
Rumah >Peranti teknologi >AI >Hancurkan sumpahan 36 tahun yang lalu! Meta melancarkan kaedah latihan terbalik untuk menghapuskan 'kutukan pembalikan' model besar
Hancurkan sumpahan 36 tahun yang lalu! Meta melancarkan kaedah latihan terbalik untuk menghapuskan 'kutukan pembalikan' model besar

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-04-09 15:40:09829semak imbas
"Kutukan pembalikan" model bahasa besar telah diselesaikan!
Sumpahan ini mula-mula ditemui pada September tahun lalu, yang serta-merta menimbulkan seruan daripada LeCun, Karpathy, Marcus dan lelaki besar yang lain.

Kerana model besar yang tiada tandingan dan angkuh itu sebenarnya mempunyai "tumit Achilles": model bahasa yang dilatih pada "A ialah B" tidak dapat menjawab "Adakah B A" dengan betul.
Sebagai contoh, dalam contoh berikut: LLM dengan jelas mengetahui bahawa "Ibu Tom Cruise ialah Mary Lee Pfeiffer", tetapi tidak boleh menjawab "Anak Mary Lee Pfeiffer ialah Tom Cruise".

——Ini adalah GPT-4 yang paling maju pada masa itu, walaupun kanak-kanak boleh mempunyai pemikiran logik yang normal, tetapi LLM tidak dapat melakukannya.
Berdasarkan data besar-besaran, dia telah menghafal ilmu yang melebihi hampir semua manusia, namun berkelakuan begitu membosankan Dia telah memperoleh api kebijaksanaan, tetapi selamanya terpenjara dalam sumpahan ini.

Alamat kertas: https://arxiv.org/pdf/2309.12288v1.pdf
Sebaik kejadian ini tersiar, seluruh Internet gempar.
Di satu pihak, netizen mengatakan bahawa model besar itu benar-benar bodoh, sungguh. Hanya mengetahui "A adalah B" tetapi tidak mengetahui "B adalah A", akhirnya saya mengekalkan maruah saya sebagai seorang manusia.
Sebaliknya, penyelidik juga telah mula mengkaji perkara ini dan bekerja keras untuk menyelesaikan cabaran utama ini.
Baru-baru ini, penyelidik dari Meta FAIR melancarkan kaedah latihan terbalik untuk menyelesaikan "sumpahan terbalik" LLM dalam satu masa.
Alamat kertas: https://arxiv.org/pdf/2403.13799.pdf
Para penyelidik mula-mula memerhatikan bahawa LLM dilatih secara autoregresif menyebabkan ini adalah kemungkinan dari kiri ke kanan - pembalikan sumpahan.
Jadi, jika anda melatih LLM (latihan songsang) dalam arah kanan ke kiri, model boleh melihat fakta dalam arah songsang.
Teks terbalik boleh dianggap sebagai bahasa kedua, memanfaatkan pelbagai sumber berbeza melalui latihan berbilang tugas atau pra-latihan merentas bahasa.
Para penyelidik mempertimbangkan 4 jenis penyongsangan: penyongsangan token, penyongsangan perkataan, penyongsangan pemuliharaan entiti dan penyongsangan segmen rawak.
Pembalikan token dan perkataan, dengan membahagikan urutan menjadi token atau perkataan masing-masing dan membalikkan susunannya untuk membentuk urutan baharu.
Entiti Memelihara Songsang, mencari nama entiti dalam urutan dan mengekalkan susunan perkataan dari kiri ke kanan di dalamnya semasa melakukan pembalikan perkataan.
Penyongsangan segmen rawak membahagikan jujukan token kepada blok panjang rawak dan kemudian mengekalkan susunan kiri ke kanan dalam setiap blok.
