



知識圖譜建構中的實體關係抽取問題,需要具體程式碼範例
#隨著資訊科技的發展和網路的快速普及,大量海量的文字資料被創造和累積。這些數據包含了各種各樣的信息,但如何從這些數據中提取有用的知識成為了一個挑戰。知識圖譜的出現為解決這個問題提供了一個有效的方法。知識圖譜是一種以圖為基礎的知識表示和推理模型,透過將實體(Entity)以節點的形式連接起來,以關係(Relation)作為邊來表示實體之間的關聯,建構出一個結構化的知識網絡。
在建構知識圖譜的過程中,實體關係抽取是一個重要的環節。實體關係抽取旨在從海量文本資料中識別出實體之間的關係,將其轉化為可供電腦理解和推理的結構化資料。而實體關係抽取的核心任務就是從文本中自動辨識並抽取出實體及其關係。
為了解決實體關係抽取問題,研究者提出了各種各樣的方法和技術。以下介紹一個基於機器學習的實體關係抽取方法。
首先,需要準備訓練資料集。訓練資料集是指包含了已標註好實體和關係資訊的文字資料集。通常需要手動標註一部分資料集,來作為模型的訓練集和測試集。標註的方式可以是手工標註或半自動化標註。
接下來,需要進行特徵工程。特徵工程是將文字資料轉換為電腦可以處理的特徵向量的過程。常見的特徵有詞袋模型(Bag-of-Words)、詞嵌入(Word Embedding)和句法分析樹等。特徵工程的目的是提取出能夠表徵實體和關係的有意義的特徵,用於訓練模型。
然後,選擇一個適合的機器學習演算法進行模型訓練。常見的機器學習演算法包括支援向量機(Support Vector Machine)、決策樹(Decision Tree)和深度學習演算法等。這些演算法可以透過訓練資料集,學習到實體和關係之間的模式和規律。
最後,使用訓練好的模型對未標註的文字進行實體關係抽取。給定一個文字句子,首先使用特徵工程將其轉換為特徵向量,然後使用訓練好的模型進行預測,得到實體和關係的結果。
以下是一個簡單的Python程式碼範例,使用支援向量機演算法進行實體關係抽取:
# 导入相应的库 from sklearn.svm import SVC from sklearn.feature_extraction.text import TfidfVectorizer # 准备训练数据集 texts = ['人民', '共和国', '中华人民共和国', '中华', '国'] labels = ['人民与共和国', '中华人民共和国', '中华人民共和国', '中华与国', '中华人民共和国'] # 特征工程,使用TfidfVectorizer提取特征 vectorizer = TfidfVectorizer() features = vectorizer.fit_transform(texts) # 训练模型 model = SVC() model.fit(features, labels) # 预测 test_text = '中华共和国' test_feature = vectorizer.transform([test_text]) predicted = model.predict(test_feature) print(predicted)
以上程式碼範例中,我們首先準備了一組訓練資料集,其中包含了一些實體和關係的文字訊息。再使用TfidfVectorizer對文字進行特徵提取,得到特徵向量。接著使用支援向量機演算法進行模型訓練,最後對未標註的文字進行實體關係抽取預測。
總結而言,知識圖譜建構中的實體關係抽取問題是一個重要的研究方向,透過機器學習的方法可以有效地解決這個問題。但實體關係抽取仍存在一些挑戰,如語義歧義、上下文資訊等。未來隨著科技的不斷發展和創新,相信這個問題會得到更好的解決。同時,我們也需要注意在實務上遵循資料隱私和知識倫理等相關議題,確保知識圖譜建構的合法性和可信度。
以上是知識圖譜建構中的實體關係抽取問題的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 火箭發射模擬和分析使用Rocketpy -Analytics VidhyaApr 19, 2025 am 11:12 AM
火箭發射模擬和分析使用Rocketpy -Analytics VidhyaApr 19, 2025 am 11:12 AM模擬火箭發射的火箭發射:綜合指南 本文指導您使用強大的Python庫Rocketpy模擬高功率火箭發射。 我們將介紹從定義火箭組件到分析模擬的所有內容
