
Rumah >Peranti teknologi >AI >Kajian semula pembangunan model CLIP, asas rajah Vincentian
Kajian semula pembangunan model CLIP, asas rajah Vincentian

- 王林ke hadapan
- 2024-03-22 20:50:221353semak imbas
. pasangan imej, di mana imej dipasangkan dengan perihalan teks yang sepadan melalui pembelajaran kontrastif, model ini bertujuan untuk memahami hubungan antara teks dan pasangan imej

Dalam model Resapan Stabil, ciri teks yang diekstrak oleh pengekod teks CLIP dibenamkan ke dalam UNet model resapan melalui perhatian silang. Secara khusus, ciri teks digunakan sebagai kunci dan nilai perhatian, manakala ciri UNet digunakan sebagai pertanyaan. Dalam erti kata lain, CLIP sebenarnya merupakan jambatan utama antara teks dan gambar, menggabungkan maklumat teks dan maklumat imej secara organik. Gabungan ini membolehkan model memahami dan memproses maklumat dengan lebih baik antara modaliti yang berbeza, dengan itu mencapai hasil yang lebih baik apabila mengendalikan tugas yang rumit. Dengan cara ini, model Stable Diffusion boleh menggunakan keupayaan pengekodan teks CLIP dengan lebih berkesan, dengan itu meningkatkan prestasi keseluruhan dan mengembangkan kawasan aplikasi.
CLIP
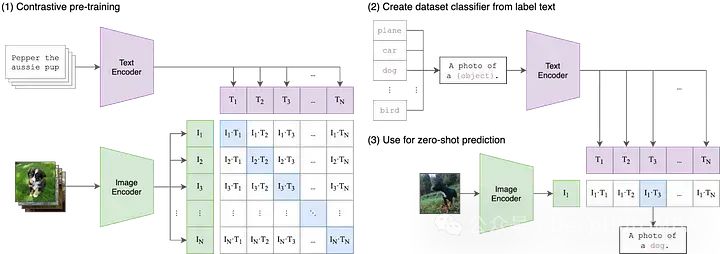
Mari mulakan dengan Imej-Bahasa.
Dalam model pembelajaran mesin tradisional, biasanya hanya satu modaliti data input boleh diterima, seperti teks, imej, data jadual atau audio. Jika anda perlu menggunakan data daripada modaliti yang berbeza untuk membuat ramalan, anda mesti melatih berbilang model yang berbeza. Dalam CLIP, "Imej-Bahasa" bermaksud model boleh menerima kedua-dua data input teks (bahasa) dan imej. Reka bentuk ini membolehkan CLIP memproses maklumat pelbagai modaliti dengan lebih fleksibel, dengan itu meningkatkan keupayaan ramalan dan skop aplikasinya.CLIP mengendalikan input teks dan imej dengan menggunakan dua pengekod berbeza iaitu pengekod teks dan pengekod imej. Kedua-dua pengekod ini memetakan data input ke dalam ruang terpendam berdimensi rendah, menjana vektor benam yang sepadan untuk setiap input. Perincian penting ialah pengekod teks dan imej membenamkan data ke dalam ruang yang sama, iaitu ruang CLIP asal ialah ruang vektor 512 dimensi. Reka bentuk ini membolehkan perbandingan langsung dan pemadanan antara teks dan imej tanpa penukaran atau pemprosesan tambahan. Dengan cara ini, CLIP boleh mewakili perihalan teks dan kandungan imej dalam ruang vektor yang sama, sekali gus mendayakan penjajaran semantik rentas mod dan fungsi perolehan semula. Reka bentuk ruang pembenaman kongsi ini memberikan CLIP keupayaan generalisasi dan kebolehsuaian yang lebih baik, membolehkannya berfungsi dengan baik pada pelbagai tugasan dan set data. . Sebagai contoh, adalah penting untuk mewujudkan hubungan yang munasabah dan boleh ditafsir antara pembenaman "anjing" atau "gambar anjing" dalam teks dan pembenaman imej anjing. Walau bagaimanapun, kita memerlukan satu cara untuk merapatkan jurang antara kedua-dua model ini.
Dalam pembelajaran mesin pelbagai mod, terdapat pelbagai teknik untuk menyelaraskan dua modaliti, tetapi pada masa ini kaedah yang paling popular ialah kontras. Teknik kontrastif mengambil sepasang input daripada dua modaliti: sebut imej dan kapsyennya dan latih dua pengekod model untuk mewakili pasangan data input ini sedekat mungkin. Pada masa yang sama, model diberi insentif untuk mengambil input tidak berpasangan (seperti imej anjing dan teks "gambar kereta") dan mewakilinya sejauh mungkin. CLIP bukanlah teknik pembelajaran kontrastif pertama untuk imej dan teks, tetapi kesederhanaan dan keberkesanannya telah menjadikannya sebagai tunjang utama dalam aplikasi multimodal. . aplikasi modal, Daripada Stable Diffusion dan DALL-E kepada StyleCLIP dan OWL-ViT. Bagi kebanyakan aplikasi hiliran ini, model CLIP awal dianggap sebagai titik permulaan untuk "pra-latihan" dan keseluruhan model diperhalusi untuk kes penggunaan baharunya.