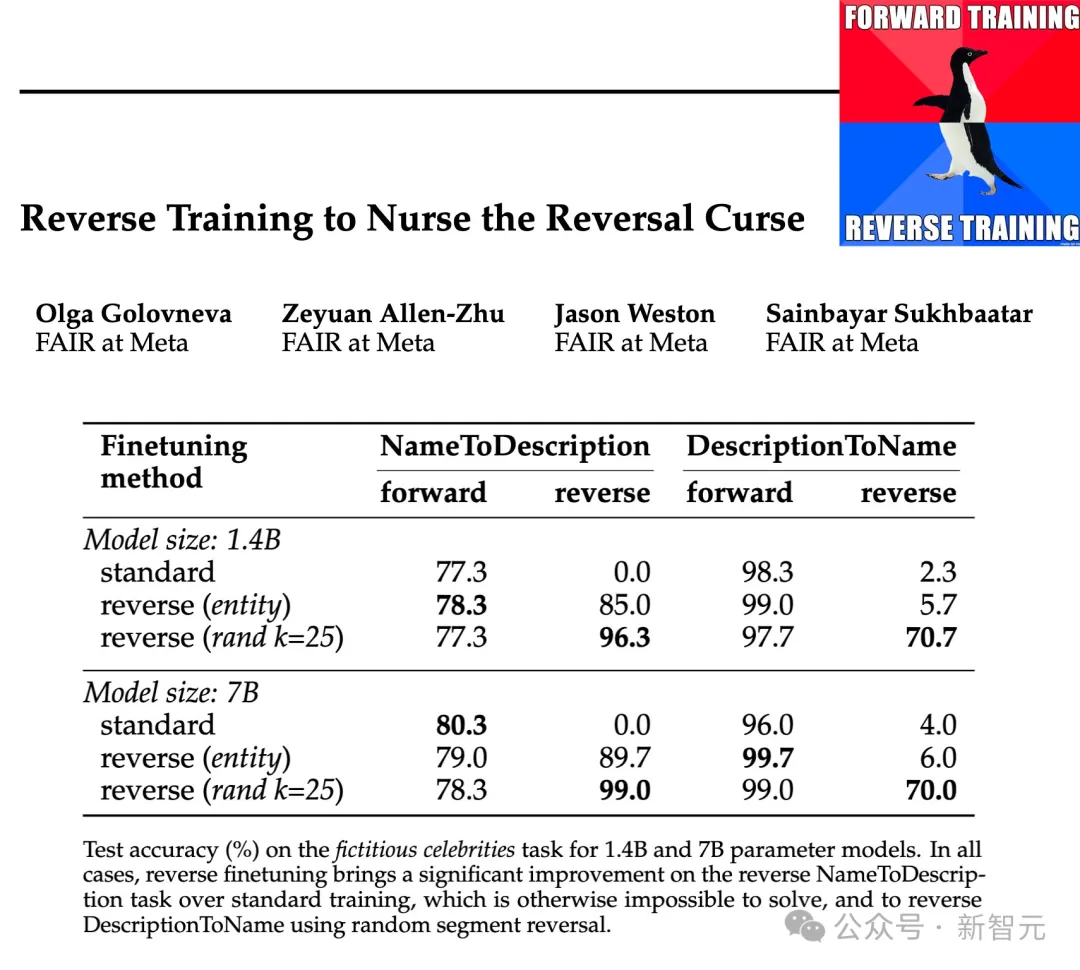
Para penyelidik menguji keberkesanan jenis penyongsangan ini pada skala parameter 1.4B dan 7B dan menunjukkan bahawa latihan pemuliharaan entiti dan latihan penyongsangan secara rawak boleh mengurangkan kutukan penyongsangan, malah dalam beberapa kes, Hapuskannya sepenuhnya.
Di samping itu, para penyelidik juga mendapati bahawa membalikkan sebelum latihan meningkatkan prestasi model berbanding latihan standard kiri-ke-kanan - jadi latihan songsang boleh digunakan sebagai kaedah latihan am.
Kaedah latihan songsang
Latihan songsang termasuk mendapatkan set data latihan dengan sampel N dan membina set sampel terbalik REVERSE (x). .
Penyongsangan Pemeliharaan Entiti: Jalankan pengesan entiti pada sampel latihan yang diberikan, pecahkan bukan entiti kepada perkataan juga. Kemudian perkataan bukan entiti diterbalikkan, manakala perkataan yang mewakili entiti mengekalkan susunan perkataan asalnya.
Pembalikan Segmen Rawak: Daripada menggunakan pengesan entiti, kami cuba menggunakan pensampelan seragam untuk membahagikan urutan secara rawak kepada segmen dengan saiz antara token 1 dan k, dan kemudian membalikkan segmen ini, tetapi mengekalkan setiap susunan perkataan dalam satu segmen, selepas itu segmen disambungkan menggunakan token khas [REV].
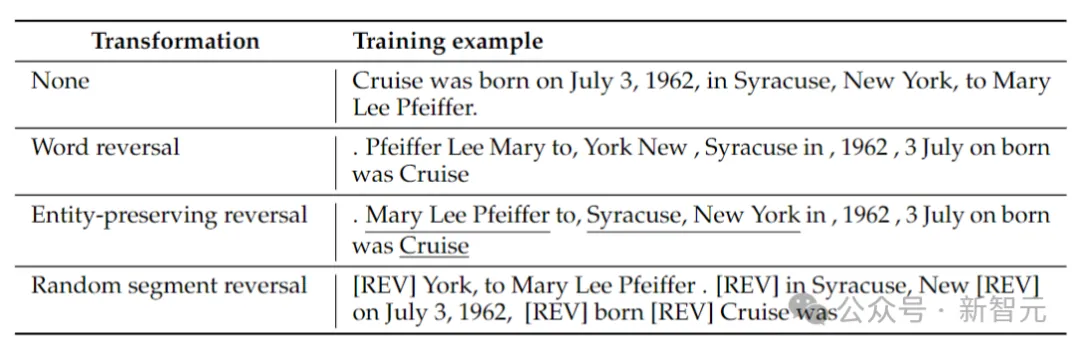
Jadual di atas memberikan contoh jenis penyongsangan yang berbeza pada rentetan tertentu.
