


得益於 AWS 的全面服務套件,現在使用 AWS 建立用於 NBA 分析的雲端原生資料湖比以往任何時候都更加簡單。本指南示範如何使用 Amazon S3、AWS Glue 和 Amazon Athena 建立 NBA 資料湖,並使用 Python 腳本自動進行設置,以實現高效的資料儲存、查詢和分析。
了解資料湖
資料湖是一個集中式儲存庫,用於儲存任何規模的結構化和非結構化資料。 資料以其原始格式存儲,根據需要進行處理,並用於分析、報告或機器學習。 AWS 提供強大的工具來有效率地建立和管理資料湖。
NBA 資料湖概述
本專案使用 Python 腳本 (setup_nba_data_lake.py) 來實現自動化:
- Amazon S3: 建立一個儲存桶來儲存原始和處理後的 NBA 資料。
- AWS Glue:建立用於元資料和架構管理的資料庫和外部表。
- Amazon Athena: 配置查詢執行以從 S3 進行直接資料分析。
此架構有助於無縫整合來自 SportsData.io 的即時 NBA 數據,以進行高級分析和報告。
使用的 AWS 服務
1。 Amazon S3(簡單儲存服務):
- 功能:可擴充的物件儲存;資料湖的基礎,儲存原始和處理後的 NBA 資料。
-
實作: 建立
sports-analytics-data-lake儲存桶。資料被組織到資料夾中(例如,raw-data表示未處理的 JSON 文件,例如nba_player_data.json)。 S3 確保高可用性、耐用性和成本效益。 - 優點: 可擴充性、成本效益、與 AWS Glue 和 Athena 無縫整合。
2。 AWS Glue:
- 功能:完全託管的ETL(提取、轉換、載入)服務;管理 S3 中資料的元資料和架構。
-
實作: 建立一個 Glue 資料庫和一個定義 S3 中 JSON 資料架構的外部表 (
nba_players)。 Glue 編錄元數據,支援 Athena 查詢。 - 優點:自動化模式管理、ETL 功能、成本效益。
3。亞馬遜雅典娜:
- 功能:使用標準 SQL 分析 S3 資料的互動式查詢服務。
-
實作: 從 AWS Glue 讀取元資料。 使用者直接對 S3 JSON 資料執行 SQL 查詢,無需資料庫伺服器。 (範例查詢:
SELECT FirstName, LastName, Position FROM nba_players WHERE Position = 'PG';) - 優點:無伺服器架構、速度、隨選付費定價。
建構 NBA 資料湖
先決條件:
- SportsData.io API 金鑰: 從 SportsData.io 取得免費的 API 金鑰以存取 NBA 資料。
- AWS 帳戶: 對 S3、Glue 和 Athena 具有足夠權限的 AWS 帳戶。
- IAM 權限: 使用者或角色需要 S3(CreateBucket、PutObject、ListBucket)、Glue(CreateDatabase、CreateTable)和 Athena(StartQueryExecution、GetQueryResults)的權限。
步驟:
1。造訪 AWS CloudShell: 登入 AWS 管理主控台並開啟 CloudShell。
2。建立並配置 Python 腳本:
- 在 CloudShell 中運行
nano setup_nba_data_lake.py。
- 複製 Python 腳本(來自 GitHub 儲存庫),將
api_key佔位符替換為您的 SportsData.io API 金鑰:SPORTS_DATA_API_KEY=your_sportsdata_api_keyNBA_ENDPOINT=https://api.sportsdata.io/v3/nba/scores/json/Players
- 儲存並退出(Ctrl X、Y、Enter)。


3。執行腳本:執行python3 setup_nba_data_lake.py.
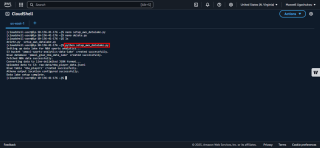
此腳本建立 S3 儲存桶、上傳範例資料、設定 Glue 資料庫和資料表,並配置 Athena。
4。資源驗證:
-
Amazon S3: 驗證
sports-analytics-data-lake儲存桶和包含raw-data的nba_player_data.json資料夾。



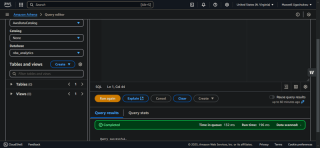
- Amazon Athena:執行範例查詢並檢查結果。

學習成果:
本專案提供雲端架構設計、資料儲存最佳實務、元資料管理、基於 SQL 的分析、API 整合、Python 自動化和 IAM 安全性的實務經驗。
未來增強:
自動資料攝取 (AWS Lambda)、資料轉換 (AWS Glue)、進階分析 (AWS QuickSight) 和即時更新 (AWS Kinesis) 是未來潛在的改進。 該專案展示了無伺服器架構在建構高效且可擴展的資料湖方面的強大功能。
以上是使用 AWS 建立 NBA 資料湖:綜合指南的詳細內容。更多資訊請關注PHP中文網其他相關文章!

