
AIGC時代的視訊擴散模型,復旦等團隊發表領域首篇綜述

- 王林轉載
- 2023-10-23 14:13:091463瀏覽
AI 生成內容已成為當前人工智慧領域的最熱門話題之一,也代表著該領域的前沿技術。近年來,隨著 Stable Diffusion、DALL-E3、ControlNet 等新技術的發布,AI 影像生成和編輯領域實現了令人驚豔的視覺效果,並且在學術界和工業界都受到了廣泛關注和探討。這些方法大多基於擴散模型,而這正是它們能夠實現強大可控生成、照片級生成以及多樣性的關鍵。
然而,與簡單的靜態圖像相比,視訊具有更為豐富的語義資訊和動態變化。影片能夠展示實物的動態演變過程,因此在影片生成和編輯領域的需求和挑戰更為複雜。儘管在這個領域,受限於標註數據和計算資源的限制,視頻生成的研究一直面臨困難,但是一些代表性的研究工作,比如Make-A-Video、Imagen Video 和Gen-2 等方法,已經開始逐漸佔據主導地位。
這些研究工作引領著影片產生和編輯技術的發展方向。研究數據顯示,自 2022 年以來,關於擴散模型在視訊任務上的研究工作呈現出爆炸性成長的態勢。這種趨勢不僅體現了視訊擴散模型在學術界和工業界的受歡迎程度,同時也凸顯了該領域的研究者對於視訊生成技術不斷突破和創新的迫切需求。
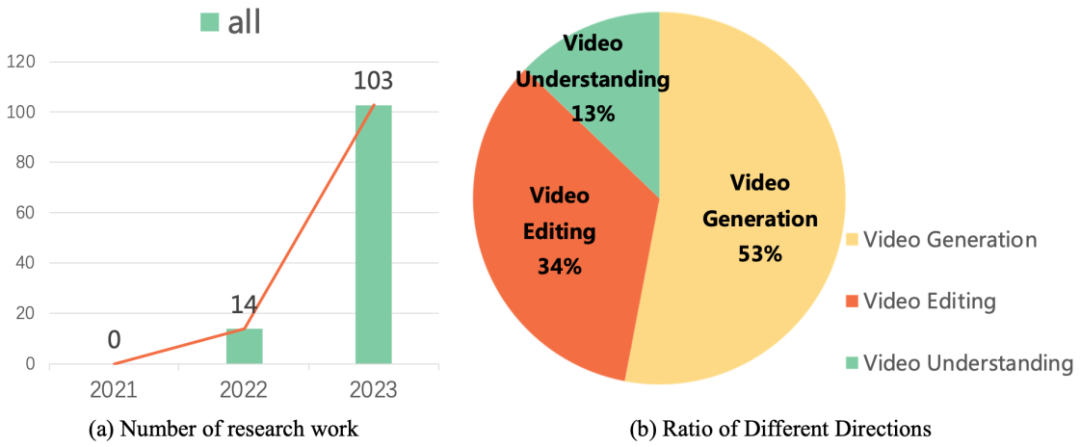
近期,復旦大學視覺與學習實驗室聯合微軟、華為等學術機構發布了首個關於擴散模型在視訊任務工作的綜述,系統梳理了擴散模型在視訊生成、視訊編輯以及視訊理解等方向的學術前沿成果。

- 論文連結:https://arxiv.org/abs/2310.10647
- #主頁連結:https://github.com/ChenHsing/Awesome-Video-Diffusion-Models
影片產生
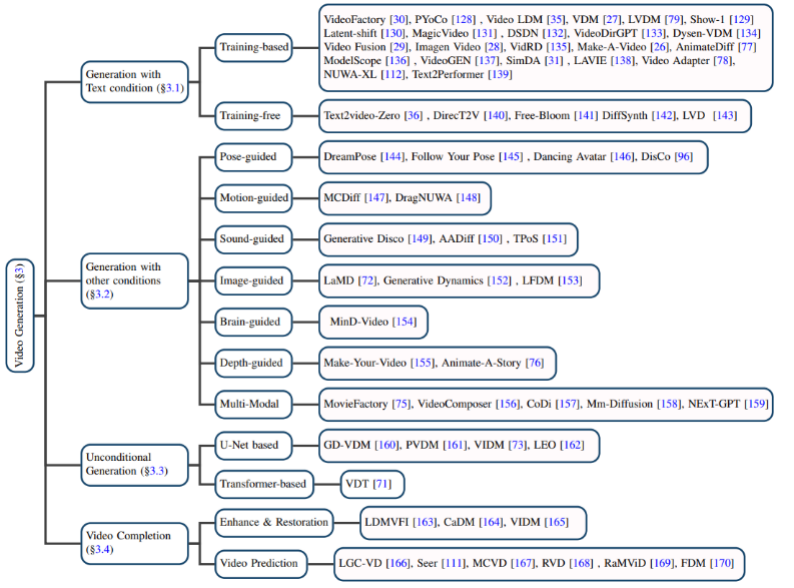
基於文字的視訊生成:自然語言作為輸入的視訊生成是視訊生成領域最為重要的任務之一。作者首先回顧了擴散模型提出先前該領域的研究成果,然後分別介紹了基於訓練的和無需訓練的文本 - 視頻生成模型。

Christmas tree holiday celebration winter snow animation.