 5個免費數據分析課程 - 分析VidhyaApr 19, 2025 am 11:11 AM
5個免費數據分析課程 - 分析VidhyaApr 19, 2025 am 11:11 AM踏上數據驅動的職業旅程而不會破壞銀行! 本文重點介紹了五個非凡的免費數據分析課程,非常適合兩位經驗豐富的專業人士,他們尋求擴大技能和好奇的新手渴望探索T
 如何使用OpenAgi構建自主AI代理? - 分析VidhyaApr 19, 2025 am 11:10 AM
如何使用OpenAgi構建自主AI代理? - 分析VidhyaApr 19, 2025 am 11:10 AM利用AI代理商的力量與OpenAgi:綜合指南 想像一下不懈的助手,總是可以簡化您的任務並提供有見地的建議。這就是AI代理商的承諾,Openagi賦予您建造它們
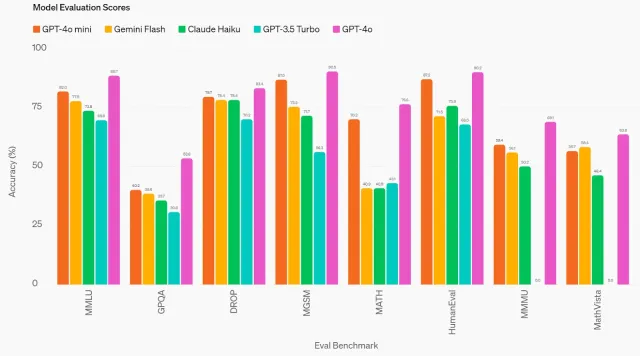 GPT-4O MINI:OpenAI的最新模型如何堆疊?Apr 19, 2025 am 11:09 AM
GPT-4O MINI:OpenAI的最新模型如何堆疊?Apr 19, 2025 am 11:09 AMOpenai的最新產品GPT-4O Mini標誌著朝著負擔得起且可訪問的高級AI邁出的重要一步。 這種小型語言模型(SLM)直接挑戰諸如Llama 3和Gemma 2之類的競爭對手,具有低潛伏期,成本效益和A
 從技術創新者到醫療保健先驅:Geetha Manjunath博士的AI故事Apr 19, 2025 am 11:02 AM
從技術創新者到醫療保健先驅:Geetha Manjunath博士的AI故事Apr 19, 2025 am 11:02 AMNiramai Analytix的創始人兼首席執行官Geetha Manjunath博士的這一集由“領導數據”的劇集。 Manjunath博士擁有AI和Healthcare的25年以上的經驗,並獲得了印度科學學院的博士學位和MBA來回。
 用Ollama -Analytics Vidhya簡化本地LLM部署Apr 19, 2025 am 11:01 AM
用Ollama -Analytics Vidhya簡化本地LLM部署Apr 19, 2025 am 11:01 AM利用Ollama本地開源LLMS的力量:綜合指南 運行大型語言模型(LLMS)本地提供無與倫比的控制和透明度,但是設置環境可能令人生畏。 Ollama簡化了這個過程
 如何使用Monsterapi微調大語言模型Apr 19, 2025 am 10:49 AM
如何使用Monsterapi微調大語言模型Apr 19, 2025 am 10:49 AM利用微調LLM的功能與Monsterapi:綜合指南 想像一個虛擬助手完美理解並預測您的需求。 由於大型語言模型(LLMS)的進步,這已成為現實。 但是,
 5統計測試每個數據科學家都應該知道-Analytics VidhyaApr 19, 2025 am 10:27 AM
5統計測試每個數據科學家都應該知道-Analytics VidhyaApr 19, 2025 am 10:27 AM數據科學的基本統計測試:綜合指南 從數據中解鎖有價值的見解至關重要。 掌握統計測試對於實現這一目標至關重要。這些測試使數據科學家能夠嚴格瓦爾


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

MinGW - Minimalist GNU for Windows
這個專案正在遷移到osdn.net/projects/mingw的過程中,你可以繼續在那裡關注我們。 MinGW:GNU編譯器集合(GCC)的本機Windows移植版本,可自由分發的導入函式庫和用於建置本機Windows應用程式的頭檔;包括對MSVC執行時間的擴展,以支援C99功能。 MinGW的所有軟體都可以在64位元Windows平台上運作。

SublimeText3漢化版
中文版,非常好用

EditPlus 中文破解版
體積小,語法高亮,不支援程式碼提示功能

Atom編輯器mac版下載
最受歡迎的的開源編輯器

禪工作室 13.0.1
強大的PHP整合開發環境

