在大模型對千行百業的改造過程中,火山引擎率先交出了一份數據產業的個人化答案。 9 月19 日,在上海舉辦的「資料飛輪・V-Tech 資料驅動科技高峰會」 上,火山引擎宣佈數智平台VeDI 應用大模型(Large Language Models)能力。 產品升級後,能夠實現用自然語言「找數」、輔助數倉模型研發、最佳化程式碼,同時還能完成視覺化圖表的生成,對話時實現歸因分析等功能。 即使沒有程式碼能力的一般營運人員也能快速找數和分析。目前,VeDI 相關資料產品已啟動邀測。 升級後的資料產品大大拉低了使用資料的門檻。 以往,一個普通營運希望找數,往往需要求助研發人員,由研發人員編寫程式碼幫助取數,分析一個資料需要結合眾多專業知識。而現在,借助升級後的數據產品,營運人員可以隨時用自然語言輸入自己的需求,即時拿到自己想要的數據。 這將進一步激發資料的價值。在企業內部,更低的使用門檻能夠數據消費鏈條上的更多人能夠開始接觸數據、使用數據,以往被現實門檻壓抑的數據需求將會被滿足,業務基於數據的洞察將會更加及時、決策將更科學、更多基於數據的商業想像將被釋放。 對於正在數位化進程中的企業來說,資料價值將在更高頻率的流轉中被釋放,資料飛輪將被進一步加速。 大模型融入資料全鏈路,進一步降低資料生產、使用門檻相較於小模型,大模型擁有強大的泛化推理能力、外部工具調取能力、程式碼產生能力。這些能力對於數據產品而言,有著重大的影響。 更強的泛化推理能力意味著更高的智能性,但同時,也需要結合許多工具的調各項能力,例如數學及分析能力等作為補充。 而大模型時代開啟的自然語言互動模式,也為資料產品的使用方式帶來了新的想像空間。 今年3 月開始,位元組內部開始將大模型與資料產品結合,在快速迭代的小範圍測試中,很快羅旋團隊發現,在資料產品的主要場景中,大模型帶來的提升和改變都是明顯的。隨後,團隊開始在數據產品的場景中大規模嘗試,不斷量化場景的優先級,並推動大模型在產品中落地。 在大模型對資料產業的改造過程中,場景的選擇是最關鍵的步驟之一,一個合適的使用情境不僅需要在目前的技術或可預期的技術上成立,還需要確保加持大模型後用戶或業務方能夠有更好的使用體驗,同時帶來更多的數據消費價值,能夠進一步帶動數據生產。 羅旋分享稱,例如,如果在一些場景中原有解決方案整體只需要花費1-2 秒,使用了大模型之後,由於大模型延遲問題,用自然語言可能要到5 秒以上,那這個場景就不能滿足業務對於時效性的體驗需求,就是不成立的。 「但是,例如在短程式碼生成環節,加入自然語言後,場景效率提升便十分明顯。未來,隨著大模型的效能不斷提升,在數據全連結的各個環節,大模型能帶來的智慧化改變將更值得期待。」在此次的「資料飛輪・V-Tech 資料驅動科技高峰會」 上,火山引擎所宣布的關於數智平台VeDI 的產品升級主要包括了DataLeap 以及DataWind 兩個部分。