
基於AI演算法的資料庫異常監測系統的設計與實現

- WBOY轉載
- 2023-04-12 18:37:06908瀏覽
作者:曹臻威遠
美團資料庫平台研發組,面臨日益急迫的資料庫異常發現需求,為了更快速、聰明地發現、定位和停損,我們開發了基於AI演算法的資料庫異常檢測服務。
1. 背景
資料庫被廣泛用於美團的核心業務場景上,對穩定性要求較高,對異常容忍度非常低。因此,快速的資料庫異常發現、定位和停損就變得越來越重要。針對異常監控的問題,傳統的固定閾值警告方式,需要依賴專家經驗進行規則配置,不能根據不同業務場景靈活動態調整閾值,容易讓小問題演變成大故障。
而基於AI的資料庫異常發現能力,可以基於資料庫歷史表現情況,對關鍵指標進行7*24小時巡檢,能夠在異常萌芽狀態就發現風險,更早地將異常暴露,輔助研發人員在問題惡化前進行定位和停損。基於以上這些因素的考量,美團資料庫平台研發組決定開發一套資料庫異常檢測服務系統。接下來,本文將會從特徵分析、演算法選型、模型訓練與即時檢測等幾個維度闡述我們的一些思考與實踐。
2. 特徵分析
2.1 找出資料的變化法則
在具體進行開發編碼前,有一項非常重要的工作,就是從現有的歷史監控指標中,發現時序資料的變化規律,從而根據資料分佈的特性選取適當的演算法。以下是我們從歷史資料中選取的一些具代表性的指標分佈圖:
圖1 資料庫指標形態
從上圖我們可以看出,資料的法則主要呈現三種狀態:週期、漂移和平穩[1]。因此,我們前期可以針對這些普遍特徵的樣本進行建模,即可涵蓋大部分場景。接下來,我們分別從週期性、漂移性和平穩性這三個角度進行分析,並討論演算法設計的過程。
2.1.1 週期性變化
在許多業務場景中,指標會因為早晚高峰或一些定時任務造成規律性波動。我們認為這屬於資料的內在規律性波動,模型應該具備識別出週期性成分,並檢測情境異常的能力。對於不存在長期趨勢成分的時序指標而言,當指標存在週期性成分的情況下,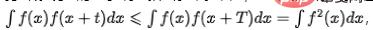 ,其中T代表的是時序的周期跨度。可透過計算自相關圖,即計算出t取不同值時
,其中T代表的是時序的周期跨度。可透過計算自相關圖,即計算出t取不同值時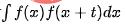 的值,然後透過分析自相關峰值的間隔來確定週期性,主要的流程包括以下幾個步驟:
的值,然後透過分析自相關峰值的間隔來確定週期性,主要的流程包括以下幾個步驟:
- 擷取趨勢成分,分離出殘差序列。使用移動平均法提取出長期趨勢項,跟原序列作差得到殘差序列(此處週期性分析與趨勢無關,若不分離趨勢成分,自相關將顯著受到影響,難以辨識週期)。
- 計算殘差的循環自相關(Rolling Correlation)序列。透過循環移動殘差序列後,與殘差序列進行向量點乘運算來計算自相關序列(循環自相關可以避免延遲衰減)。
- 根據自相關序列的峰值座標來決定週期T。提取自相關序列的一系列局部最高峰,取橫座標的間隔為週期(如果該週期點對應的自相關值小於給定閾值,則認為無顯著週期性)。
具體過程如下:
#
图2 周期提取流程示意
2.1.2 漂移性变化
对于待建模的序列,通常要求它不存在明显的长期趋势或是存在全局漂移的现象,否则生成的模型通常无法很好地适应指标的最新走势[2]。我们将时间序列随着时间的变化出现均值的显著变化或是存在全局突变点的情况,统称为漂移的场景。为了能够准确地捕捉时间序列的最新走势,我们需要在建模前期判断历史数据中是否存在漂移的现象。全局漂移和周期性序列均值漂移,如下示例所示:

图3 数据漂移示意
数据库指标受业务活动等复杂因素影响,很多数据会有非周期性的变化,而建模需要容忍这些变化。因此,区别于经典的变点检测问题,在异常检测场景下,我们只需要检测出历史上很平稳,之后出现数据漂移的情况。综合算法性能和实际表现,我们使用了基于中位数滤波的漂移检测方法,主要的流程包含以下几个环节:
1. 中位数平滑
a. 根据给定窗口的大小,提取窗口内的中位数来获取时序的趋势成分。
b. 窗口需要足够大,以避免周期因素影响,并进行滤波延迟矫正。
c. 使用中位数而非均值平滑的原因在于为了规避异常样本的影响。
2. 判断平滑序列是否递增或是递减
a. 中位数平滑后的序列数据,若每个点都大于(小于)前一个点,则序列为递增(递减)序列。
b. 如果序列存在严格递增或是严格递减的性质,则指标明显存在长期趋势,此时可提前终止。
3. 遍历平滑序列,利用如下两个规则来判断是否存在漂移的现象
a. 当前样本点左边序列的最大值小于当前样本点右边序列的最小值,则存在突增漂移(上涨趋势)。
b. 当前样本点左边序列的最小值大于当前样本点右边序列的最大值,则存在突降漂移(下跌趋势)。
2.1.3 平稳性变化
对于一个时序指标,如果其在任意时刻,它的性质不随观测时间的变化而变化,我们认为这条时序是具备平稳性的。因此,对于具有长期趋势成分亦或是周期性成分的时间序列而言,它们都是不平稳的。具体示例如下图所示:

图4 数据平稳示意
针对这种情况,我们可以通过单位根检验(Augmented Dickey-Fuller Test)[3]来判断给定的时间序列是否平稳。具体地说,对于一条给定时间范围指标的历史数据而言,我们认为在同时满足如下条件的情况下,时序是平稳的:
- 最近1天的時序資料透過adfuller檢定所得的p值小於0.05。
- 最近7天的時序資料經由adfuller檢定所得的p值小於0.05。
3. 演算法選型
3.1 分佈規律與演算法選擇
透過了解業界的一些知名公司在時序資料異常檢測上所發表的產品介紹,加上我們歷史累積的經驗,以及對部分線上實際指標的抽樣分析,它們的機率密度函數符合如下情況的分佈:

圖5 分佈偏斜示意
針對上述的分佈,我們研究了一些常見的演算法,並確定了箱形圖、絕對中位數差和極值理論作為最終異常檢測演算法。以下是常見時序資料偵測的演算法比較表:

#我們沒有選擇3Sigma的主要原因是它對異常容忍度較低,而絕對中位數差從理論上具有更好的異常容忍度,所以在數據呈現高對稱分佈時,透過絕對中位數差(MAD)取代3Sigma進行檢測。我們對不同資料的分佈分別採用了不同的偵測演算法(關於不同演算法的原理可以參考文末附錄的部分,這裡不做過多的闡述):
- #低偏態高對稱分佈:絕對中位數差(MAD)
- 中偏態分佈:箱形圖(Boxplot)
- #高偏態分佈:極值理論(EVT)
有瞭如上的分析,我們可以得到具體的根據樣本輸出模型的流程:

圖6 演算法建模流程
演算法的整體建模流程如上圖所示,主要涵蓋以下幾個分支環節:時序漂移偵測、時序平穩性分析、時序週期性分析和偏度計算。以下分別進行介紹:
- 時序漂移偵測。如果偵測存在漂移的場景,則需要根據偵測所獲得的漂移點t來切割輸入時序,並使用漂移點後的時序樣本作為後續建模流程的輸入,記為S={Si},其中i>t。
- 時序平穩性分析。如果輸入時序S滿足平穩性檢驗,則直接透過箱型圖(預設)或是絕對中位數差的方式來進行建模。
- 時序週期性分析。存在週期性的情況下,將週期跨度記為T,將輸入時序S根據跨度T進行切割,針對各個時間索引j∈{0,1,⋯,T−1}所組成的資料桶進行建模流程。在不存在週期性的情況下,針對全部輸入時序S作為資料桶進行建模流程。
案例:給定一條時間序列ts={t0,t1,⋯ ,tn},假設其存在週期性且週期跨度為T,對於時間索引j而言,其中j∈{0,1,⋯,T−1},對其建模所需的樣本點由區間[tj−kT−m, tj−kT m]構成,其中m為參數,代表視窗大小,k為整數,滿足j−kT −m≥0, j−kT m≤n。舉例來說,假設給定時序自2022/03/01 00:00:00至2022/03/08 00:00:00止,給定視窗大小為5,週期跨度為一天,那麼對於時間索引30而言,對其建模所需的樣本點將來自於以下時間段:[03/01 00:25:00, 03/01 00:35:00]
[03/02 00:25:00, 03/02 00:35:00]
...
[03/07 00:25:00, 03/07 00:35:00]
- #偏態計算。時序指標轉換為機率分佈圖,計算分佈的偏度,若偏度的絕對值超過閾值,則透過極值理論進行建模輸出閾值。若偏度的絕對值小於閾值,則透過箱形圖或是絕對中位差的方式進行建模輸出閾值。
3.2 案例樣本建模
這裡選取了一個案例,展示資料分析及建模過程,以便更清晰的理解上述過程。其中圖(a)為原始序列,圖(b)為依照天的跨度進行折疊的序列,圖(c)為圖(b)中某時間索引區間內的樣本經過放大後的趨勢表現,圖(d )中黑色曲線為圖(c)中時間索引所對應的下閾值。如下是針對某時序的歷史樣本進行建模的案例:

圖7 建模案例
上圖(c)區域內的樣本分佈直方圖以及閾值(已剔除其中部分異常樣本),可以看到,在該高偏分佈的場景中,EVT演算法計算的閾值更為合理。

圖8 偏斜分佈閾值比較
4.模型訓練與即時偵測
4.1 資料流轉過程
為了即時偵測規模龐大的秒級數據,我們以基於Flink進行即時串流處理為出發點,設計如下的技術方案:
- 即時偵測部分:基於Flink即時串流處理,消費Mafka(美團內部的訊息佇列元件)訊息進行線上偵測,結果儲存於Elasticsearch(以下簡稱ES)中,並產生異常記錄。
- 離線訓練部分:以Squirrel(美團內部的KV資料庫)作為任務隊列,從MOD(美團內部維運資料倉儲)讀取訓練數據,從配置表讀取參數,訓練模型,儲存於ES,支援自動和手動觸發訓練,透過定時讀取模型庫的方式,進行模型載入和更新。
以下是特定的離線訓練與線上偵測技術設計:

圖9離線訓練與線上偵測技術設計
4.2 異常偵測過程
異常偵測演算法整體採用分治思想,在模型訓練階段,根據歷史資料辨識擷取特徵,選定合適的檢測演算法。這裡分為離線訓練和線上偵測兩部分,離線主要根據歷史情況進行資料預處理、時序分類和時序建模。線上主要載入運用離線訓練的模型進行線上即時異常檢測。具體設計如下圖所示:

#圖10 異常檢測過程
5.產品營運
為了提高優化迭代演算法的效率,持續運作以提高精準率和召回率,我們藉助Horae(美團內部可擴展的時序資料異常檢測系統)的案例回溯能力,實現線上檢測、案例保存、分析優化、結果評估、發布上線的閉環。

圖11 營運流程
##目前,異常偵測演算法指標如下:
- 精準率#:隨機選擇一部分偵測出異常的案例,人工校驗其中確實是異常的比例,為81%。
- 召回率:根據故障、警告等來源,檢視對應實例各指標異常情況,對照監測結果計算召回率,為82%。
- F1-score:精準率和召回率的調和平均數,為81%。
6. 未來展望
#目前,美團資料庫異常監測能力已基本建置完成,後續我們將對產品繼續進行最佳化和拓展,具體方向包括:#
- 具有例外類型辨識能力。可以偵測出異常的類型,如平均值變化、波動變化、尖刺等,支援以異常類型進行警告訂閱,並作為特徵輸入後續診斷系統,完善資料庫自治生態[4] 。
- 建構Human-in-Loop環境。支援根據回饋標註自動學習,保障模型持續最佳化[5]。
- 多種資料庫場景的支援。異常檢測能力平台化以支援更多資料庫場景,如DB端對端報錯、節點網路監測等。
7.附錄
7.1 絕對中位數差
絕對中位數差,即Median Absolute Deviation(MAD),是對單變量數值型資料的樣本偏差的一種穩健性測量[6],通常由下式計算而得:
其中在先驗為常態分佈的情況下,一般C選擇1.4826,k選擇3。 MAD假定樣本中間的50%區域均為正常樣本,而異常樣本落在兩側的50%區域內。當樣本服從常態分佈的情況下,MAD指標相較於標準差更能適應資料集中的異常值。對於標準差,使用的是數據到均值的距離平方,較大的偏差權重較大,異常值對結果影響不能忽視,而對MAD而言少量的異常值不會影響實驗的結果,MAD演算法對於數據的常態性有較高要求。
7.2 箱形圖
箱型圖主要透過幾個統計量來描述樣本分佈的離散程度以及對稱性,包括:
- Q0:最小值(Minimum)
- #Q1:下四分位數(Lower Quartile )
- Q2:中位數(Median)
- Q3:上四分位數( Upper Quartile)
- Q4:最大值(Maximum)

