
Rumah >Peranti teknologi >AI >Empat teknik pengesahan silang yang anda mesti pelajari dalam pembelajaran mesin
Empat teknik pengesahan silang yang anda mesti pelajari dalam pembelajaran mesin

- 王林ke hadapan
- 2023-04-12 16:31:122008semak imbas
Pengenalan
Pertimbangkan untuk mencipta model pada set data, tetapi ia gagal pada data yang tidak kelihatan.
Kami tidak boleh hanya memuatkan model pada data latihan kami dan menunggu ia berfungsi dengan sempurna pada data sebenar yang tidak kelihatan.
Ini ialah contoh overfitting, di mana model kami telah mengekstrak semua corak dan hingar dalam data latihan. Untuk mengelakkan perkara ini daripada berlaku, kami memerlukan satu cara untuk memastikan model kami telah menangkap sebahagian besar corak dan tidak mengambil setiap bit hingar dalam data (pincang rendah dan varians rendah). Salah satu daripada banyak teknik untuk menangani masalah ini ialah pengesahan silang.
Memahami pengesahan silang
Andaikan dalam set data tertentu, kami mempunyai 1000 rekod dan kami train_test_split() dilaksanakan padanya. Dengan mengandaikan kami mempunyai 70% data latihan dan 30% data ujian random_state = 0, parameter ini menghasilkan ketepatan 85%. Sekarang, jika kita menetapkan random_state = 50 katakan ketepatannya meningkat kepada 87%.
Ini bermakna jika kita terus memilih nilai ketepatan untuk keadaan_rawak yang berbeza, turun naik akan berlaku. Untuk mengelakkan ini, teknik yang dipanggil pengesahan silang akan dimainkan.
Jenis pengesahan silang
Pengesahan silang tinggalkan satu (LOOCV)
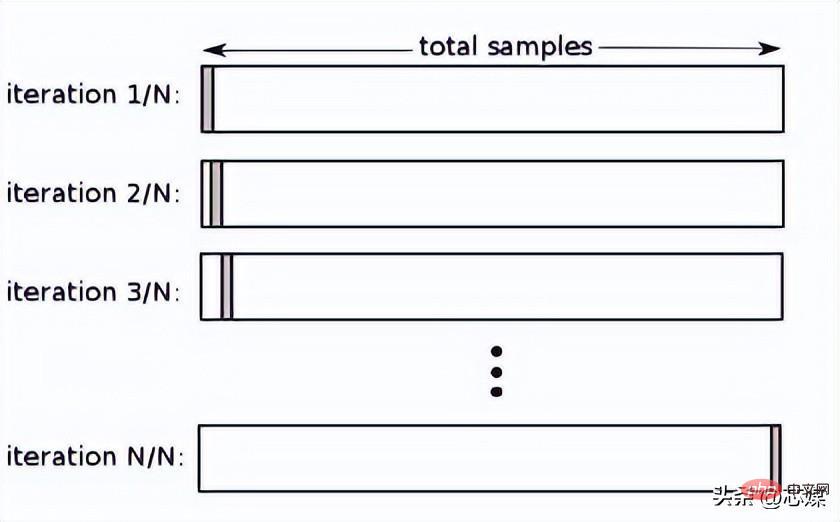
Dalam LOOCV, kami pilih 1 titik data sebagai ujian, dan semua data yang tinggal akan menjadi data latihan dari lelaran pertama. Dalam lelaran seterusnya, kami akan memilih titik data seterusnya sebagai ujian dan selebihnya sebagai data latihan. Kami akan mengulangi ini untuk keseluruhan set data supaya titik data terakhir dipilih sebagai ujian dalam lelaran akhir.
Lazimnya, untuk mengira pengesahan silang R² untuk prosedur pengesahan silang berulang, anda mengira skor R² untuk setiap lelaran dan mengambil puratanya.
Walaupun ia membawa kepada anggaran prestasi model yang boleh dipercayai dan tidak berat sebelah, ia adalah mahal dari segi pengiraan untuk dilakukan.
2. Pengesahan silang K-lipatan

dalam Dalam CV lipatan K, kami membahagikan set data kepada subset k (dipanggil lipatan), kemudian kami melatih semua subset tetapi meninggalkan satu subset (k-1) untuk penilaian selepas model latihan.
Andaikan kita mempunyai 1000 rekod dan K=5 kita. Nilai K ini bermakna kita mempunyai 5 lelaran. Bilangan titik data untuk lelaran pertama yang akan dipertimbangkan untuk data ujian ialah 1000/5=200 dari permulaan. Kemudian untuk lelaran seterusnya, 200 titik data seterusnya akan dianggap sebagai ujian, dan seterusnya.
Untuk mengira ketepatan keseluruhan, kami mengira ketepatan bagi setiap lelaran dan kemudian mengambil purata.
Ketepatan minimum yang boleh kita perolehi daripada proses ini akan menjadi ketepatan terendah yang dihasilkan antara semua lelaran, begitu juga ketepatan maksimum akan menjadi ketepatan yang dihasilkan di antara semua lelaran Menghasilkan ketepatan tertinggi.