基於其他條件的影片生成:細分領域的影片產生工作。作者將它們歸類為基於以下的條件:姿勢(pose-guided)、動作(motion-guided)、聲音(sound-guided)、圖像(image-guided)、深度圖(depth-guided)等。


#無條件的影片產生: 此任務指的是特定領域中無需輸入條件的影片生成,作者根據模型架構主要分為基於U-Net 和基於Transformer 的生成模型。
影片補全:主要包含影片增強與復原、影片預測等任務。
資料集:影片產生任務所用到的資料集可分為以下兩類:
#1.Caption-level:每個影片都有與之對應的文字描述訊息,最具代表性的就是WebVid10M 資料集。
2.Category-level:影片只有分類標籤而沒有文字描述訊息,UCF-101 是目前在影片產生、影片預測等任務上最常用的資料集。
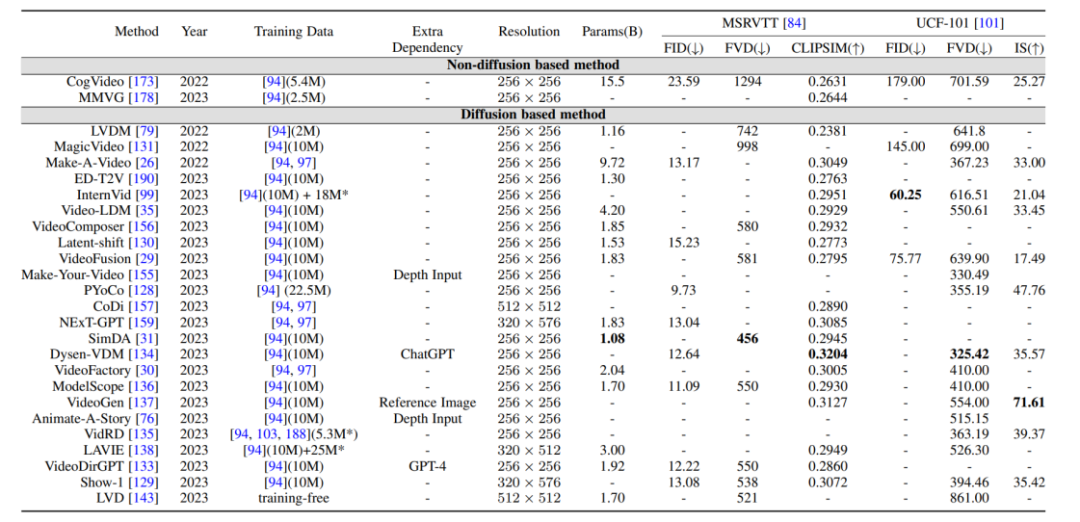
評估指標與結果比較:影片產生的評估指標主要分為品質層面的評估指標與量化層面的評估指標,品質層面的評估指標主要是基於人工主觀評分的方式,而定量層面的評估指標又可分為:
1. 影像層面的評估指標:影片是由一系列的影像幀所組成的,因此影像層面的評估方式基本上參照T2I 模型的評估指標。
2. 影片層面的評估指標:相較於影像層面的評量指標較偏向逐格的衡量,影片層面的評量指標能夠衡量產生影片的時序連貫性等方面。
此外,作者也將前述提到的生成模型在基準資料集上的評估指標進行了橫向比較。
