
新標題:英偉達H200發表:HBM容量提升76%,大幅提升大模型效能90%的最強AI晶片

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB轉載
- 2023-11-14 15:21:131448瀏覽

11月14日消息,英偉達(Nvidia)在當地時間13日上午的「Supercomputing 23」會議上正式發布了全新的H200 GPU,並更新了GH200產品線
其中,H200仍然是建立在現有的Hopper H100 架構之上,但增加了更多高頻寬記憶體(HBM3e),從而更好地處理開發和實施人工智慧所需的大型資料集,使得運行大模型的綜合性能相比前代H100提升了60%到90%。而更新後的GH200,也將為下一代 AI 超級電腦提供動力。 2024 年將會有超過 200 exaflops 的 AI 運算能力上線。
H200:HBM容量增加了76%,大型機型的效能提升了90%
具體來說,全新的H200提供了高達141GB的HBM3e內存,有效運行速度約為6.25 Gbps,六個HBM3e堆疊中每個GPU的總頻寬為4.8 TB/s。與上一代的H100(具有80GB HBM3和3.35 TB/s頻寬)相比,這是一個巨大的改進,HBM容量提升了超過76%。根據官方提供的數據,在運行大模型時,H200相比H100將帶來60%(GPT3 175B)到90%(Llama 2 70B)的提升


雖然H100 的某些配置確實提供了更多內存,例如H100 NVL 將兩塊板配對,並提供總計188GB 內存(每個GPU 94GB),但即便是與H100 SXM 變體相比,新的H200 SXM 也提供了76% 以上的記憶體容量和43 % 更多頻寬。
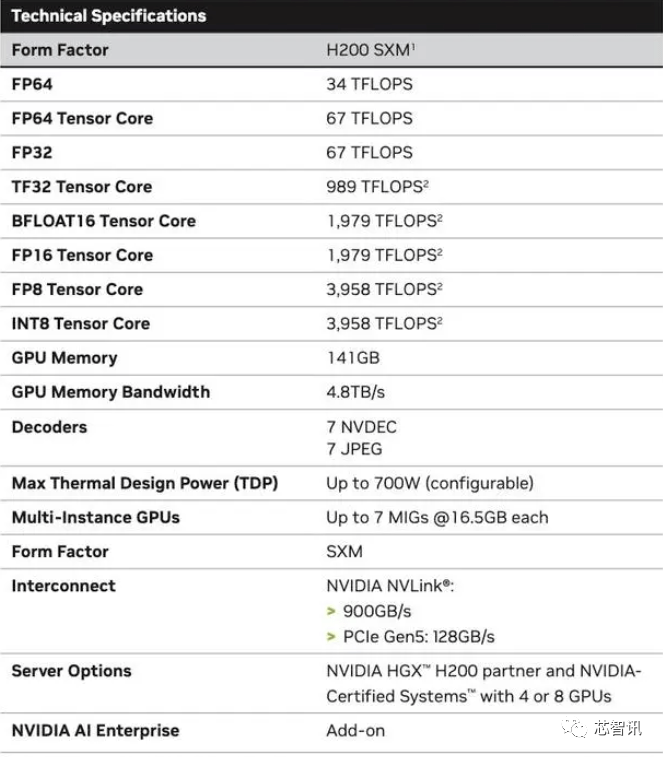
要指出的是,H200原始運算效能似乎沒有太大變化。英偉達所展示的唯一體現運算效能的投影片是基於使用了8個GPU的HGX 200配置,總效能為「32 PFLOPS FP8」。而最初的H100提供了3,958 teraflops的FP8算力,因此八個這樣的GPU也提供了大約32 PFLOPS的FP8算力
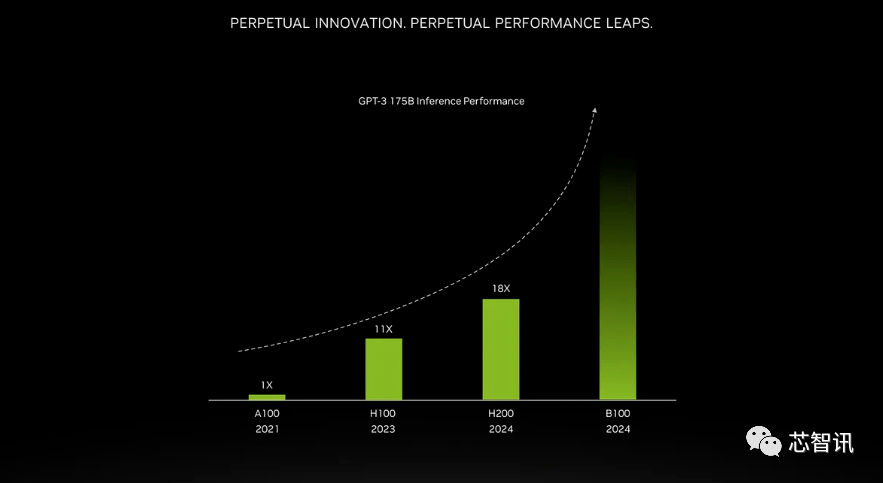