3.Pengesahan silang hierarki
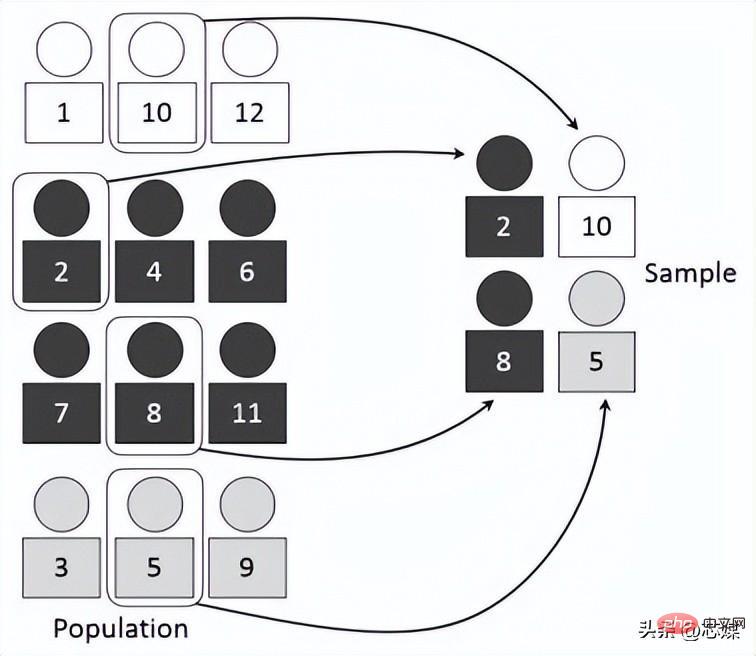
CV hierarki ialah lanjutan daripada pengesahan silang lipatan k biasa, tetapi khusus untuk masalah klasifikasi yang mana pemisahan tidak rawak sepenuhnya dan nisbah antara kelas sasaran adalah sama pada setiap lipatan seperti dalam set data penuh.
Andaikan kita mempunyai 1000 rekod yang mengandungi 600 ya dan 400 tidak. Oleh itu, dalam setiap percubaan, ia memastikan bahawa sampel rawak yang dimasukkan ke dalam latihan dan ujian diisikan sedemikian rupa sehingga sekurang-kurangnya beberapa kejadian setiap kelas akan hadir dalam pembahagian latihan dan ujian.
4.Pengesahan Silang Siri Masa
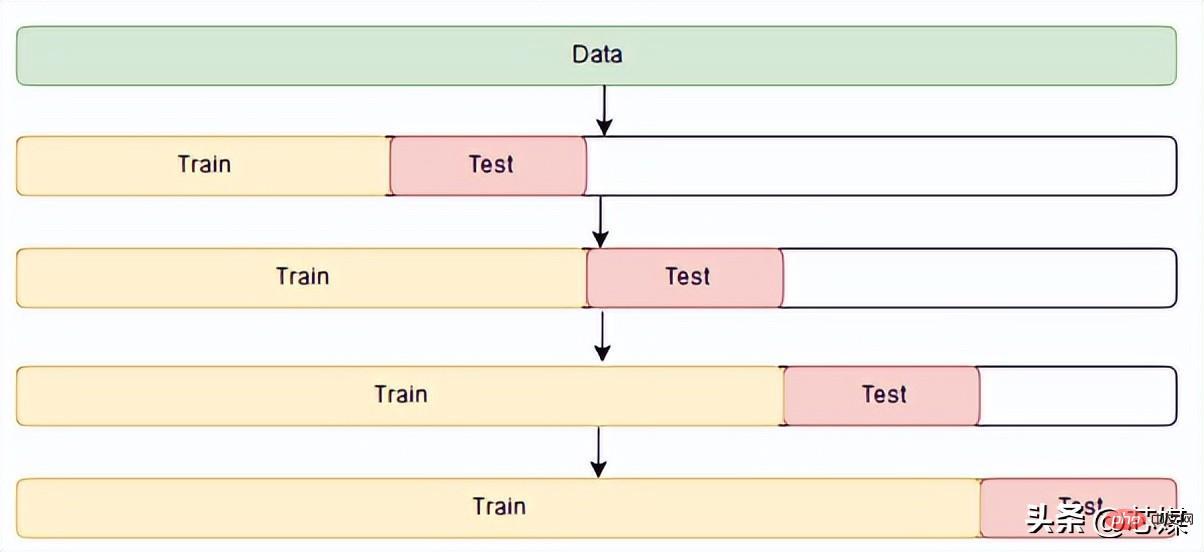
Dalam CV siri masa terdapat satu siri set ujian, setiap set ujian mengandungi satu pemerhatian. Set latihan yang sepadan mengandungi hanya pemerhatian yang berlaku sebelum pemerhatian 〈🎜〉 yang membentuk set ujian. Oleh itu, pemerhatian masa hadapan tidak boleh digunakan untuk membina ramalan.
Ketepatan ramalan dikira dengan purata set ujian. Proses ini kadangkala dipanggil "penilaian asal ramalan bergulir" kerana "asal asal" yang berasaskan ramalan itu dilancarkan ke hadapan dalam masa.
Kesimpulan
Dalam pembelajaran mesin, kami biasanya tidak mahu algoritma atau model yang berprestasi terbaik pada set latihan. Sebaliknya, kami mahukan model yang berprestasi baik pada set ujian dan model yang konsisten berprestasi baik diberikan data input baharu. Pengesahan silang ialah langkah kritikal untuk memastikan kami dapat mengenal pasti algoritma atau model tersebut.
Atas ialah kandungan terperinci Empat teknik pengesahan silang yang anda mesti pelajari dalam pembelajaran mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI