
多模態技術在淘寶主搜召回場景的探索

- PHPz轉載
- 2023-04-08 23:31:061585瀏覽
搜索召回作为搜索系统的基础,决定了效果提升的上限。如何在现有的海量召回结果中,继续带来有差异化的增量价值,是我们面临的主要挑战。而多模态预训练与召回的结合,为我们打开了新的视野,带来线上效果的显著提升。
前言
多模态预训练是学术界与工业界研究的重点,通过在大规模数据上进行预训练,得到不同模态之间的语义对应关系,在多种下游任务如视觉问答、视觉推理、图文检索上能够提升效果。 在集团内部,多模态预训练也有一些研究与应用。 在淘宝主搜场景中,用户输入的Query与待召回商品之间存在天然的跨模态检索需求,只是以往对于商品更多地使用标题和统计特征,忽略了图像这样更加直观的信息。 但对于某些有视觉元素的Query(如白色连衣裙、碎花连衣裙),相信大家在搜索结果页都会先被图像所吸引。
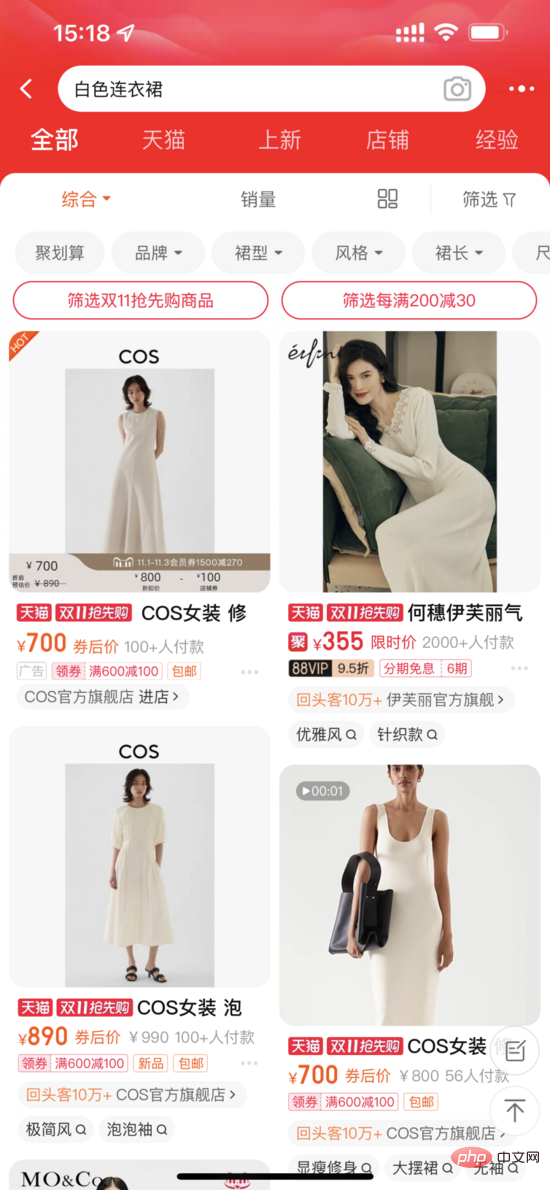

淘宝主搜场景
一方面是图像占据着更显著的位置,另一方面则是图像可能包含着标题所没有的信息,如白色、碎花这样的视觉元素。对于后者,需要区分两种情况:一种是标题中有信息、但由于显示限制无法完全展示,这种情况不影响商品在系统链路里的召回;另一种是标题中没有信息但图像中有,也就是图像相对于文本可以带来增量。后者是我们需要重点关注的对象。
▐ 技术问题与解决思路
在主搜召回场景中应用多模态技术,有两个主要问题需要解决:
- 多模态图文预训练模型一般融合图像、文本两种模态,主搜由于有Query的存在,在原本商品图像、标题的图文模态基础上,需要考虑额外的文本模态。同时,Query与商品标题之间存在语义Gap,Query相对短且宽泛,而商品标题由于卖家会做SEO,往往长且关键词堆砌。
- 通常预训练任务与下游任务的关系是,预训练采用大规模无标注数据,下游采用少量有标注数据。但对于主搜召回来说,下游向量召回任务的规模巨大,数据在数十亿量级,而受限于有限的GPU资源,预训练只能采用其中相对少量的数据。在这种情况下,预训练是否还能对下游任务带来增益。
我们的解决思路如下:
- 文字-圖文預訓練 #:將Query和商品Item分別過Encoder,作為雙塔輸入到跨模態Encoder。如果從Query和Item雙塔來看,它們在後期才進行交互,類似於雙流模型,不過具體看Item塔,圖像和標題兩個模態在早期就進行了交互,這部分是單流模型。所以,我們的模型結構是區別於常見的單流或雙流結構的。這種設計的出發點是:更有效地提取Query向量和Item向量,為下游的雙塔向量召回模型提供輸入,並且能夠在預訓練階段引入雙塔內積的建模方式。為了建模Query與標題之間存在的語意連結與Gap,我們將Query與Item雙塔的Encoder分享,再分別學習語言模型。
- 預訓練與回想任務連結 :針對下游向量回想任務的樣本建構方式與Loss,設計了預訓練階段的任務及建模方式。區別於常見的圖文匹配任務,我們採用Query-Item和Query-Image匹配任務,並將Query下點擊最多的Item作為正樣本,將Batch內的其他樣本作為負樣本,增加採用Query和Item雙塔內積方式建模的多分類任務。這種設計的出發點是:使預訓練更靠近向量召回任務,在有限的資源下,盡可能為下游任務提供有效的輸入。另外,對向量回想任務來說,如果預訓練輸入的向量在訓練過程中是固定不變的,就無法有效地針對大規模資料做調整,為此,我們還在向量回想任務裡建模了預訓練向量的更新。
預訓練模型
#▐ #建模方法
多模態預訓練模型需要從影像中擷取特徵,再與文字特徵融合。從影像中擷取特徵的方式主要有三種:使用CV領域訓練好的模型擷取影像的RoI特徵、Grid特徵和Patch特徵。從模型結構來看,根據影像特徵和文字特徵融合方式的不同,主要有兩類:單流模型或雙流模型。在單流模型中,影像特徵與文字特徵在早期就拼接在一起輸入Encoder,而在雙流模型中,影像特徵和文字特徵分別輸入到兩個獨立的Encoder,然後再輸入到跨模態Encoder中進行融合。
▐ 初步探索
我們擷取影像特徵的方式是:將影像分割為Patch序列,使用ResNet擷取每個Patch的影像特徵。在模型結構上,嘗試過單流結構,也就是將Query、標題、影像拼接在一起輸入Encoder。經過多組實驗,我們發現在這個結構下,很難提取出純粹的Query向量和Item向量作為下游雙塔向量召回任務的輸入。如果提取某一向量時,Mask掉不需要的模態,會使得預測與訓練不一致。這個問題類似於,在一個互動型的模型裡直接提取出雙塔模型,根據我們的經驗,這種模型的效果不如經過訓練的雙塔模型。基於此,我們提出了一個新的模型結構。
▐
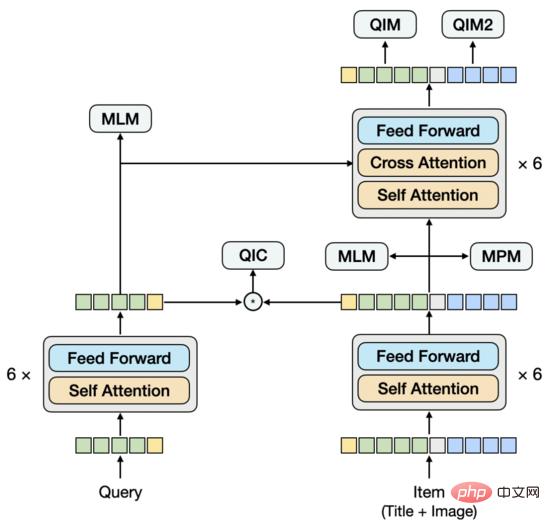
類似雙流結構,模型下方由雙塔構成,上方透過跨模態Encoder融合雙塔。與雙流結構不同的是,雙塔不是分別由單一模態構成,其中的Item塔中包含了Title和Image圖文雙模態,Title和Image拼接在一起輸入Encoder,這部分類似單流模型。為了建模Query與Title之間存在的語意連結與Gap,我們將Query與Item雙塔的Encoder分享,再分別學習語言模型。
對於預訓練來說,設計合適的任務也是比較關鍵的。我們嘗試過常用的Title和Image的圖文匹配任務,雖然能達到比較高的匹配度,但對於下游向量召回任務帶來的增益很少,這是因為用Query去召回Item時,Item的Title和Image是否符合不是關鍵因素。所以,我們在設計任務時,更考慮了Query與Item之間的關係。目前,共採用5種預訓練任務。