Pada masa ini, model bahasa masih dilatih dari kiri ke kanan Dalam kes pembalikan perkataan, ia bersamaan dengan meramal ayat dari kanan ke kiri.
Latihan songsang melibatkan latihan pada contoh standard dan songsang, jadi bilangan token latihan digandakan, manakala kedua-dua sampel latihan ke hadapan dan songsang dicampur bersama.
Transformasi songsang boleh dilihat sebagai bahasa kedua yang model mesti pelajari bahawa semasa penyongsangan, hubungan antara fakta tetap tidak berubah dan model boleh menilai dari tatabahasa sama ada arah hadapan atau songsang model ramalan bahasa.
Perspektif lain latihan songsang boleh dijelaskan oleh teori maklumat: matlamat pemodelan bahasa adalah untuk mempelajari taburan kebarangkalian bahasa semula jadi
Mulakan dengan mencipta set data berasaskan simbol mudah untuk mengkaji laknat penyongsangan dalam persekitaran terkawal.
Gandingkan entiti a dan b secara rawak dengan cara satu dengan satu Data latihan mengandungi semua pasangan pemetaan (a→b), tetapi hanya separuh daripada pemetaan (b→a), dan separuh lagi berfungsi sebagai. data ujian. Model mesti membuat kesimpulan peraturan a→b ⇔ b→a daripada data latihan dan kemudian umumkannya kepada pasangan dalam data ujian.
Jadual di atas menunjukkan ketepatan ujian (%) tugas pembalikan tanda. Walaupun tugas itu mudah, latihan model bahasa standard gagal sepenuhnya, menunjukkan bahawa penskalaan sahaja tidak mungkin menyelesaikannya.
Sebaliknya, latihan terbalik hampir boleh menyelesaikan masalah dua entiti perkataan, tetapi prestasinya menurun dengan cepat apabila entiti itu semakin panjang.
Pembalikan perkataan berfungsi dengan baik untuk entiti yang lebih pendek, tetapi untuk entiti dengan lebih banyak perkataan, penyongsangan yang memelihara entiti diperlukan. Pembalikan segmen rawak berprestasi baik apabila panjang segmen maksimum k sekurang-kurangnya sepanjang entiti. 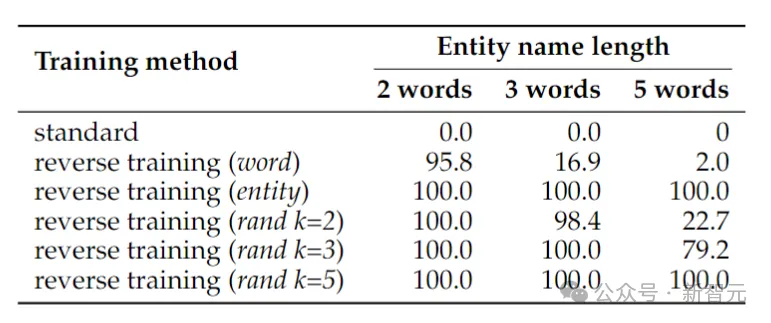
Meningkatkan nama orang -orang di atas menunjukkan tugas pembalikan untuk menentukan nama penuh seseorang. nama penuh masih menghampiri sifar, - ini kerana dalam kaedah pengesanan entiti yang diterima pakai dalam artikel ini, tarikh dianggap sebagai tiga entiti, jadi susunan mereka tidak dikekalkan dalam pembalikan.
Jika tugas penyongsangan dikurangkan kepada hanya menentukan nama keluarga seseorang, penyongsangan peringkat perkataan sudah memadai.
Fenomena lain yang mungkin mengejutkan ialah kaedah pengekalan entiti boleh menentukan nama penuh orang itu, tetapi bukan nama keluarga orang itu.
Ini adalah fenomena yang diketahui: model bahasa mungkin tidak dapat mendapatkan semula token lewat serpihan pengetahuan (seperti nama keluarga).
