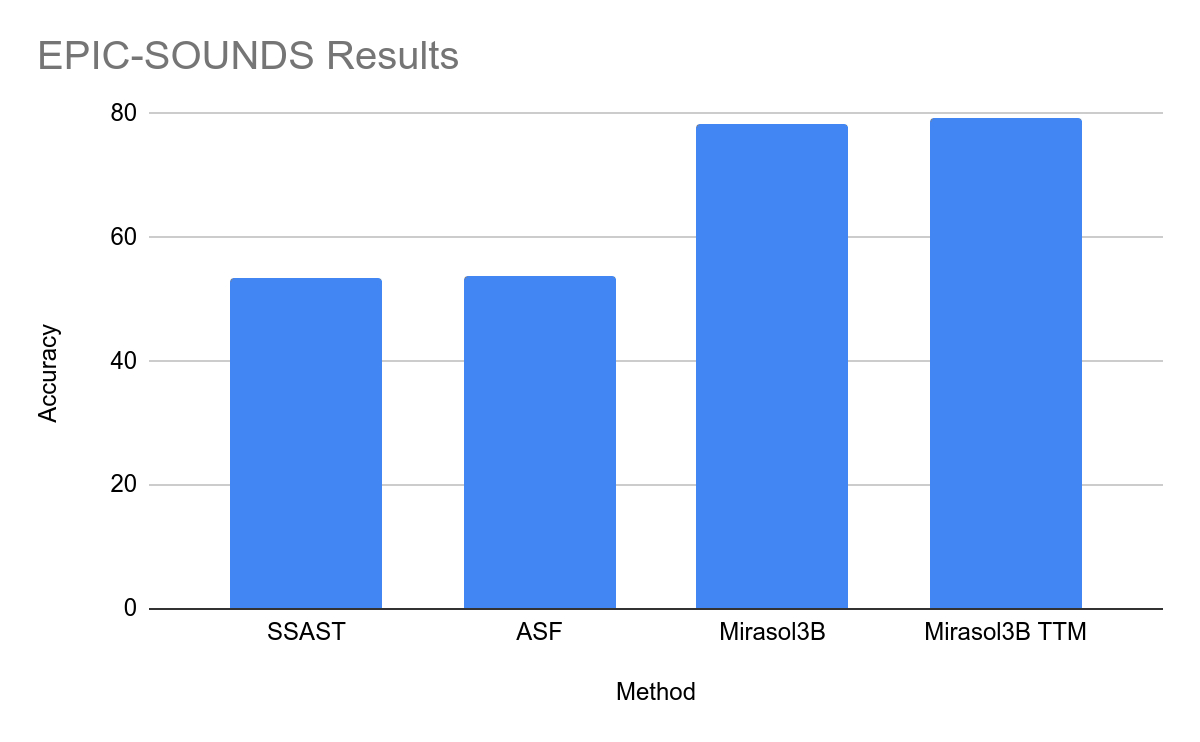
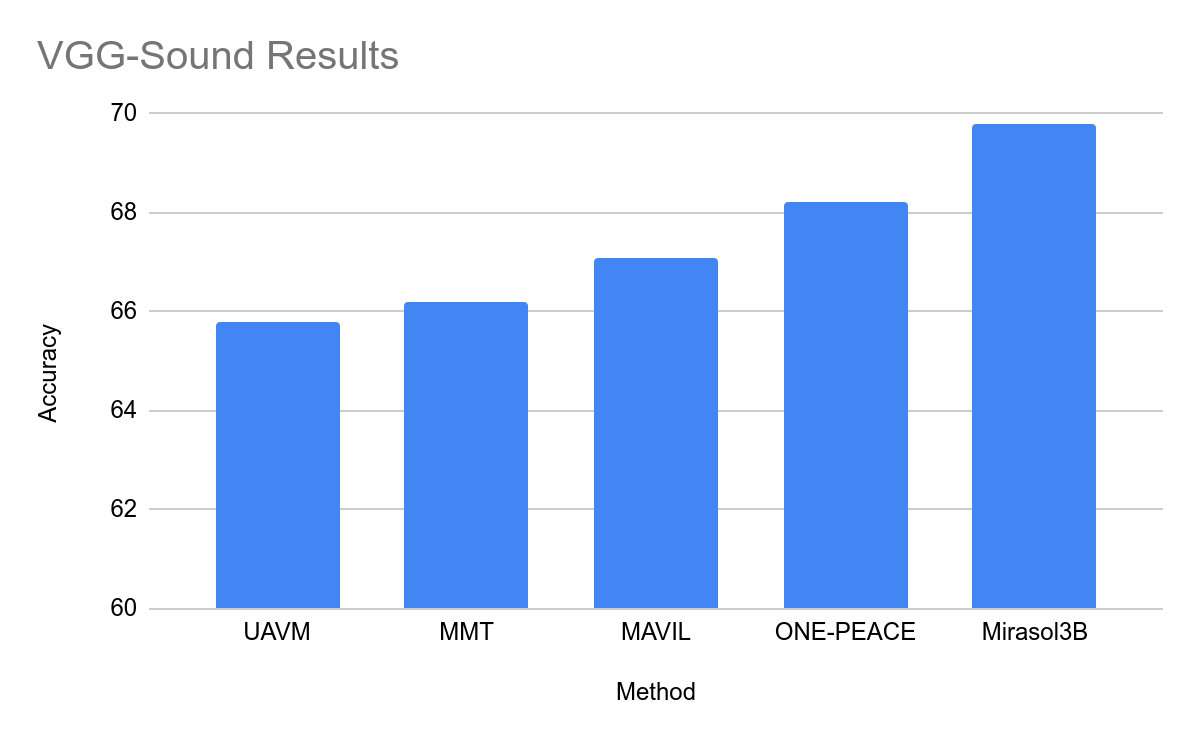
在測試中,Mirasol3B 在視頻問題分析方面達到了新的基準,體積明顯更小,並且可以處理更長的視訊。透過使用帶有記憶體的組合器變體,該團隊能夠進一步降低所需的運算能力18%
#本站在此附上Mirasol 的官方新聞稿,有興趣的用戶可以深入閱讀。
以上是Google推出Mirasol:30億參數,將多模態理解擴展至長視頻的詳細內容。更多資訊請關注PHP中文網其他相關文章!
陳述:
本文轉載於:51cto.com。如有侵權,請聯絡admin@php.cn刪除