▐ 預訓練任務
- Masked Language Modeling (MLM):在文字Token中,隨機Mask掉15%,用剩下的文字和圖像預測被Mask的文字Token。對於Query和Title,有各自的MLM任務。 MLM最小化交叉熵Loss:
 其中 表示剩餘的文字token
其中 表示剩餘的文字token
- Masked Patch Modeling (MPM):在影像的Patch Token中,隨機Mask掉25%,用剩下的圖像和文字預測被Mask的圖像Token。 MPM最小化KL散度Loss:其中 表示剩餘的圖片token
-
Query Item Classification (QIC ): 一個Query下點選最多的Item作為正樣本,Batch內其他樣本作為負樣本。 QIC將Query塔和Item塔的[CLS] token經過線性層降維到256維,再做相似度計算得到預測機率,最小化交叉熵Loss:其中 的計算可以有許多方法:


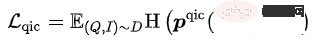

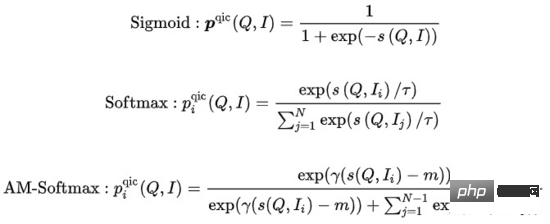
##其中 表示相似度計算, #表示溫度超參數, 和m分別表示縮放因子和鬆弛因子
- Query Item Matching (QIM):一個Query下點擊最多的Item作為正樣本,Batch內與當前Query相似度最高的其他Item作為負樣本。 QIM使用跨模態Encoder的[CLS] token計算預測機率,最小化交叉熵Loss:
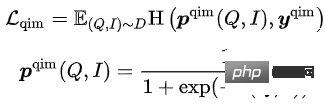
- Query Image Matching (QIM2):在QIM的樣本中,Mask掉Title,強化Query與Image之間的匹配。 QIM2最小化交叉熵Loss:
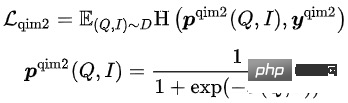
在這5種預訓練任務中,MLM任務和MPM任務位於Item塔的上方,建模Title或Image的部分Token被Mask後,使用跨模態資訊相互恢復的能力。 Query塔上方有獨立的MLM任務,透過共享Query塔和Item塔的Encoder,建模Query與Title之間的語意連結與Gap。 QIC任務使用雙塔內積的方式,將預訓練和下游向量召回任務做一定程度的對齊,並用AM-Softmax拉近Query的表示與Query下點擊最多Item的表示之間的距離,推開Query與其他Item的距離。 QIM任務位於跨模態Encoder的上方,使用跨模態資訊建模Query和Item的匹配。出於計算量的考慮,採用通常NSP任務的正負樣本比1:1,為了進一步推開正負樣本之間的距離,基於QIC任務的相似度計算結果建構了難負樣本。 QIM2任務與QIM任務位於相同的位置,明確建模影像相對於文字所帶來的增量資訊。