Fakta Dunia Sebenar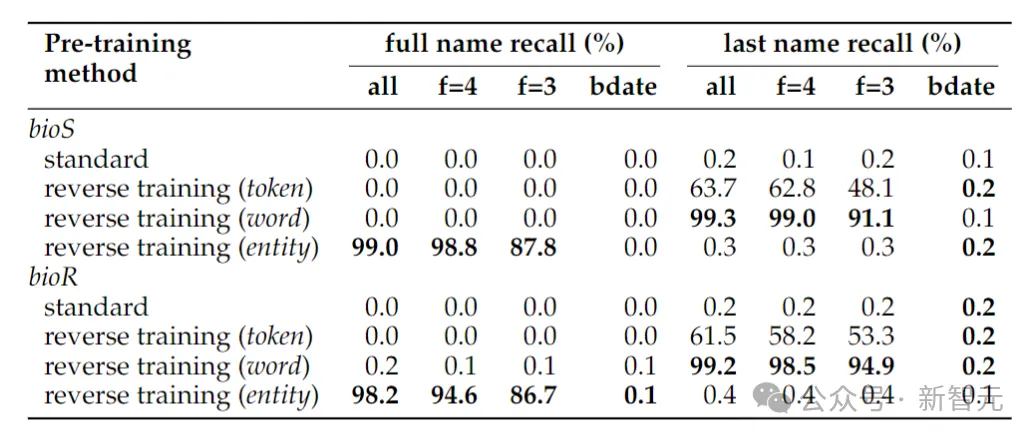
Di sini penulis melatih model parameter Llama-2 1.4 bilion, melatih model garis dasar 2 trilion token ke arah kiri ke kanan.
Sebaliknya, latihan songsang hanya menggunakan 1 trilion token, tetapi menggunakan subset data yang sama untuk melatih dalam dua arah, kiri ke kanan dan kanan ke kiri - dua arah digabungkan ialah 2 trilion token, memastikan keadilan dan keadilan dari segi sumber pengkomputeran.
Untuk menguji pembalikan fakta dunia sebenar, penyelidik menggunakan tugas selebriti, yang termasuk soalan seperti "Siapa ibu selebriti serta soalan penyongsangan yang lebih mencabar, contohnya, "Siapakah anak-anak orang tertentu?" ibu bapa selebriti?" Keputusan ditunjukkan dalam jadual di atas. Para penyelidik mencuba model beberapa kali untuk setiap soalan dan menganggapnya berjaya jika mana-mana daripadanya mengandungi jawapan yang betul. Secara amnya, ketepatan biasanya agak rendah kerana modelnya kecil dari segi bilangan parameter, mempunyai pra-latihan yang terhad dan kurang penalaan halus. Walau bagaimanapun, latihan terbalik menunjukkan prestasi yang lebih baik. Pada tahun 1988, Fodor dan Pylyshyn menerbitkan artikel tentang sifat pemikiran yang sistematik dalam jurnal "Kognisi". Jika anda benar-benar memahami dunia ini, maka anda sepatutnya dapat memahami hubungan antara a dan b, dan hubungan antara b dan a. Makhluk kognitif bukan lisan pun sepatutnya boleh melakukan ini. 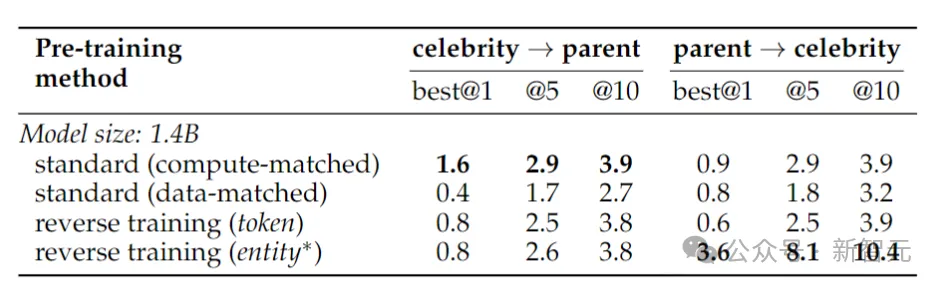
Prophecy 36 tahun yang lalu

Atas ialah kandungan terperinci Hancurkan sumpahan 36 tahun yang lalu! Meta melancarkan kaedah latihan terbalik untuk menghapuskan 'kutukan pembalikan' model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 怎么申请email
- ai训练集群是什么
- Senarai teratas antarabangsa yang berwibawa bagi penghuraian semantik perbualan SParC dan CoSQL, model pra-latihan pengetahuan meja dialog pelbagai pusingan baharu tafsiran STAR
- Ujian dalaman Kimi Chat bermula, Volcano Engine menyediakan penyelesaian pecutan, menyokong latihan dan inferens perkhidmatan model besar AI Moonshot
- Gunakan penglihatan untuk menggesa! Shen Xiangyang mempamerkan model baharu Institut Penyelidikan IDEA, yang tidak memerlukan latihan atau penalaan halus dan boleh digunakan di luar kotak.