Walaupun OpenAI tidak pernah menyatakan atau berkongsi data yang digunakan secara eksplisit untuk melatih model CLIP asal, kertas CLIP menyebut bahawa model itu dilatih pada 400 juta pasangan teks imej yang dikumpul daripada Internet.
https: //www.php.cn/link/7c1bbdaebec5e20e91db1fe61222228f
align: skala pembelajaran perwakilan visual dan penglihatan dengan pengawasan teks yang bising. pasangan teks imej Memandangkan tiada butiran disediakan, adalah mustahil untuk mengetahui dengan tepat cara set data dibina. Tetapi dalam menerangkan set data baharu, mereka melihat Kapsyen Konseptual Google sebagai inspirasi - set data yang agak kecil (3.3 juta pasangan kapsyen imej) yang menggunakan teknik penapisan dan pasca pemprosesan yang mahal, walaupun ini Teknologi ini berkuasa, tetapi tidak berskala terutamanya) .
 Jadi set data berkualiti tinggi telah menjadi hala tuju penyelidikan Tidak lama selepas CLIP, ALIGN menyelesaikan masalah ini melalui penapisan skala. ALIGN tidak bergantung pada set data kapsyen imej yang kecil, beranotasi dengan teliti dan dipilih susun, sebaliknya memanfaatkan 1.8 bilion pasangan imej dan teks alt.
Jadi set data berkualiti tinggi telah menjadi hala tuju penyelidikan Tidak lama selepas CLIP, ALIGN menyelesaikan masalah ini melalui penapisan skala. ALIGN tidak bergantung pada set data kapsyen imej yang kecil, beranotasi dengan teliti dan dipilih susun, sebaliknya memanfaatkan 1.8 bilion pasangan imej dan teks alt.
Walaupun huraian teks alt ini secara purata lebih bising daripada tajuk, saiz set data yang kecil lebih daripada itu. Pengarang menggunakan penapisan asas untuk mengalih keluar pendua, imej dengan lebih 1,000 teks alt yang berkaitan, serta teks alt yang tidak bermaklumat (sama ada terlalu biasa atau mengandungi teg jarang). Dengan langkah mudah ini, ALIGN mencapai atau melebihi teknologi terkini dalam pelbagai tugasan sifar dan penalaan halus. . pasangan teks imej berkualiti tinggi untuk beberapa masalah yang terhad.
K-LITE memfokuskan pada menerangkan konsep, iaitu definisi atau penerangan kerana konteks dan konsep yang tidak diketahui boleh membantu membangunkan pemahaman yang luas. Penjelasan yang popular ialah apabila orang pertama kali memperkenalkan istilah teknikal dan perbendaharaan kata yang tidak biasa, mereka biasanya hanya mentakrifkannya Atau menggunakan analogi kepada sesuatu yang diketahui oleh semua orang.
Untuk melaksanakan pendekatan ini, penyelidik dari Microsoft dan UC Berkeley menggunakan WordNet dan Wiktionary untuk meningkatkan teks dalam pasangan teks imej. Untuk beberapa konsep terpencil, seperti label kelas dalam ImageNet, konsep itu sendiri dipertingkatkan, manakala untuk tajuk (cth. daripada GCC), frasa nama yang paling kurang biasa dipertingkatkan. Dengan pengetahuan berstruktur tambahan ini, model pra-latihan menunjukkan peningkatan yang ketara pada tugasan pembelajaran pemindahan. . domain visual. Kerja empirikal perintis dalam kedua-dua bidang juga telah menunjukkan dengan jelas bahawa prestasi model pengubah pada tugas unimodal boleh digambarkan dengan baik oleh undang-undang skala mudah. Ini bermakna apabila jumlah data latihan, masa latihan atau saiz model meningkat, seseorang boleh meramalkan prestasi model dengan agak tepat.
OpenCLIP mengkaji secara sistematik prestasi model pasangan data latihan dalam tugasan sifar pukulan dan penalaan halus dengan memanjangkan teori di atas kepada senario berbilang modal menggunakan set data pasangan imej-teks sumber terbuka terbesar yang dikeluarkan sehingga kini (5B) Impak . Seperti dalam kes unimodal, kajian ini mendedahkan bahawa prestasi model pada skala tugas multimodal dengan undang-undang kuasa dari segi pengiraan, bilangan sampel yang dilihat dan bilangan parameter model.
Lebih menarik daripada kewujudan undang-undang kuasa ialah hubungan antara penskalaan undang-undang kuasa dan data pra-latihan. Mengekalkan seni bina model CLIP OpenAI dan kaedah latihan, model OpenCLIP menunjukkan keupayaan penskalaan yang lebih kukuh pada tugas mendapatkan imej sampel. Untuk klasifikasi imej tangkapan sifar pada ImageNet, model OpenAI (dilatih pada set data proprietarinya) menunjukkan keupayaan penskalaan yang lebih kukuh. Penemuan ini menyerlahkan kepentingan pengumpulan data dan prosedur penapisan pada prestasi hiliran. 
Walau bagaimanapun, sejurus selepas OpenCLIP dikeluarkan, set data LAION telah dialih keluar daripada Internet kerana ia mengandungi imej yang menyalahi undang-undang.
MetaCLIP: Menyahmimiskan Data CLIP
OpenCLIP cuba memahami cara prestasi tugasan hiliran berubah dengan jumlah data, usaha pengiraan dan bilangan parameter model, manakala MetaCLIP memfokuskan pada cara memilih data. Seperti yang penulis katakan, "Kami percaya bahawa faktor utama dalam kejayaan CLIP adalah datanya, bukannya seni bina model atau sasaran pra-latihan
Untuk mengesahkan hipotesis ini, penulis membetulkan langkah-langkah latihan dan seni bina model." menjalankan eksperimen. Pasukan MetaCLIP menguji pelbagai strategi yang berkaitan dengan pemadanan subrentetan, penapisan dan pengedaran data mengimbangi, dan mendapati bahawa prestasi terbaik dicapai apabila setiap teks muncul maksimum 20,000 kali dalam set data latihan Untuk menguji teori ini, mereka akan melakukannya malah Perkataan "foto", yang berlaku 54 juta kali dalam kumpulan data awal, juga dihadkan kepada 20,000 pasangan teks imej dalam data latihan. Menggunakan strategi ini, MetaCLIP telah dilatih pada pasangan teks imej 400M daripada dataset Common Crawl, mengatasi prestasi model CLIP OpenAI pada pelbagai penanda aras. . -prestasi model multi-modal (seperti CLIP). Strategi penapisan MetaCLIP sangat berjaya, tetapi ia juga berdasarkan kaedah heuristik. Para penyelidik kemudian beralih kepada sama ada model boleh dilatih untuk melakukan penapisan ini dengan lebih cekap.
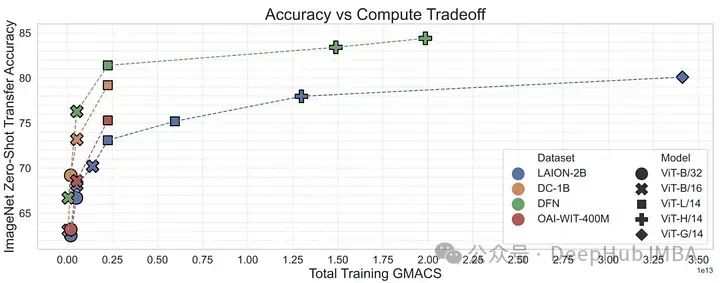
Untuk mengesahkan ini, penulis menggunakan data berkualiti tinggi daripada konseptual 12M untuk melatih model CLIP untuk menapis data berkualiti tinggi daripada data berkualiti rendah. Rangkaian Penapisan Data (DFN) ini digunakan untuk membina set data berkualiti tinggi yang lebih besar dengan memilih hanya data berkualiti tinggi daripada set data tidak dipilih (dalam kes ini Common Crawl). Model CLIP yang dilatih pada data yang ditapis mengatasi model yang dilatih hanya pada data awal berkualiti tinggi dan model yang dilatih pada sejumlah besar data yang tidak ditapis.https://arxiv.org/abs/2309.17425
 Ringkasan
Ringkasan
Model CLIP OpenAI mengubah cara kami memproses data berbilang modal dengan ketara. Tetapi CLIP hanyalah permulaan. Daripada data pra-latihan kepada butiran kaedah latihan dan fungsi kehilangan kontrastif, keluarga CLIP telah mencapai kemajuan yang luar biasa sejak beberapa tahun lalu. ALIGN menskalakan teks bising, K-LITE meningkatkan pengetahuan luaran, OpenCLIP mengkaji undang-undang penskalaan, MetaCLIP mengoptimumkan pengurusan data dan DFN meningkatkan kualiti data. Model-model ini memperdalam pemahaman kami tentang peranan CLIP dalam pembangunan kecerdasan buatan multimodal, menunjukkan kemajuan dalam menyambungkan imej dan teks.
Atas ialah kandungan terperinci Kajian semula pembangunan model CLIP, asas rajah Vincentian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!