影片編輯
#透過對許多研究的梳理,作者發現影片編輯任務的核心目標在於實現:
1. 保真度(fidelity):編輯後的影片的對應影格應與原始影片在內容上保持一致。
2. 對齊性(alignment):編輯後的影片需要和輸入的條件保持對齊。
3. 高品質(high quality):編輯後的影片應當是連貫且高品質的。
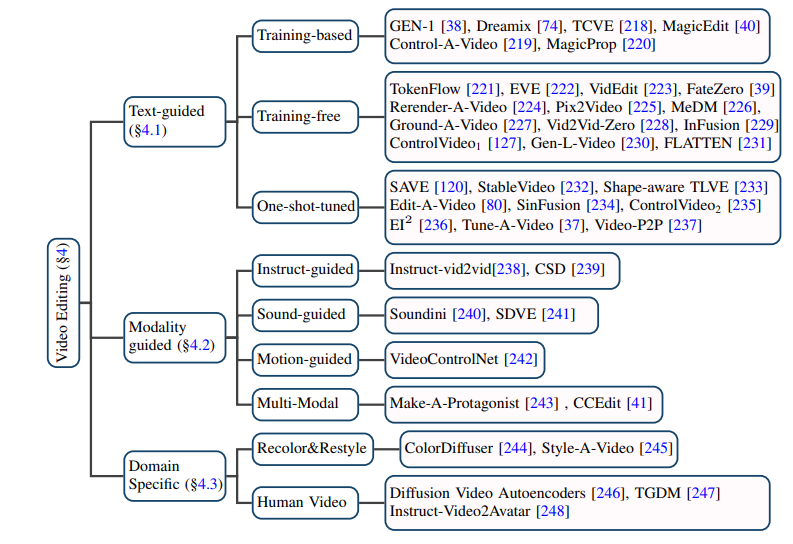
基於文字的影片編輯:考慮到現有文字- 影片資料規模有限,目前大多數基於文字的影片編輯任務都傾向於利用預先訓練的T2I 模型,在此基礎上解決視訊幀的連貫性和語義不一致性等問題。作者進一步將此類任務細分為基於訓練的(training-based)、無需訓練的(training-free)和一次性調優的(one-shot tuned)方法,分別加以總結。


#基於其他條件的影片編輯:隨著大模型時代的到來,除了最直接的自然語言訊息作為條件的影片編輯,由指令、聲音、動作、多模態等作為條件的影片編輯正受到越來越多的關注,作者也對相應的工作進行了分類梳理。
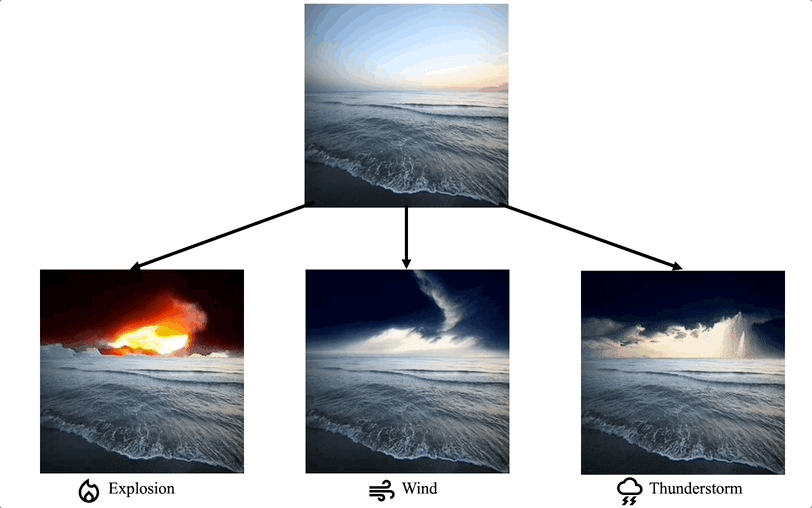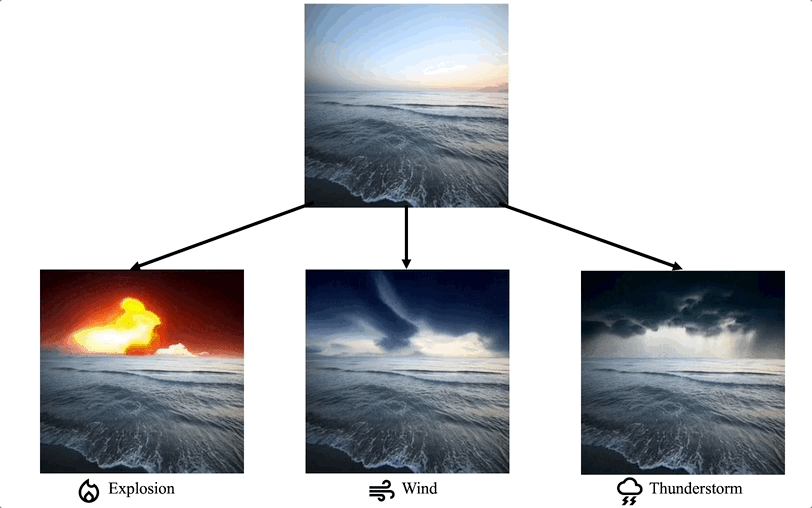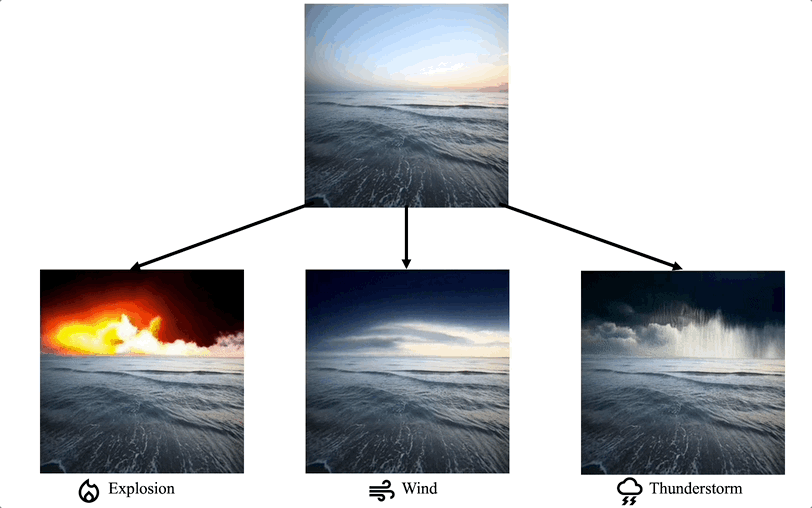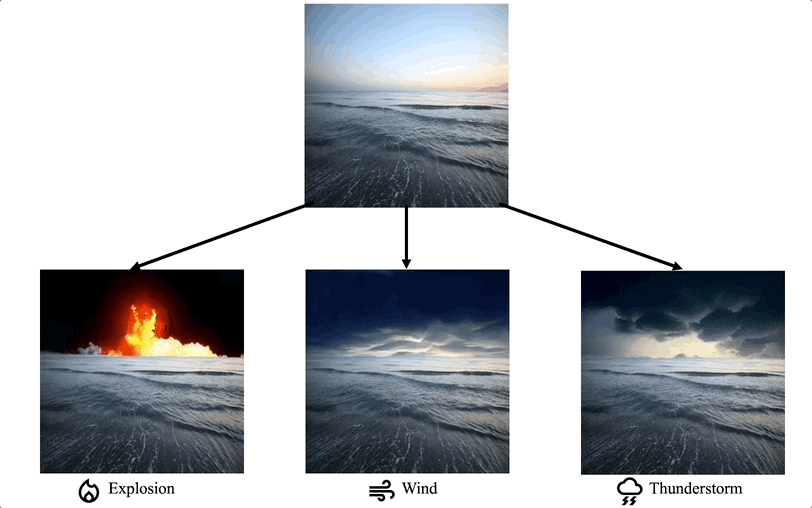