更高頻寬記憶體帶來的提升取決於工作量。大型模型(如GPT-3)將極大受益於HBM記憶體容量的增加。根據英偉達表示,H200在運行GPT-3時的性能將比原始A100高出18倍,比H100快約11倍。此外,即將推出的Blackwell B100的預告片顯示,它包含一個逐漸變黑的更高條,大約是H200的兩倍最右
不僅如此,H200和H100是互相相容的。也就是說,使用H100訓練/推理模型的AI企業,可以無縫更換成最新的H200晶片。雲端服務商將H200新增至產品組合時也不需要進行任何修改。
英偉達表示,透過推出新產品,他們希望跟上用於創建人工智慧模型和服務的資料集規模的成長。增強的記憶體能力將使H200在向軟體提供資料的過程中更快速,這個過程有助於訓練人工智慧執行識別影像和語音等任務。
“整合更快、更大容量的HBM內存有助於對運算要求較高的任務提升性能,包括生成式AI模型和高性能運算應用程序,同時優化GPU使用率和效率”,NVIDIA高性能計算產品副總裁Ian Buck表示。
英偉達資料中心產品負責人迪翁·哈里斯(Dion Harris)表示:「當你觀察市場發展的趨勢時,會發現模型規模正在迅速增大。這是我們持續引入最新和最優秀技術的典範。
預計大型電腦製造商和雲端服務供應商將於2024年第二季開始使用H200。英偉達伺服器製造夥伴(包括永擎、華碩、戴爾、Eviden、技嘉、HPE、鴻佰、聯想、雲端達、美超威、緯創資通以及緯穎科技)可以使用H200更新現有系統,而亞馬遜、Google、微軟、甲骨文等將成為首批採用H200的雲端服務商。鑑於目前市場對於英偉達AI晶片的旺盛需求,以及全新的H200增加了更多的昂貴的HBM3e內存,因此H200的價格肯定會更昂貴。英偉達沒有列出它的價格,但上一代H100價格就已經高達25,000美元至40,000美元。
英偉達發言人Kristin Uchiyama表示,最終的定價將由英偉達的製造夥伴來決定
對於H200的推出是否會影響H100的生產,Kristin Uchiyama表示:「我們預計全年的總供應量將會增加。」
英偉達的高階AI晶片一直以來被視為處理大量資料和訓練大型語言模式、AI生成工具的最佳選擇。然而,在推出H200晶片之時,AI公司仍在市場上拼命尋求A100/H100晶片。市場的焦點仍然在於,英偉達是否能夠提供足夠的供應來滿足市場需求。因此,H200晶片是否會像H100晶片一樣供不應求,NVIDIA並沒有給出答案