圖12 箱線圖將Q##1與Q3之間的間距稱為IQR,當樣本偏離上四分位數1.5倍的IQR(
或是偏離下四分位數1.5倍的IQR)的情況下,將樣本視為離群點。不同於基於常態假設的三倍標準差,通常情況下,箱形圖對於樣本的潛在資料分佈沒有任何假定,能夠描述出樣本的離散情況,且對樣本中包含的潛在異常樣本有較高的容忍度。對於有偏數據,Boxplot進行校準後建模更加符合資料分佈
[7]。 7.3 極值理論真實世界的資料很難用一種已知的分佈來概括,例如對於某些極端事件(異常),機率模型(例如高斯分佈)往往會給出其機率為0。極值理論
[8]是在不基於原始資料的任何分佈假設下,透過推斷我們可能會觀察到的極端事件的分佈,這就是極值分佈(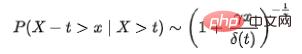 EVD
EVD
其中t代表樣本的經驗閾值,對於不同場景可以設定不同取值,,分別是廣義帕累托分佈中的形狀參數與尺度參數,在給定樣本超過人為設定的經驗閾值t的情況下,隨機變數X-t是服從廣義帕累托分佈的。透過極大似然估計方法我們可以計算得到參數估計值與 ,並且透過以下公式來求取模型閾值:
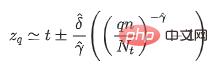
上述公式中q代表風險參數,n是所有樣本數,Nt是滿足x-t>0的樣本數。由於通常情況下對於經驗閾值t的估計沒有先驗的信息,因此可以使用樣本經驗分位數來替代數值t,這裡經驗分位數的取值可以根據實際情況來選擇。
8. 參考文獻
[1] Ren, H., Xu, B., Wang, Y., Yi, C., Huang, C., Kou, X., ... & Zhang, Q. (2019, July). Time-series anomaly detection service at microsoft. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining (pp. 3009-3017) .
[2] Lu, J., Liu, A., Dong, F., Gu, F., Gama, J., & Zhang, G. (2018). Learning under concept drift: A review. IEEE Transactions on Knowledge and Data Engineering, 31(12), 2346-2363.
[3] Mushtaq, R. (2011). Augmented dickey fuller test.
[4] Ma, M., Yin, Z., Zhang, S., Wang, S., Zheng, C., Jiang, X., ... & Pei, D. (2020) . Diagnosing root causes of intermittent slow queries in cloud databases. Proceedings of the VLDB Endowment, 13(8), 1176-1189.
[5] Holzinger, A. (2016). for health informatics: when do we need the human-in-the-loop?. Brain Informatics, 3(2), 119-131.
#[6] Leys, C., Ley, C ., Klein, O., Bernard, P., & Licata, L. (2013). Detecting outliers: Do not use standard deviation around the mean, use absolute deviation around the median. Journal of experimental social psychology, 49(44) , 764-766.
[7] Hubert, M., & Vandervieren, E. (2008). An adjusted boxplot for skewed distributions. Computational statistics & data analysis, 52(12), 5186 -5201.
[8] Siffer, A., Fouque, P. A., Termier, A., & Largouet, C. (2017, August). Anomaly detection in streams with extreme value theory. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 1067-1075).
以上是基於AI演算法的資料庫異常監測系統的設計與實現的詳細內容。更多資訊請關注PHP中文網其他相關文章!