其中,DataLeap 中的 「找數助手」 能夠支援以問答方式進行找數,「開發助理」 能夠支援以自然語言產生、最佳化 SQL 程式碼;DataWind - 分析助理則能夠支援自然語言完成資料視覺化查詢與分析。 涵蓋了找數、取數以及分析全鏈路,為資料生產與消費全流程降低了技術門檻。 「找數」 通常是數據消費全鏈條的第一步,找到正確的數據資產,才能實現數據的消費。但是,在傳統流程中的 「找數」 並不是一個簡單的工作,需要強依賴業務專業知識的輸入,通常人們只能透過關鍵字的檢索,再進行人為篩選或尋求專業資料開發人員才能確認。 
“找數助手” 功能,透過與大語言模型(LLM)結合,大大降低了“找數” 的門檻。 利用“找數助手”,沒有代碼能力的人員也能夠通過自然語言進行“擬人化” 查詢,比如一位電商運營可以直接提問:“最近7 天好物直播間的經營狀況,要用哪些表?」。 DataLeap - 找數助理會根據業務的知識庫,推薦與經營狀況相關的表,並解釋每張表對應的資料維度。 目前,「找數助理」 能夠實現包含Hive 資料表、資料集、儀表板、資料指標、維度等多種資料型別及相關業務知識的問答式檢索,實現擬人化查詢。 另外,除了「找數」 變得更加簡單,結合了大模型能力的「找數助手」 還能讓「找數」 的準確率進一步提高。過去傳統技術方案下,資料資產檢索依賴資料結構化管理,非結構化的業務資料則可能關聯缺失,用關鍵字進行檢索時,產生的連結割裂問題,可能會大幅降低基於業務場景的數據尋找和消費效率。此外,檢索提供的是基於關鍵字的候選答案集合,需要人為再次篩選確認,而不是直接的答案,導致使用者很難有良好體驗。 而現在,在與使用者對話式的過程中,大語言模型(LLM) 可以理解使用者真實意圖,讓搜尋過程更聚焦,節約了人為判斷的成本,「找數」 本身變得更快,同時,伴隨模型語意理解分析能力的逐步提升,對話式檢索相比單純地用關鍵字檢索的方式,其全鏈路的檢索效率也更高。 在資料生產加工環節,“開發助手”能夠支援使用自然語言,自動產生SQL 程式碼;針對現有的程式碼可以自動實作Bug 修復,程式碼最佳化、解釋與註解等,此外還可以透過對話方式實現文件搜尋、函數使用、程式碼範例等SQL 使用類別的問題諮詢。
#####################################44語言模型。 ,經過大量的程式碼和語料訓練,可以根據使用者的自然語言輸入,自動關聯包括表Schema 在內的元資料訊息,產生高品質的資料加工程式碼,並具備程式碼的理解、改寫以及問答能力。 ############
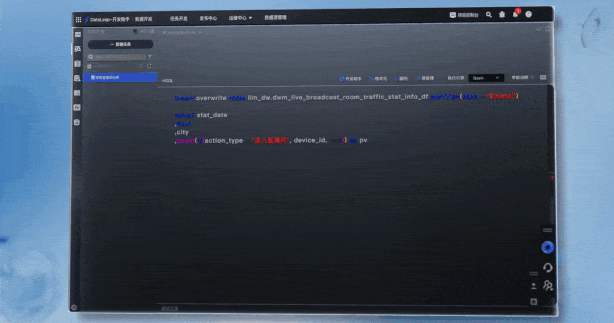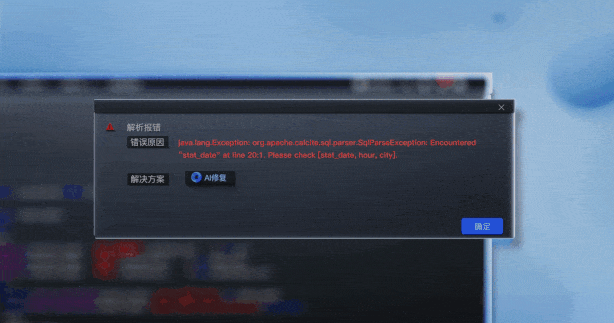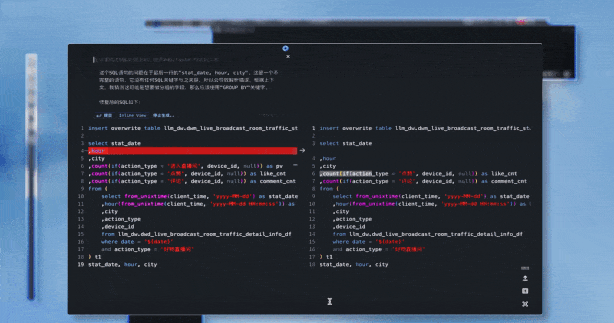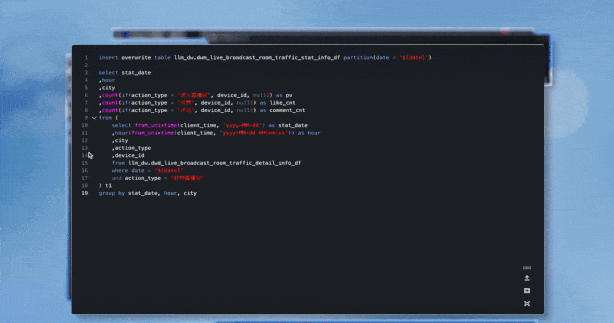