不過,明年對GPU買家來說可能將是一個更有利時期,根據《金融時報》8月報導曾指出,NVIDIA計劃在2024年將H100產量提升三倍,產量目標將從2023年約50萬個增加至2024年200萬個。但生成式AI仍在蓬勃發展,未來需求也可能更大。
舉個例子,最新推出的GPT-4大約是在10000-25000塊A100上進行訓練的。 Meta的AI大模型需要大約21000塊A100進行訓練。 Stability AI使用了大約5000塊A100。 Falcon-40B的訓練則需要384塊A100
根據馬斯克的說法,GPT-5可能需要30000-50000塊H100。摩根士丹利的說法是25000個GPU。
Sam Altman否認了在訓練GPT-5,但卻提過「OpenAI的GPU嚴重短缺,使用我們產品的人越少越好」。
當然,除了英偉達之外,AMD和英特爾也在積極的進入AI市場與英偉達展開競爭。先前AMD推出的MI300X就配備192GB的HBM3和5.2TB/s的顯存頻寬,這將使其在容量和頻寬上遠超H200。
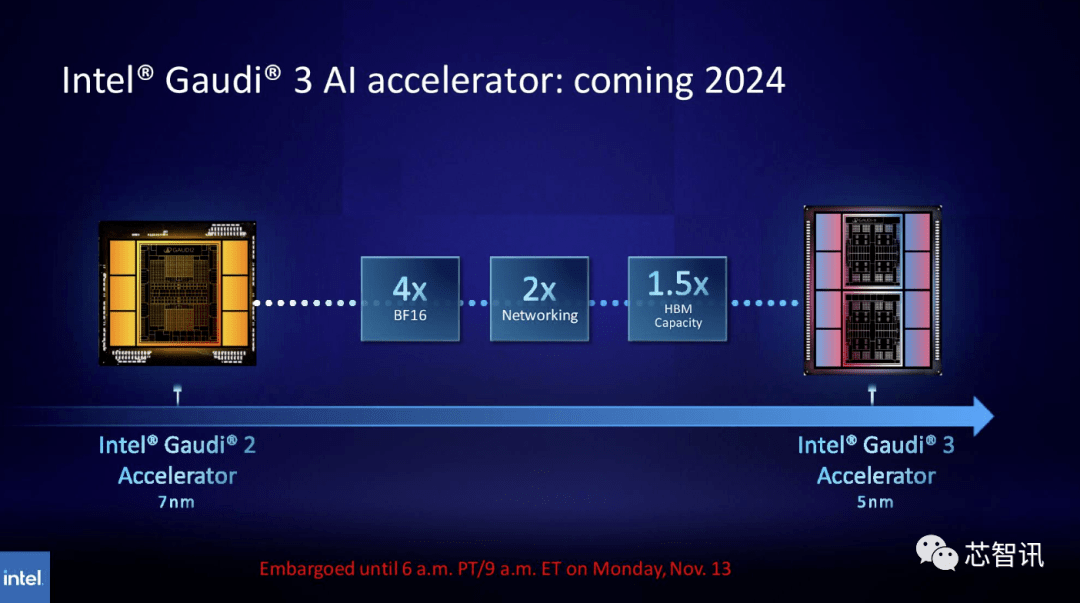
同樣,英特爾計劃提升Gaudi AI晶片的HBM容量。根據最新公佈的資訊顯示,Gaudi 3採用5nm工藝,其在BF16工作負載方面的性能將是Gaudi 2的四倍,網絡性能也將是其的兩倍(Gaudi 2有24個內置的100 GbE RoCE Nic )。此外,Gaudi 3的HBM容量是Gaudi 2的1.5倍(Gaudi 2有96 GB的HBM2E)。從下圖可以看出,Gaudi 3採用了基於chiplet的設計,具有兩個計算集群,而不像Gaudi 2使用英特爾的單晶片解決方案
全新GH200超級晶片:為下一代 AI 超級電腦提供動力
英偉達除了發表全新的H200 GPU外,還推出了升級版的GH200超級晶片。這款晶片採用了NVIDIA NVLink-C2C晶片互連技術,結合了最新的H200 GPU和Grace CPU(不確定是否為升級版)。每台GH200超級晶片也將搭載總計624GB的記憶體