特定細分領域的影片編輯:一些工作專注於在特定領域對影片編輯任務有特殊客製化的需求,例如影片著色、人像影片編輯等。
影片理解
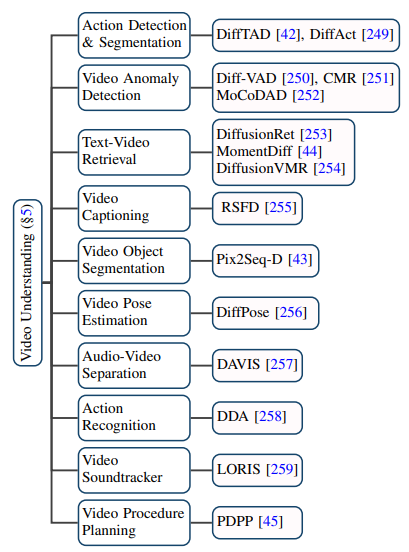
#擴散模型在影片領域的應用已遠不止傳統的影片產生和編輯任務,它在影片理解任務上也展現了出巨大的潛能。透過對前沿論文的追踪,作者歸納了視訊時序分割、視訊異常檢測、視訊物件分割、文字視訊檢索、動作識別等 10 個現有的應用場景。
未來與總結
該綜述全面細緻地總結了AIGC 時代擴散模型在視頻任務上的最新研究,根據研究對象和技術特點,將百餘份前沿工作進行了分類和概述,在一些經典的基準(benchmark)上對這些模型進行比較。此外,擴散模型在視訊任務領域也還有一些新的研究方向和挑戰,如:
1. 大規模的文本- 視訊資料集收集:T2I 模型的成功離不開數以億計高品質的文字- 影像資料集,同樣地,T2V 模型也需要大量無浮水印、高解析度的文字- 視訊資料作為支撐。
2. 高效率的訓練與推理:視訊資料比起影像資料規模龐大,在訓練與推理階段所需的算力也呈現幾何倍數增加,高效率的訓練與推理演算法能大幅降低成本。
3. 可靠的基準與評價指標:現有影片領域的評估指標往往在於衡量產生影片與原始影片在分佈上的差異,而未能全面衡量產生影片的品質.同時,目前使用者測試仍是重要的評估方式之一,考慮到其需要大量人力且主觀性強,因此迫切需要更客觀全面的評估指標。
以上是AIGC時代的視訊擴散模型,復旦等團隊發表領域首篇綜述的詳細內容。更多資訊請關注PHP中文網其他相關文章!