#11開發基礎上降低了資料門檻上的資料門檻。 「原來(加工)資料這件事你可能要會一門程式語言,例如SQL 或Python,這是一個相對強的技能需求。但是,現在你可以不再需要程式語言,可以使用自然語言。那麼,這意味著做這件事的人的要求,也進一步降低。」#對於有資料消費訴求的分析師和營運人員,不懂SQL也可以做一些基礎ETL。 營運人員可以讓 DataLeap 自動產生對應經營狀況的資料需求代碼,例如分城市的訂單銷售,或分時段的直播間流量等。營運人員還能追問程式碼的含義,例如 “這張表在運行期間,有什麼優化方案嗎?”,也可以對話:“幫我檢查、修復這串程式碼”。也能夠一鍵解析產生的程式碼,呼叫 SQL 工具做表的檢查,點選確認 AI 自動修復,進一步優化資料資產。 更重要的是,對於專業研發人員來說,DataLeap - 開發助理可以幫助他們做一些基礎性的工作,處理來自資料分析師、依賴資料的業務營運人員的一些繁雜但基礎的需求,工程師只需要在最後校正和核對所產生程式碼的準確性。 於是,研發人員能夠將精力放在更有創意的工作上,更聚焦複雜場景的需求,利用開發助手優化程式碼,提高研發生產效率與程式碼品質。 在實作找數和取數之後,來到了數據分析環節。結合了大模型能力的 DataWind - 分析助手,能夠幫助非分析崗位的人員,透過自然語言對話,可完成資料視覺化查詢與分析等一系列業務探索,降低此環節的門檻。 首先是 「資料集」 的建立。有了資料資產,營運人員透過 DataWind 拖曳方式做資料集的創建,然後使用自然語言的方式去定義不同欄位的邏輯,例如直接查 「大咖直播時段」 的資料。
##'幫助 -B不同分析領域的分析。過去BI 工具,普遍採用拖拉拽的操作方式,雖然在儀錶板製作上已經降低了門檻,但在分析洞察領域,依舊需要大量專業知識的輸入,才能更好地理解數據,這是一道“門檻” 。 可視化探索
######但通過大模型更強泛化推理能力的加持,DataWind 已經能夠進行基礎的假設與驗證,提出分析思路。 ###DataWind 提供的 AI 自動分析功能,能夠支持其根據圖表進一步探索背後的原因。比方說在產生的 「直播間分時段流量圖」、「直播間銷售額地區 Top」 等視覺化圖表中,AI 能自動分析,營運人員只需基於分析結果,透過對話形式進一步歸因。 ###############同時,DataWind 也聯通飛書等辦公室協同工具,使用者透過IM 訊息訂閱、自然對話,進行更多延展分析,實現隨時隨地的彈性分析,滿足從數據集、視覺化洞察、訊息訂閱等全鏈路上的自助智能,聯通辦公集成,讓數據分析無縫融入日常。 ############
##水平語言對話直接了解結果,資料分析思考週期大幅縮短,解決過去分析洞察上需要大量專業知識的痛點,縮短資料分析週期。
現階段DataWind - 分析助手的應用場景已經十分豐富,除了在核心的分析場景可以實現對話式探索之外,分析助手還將能力延展到了表達式生成等過去需要更多技術門檻的場景。