作為對比,上一代的GH200則是基於H100 GPU和 72 核心的Grace CPU,提供了96GB 的 HBM3 和 512 GB 的 LPDDR5X 整合在同一個封裝中。
雖然英偉達並未介紹GH200超級晶片當中的Grace CPU細節,但是英偉達提供了GH200 和「現代雙路 x86 CPU」之間的一些比較。可以看到,GH200帶來了ICON性能8倍的提升,MILC、Quantum Fourier Transform、RAG LLM Inference等更是帶來數十倍乃至百倍的提升。
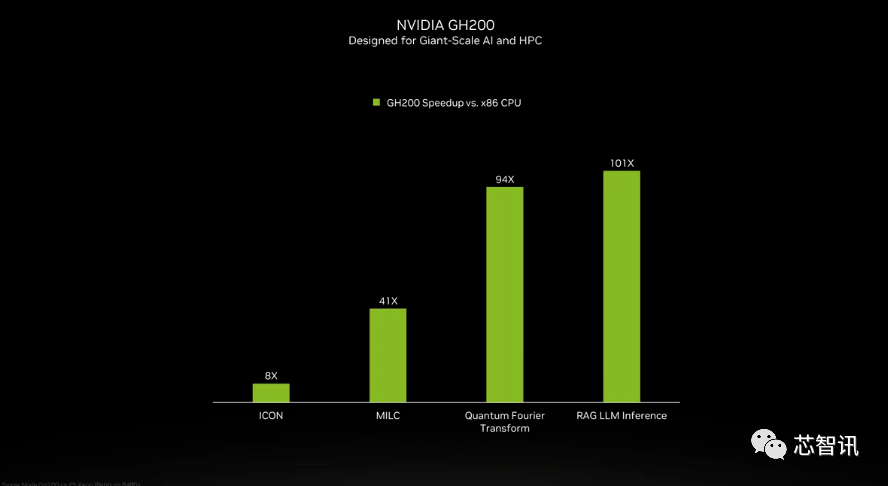
但需要指出的是,其中提到了加速與「非加速系統」。這意味著什麼?我們只能假設 x86 伺服器運行的是未完全優化的程式碼,特別是考慮到人工智慧世界正在快速發展,並且優化方面似乎定期出現新的進展。
全新的GH200 也將用於新的 HGX H200 系統。據說這些與現有的 HGX H100 系統“無縫兼容”,這意味著 HGX H200 可以在相同的安裝中使用,以提高性能和內存容量,而無需重新設計基礎設施。
據介紹,瑞士國家超級電腦中心的阿爾卑斯超級電腦可能是明年第一批投入使用的基於GH100的Grace Hopper超級電腦之一。第一個在美國投入使用的GH200系統將是洛斯阿拉莫斯國家實驗室的Venado超級電腦。德州高階運算中心(TACC) Vista系統也將使用剛剛宣布的Grace CPU和Grace Hopper超級晶片,但尚不清楚它們是基於H100還是H200

目前,即將安裝的最大的超級電腦是Jϋlich超級計算中心的Jupiter 超級電腦。它將容納「近」24000 個 GH200 超級晶片,總共 93 exaflops 的 AI 計算(大概是使用 FP8,雖然大多數 AI 仍然使用 BF16 或 FP16)。它還將提供 1 exaflop 的傳統 FP64 計算。它將使用具有四個 GH200 超級晶片的“Quad GH200”板。
英偉達預計在未來一年左右安裝的這些新型超級計算機,總體來說,將實現超過200 exaflops的人工智慧運算能力
不需要改變原始意思的情況下,需要將內容改寫成中文,不需要出現原句
以上是新標題:英偉達H200發表:HBM容量提升76%,大幅提升大模型效能90%的最強AI晶片的詳細內容。更多資訊請關注PHP中文網其他相關文章!