向量回想模型
▐ 建模方法
在大規模資訊檢索系統中,召回模型位於最底層,需要在海量的候選集中評分。出於效能的考慮,往往採用User和Item雙塔計算向量內積的結構。向量回想模型的一個核心問題是:如何建構正負樣本以及負樣本取樣的規模。我們的解決方法是:將使用者在一個頁面內的點擊Item作為正樣本,在全量商品池中根據點擊分佈採樣出萬級別的負樣本,用Sampled Softmax Loss在採樣樣本中推導出Item在全量商品池中的點擊機率。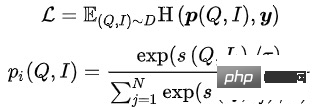
其中 #表示相似度計算, 表示溫度超參數
▐ 初步探索
#遵循常見的FineTune範式,我們嘗試過將預先訓練的向量直接輸入到雙塔MLP,結合大規模負採樣和Sampled Softmax來訓練多模態向量召回模型。不過,與通常的小規模下游任務相反,向量召回任務的訓練樣本量巨大,在數十億量級。我們觀察到MLP的參數量無法支撐模型的訓練,很快就會達到自身的收斂狀態,但效果並不好。同時,預訓練向量在向量召回模型中作為輸入而非參數,無法隨著訓練的進行而更新。這樣一來,在相對小規模資料上進行的預訓練,與大規模資料上的下游任務有一定的衝突。
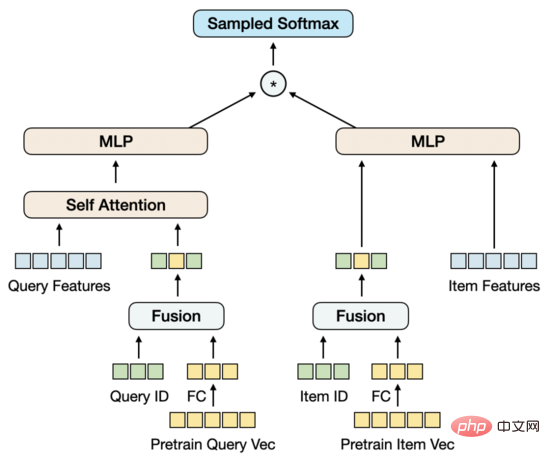
解決的想法有幾種,一種方法是將預訓練模型整合到向量召回模型中,但預訓練模型的參數量過大,再加上向量召回模型的樣本量,無法在在有限的資源限制下,以合理的時間進行常態化訓練。另一種方法是在向量回想模型中建構參數矩陣,將預訓練向量載入到矩陣中,隨著訓練的進行更新矩陣的參數。經過調查,這種方式在工程實現上成本比較高。基於此,我們提出了簡單可行地建模預訓練向量更新的模型結構。
▐ 模型結構
實驗分析
▐ 評測指標
##對於預訓練模式的效果,通常是用下游任務的指標來評測,而很少用單獨的評測指標。但這樣一來,預訓練模型的迭代成本會比較高,因為每迭代一個版本的模型都需要訓練對應的向量回想任務,再評測向量回想任務的指標,整個流程會很長。有沒有單獨評測預訓練模式的有效指標?我們首先嘗試了一些論文中的Rank@K,這個指標主要是用來評測圖文匹配任務:先用預訓練模型在人工構造的候選集中打分,再計算根據分數排序後的Top K結果命中圖文配對正樣本的比例。我們直接將Rank@K套用在Query-item匹配任務上,發現結果不符合預期,一個Rank@K更好的預訓練模型,在下游的向量召回模型中可能會獲得更差的效果,無法指導預訓練模型的迭代。基於此,我們將預訓練模型的評測與向量回想模型的評測統一起來,採用相同的評測指標及流程,可以相對有效地指導預訓練模型的迭代。Recall@K :評測資料集由訓練集的下一天資料構成,先將同一個Query下不同使用者的點選、成交結果聚合成 ,再計算模型預測的Top K結果 命中 的比例:
,再計算模型預測的Top K結果 命中 的比例:
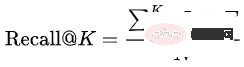
对于向量召回模型,在Recall@K提高到一定程度后,也需要关注Query和Item之间的相关性。一个相关性差的模型,即使能提高搜索效率,也会面临Bad Case增加导致的用户体验变差和投诉舆情增多。 我们采用与线上相关性模型一致的离线模型,评测Query和Item之间以及Query和Item类目之间的相关性。
▐ 预训练实验
我们选取部分类目下1亿量级的商品池,构造了预训练数据集。
我们的Baseline模型是经过优化的FashionBert,加入了QIM和QIM2任务,提取Query和Item向量时采用只对非Padding Token做Mean Pooling的方式。以下实验探索了以双塔方式建模,相对于单塔带来的增益,并通过消融实验给出关键部分的作用。

从这些实验中,我们能得出如下结论:
- 实验8 vs 实验3:经过调优后的双塔模型,在Recall@1000上显著高于单塔Baseline。
- 实验3 vs 实验1/2:对单塔模型来说,如何提取Query和Item向量是重要的。我们尝试过Query和Item都用[CLS] token,得到比较差的结果。实验1对Query和Item分别用对应的Token做Mean Pooling,效果要好一些,但进一步去掉Padding Token再做Mean Pooling,会带来更大的提升。实验2验证了显式建模Query-Image匹配来突出图像信息的作用,会带来提升。
- 实验6 vs 实验4/5:实验4将Item塔的MLM/MPM任务上移到跨模态Encoder,效果会差一些,因为将这两个任务放在Item塔能够增强Item表示的学习;另外,在Item塔做基于Title和Image的跨模态恢复会有更强的对应关系。实验5验证了对Query和Item向量在训练和预测时增加L2 Norm,会带来提升。
- 实验6/7/8:改变QIC任务的Loss会带来提升,Softmax相比于Sigmoid更接近下游的向量召回任务,AM-Softmax则更进一步推开了正样本与负样本之间的距离。
▐ 向量召回实验
我们选取10亿量级有点击的页面,构造了向量召回数据集。在每个页面中包含3个点击Item作为正样本,从商品池中根据点击分布采样出1万量级的负样本。在此基础上,进一步扩大训练数据量或负样本采样量,没有观察到效果的明显提升。
我们的Baseline模型是主搜的MGDSPR模型。以下实验探索了将多模态预训练与向量召回结合,相对于Baseline带来的增益,并通过消融实验给出关键部分的作用。
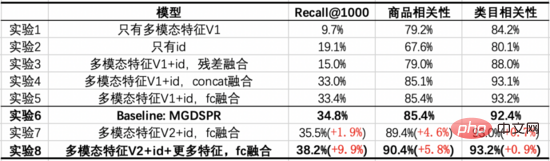
从这些实验中,我们能得出如下结论:
- 实验7/8 vs 实验6:多模态特征与ID通过FC融合后,在3个指标上都超过了Baseline,在提升Recall@1000的同时,对商品相关性提升更多。在此基础上,加入与Baseline相同的特征,能进一步提升3个指标,并在Recall@1000上提升得更多。
- 实验1 vs 实验2:只有多模态特征相比于只有ID,Recall@1000更低,但相关性更高,且相关性接近线上可用的程度。说明这时的多模态召回模型,从召回结果来看有更少的Bad Case,但对点击、成交的效率考虑得不够。
- 实验3/4/5 vs 实验1/2:将多模态特征与ID融合后,能够在3个指标上都带来提升,其中将ID过FC再与降维后的多模态特征相加,效果更好。不过,与Baseline相比,在Recall@1000上仍有差距。
- 实验7 vs 实验5:叠加预训练模型的优化后,在Recall@1000、商品相关性上都有提升,类目相关性基本持平。
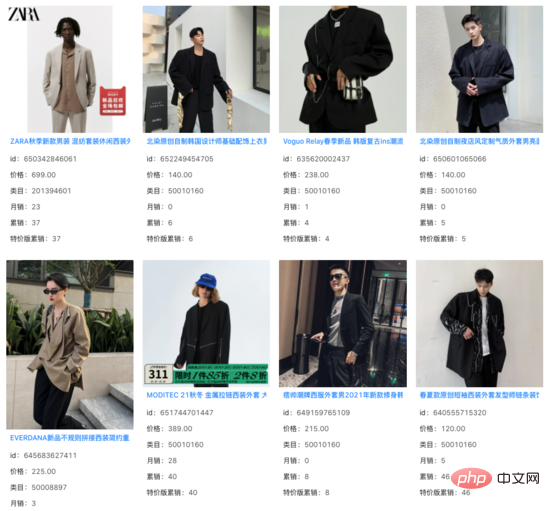
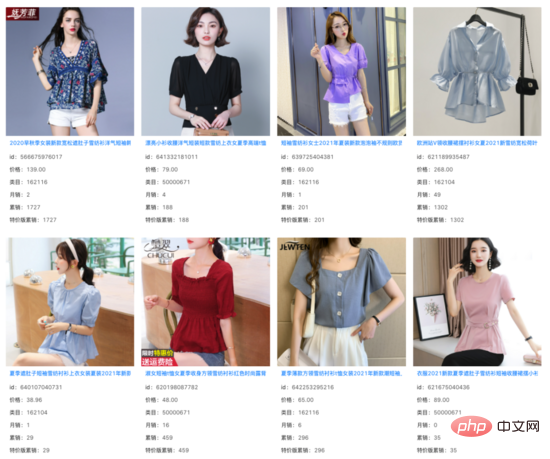
我们在向量召回模型的Top 1000结果中,过滤掉线上系统已经能召回的Item,发现其余增量结果的相关性基本不变。在大量Query下,我们看到这些增量结果捕捉 到了商品Title之外的图像信息,并对Query和Title之间存在的语义Gap起到了一定的作用。
query: 痞帅西装
query: 女掐收腰小衫
總結與展望
針對主搜尋場景的應用需求,我們提出了文字-圖文預訓練模型,採用了Query和Item雙塔輸入跨模態Encoder的結構,其中Item塔是包含圖文多模態的單流模型。透過Query-Item和Query-Image匹配任務,以及Query和Item雙塔內積方式建模的Query-Item多分類任務,使預訓練更接近下游的向量召回任務。同時,在向量召回中建模了預訓練向量的更新。在資源有限的情況下,使用相對少量資料的預訓練,對使用大量資料的下游任務仍然帶來了效果的提升。
在主搜的其他場景中,如商品理解、相關性、排序,也存在著應用多模態技術的需求。我們也參與了這些場景的探索中,相信多模態技術在未來會為越來越多的場景帶來增益。
團隊介紹
淘寶主搜召回團隊:團隊負責主搜鏈路中的召回、粗排環節,目前的主要技術方向為基於全空間樣本的多目標個人化向量回想、基於大規模預訓練的多模態回想、基於對比學習的相似Query語義改寫以及粗排模型等。
以上是多模態技術在淘寶主搜召回場景的探索的詳細內容。更多資訊請關注PHP中文網其他相關文章!