位元組跳動擁有深厚的數據驅動基因。自成立以來,位元組跳動內部幾乎所有場景都會落到A/B 測試,透過資料回饋驅動業務的策略進行調整,例如抖音影片畫質的最佳化效果好不好、推薦演算法策略優化準不準、甚至今日頭條的名字,也經過A/B 測試。
在位元組內部,資料消費的範圍很廣。組織上,從高層到中層,以及第一線員工基本上實現全員看數,透過數據來評估公司的經營狀況、收支狀況、業務進度、產品策略。在具體場景上,例如在直播電商中的即時行銷中,營運根據即時數據進行對應的行銷策略設計和推送 push。
字節透過數據消費實現了決策科學、行動敏捷,帶來業務價值提升;也透過頻繁的數據消費和業務收益,有的放矢低成本建設高質量的數據資產,更好地支撐業務應用。 今年4 月,火山引擎基於字節跳動十餘年數據驅動的實踐經驗,曾對外發布企業數智化升級新範式“數據飛輪”,用「資料飛輪」 來概括企業資料流充分融入業務流程後,能夠實現資料資產與業務應用提升的飛輪效應。
在整個數位化的大趨勢下,千行百業的企業業務都在與數位化更加緊密,而資料對於企業而言越來越重要。作為新型生產要素,數據正支撐企業的數智轉型。但客觀來看,雖然不少企業數位化建設較多,卻無法較好釋放數據價值。
「一家企業可能花費高昂的價格部署了數據產品,但是可能內部真正使用的人卻寥寥無幾,數據難以流動就很難發揮價值。」羅旋在資料產品市場觀察到,許多正在進行數位化建設的企業,存在著資料建置與管理成本高、資料產品使用門檻高、資料資產價值低的問題。 而從整個數位化進程來看,要達到 “數據驅動”,是一件難而正確的事。以位元組為例,羅旋透露稱,目前,位元組跳動內部 80% 的員工可以直接使用資料產品,可管理、營運的資料資產覆蓋 80% 的日常分析場景。從位元組經驗來看,這意味著,企業內部數據產品的使用率以及可管理運營的數據資產在場景中的覆蓋率都需要提升到較高的水平,才能在公司形成良好的“數據飛輪” 。
在這個過程中,大模型加持下的資料產品或許是幫助企業達成目標的重要推手。 經過大模型能力升級後的數智平台 VeDI 進一步降低了找數、取數以及資料分析等資料生產和消費的全環節。在同樣的需求水準下,使用升級後的VeDI,公司中有能力使用數據產品的人從專業的數據分析師擴張到了所有有數據需求的人,可能是營運、老闆、產品經理等等角色,數據消費變得普惠。 ###############“只有降低門檻,把數據用起來了,才知道數據在流轉中到底會產生什麼樣的價值”,對於剛剛邁入數字化進程的公司而言,數據的價值是一座遠遠沒有被開掘的寶藏,更低門檻的數據產品可能是一把開啟的鑰匙。 ##################在大模型加持下,企業內部的 「資料飛輪」 將加速旋轉。 ###公司業務擁有了更強大的引擎,業務人員能夠從「秒出數據」 中快速得到數據反饋,從而對業務進行更快優化,在數據加速流轉過程中,更多高質量數據資產的不斷沉澱帶給業務更多的洞察,最終讓業務決策更科學、更敏捷。 ###
以上是用火山引擎,大模型將資料飛輪「點燃」的詳細內容。更多資訊請關注PHP中文網其他相關文章!