
Rumah >Peranti teknologi >AI >Video Google AI lagi hebat! VideoPrism, pengekod visual universal semua-dalam-satu, menyegarkan 30 ciri prestasi SOTA
Video Google AI lagi hebat! VideoPrism, pengekod visual universal semua-dalam-satu, menyegarkan 30 ciri prestasi SOTA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2024-02-26 09:58:241341semak imbas
Selepas model video AI Sora menjadi popular, syarikat utama seperti Meta dan Google telah mengetepikan untuk melakukan penyelidikan dan mengejar OpenAI.
Baru-baru ini, penyelidik daripada pasukan Google mencadangkan pengekod video universal - VideoPrism.
Ia boleh mengendalikan pelbagai tugas pemahaman video melalui satu model beku.
 Pictures
Pictures
Alamat kertas: https://arxiv.org/pdf/2402.13217.pdf
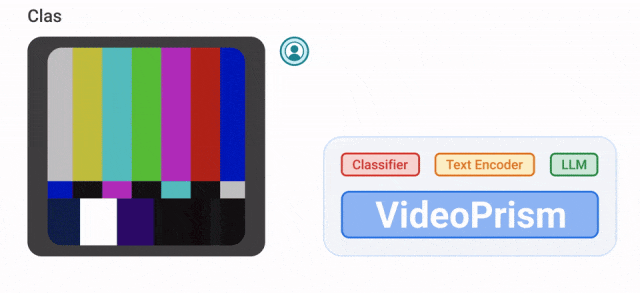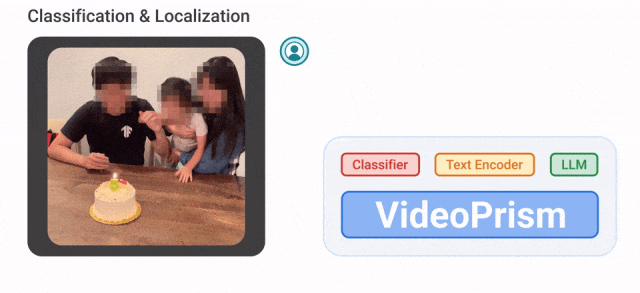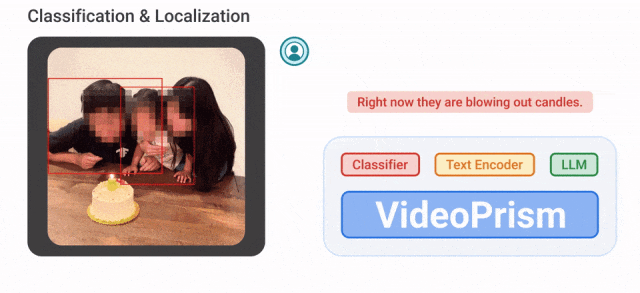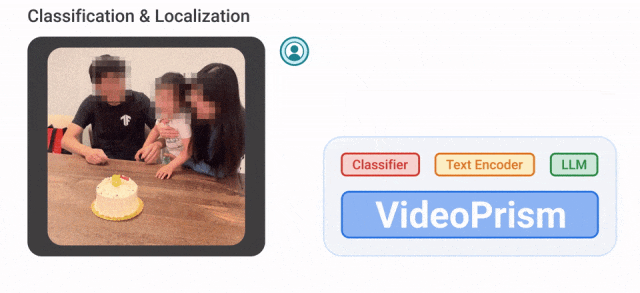
Sebagai contoh, VideoPrism boleh mengelaskan dan mengesan orang yang meniup lilin dalam video di bawah.
 Gambar
Gambar
Pengambilan teks video, berdasarkan kandungan teks, kandungan yang sepadan dalam video boleh diambil semula.
 Gambar
Gambar
Untuk contoh lain, huraikan video di bawah - seorang gadis kecil sedang bermain dengan blok bangunan.
Anda juga boleh menjalankan soalan dan jawapan QA.