 如何解決Linux終端中查看Python版本時遇到的權限問題?Apr 01, 2025 pm 05:09 PM
如何解決Linux終端中查看Python版本時遇到的權限問題?Apr 01, 2025 pm 05:09 PMLinux終端中查看Python版本時遇到權限問題的解決方法當你在Linux終端中嘗試查看Python的版本時,輸入python...
 我如何使用美麗的湯來解析HTML?Mar 10, 2025 pm 06:54 PM
我如何使用美麗的湯來解析HTML?Mar 10, 2025 pm 06:54 PM本文解釋瞭如何使用美麗的湯庫來解析html。 它詳細介紹了常見方法,例如find(),find_all(),select()和get_text(),以用於數據提取,處理不同的HTML結構和錯誤以及替代方案(SEL)
 python對象的序列化和避難所化:第1部分Mar 08, 2025 am 09:39 AM
python對象的序列化和避難所化:第1部分Mar 08, 2025 am 09:39 AMPython 對象的序列化和反序列化是任何非平凡程序的關鍵方面。如果您將某些內容保存到 Python 文件中,如果您讀取配置文件,或者如果您響應 HTTP 請求,您都會進行對象序列化和反序列化。 從某種意義上說,序列化和反序列化是世界上最無聊的事情。誰會在乎所有這些格式和協議?您想持久化或流式傳輸一些 Python 對象,並在以後完整地取回它們。 這是一種在概念層面上看待世界的好方法。但是,在實際層面上,您選擇的序列化方案、格式或協議可能會決定程序運行的速度、安全性、維護狀態的自由度以及與其他系
 Python中的數學模塊:統計Mar 09, 2025 am 11:40 AM
Python中的數學模塊:統計Mar 09, 2025 am 11:40 AMPython的statistics模塊提供強大的數據統計分析功能,幫助我們快速理解數據整體特徵,例如生物統計學和商業分析等領域。無需逐個查看數據點,只需查看均值或方差等統計量,即可發現原始數據中可能被忽略的趨勢和特徵,並更輕鬆、有效地比較大型數據集。 本教程將介紹如何計算平均值和衡量數據集的離散程度。除非另有說明,本模塊中的所有函數都支持使用mean()函數計算平均值,而非簡單的求和平均。 也可使用浮點數。 import random import statistics from fracti
 如何使用TensorFlow或Pytorch進行深度學習?Mar 10, 2025 pm 06:52 PM
如何使用TensorFlow或Pytorch進行深度學習?Mar 10, 2025 pm 06:52 PM本文比較了Tensorflow和Pytorch的深度學習。 它詳細介紹了所涉及的步驟:數據準備,模型構建,培訓,評估和部署。 框架之間的關鍵差異,特別是關於計算刻度的
 用美麗的湯在Python中刮擦網頁:搜索和DOM修改Mar 08, 2025 am 10:36 AM
用美麗的湯在Python中刮擦網頁:搜索和DOM修改Mar 08, 2025 am 10:36 AM該教程建立在先前對美麗湯的介紹基礎上,重點是簡單的樹導航之外的DOM操縱。 我們將探索有效的搜索方法和技術,以修改HTML結構。 一種常見的DOM搜索方法是EX
 哪些流行的Python庫及其用途?Mar 21, 2025 pm 06:46 PM
哪些流行的Python庫及其用途?Mar 21, 2025 pm 06:46 PM本文討論了諸如Numpy,Pandas,Matplotlib,Scikit-Learn,Tensorflow,Tensorflow,Django,Blask和請求等流行的Python庫,並詳細介紹了它們在科學計算,數據分析,可視化,機器學習,網絡開發和H中的用途
 如何使用Python創建命令行接口(CLI)?Mar 10, 2025 pm 06:48 PM
如何使用Python創建命令行接口(CLI)?Mar 10, 2025 pm 06:48 PM本文指導Python開發人員構建命令行界面(CLIS)。 它使用Typer,Click和ArgParse等庫詳細介紹,強調輸入/輸出處理,並促進用戶友好的設計模式,以提高CLI可用性。


熱AI工具

Undresser.AI Undress
人工智慧驅動的應用程序,用於創建逼真的裸體照片

AI Clothes Remover
用於從照片中去除衣服的線上人工智慧工具。

Undress AI Tool
免費脫衣圖片

Clothoff.io
AI脫衣器

AI Hentai Generator
免費產生 AI 無盡。

熱門文章
熱工具

ZendStudio 13.5.1 Mac
強大的PHP整合開發環境

SublimeText3 Linux新版
SublimeText3 Linux最新版

MantisBT
Mantis是一個易於部署的基於Web的缺陷追蹤工具,用於幫助產品缺陷追蹤。它需要PHP、MySQL和一個Web伺服器。請查看我們的演示和託管服務。

Atom編輯器mac版下載
最受歡迎的的開源編輯器

mPDF
mPDF是一個PHP庫,可以從UTF-8編碼的HTML產生PDF檔案。原作者Ian Back編寫mPDF以從他的網站上「即時」輸出PDF文件,並處理不同的語言。與原始腳本如HTML2FPDF相比,它的速度較慢,並且在使用Unicode字體時產生的檔案較大,但支援CSS樣式等,並進行了大量增強。支援幾乎所有語言,包括RTL(阿拉伯語和希伯來語)和CJK(中日韓)。支援嵌套的區塊級元素(如P、DIV),