- Apakah warna blok yang dia letak di atas blok hijau?
- Ungu.
 Pictures
Pictures
Para penyelidik telah melatih VideoPrism pada korpus heterogen yang mengandungi 36 juta pasangan sari kata video berkualiti tinggi dan 582 juta klip video dengan teks selari yang bising (seperti teks transkripsi ASR).
Perlu dinyatakan bahawa VideoPrism menyegarkan 30 SOTA dalam 33 ujian penanda aras pemahaman video. .
Walaupun penyelidikan terdahulu telah mencapai kemajuan besar dalam pemahaman video umum, membina "model video asas" yang sebenar masih merupakan matlamat yang sukar difahami. 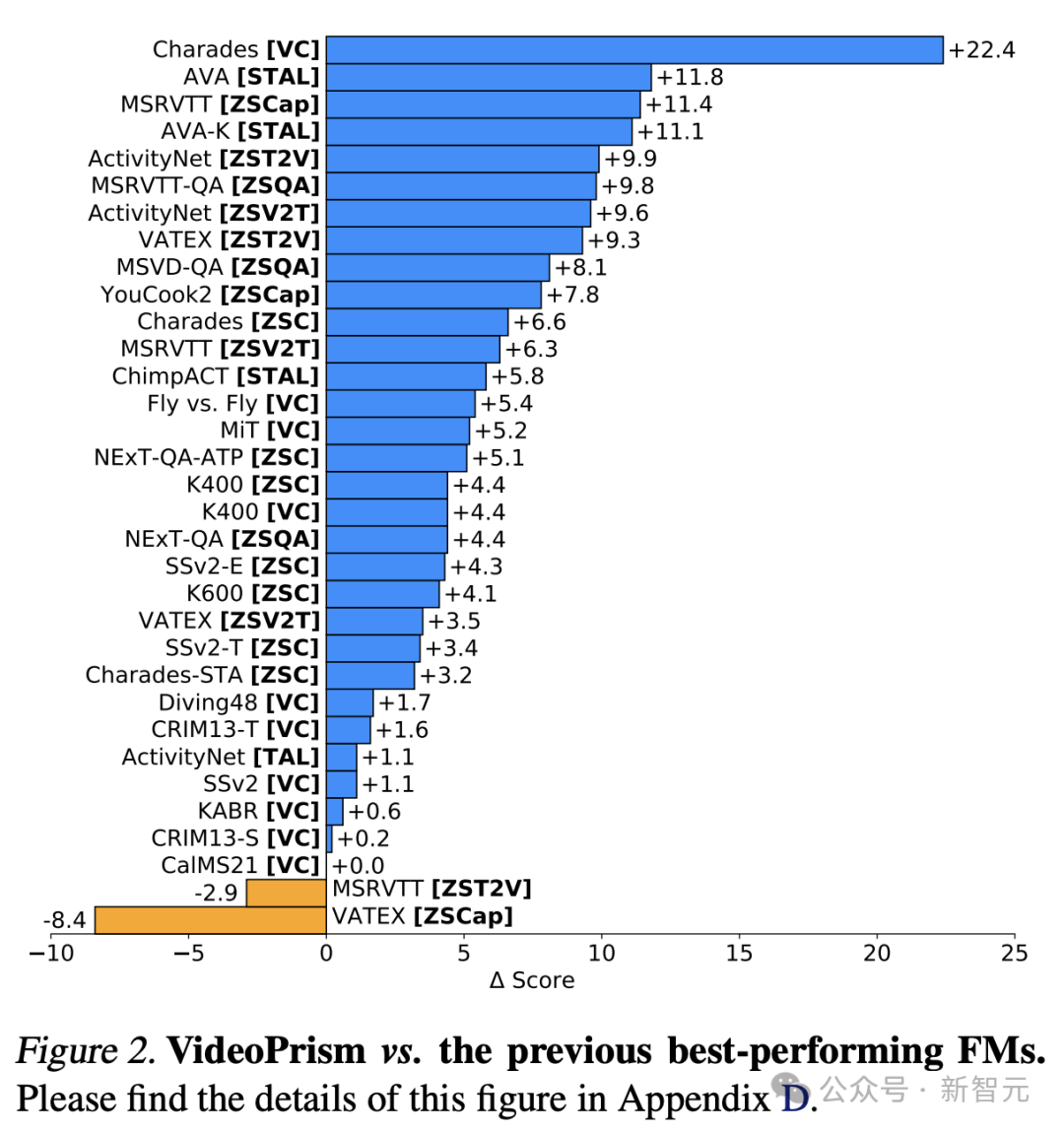 Sebagai tindak balas, Google melancarkan VideoPrism, pengekod visual tujuan umum yang direka untuk menyelesaikan pelbagai tugas pemahaman video, termasuk pengelasan, penyetempatan, pengambilan semula, sari kata dan menjawab soalan (QA).
Sebagai tindak balas, Google melancarkan VideoPrism, pengekod visual tujuan umum yang direka untuk menyelesaikan pelbagai tugas pemahaman video, termasuk pengelasan, penyetempatan, pengambilan semula, sari kata dan menjawab soalan (QA).
Struktur reka bentuk, kaedah latihan dua peringkat
Konsep reka bentuk di sebalik VideoPrism adalah seperti berikut.
Data pra-latihan ialah asas model asas (FM) Data pra-latihan yang ideal untuk ViFM ialah sampel yang mewakili semua video di dunia.  Dalam sampel ini, kebanyakan video tidak mempunyai teks selari yang menerangkan kandungan.
Dalam sampel ini, kebanyakan video tidak mempunyai teks selari yang menerangkan kandungan.
 Gambar
Gambar
Dari segi pemodelan, pengarang mula-mula mempelajari secara perbandingan pembenaman video semantik daripada semua pasangan teks video dengan kualiti yang berbeza.
Pembenaman semantik kemudiannya di peringkat global dan dilabel diperhalusi menggunakan data video tulen yang meluas, menambah baik pemodelan video bertopeng yang diterangkan di bawah.
Walaupun berjaya dalam bahasa semula jadi, pemodelan data bertopeng kekal mencabar untuk CV kerana kekurangan semantik dalam isyarat visual mentah.
Penyelidikan sedia ada menggabungkan kadar penyamaran yang tinggi dan ringan dengan meminjam semantik tidak langsung (seperti menggunakan CLIP untuk membimbing model atau tokenizer, atau semantik tersirat untuk menangani cabaran ini) atau menyamaratakan secara tersirat (seperti melabelkan tompok visual) gabungan dekoder.
Berdasarkan idea di atas, pasukan Google menggunakan pendekatan dua peringkat berdasarkan data pra-latihan.
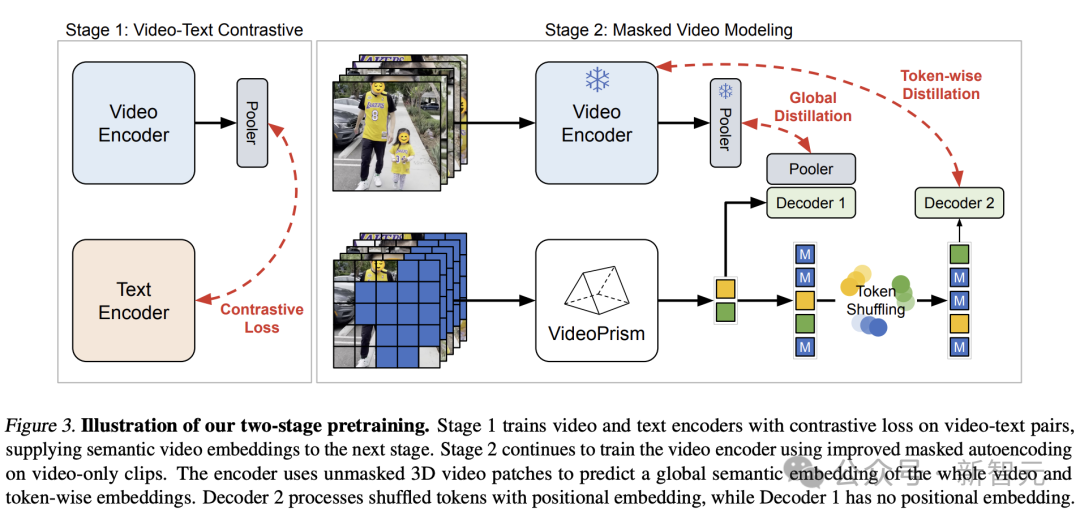 Gambar
Gambar
Pada peringkat pertama, pembelajaran kontrastif dilakukan untuk menjajarkan pengekod video dengan pengekod teks menggunakan semua pasangan teks video.
Berdasarkan penyelidikan terdahulu, pasukan Google meminimumkan skor persamaan semua pasangan teks video dalam kelompok, melakukan pengecilan kehilangan rentas entropi simetri.
Dan gunakan model imej CoCa untuk memulakan modul pengekodan spatial dan memasukkan WebLI ke dalam pra-latihan.
Sebelum mengira kerugian, ciri pengekod video diagregatkan melalui pengumpulan perhatian berbilang kepala (MAP).
Peringkat ini membolehkan pengekod video mempelajari semantik visual yang kaya daripada penyeliaan linguistik, dan model yang dihasilkan menyediakan pembenaman video semantik untuk latihan peringkat kedua.
 Gambar
Gambar
Di peringkat kedua, pengekod terus dilatih dan dua penambahbaikan dibuat:
- Model perlu meramalkan pembenaman global peringkat video dan token peringkat pertama berdasarkan video input yang tidak bertopeng patch Embedding
- Token output pengekod dikocok secara rawak sebelum dihantar ke penyahkod untuk mengelakkan pintasan pembelajaran.
Terutamanya, pra-latihan penyelidik memanfaatkan dua isyarat penyeliaan: penerangan tekstual video dan penyeliaan kendiri kontekstual, yang membolehkan VideoPrism berprestasi baik pada tugasan penampilan dan aksi.
Malah, kajian terdahulu menunjukkan bahawa kapsyen video terutamanya mendedahkan petunjuk penampilan, manakala penyeliaan kontekstual membantu mempelajari tindakan. .
Terbahagi terutamanya kepada empat kategori berikut:  (1) Secara amnya hanya pemahaman video, termasuk pengelasan dan kedudukan spatiotemporal
(1) Secara amnya hanya pemahaman video, termasuk pengelasan dan kedudukan spatiotemporal
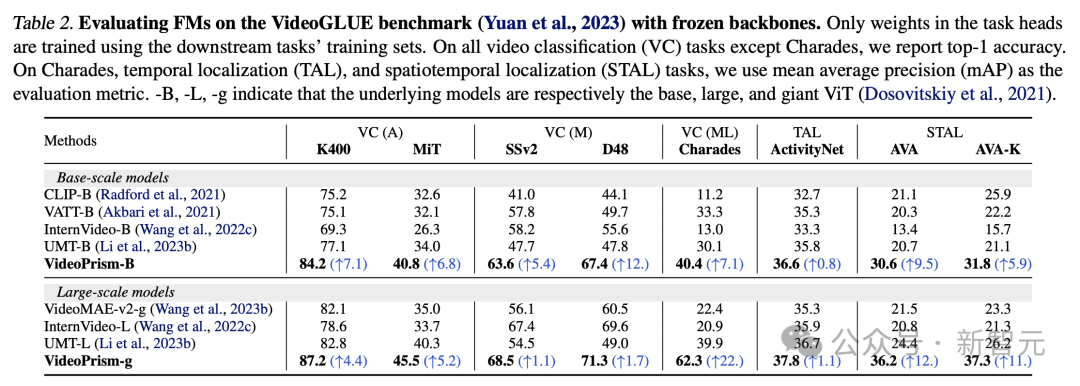
(4 ) Tugasan CV dalam sains Klasifikasi dan penyetempatan spatiotemporal Jadual 2 menunjukkan keputusan tulang belakang beku pada VideoGLUE. VideoPrism dengan ketara mengatasi garis dasar pada semua set data. Tambahan pula, meningkatkan saiz model asas VideoPrism daripada ViT-B kepada ViT-g dengan ketara meningkatkan prestasi. Perlu diingat bahawa tiada kaedah garis dasar mencapai hasil kedua terbaik merentas semua penanda aras, menunjukkan bahawa kaedah sebelumnya mungkin telah dibangunkan untuk menyasarkan aspek pemahaman video tertentu. Dan VideoPrism terus menambah baik dalam pelbagai tugasan ini. Hasil ini menunjukkan bahawa VideoPrism menyepadukan pelbagai isyarat video ke dalam satu pengekod: semantik pada pelbagai butiran, penampilan dan isyarat gerakan, maklumat spatiotemporal dan keteguhan kepada sumber video yang berbeza (seperti video dalam talian dan persembahan berskrip) .
 Imej
Imej
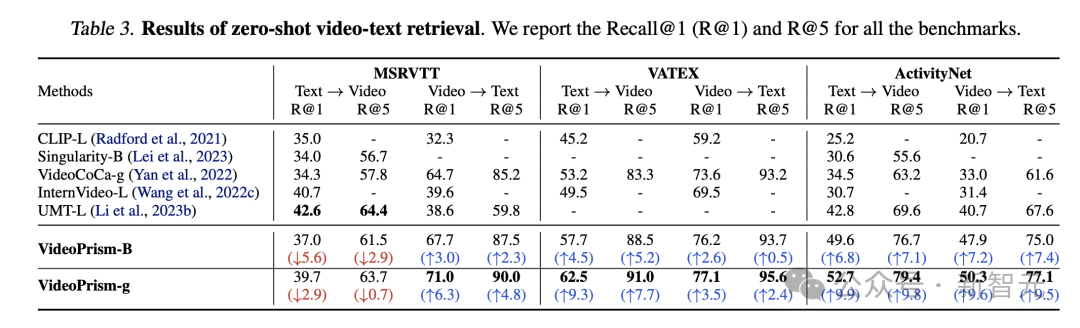
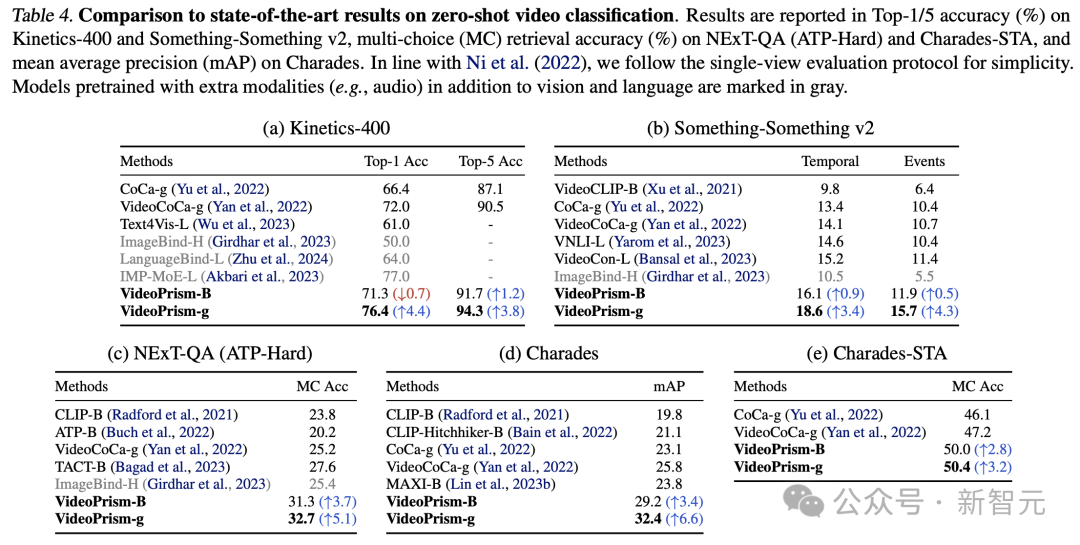
Pendapatan dan pengelasan teks video tangkapan sifar
Jadual 3 dan Jadual 4 masing-masing meringkaskan hasil perolehan teks video dan klasifikasi video.
Prestasi VideoPrism menyegarkan berbilang penanda aras, dan pada set data yang mencabar, VideoPrism telah mencapai peningkatan yang sangat ketara berbanding dengan teknologi sebelumnya.
 Gambar
Gambar
Kebanyakan hasil untuk model asas VideoPrism-B sebenarnya mengatasi model berskala lebih besar sedia ada.
Tambahan pula, VideoPrism adalah setanding atau lebih baik daripada model dalam Jadual 4 yang dipralatih menggunakan data dalam domain dan modaliti tambahan (cth. audio). Penambahbaikan dalam pengambilan sifar dan tugas klasifikasi ini mencerminkan keupayaan generalisasi VideoPrism yang berkuasa.
 Gambar
Gambar
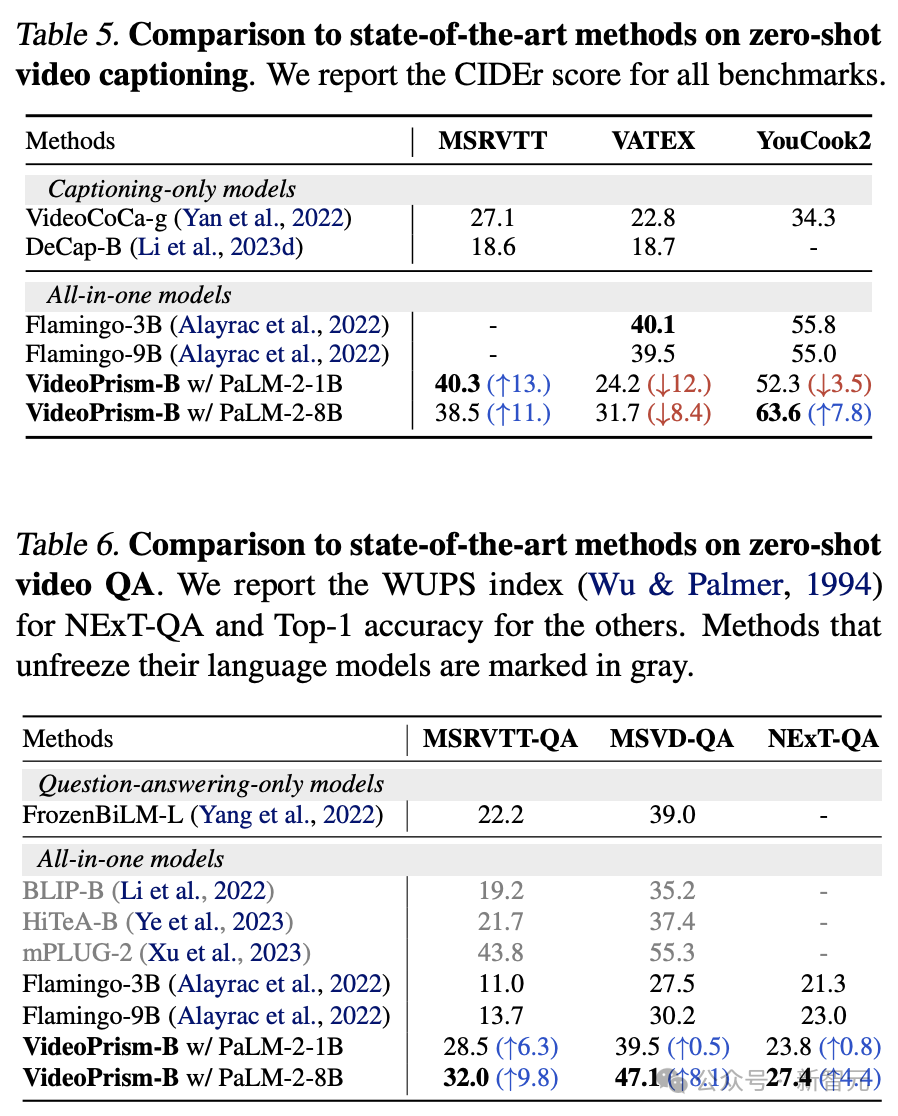
Sari kata video sampel sifar dan semakan kualiti
Jadual 5 dan Jadual 6 menunjukkan, masing-masing, keputusan sari kata video sampel sifar dan QA.
Walaupun seni bina model yang ringkas dan bilangan parameter penyesuai yang kecil, model terkini masih kompetitif dan, kecuali VATEX, berada di kedudukan antara kaedah teratas untuk membekukan model visual dan bahasa.
Hasilnya menunjukkan bahawa pengekod VideoPrism membuat generalisasi dengan baik kepada tugas penjanaan video ke pertuturan.
 Gambar
Gambar
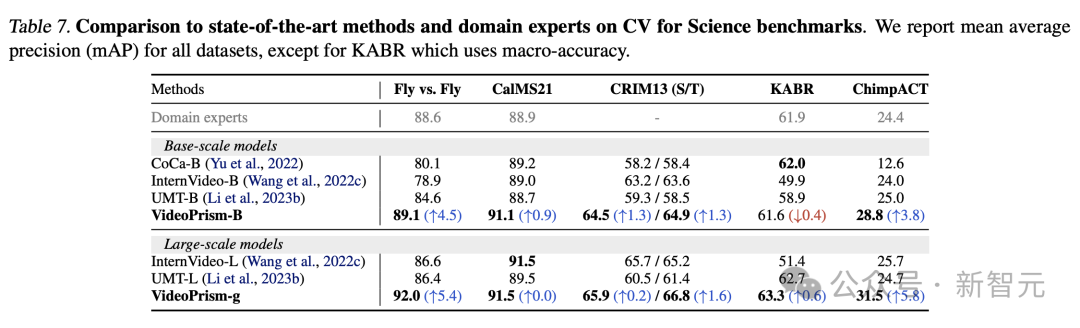
Tugas CV dalam domain saintifik
Universal ViFM menggunakan pengekod beku dikongsi merentas semua penilaian, dengan prestasi yang setanding dengan model khusus domain yang dikhususkan untuk satu tugasan.
Khususnya, VideoPrism selalunya menunjukkan prestasi terbaik dan mengatasi model pakar domain dengan model skala asas.
Penskalaan kepada model berskala besar boleh meningkatkan lagi prestasi pada semua set data. Keputusan ini menunjukkan bahawa ViFM mempunyai potensi untuk mempercepatkan analisis video dengan ketara dalam bidang yang berbeza.
Kajian Ablasi
Rajah 4 menunjukkan keputusan ablasi. Terutamanya, penambahbaikan berterusan VideoPrism pada SSv2 menunjukkan keberkesanan pengurusan data dan usaha reka bentuk model dalam mempromosikan pemahaman gerakan dalam video.
Walaupun garis dasar perbandingan sudah mencapai keputusan yang kompetitif pada K400, penyulingan global yang dicadangkan dan shuffling token meningkatkan lagi ketepatan.
 Gambar
Gambar
Rujukan:
https://arxiv.org/pdf/2402.13217.pdf
https://blog.research.google/2024 .html
Atas ialah kandungan terperinci Video Google AI lagi hebat! VideoPrism, pengekod visual universal semua-dalam-satu, menyegarkan 30 ciri prestasi SOTA. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!