
Rumah >Peranti teknologi >AI >Reka bentuk dan pelaksanaan rangka kerja inferens LLM berprestasi tinggi
Reka bentuk dan pelaksanaan rangka kerja inferens LLM berprestasi tinggi

- WBOYke hadapan
- 2024-02-26 09:52:29690semak imbas

1. Gambaran keseluruhan inferens model bahasa besar
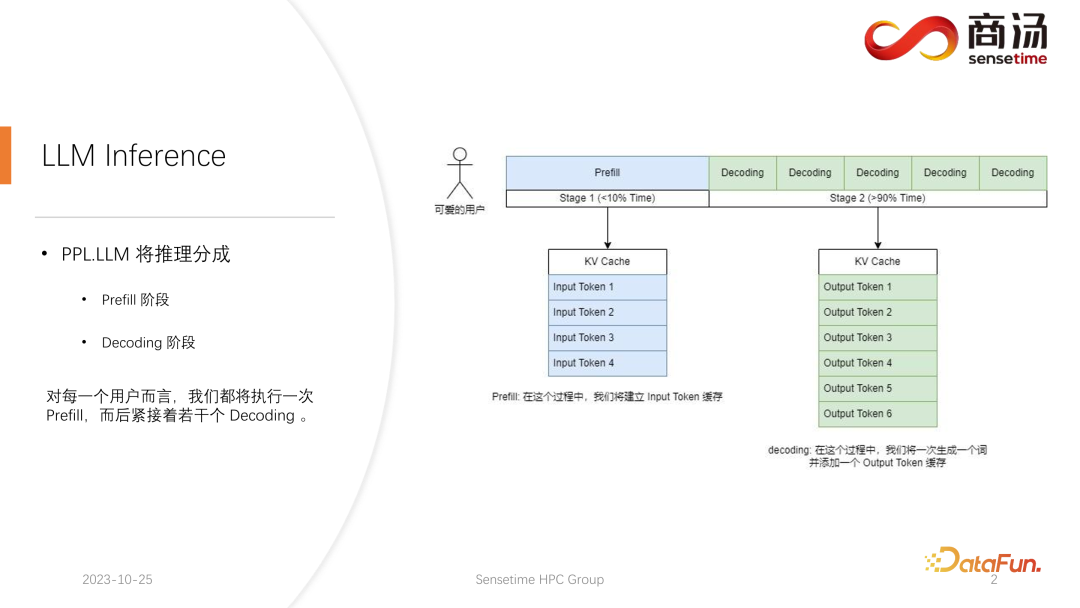
Berbeza daripada inferens model CNN tradisional, inferens model bahasa besar biasanya dibahagikan kepada dua peringkat: praisi dan penyahkodan. Proses penaakulan yang dijana selepas setiap permintaan dimulakan akan melalui proses Praisi Proses praisi akan mengira semua input pengguna dan menjana cache KV yang sepadan Kemudiannya akan melalui beberapa proses penyahkodan, pelayan akan jana aksara Dan masukkan ke dalam cache KV, dan kemudian ulang mengikut urutan.
Memandangkan proses penyahkodan dijana aksara demi aksara, penjanaan setiap serpihan jawapan mengambil banyak masa dan menjana sejumlah besar aksara. Oleh itu, bilangan peringkat penyahkodan adalah sangat besar, merangkumi sebahagian besar daripada keseluruhan proses penaakulan, melebihi 90%.
Dalam proses Praisi, walaupun banyak pengiraan perlu diproses kerana semua perkataan yang dimasukkan oleh pengguna perlu dikira pada masa yang sama, ini hanya satu proses sahaja. Oleh itu, Praisi hanya menyumbang kurang daripada 10% masa dalam keseluruhan proses inferens.
Dalam inferens model bahasa berskala besar, biasanya terdapat empat metrik utama untuk difokuskan: daya pemprosesan, kependaman perkataan pertama, kependaman keseluruhan dan permintaan sesaat (QPS). Penunjuk prestasi ini menilai keupayaan perkhidmatan sistem dari perspektif yang berbeza. Throughput mengukur seberapa cepat dan cekap sistem mengendalikan permintaan, manakala kependaman perkataan pertama merujuk kepada masa yang diperlukan untuk sistem menjana token pertamanya. Kependaman keseluruhan ialah masa yang diambil oleh sistem untuk menyelesaikan keseluruhan tugasan inferens. Akhir sekali, QPS mewakili bilangan permintaan yang dikendalikan oleh sistem sesaat. Metrik ini memainkan peranan penting dalam menilai prestasi model dan pengoptimuman sistem, membantu memastikan sistem boleh mengendalikan pelbagai tugas inferens dengan cekap.
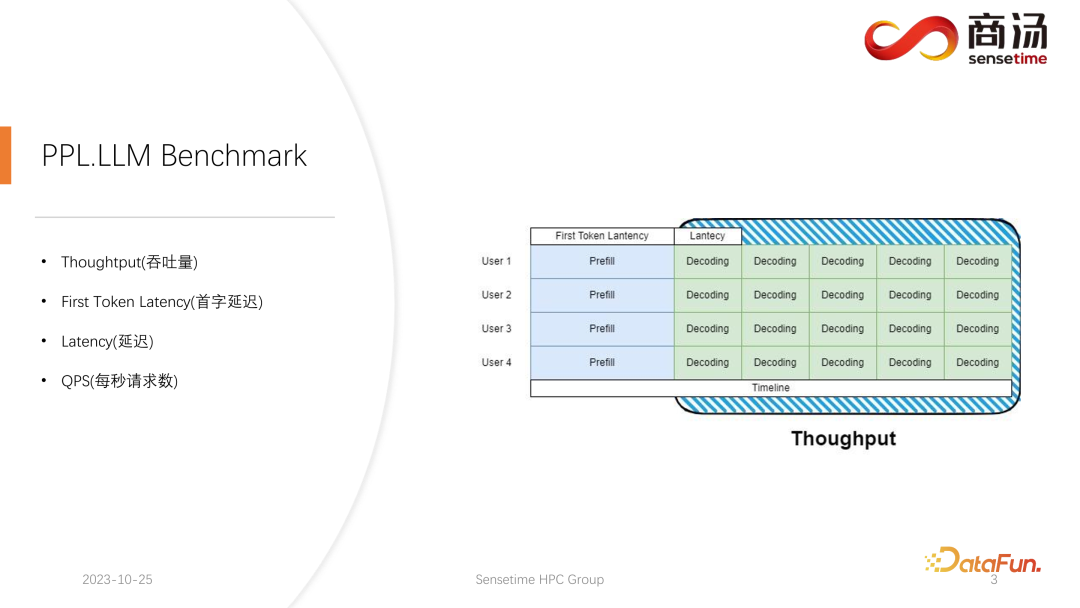
Mula-mula, mari perkenalkan Throughput. Daripada tahap inferens model, perkara pertama yang perlu difokuskan ialah daya pemprosesan. Throughput merujuk kepada berapa banyak penyahkodan boleh dilakukan setiap unit masa apabila beban sistem mencapai maksimum, iaitu, berapa banyak aksara yang dijana. Cara untuk menguji daya pengeluaran adalah dengan mengandaikan bahawa semua pengguna akan tiba pada masa yang sama, dan pengguna ini akan bertanya soalan yang sama, pengguna ini boleh bermula dan tamat pada masa yang sama, dan panjang teks yang mereka hasilkan dan panjang teks input adalah sama dengan. Satu kelompok lengkap dibentuk dengan menggunakan input yang sama. Dalam kes ini, daya tampung sistem dimaksimumkan. Tetapi keadaan ini tidak realistik, jadi ini adalah maksimum teori. Kami mengukur berapa banyak peringkat penyahkodan bebas yang boleh dilakukan oleh sistem dalam satu saat.
Satu lagi penunjuk utama ialah First Token Latency, iaitu masa yang diambil oleh pengguna untuk melengkapkan fasa Praisi selepas memasuki sistem inferens. Ini merujuk kepada masa tindak balas sistem untuk menjana aksara pertama. Ramai pengguna mengharapkan untuk menerima jawapan dalam masa 2-3 saat selepas memasukkan soalan ke dalam sistem.
Satu lagi metrik penting ialah kependaman. Latensi mewakili masa yang diperlukan untuk setiap operasi penyahkodan, yang mencerminkan selang masa yang diperlukan untuk sistem model bahasa yang besar untuk menjana setiap aksara semasa pemprosesan masa nyata, serta kelancaran proses penjanaan. Biasanya, kami mahu kependaman kekal di bawah 50 milisaat, yang bermaksud kami boleh menjana 20 aksara sesaat. Dengan cara ini, proses penjanaan model bahasa besar akan menjadi lebih lancar.
Metrik terakhir ialah QPS (permintaan sesaat). Ia mencerminkan berapa banyak permintaan pengguna boleh diproses dalam satu saat dalam perkhidmatan sistem dalam talian. Kaedah pengukuran penunjuk ini agak kompleks dan akan diperkenalkan kemudian.
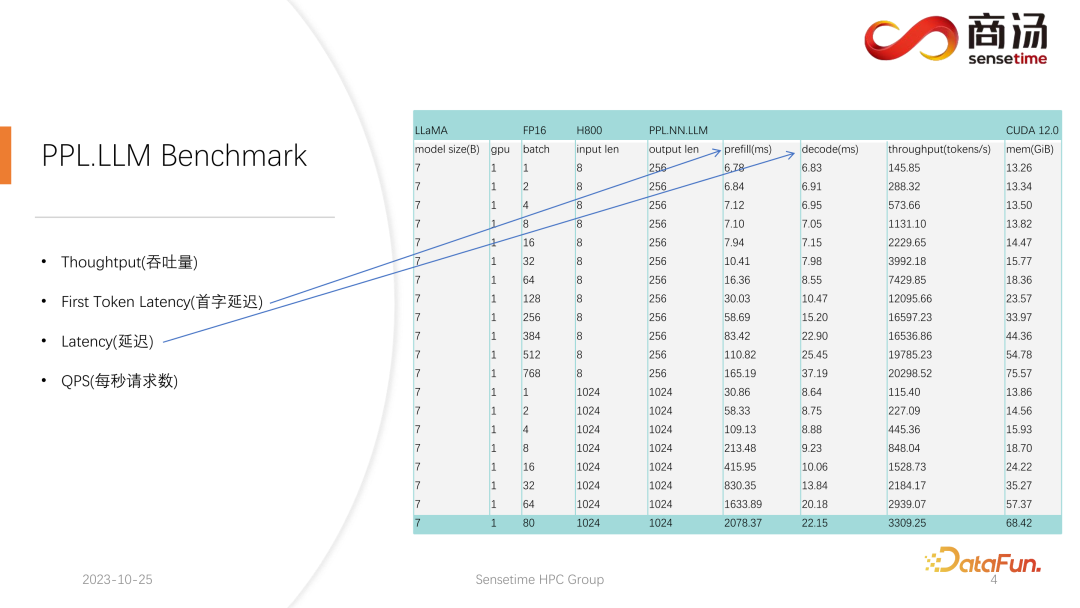
Kami telah menjalankan ujian yang agak lengkap pada kedua-dua penunjuk Latensi Token Pertama dan Latensi. Kedua-dua penunjuk ini akan banyak berubah disebabkan oleh panjang input pengguna yang berbeza dan saiz kelompok yang berbeza.
Seperti yang anda boleh lihat dalam jadual di atas, untuk model 7B yang sama, jika panjang input pengguna berubah dari 8 kepada 2048, masa Praisi adalah daripada 6.78 milisaat sehingga menjadi 2078 milisaat, iaitu 2 saat. Jika terdapat 80 pengguna, dan setiap pengguna memasukkan 1,024 perkataan, maka Praisi akan mengambil masa kira-kira 2 saat untuk dijalankan pada pelayan, yang berada di luar julat yang boleh diterima. Tetapi jika panjang input pengguna adalah sangat pendek, contohnya, hanya 8 perkataan dimasukkan setiap lawatan, walaupun 768 pengguna tiba pada masa yang sama, kelewatan perkataan pertama hanya akan menjadi kira-kira 165 milisaat.
Perkara yang paling relevan dengan kelewatan perkataan pertama ialah panjang input pengguna Semakin lama panjang input pengguna, semakin tinggi kelewatan perkataan pertama. Jika panjang input pengguna pendek, kelewatan perkataan pertama tidak akan menjadi halangan dalam keseluruhan proses inferens model bahasa yang besar.
Bagi kelewatan penyahkodan seterusnya, biasanya selagi ia bukan model tahap 100 bilion, kelewatan penyahkodan akan dikawal dalam masa 50 milisaat. Ia terutamanya dipengaruhi oleh saiz kelompok Semakin besar saiz kelompok, semakin besar kelewatan inferens, tetapi pada asasnya peningkatan tidak akan terlalu tinggi.
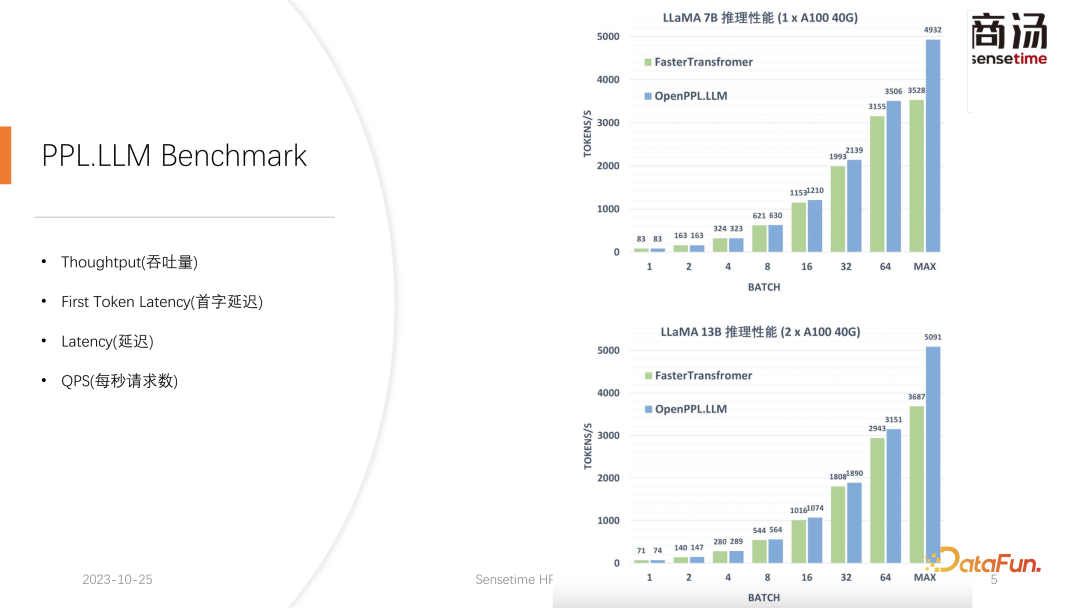
Throughput sebenarnya akan dipengaruhi oleh dua faktor ini. Jika panjang input pengguna dan panjang yang dijana adalah sangat panjang, daya pemprosesan sistem tidak akan menjadi sangat tinggi. Jika kedua-dua panjang input pengguna dan panjang yang dijana tidak terlalu panjang, daya pemprosesan sistem mungkin mencapai tahap yang sangat tidak masuk akal.
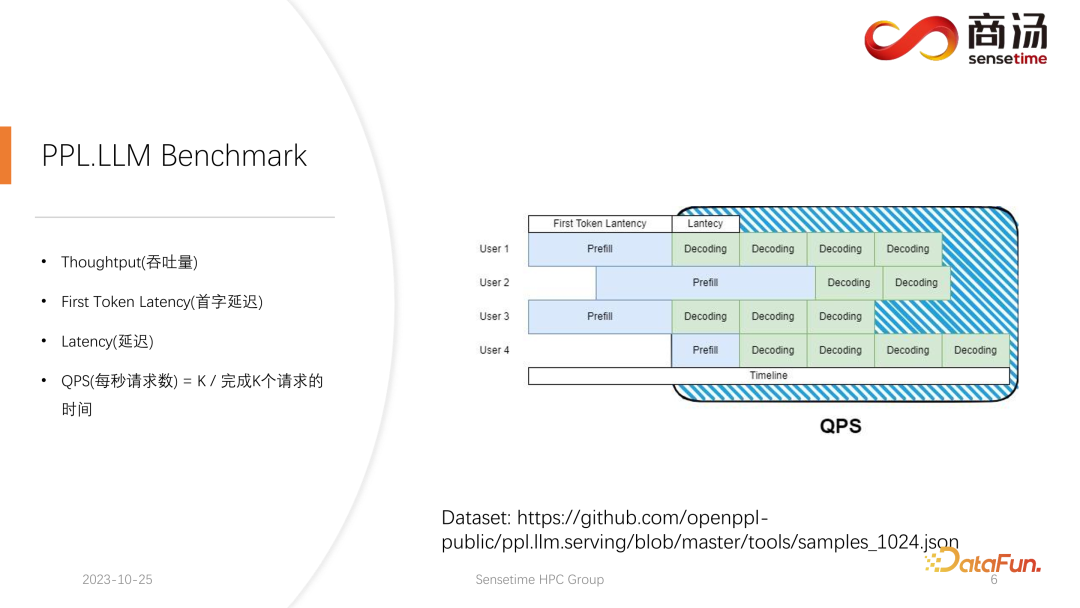
Jom tengok QPS sekali lagi. QPS ialah metrik yang sangat khusus yang menunjukkan bilangan permintaan sesaat yang boleh dikendalikan oleh sistem Semasa menjalankan ujian ini, kami akan menggunakan data sebenar. (Kami telah pun mengambil sampel data ini dan meletakkannya di github.)
Pengukuran QPS berbeza daripada throughput, kerana apabila sistem model bahasa yang besar sebenarnya digunakan, setiap pengguna datang Masanya tidak menentu. Sesetengah pengguna mungkin datang awal, dan ada yang datang lewat, dan tempoh penjanaan selepas setiap pengguna melengkapkan Praisi juga tidak pasti. Sesetengah pengguna mungkin keluar selepas menghasilkan 4 perkataan, manakala yang lain mungkin perlu menjana lebih daripada 20 perkataan.
Dalam peringkat Praisi, dalam inferens dalam talian sebenar, kerana pengguna sebenarnya menjana panjang yang berbeza, mereka akan menghadapi masalah: sesetengah pengguna akan menjananya terlebih dahulu, manakala sesetengah pengguna akan menjana banyak panjang sebelum ia tamat. Semasa binaan seperti ini, terdapat banyak tempat di mana GPU akan melahu. Oleh itu, dalam proses inferens sebenar, QPS kami tidak dapat memanfaatkan sepenuhnya daya pemprosesan. Daya pemprosesan kami mungkin hebat, tetapi kuasa pemprosesan sebenar mungkin lemah kerana pemprosesan penuh dengan lubang yang tidak boleh menggunakan kad grafik. Oleh itu, dari segi penunjuk QPS, kami akan mempunyai banyak penyelesaian pengoptimuman khusus untuk mengelakkan lubang pengiraan atau ketidakupayaan untuk menggunakan kad grafik dengan berkesan, supaya daya pengeluaran dapat memberi perkhidmatan sepenuhnya kepada pengguna. . Petunjuk.
1. Proses inferens LLM
Pertama, mari kita perkenalkan proses inferens model bahasa besar secara terperinci Seperti yang dinyatakan dalam artikel sebelum ini, setiap permintaan mesti melalui dua peringkat: praisi dan penyahkodan. Dalam peringkat praisi, sekurang-kurangnya Empat perkara perlu dilakukan:
Perkara pertama ialah menvektorkan input pengguna Proses tokenisasi merujuk kepada menukar input teks oleh pengguna kepada vektor , ia mungkin mengambil masa 10% daripada masa, ini memerlukan kos. 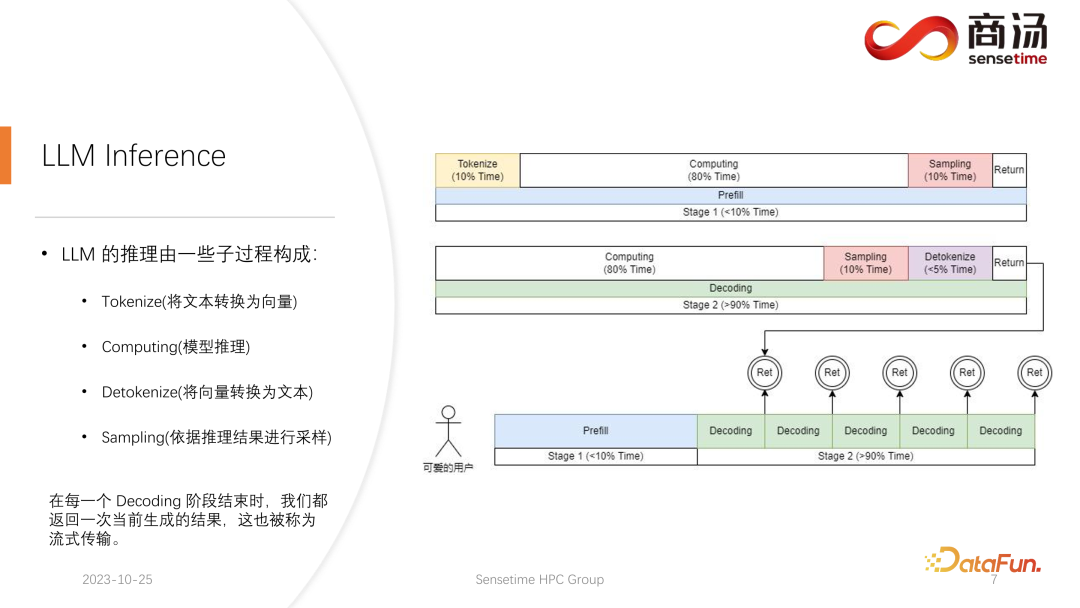
Pengiraan praisi sebenar kemudiannya akan dilakukan, dan proses ini akan mengambil kira-kira 80% masa.
Selepas pengiraan, pensampelan akan dilakukan Proses ini biasanya digunakan dalam Pytorch, seperti sampel dan p atas. Argmax digunakan dalam inferens model bahasa besar. Secara keseluruhannya, ia adalah satu proses menghasilkan kata akhir berdasarkan hasil model. Proses ini mengambil masa 10% daripada masa.
Akhirnya, hasil isian semula dikembalikan kepada pelanggan, yang mengambil masa yang agak singkat, kira-kira 2% hingga 5% masa.
Peringkat penyahkodan tidak memerlukan tokenisasi Setiap kali anda melakukan penyahkodan, ia akan bermula terus daripada pengiraan Keseluruhan proses penyahkodan akan mengambil masa 80%, dan pensampelan seterusnya, iaitu proses pensampelan dan penjanaan perkataan. , juga akan mengambil 10% masa . Tetapi ia akan mengambil masa detokenize bermakna bahawa selepas perkataan dijana, perkataan yang dijana adalah vektor dan perlu dinyahkodkan kembali kepada teks Operasi ini akan mengambil masa kira-kira 5% daripada masa yang dijana menjadi Kembali kepada pengguna.
Apabila permintaan baharu masuk, selepas praisi, penyahkodan akan dilakukan secara berulang Selepas setiap peringkat penyahkodan, hasilnya akan dikembalikan kepada pelanggan serta-merta. Proses penjanaan ini sangat biasa dalam model bahasa besar, dan kami memanggil kaedah ini penstriman.
2. Pengoptimuman saluran paip pra dan pasca pemprosesan dan pensampelan berprestasi tinggi
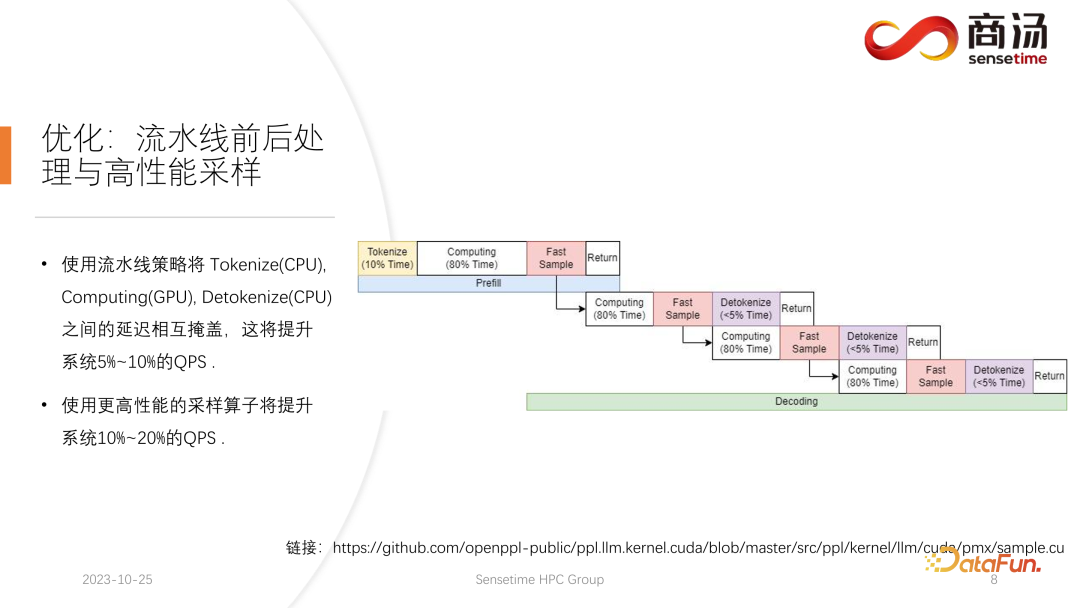
Pengoptimuman pertama yang diperkenalkan di sini ialah pengoptimuman saluran paip, yang tujuannya adalah untuk memaksimumkan kad
Dalam proses inferens model bahasa yang besar, proses tokenize, sampel pantas dan detokenize tiada kaitan dengan pengiraan model. Kita boleh membayangkan penaakulan keseluruhan model bahasa besar sebagai proses sedemikian Semasa proses melaksanakan praisi, selepas saya mendapat vektor perkataan sampel pantas, saya boleh segera memulakan peringkat penyahkodan seterusnya tanpa menunggu hasilnya. dikembalikan, kerana hasilnya sudah ada pada GPU. Apabila penyahkodan selesai, tidak perlu menunggu untuk penyahkodan selesai, dan penyahkodan seterusnya boleh dimulakan serta-merta. Oleh kerana nyahtoken ialah proses CPU, dua proses terakhir hanya melibatkan pengembalian hasil kepada pengguna dan tidak melibatkan sebarang operasi GPU. Dan selepas melaksanakan proses persampelan, kami sudah tahu apa perkataan yang dihasilkan seterusnya Kami telah memperoleh semua data yang kami perlukan dan boleh memulakan operasi seterusnya dengan segera tanpa menunggu penyiapan dua proses seterusnya. . mengembalikan keputusan Proses dan nyahtoknik;
Kolam benang di tengah digunakan untuk melaksanakan proses pengkomputeran.
Ketiga-tiga kumpulan benang ini mengasingkan ketiga-tiga bahagian kelewatan ini secara tidak segerak antara satu sama lain, dengan itu menutupi tiga bahagian kelewatan ini sebanyak mungkin. Ini akan membawa peningkatan QPS sebanyak 10% hingga 20% kepada sistem, yang merupakan pengoptimuman pertama yang kami lakukan.
3. Pengoptimuman: Batching dinamik
Selepas ini, PPL.LLM juga boleh melakukan pengoptimuman yang lebih menarik dipanggil dynamic batching.
Seperti yang dinyatakan sebelum ini, dalam proses penaakulan sebenar, panjang penjanaan pengguna adalah berbeza, dan masa ketibaan pengguna juga berbeza. Oleh itu, akan berlaku situasi di mana jika GPU semasa dalam proses inferens, sudah ada permintaan untuk inferens dalam talian, permintaan kedua dimasukkan Pada masa ini, proses penjanaan permintaan kedua akan Bercanggah dengan proses penjanaan permintaan pertama. Oleh kerana kami hanya mempunyai satu GPU dan hanya boleh menjalankan tugas secara bersiri pada GPU ini, kami tidak boleh menyamakannya dengan GPU sahaja.
Apa yang kami lakukan ialah, pada masa apabila permintaan kedua masuk, campurkan fasa praisi dengan fasa penyahkodan yang sepadan dengan permintaan pertama, dan jana fasa baharu yang dipanggil Langkah Gabung. Dalam Langkah Gabungan ini, bukan sahaja penyahkodan permintaan pertama akan dilakukan, malah Praisi permintaan kedua juga akan dilakukan. Ciri ini wujud dalam banyak sistem inferens model bahasa besar, dan pelaksanaannya telah meningkatkan QPS model bahasa besar sebanyak 100%. 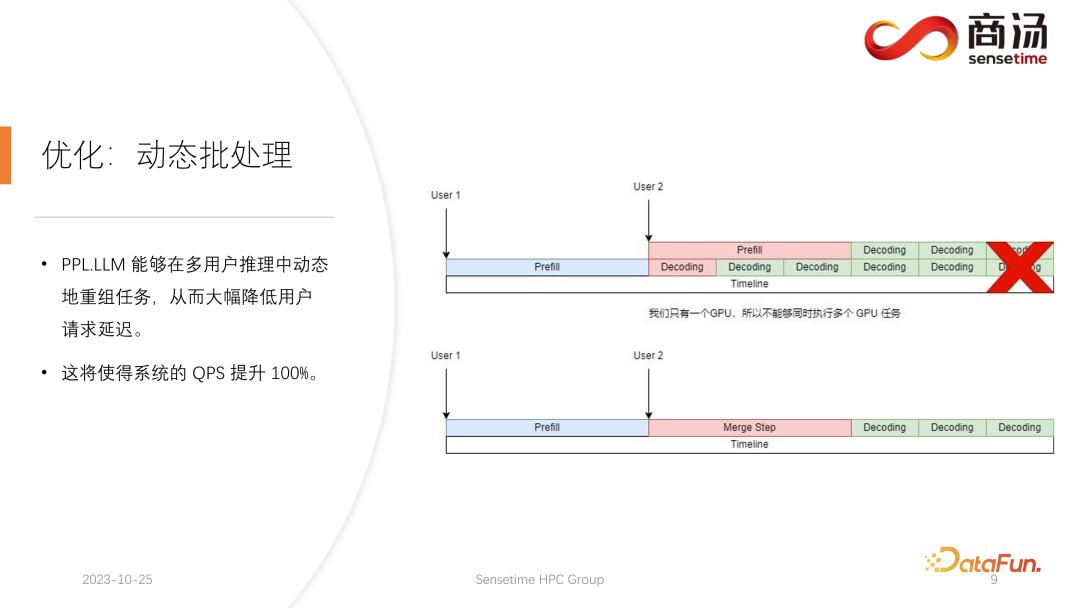
Proses khusus ialah proses penjanaan permintaan pertama sudah separuh jalan, bermakna ia akan mempunyai input panjang 1 apabila penyahkodan, manakala permintaan kedua baru dimasukkan dan sedang dalam proses Praisi , akan ada menjadi input dengan panjang 48. Penyambungan kedua-dua input ini antara satu sama lain di sepanjang dimensi pertama, panjang input yang disambung ialah 49, dan dimensi tersembunyi ialah input 4096. Dalam input panjang 49 ini, perkataan pertama diminta dahulu, dan baki 48 perkataan diminta kedua.
Oleh kerana dalam penaakulan model besar, operator yang perlu berpengalaman, seperti RMSNorm, pendaraban matriks dan perhatian, mempunyai struktur yang sama sama ada ia digunakan untuk penyahkodan atau praisi. Oleh itu, input yang disambungkan boleh terus dimasukkan ke dalam keseluruhan rangkaian dan dijalankan. Kita hanya perlu membezakan di satu tempat sahaja, iaitu perhatian. Semasa proses perhatian atau semasa pelaksanaan pengendali perhatian diri, kami akan melakukan shunt data, shunt semua permintaan penyahkodan ke dalam satu gelombang, shunt semua permintaan praisi ke dalam gelombang lain, dan laksanakan dua Operasi berbeza. Semua permintaan praisi akan melaksanakan Flash Attention semua pengguna penyahkod akan melaksanakan pengendali yang sangat istimewa yang dipanggil Decoding Attention. Selepas pengendali perhatian dilaksanakan secara berasingan, input pengguna ini akan disambungkan sekali lagi untuk melengkapkan pengiraan operator lain.
Untuk Langkah Penggabungan, sebenarnya, apabila setiap permintaan datang, kami akan menyambung permintaan ini bersama-sama dengan input semua permintaan pada sistem, melengkapkan pengiraan ini, dan kemudian terus melakukannya, iaitu pelaksanaan pemprosesan kelompok dinamik dalam model bahasa besar.
4. Pengoptimuman: Menyahkod Perhatian
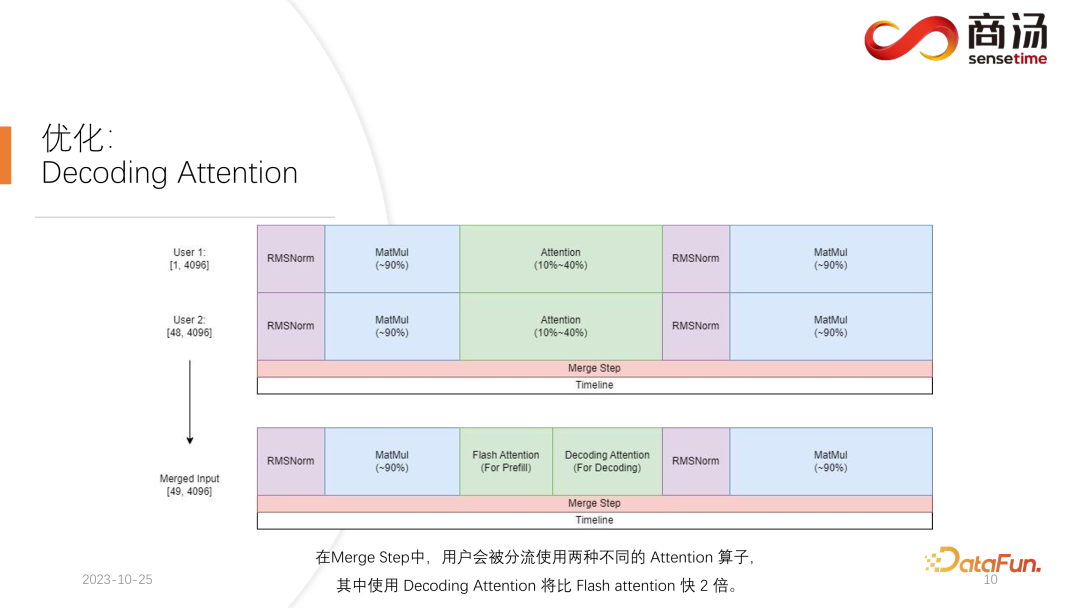
Pengendali Perhatian Penyahkodan tidak begitu terkenal dengan pengendali Perhatian Flash, tetapi ia sebenarnya lebih pantas daripada Perhatian Flash dalam memproses tugasan penyahkod.
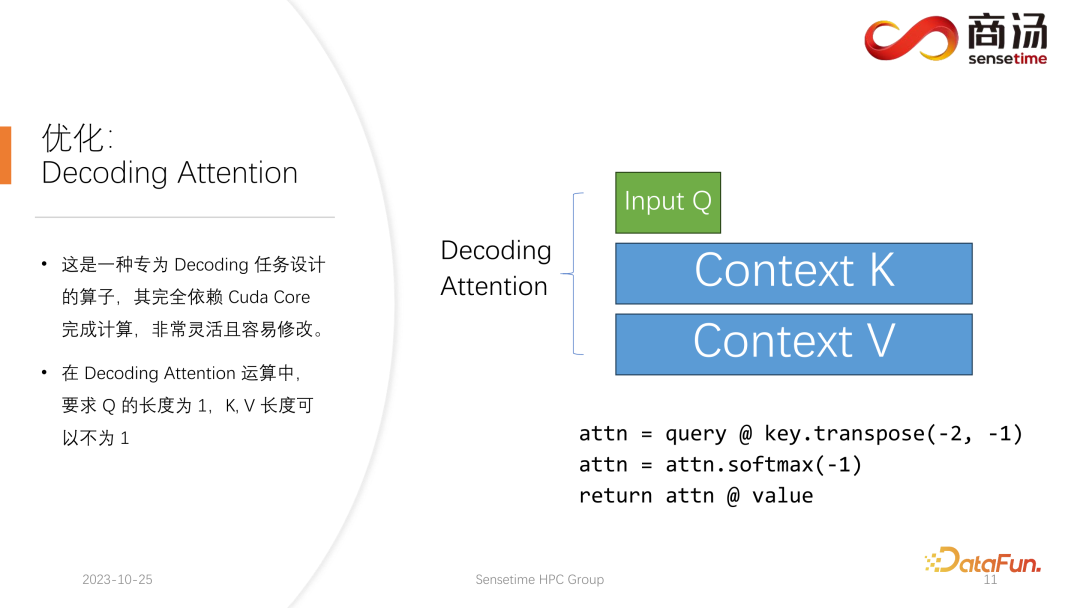
Ini ialah pengendali yang direka khas untuk tugasan penyahkodan Ia bergantung sepenuhnya pada Teras Cuda dan tidak bergantung pada Teras Tensor untuk menyelesaikan pengiraan. Ia sangat fleksibel dan mudah untuk diubah suai, tetapi ia mempunyai had, kerana ia dicirikan oleh operasi tensor penyahkodan, jadi ia memerlukan panjang input q mestilah 1, tetapi panjang k dan v adalah berubah-ubah. Ini adalah had Perhatian Penyahkodan Di bawah had ini, kita boleh melakukan beberapa pengoptimuman tertentu.

Pengoptimuman khusus ini menjadikan pelaksanaan pengendali perhatian dalam peringkat penyahkodan lebih pantas daripada Flash Attention. Pelaksanaan ini kini sumber terbuka dan anda boleh melawatinya di URL dalam gambar di atas.
5. Pengoptimuman VM: VM Allocator
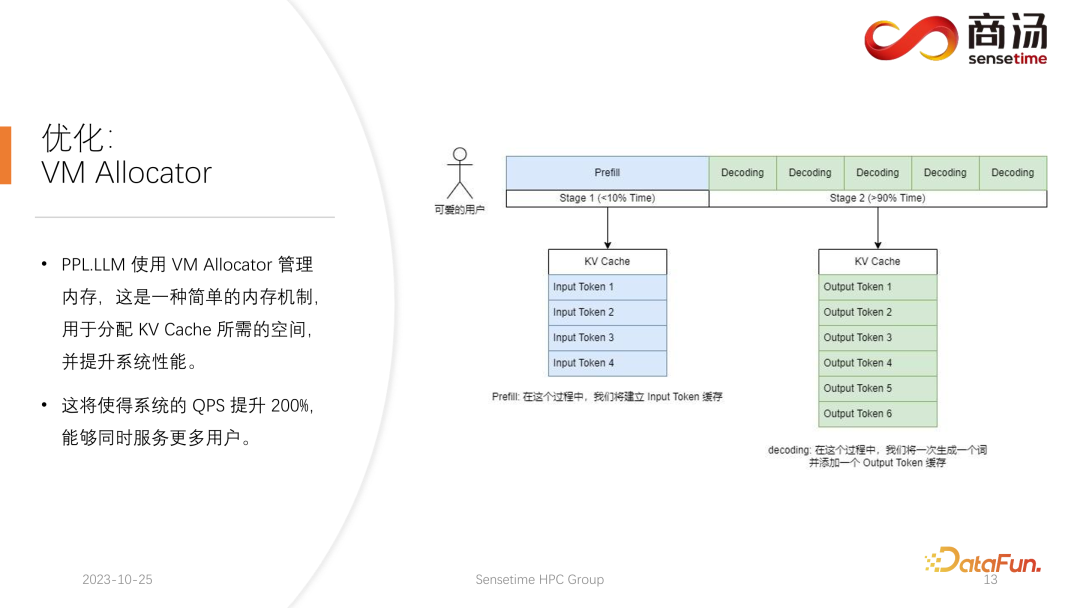
Satu lagi pengoptimuman ialah Virtual Memory Allocator, sepadan dengan pengoptimuman Perhatian Halaman. Apabila permintaan datang, ia akan melalui fasa praisi dan fasa penyahkodan Semua token inputnya akan menghasilkan cache KV ini merekodkan semua maklumat sejarah permintaan ini. Jadi berapa banyak ruang cache KV perlu diperuntukkan kepada permintaan sedemikian untuk memenuhinya untuk menyelesaikan tugas penjanaan ini? Jika ia dibahagikan terlalu banyak, memori video akan terbuang Jika ia dibahagikan terlalu sedikit, ia akan mencecah kedudukan cut-off cache KV semasa peringkat penyahkodan, dan tidak akan ada cara untuk terus menjananya.
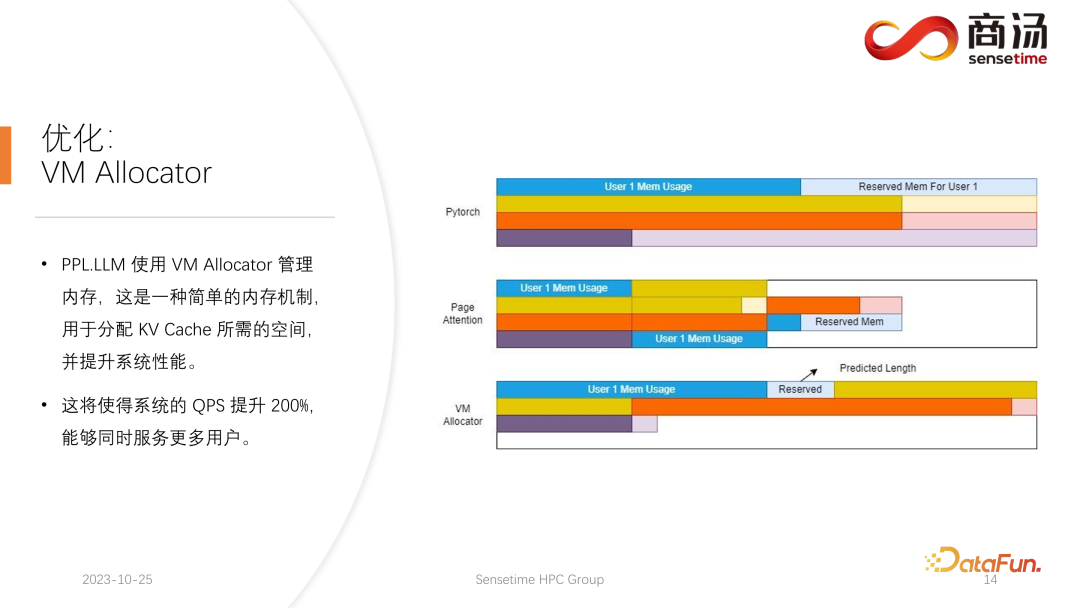
Untuk menyelesaikan masalah ini, ada 3 penyelesaian.
Kaedah pengurusan memori Pytorch adalah untuk menempah ruang yang cukup lama untuk setiap permintaan, biasanya 2048 atau 4096, untuk memastikan 4096 perkataan dijana. Tetapi panjang sebenar yang dihasilkan kebanyakan pengguna tidak akan begitu lama, jadi banyak ruang memori akan dibazirkan.
Perhatian Halaman menggunakan kaedah pengurusan memori video yang lain. Membenarkan pengguna menambah memori video secara berterusan semasa proses penjanaan. Sama seperti storan paging atau paging memori dalam sistem pengendalian. Apabila permintaan datang, sistem akan memperuntukkan sekeping kecil memori video untuk permintaan sekeping kecil memori video ini biasanya hanya cukup untuk menjana 8 aksara Apabila permintaan menjana 8 aksara, sistem akan menambah sekeping memori video , dan hasilnya boleh ditambah lagi Apabila menulis ke memori video ini, sistem akan mengekalkan senarai terpaut antara blok memori video dan blok memori video, supaya operator boleh mengeluarkan secara normal. Apabila panjang yang dijana terus berkembang, pengguna akan terus diperuntukkan blok memori video tambahan, dan senarai peruntukan blok memori video boleh dikekalkan secara dinamik, supaya sistem tidak mempunyai sejumlah besar sumber terbuang dan tidak memerlukan untuk menempah terlalu banyak memori video untuk permintaan ini.
PPL.LLM menggunakan mekanisme pengurusan Memori Maya untuk meramalkan panjang penjanaan yang diperlukan untuk setiap permintaan. Selepas setiap permintaan masuk, ruang berterusan akan diperuntukkan terus kepadanya, dan panjang ruang berterusan ini diramalkan. Walau bagaimanapun, ia mungkin sukar untuk dicapai secara teori, terutamanya dalam peringkat penaakulan dalam talian Adalah mustahil untuk mengetahui dengan jelas berapa lama kandungan akan dijana untuk setiap permintaan. Oleh itu kami mengesyorkan melatih model untuk melakukan ini. Kerana walaupun kita menggunakan model seperti Page Attention, kita masih akan menghadapi masalah. Perhatian Halaman Semasa proses berjalan, pada masa tertentu, contohnya, sudah ada empat permintaan pada sistem semasa, dan masih terdapat 6 blok memori video yang tinggal dalam sistem yang belum diperuntukkan. Pada masa ini, kami tidak mempunyai cara untuk mengetahui sama ada permintaan baharu akan masuk dan sama ada kami boleh terus menyediakan perkhidmatan untuknya, kerana empat permintaan semasa masih belum berakhir dan blok memori video baharu mungkin terus ditambahkan padanya dalam masa depan. Jadi walaupun dengan mekanisme Perhatian Halaman, masih perlu untuk meramalkan panjang penjanaan sebenar setiap pengguna. Hanya dengan cara ini kita boleh tahu sama ada kita boleh menerima input daripada pengguna baharu pada masa tertentu.
Ini adalah sesuatu yang tidak boleh dilakukan oleh sistem penaakulan semasa kami, termasuk PPL. Walau bagaimanapun, mekanisme pengurusan Memori Maya masih membolehkan kami mengelakkan pembaziran memori video pada tahap yang besar, dengan itu meningkatkan keseluruhan QPS sistem kepada kira-kira 200%.
6. Pengoptimuman: KV Cache Quantification
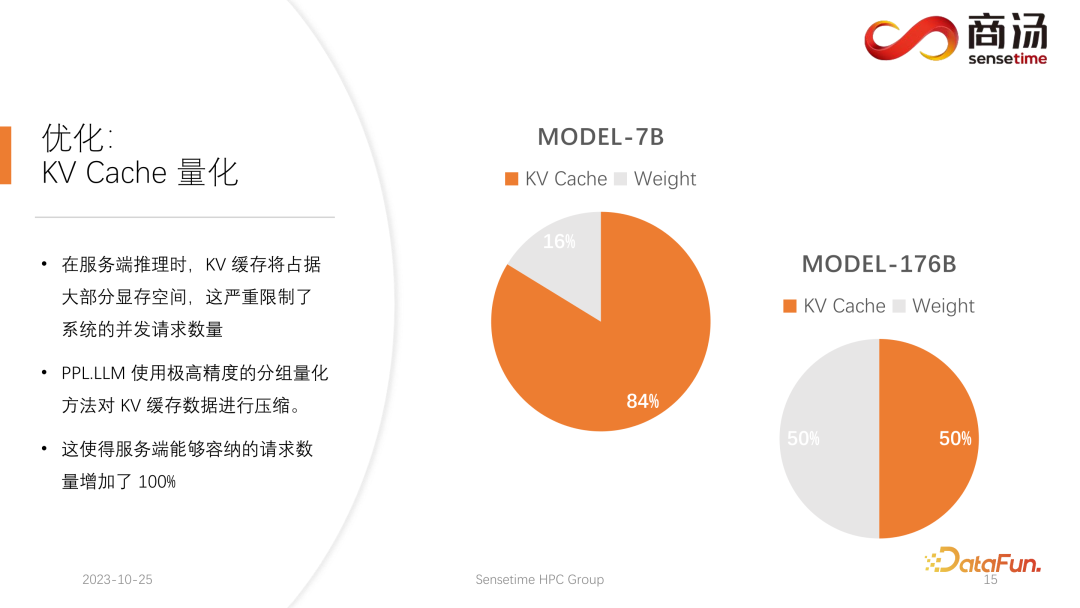
Satu lagi pengoptimuman yang dilakukan oleh PPL.LLM ialah kuantifikasi cache KV. Dalam proses inferens bahagian pelayan yang luas ruang memori video, yang akan mengehadkan bilangan permintaan serentak pada sistem dengan teruk.
Anda dapat melihat bahawa apabila menjalankan model bahasa yang besar seperti model 7B pada pelayan, terutamanya pada pelayan dengan memori besar seperti A100 dan H100, cache KVnya akan menduduki 84% ruang memori. , dan untuk model besar seperti 176B, yang cache KVnya juga akan menduduki lebih daripada 50% ruang cache. Ini akan mengehadkan bilangan keselarasan model dengan teruk Selepas setiap permintaan tiba, sejumlah besar memori video perlu diperuntukkan kepadanya. Dengan cara ini, bilangan permintaan tidak boleh ditingkatkan, dan dengan itu QPS dan throughput tidak boleh dipertingkatkan.
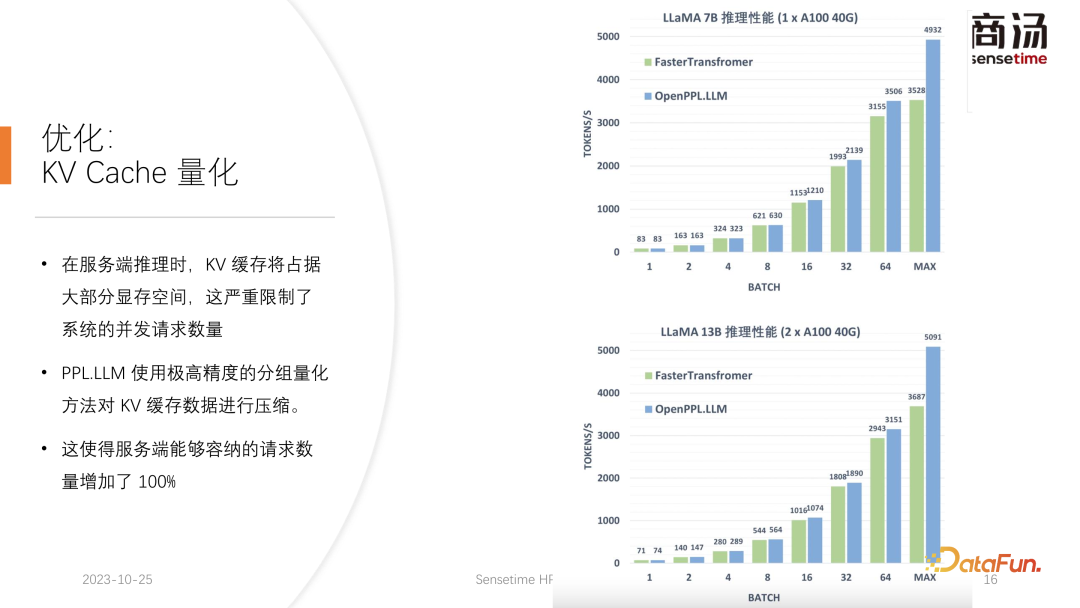
PPL.LLM menggunakan kaedah kuantisasi yang sangat istimewa, kuantisasi kumpulan, untuk memampatkan data dalam cache KV. Maksudnya, untuk data FP16 asal, percubaan akan dibuat untuk mengkuantumkannya kepada INT8. Ini akan mengurangkan saiz cache KV sebanyak 50% dan meningkatkan bilangan permintaan yang pelayan boleh menampung sebanyak 100%.
Sebab mengapa ia boleh meningkatkan daya pengeluaran kira-kira 50% berbanding Faster Transformer adalah tepat disebabkan oleh peningkatan saiz kelompok yang dibawa oleh pengkuantitian cache KV.
7. Pengoptimuman: Pengkuantitian pendaraban matriks

Selepas pengkuantitian cache KV, kami melakukan pengkuantitian pendaraban matriks yang lebih terperinci. Dalam keseluruhan proses inferens bahagian pelayan, pendaraban matriks menyumbang lebih daripada 70% daripada keseluruhan masa inferens PPL.LLM menggunakan kaedah pengkuantitian hibrid berselang-seli setiap saluran/per-token untuk mempercepatkan pendaraban matriks. Pengkuantitian ini juga sangat tepat dan boleh meningkatkan prestasi hampir 100%.
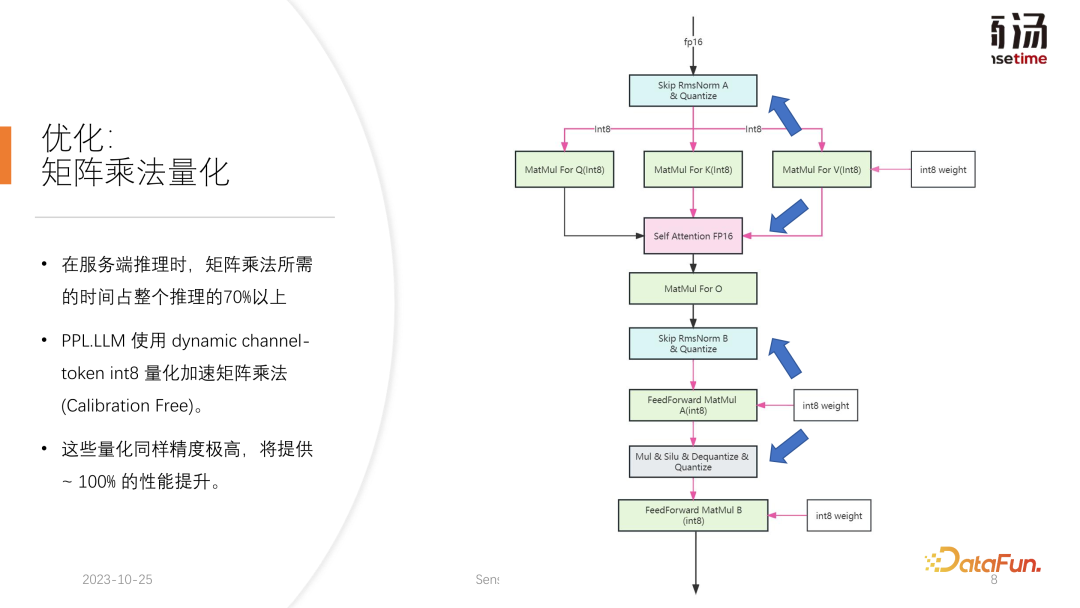
Kaedah khusus adalah untuk menyepadukan pengendali pengkuantitian berdasarkan pengendali RMSNorm ini akan mengira maklumat Token berdasarkan fungsi pengendali RMSNorm, dan mengira setiap nilai maksimum dan minimum , dan ukur data ini di sepanjang dimensi token. Maksudnya, data selepas RMSNorm akan ditukar daripada FP16 kepada INT8, dan kali ini kuantisasi adalah dinamik sepenuhnya dan tidak memerlukan penentukuran. Dalam pendaraban matriks QKV yang seterusnya, ketiga-tiga pendaraban matriks ini akan dikuantisasikan setiap saluran. Data yang mereka terima ialah INT8, dan pemberatnya juga INT8, jadi pendaraban matriks ini boleh melakukan pendaraban matriks INT8 penuh. Keluaran mereka akan diterima oleh Perhatian Lembut, tetapi proses penyahkuansian akan dilakukan sebelum penerimaan Kali ini proses penyahkuansian akan digabungkan dengan pengendali perhatian lembut.
Pendaraban matriks O seterusnya tidak melakukan pengkuantitian, dan proses pengiraan Perhatian Lembut itu sendiri tidak melakukan sebarang pengkuantitian. Dalam proses FeedForward yang seterusnya, kedua-dua matriks ini juga dikuantisasi dengan cara yang sama, digabungkan dengan RMSNorm di atas, atau digabungkan dengan fungsi pengaktifan seperti Silu dan Mul di atas. Pengendali pengkuantitian penyelesaian mereka akan digabungkan dengan pengendali hiliran mereka.
8: INT8 vs INT4
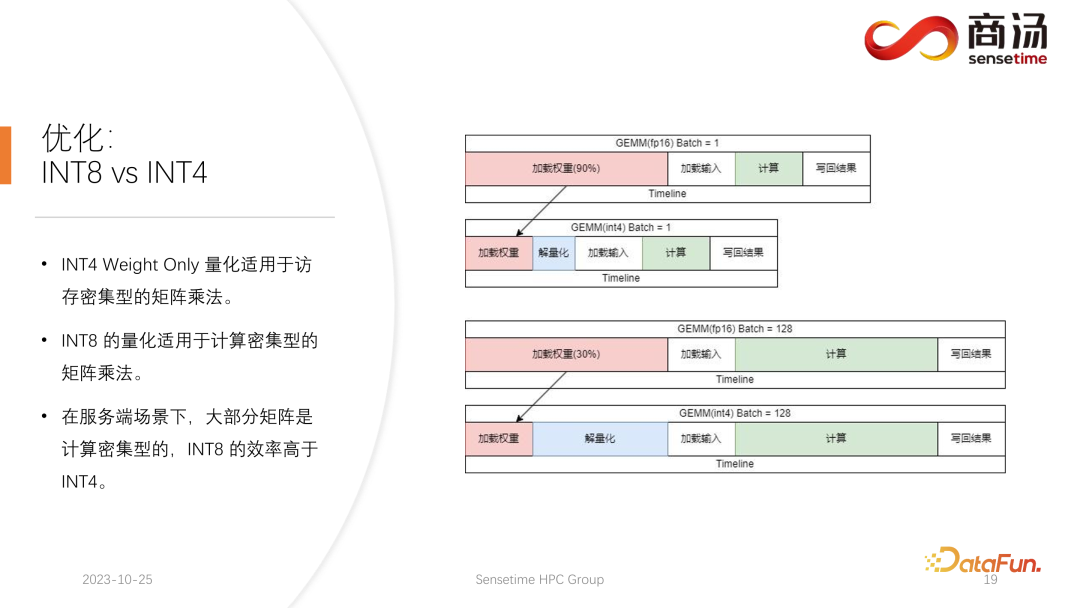
Tumpuan kuantitatif semasa kalangan akademik pada model bahasa besar mungkin tertumpu terutamanya pada INT4, tetapi dalam proses inferens sebelah pelayan, sebenarnya lebih sesuai. kuantifikasi.
Pengkuantitian INT4 juga dipanggil Pengkuantiti Berat Sahaja Kepentingan kaedah pengkuantitian ini ialah apabila kumpulan agak kecil semasa proses inferens model bahasa besar, 90% masa akan digunakan untuk memuatkan semasa pengiraan pendaraban matriks. proses. Kerana saiz pemberat adalah sangat besar, dan masa untuk memuatkan input adalah sangat singkat, input mereka, iaitu, pengaktifan juga sangat singkat, masa pengiraan tidak terlalu lama, dan masa untuk menulis semula keputusan adalah juga tidak terlalu lama, yang bermaksud sub pengiraan ini ialah pengendali intensif akses memori. Dalam kes ini, kami akan memilih kuantisasi INT4, dengan syarat kumpulan itu cukup kecil Selepas setiap pemberat dimuatkan menggunakan kuantisasi INT4, proses penyahkuansian akan mengikuti. Dekuantisasi ini akan menyahkuantisasi berat dari INT4 kepada FP16 Selepas melalui proses dekuantisasi, pengiraan seterusnya adalah sama dengan FP16 Maksudnya, kuantisasi INT4 Weight Only adalah sesuai untuk pendaraban matriks intensif akses memori. pengiraannya Proses masih diselesaikan oleh peranti pengkomputeran FP16.
Apabila kumpulan cukup besar, seperti 64 atau 128, kuantisasi Berat Sahaja INT4 tidak akan membawa sebarang peningkatan prestasi. Kerana jika batch cukup besar, masa pengiraan akan menjadi sangat lama. Dan kuantisasi Weight Only INT4 mempunyai titik yang sangat buruk Jumlah pengiraan yang diperlukan untuk proses penyahkuantasiannya akan meningkat dengan pertambahan kumpulan (GeMM Batch) Apabila kumpulan input meningkat, masa untuk penyahkuantasi juga akan meningkat Ia akan menjadi lebih lama dan lebih lama. Apabila saiz kelompok mencapai 128, kehilangan masa yang disebabkan oleh dekuantisasi dan kelebihan prestasi yang dibawa oleh pemberat pemuatan telah membatalkan satu sama lain. Maksudnya, apabila kumpulan mencapai 128, pengkuantitian matriks INT4 tidak akan lebih cepat daripada pengkuantitian matriks FP16, dan kelebihan prestasi adalah minimum. Kira-kira apabila kumpulan itu bersamaan dengan 64, kuantisasi Weight Only INT4 hanya akan menjadi 30% lebih cepat daripada FP16 Apabila kumpulan adalah 128, ia hanya akan menjadi kira-kira 20% lebih cepat atau lebih rendah.
Tetapi untuk INT8, perbezaan terbesar antara kuantisasi INT8 dan kuantisasi INT4 ialah ia tidak memerlukan sebarang proses nyahkuantisasi, dan pengiraannya boleh digandakan mengikut masa. Apabila kelompok bersamaan dengan 128, daripada pengkuantitian FP16 kepada INT8, masa untuk memuatkan pemberat akan dikurangkan separuh, dan masa pengiraan juga akan dikurangkan separuh, yang akan membawa pecutan kira-kira 100%.
Dalam senario bahagian pelayan, terutamanya kerana akan terdapat kemasukan permintaan yang berterusan, kebanyakan pendaraban matriks akan intensif secara pengiraan. Dalam kes ini, jika anda ingin mengejar daya pengeluaran muktamad, kecekapan INT8 sebenarnya lebih tinggi daripada INT4. Ini juga merupakan salah satu sebab mengapa kami terutamanya mempromosikan INT8 pada bahagian pelayan dalam pelaksanaan yang telah kami selesaikan setakat ini.
9. Pengoptimuman: FP8 vx INT8
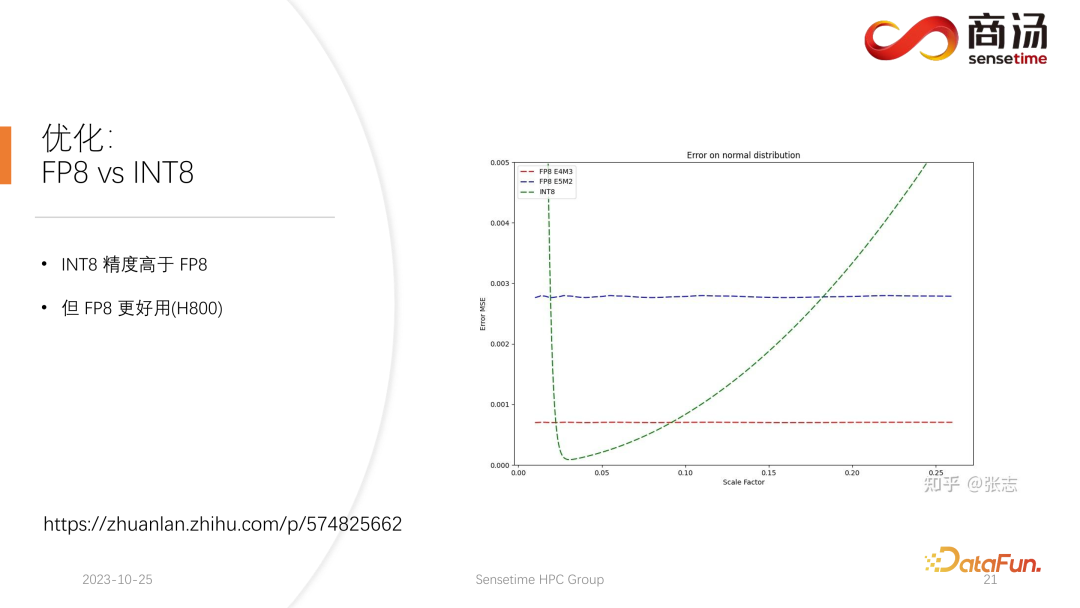
Pada H100, H800, 4090, kami boleh melakukan kuantisasi FP8. Format data seperti FP8 telah diperkenalkan dalam kad grafik generasi terbaru Nvidia. Ketepatan INT8 secara teorinya lebih tinggi daripada FP8, tetapi FP8 akan lebih berguna dan berprestasi lebih baik. Kami juga akan mempromosikan pelaksanaan FP8 dalam kemas kini seterusnya kepada proses inferens sebelah pelayan. Seperti yang dapat dilihat dalam rajah di atas, ralat FP8 adalah kira-kira 10 kali lebih besar daripada INT8. INT8 akan mempunyai faktor saiz terkuantisasi, dan ralat pengkuantitian INT8 boleh dikurangkan dengan melaraskan faktor saiz. Ralat pengkuantitian FP8 pada asasnya adalah bebas daripada faktor saiz Ia tidak dipengaruhi oleh faktor saiz, yang bermaksud bahawa kita pada dasarnya tidak perlu melakukan apa-apa penentukuran padanya. Tetapi ralatnya biasanya lebih tinggi daripada INT8.
10. Pengoptimuman: INT4 lwn kuantisasi bukan linear

PPL.LLM juga akan mengemas kini kuantisasi matriks INT4 dalam kemas kini seterusnya. Pengkuantitian matriks Weight Only ini terutamanya berfungsi pada bahagian terminal, untuk peranti seperti terminal mudah alih di mana kumpulan ditetapkan kepada 1. Dalam kemas kini seterusnya, ia akan berubah secara beransur-ansur daripada INT4 kepada pengkuantitian bukan linear. Kerana dalam proses pengiraan Berat Sahaja, akan berlaku proses dekuantisasi ini sebenarnya boleh disesuaikan dan mungkin bukan proses dekuantisasi linear Menggunakan proses dekuantisasi yang lain akan menjadikan kali ini ketepatan pengiraan lebih tinggi. . Dalam kemas kini PPL.LLM seterusnya, kami akan cuba menggunakan pengkuantitian sedemikian untuk mengoptimumkan inferens sisi peranti.
3. Perkakasan untuk inferens model bahasa besar
Akhir sekali, mari perkenalkan perkakasan untuk pemprosesan model bahasa besar.
Setelah struktur model ditentukan, kita akan mengetahui jumlah pengiraan khususnya, berapa banyak akses memori diperlukan dan berapa banyak jumlah pengiraan yang diperlukan. Pada masa yang sama, anda juga akan mengetahui lebar jalur, kuasa pengkomputeran, harga, dsb. bagi setiap kad grafik. Selepas menentukan struktur model dan menentukan penunjuk perkakasan, kita boleh menggunakan penunjuk ini untuk mengira daya pemprosesan maksimum untuk membuat kesimpulan model besar pada kad grafik ini, apakah kelewatan pengiraan, dan berapa banyak masa capaian memori yang diperlukan jadual tertentu boleh dikira. Kami akan membuat jadual ini umum dalam maklumat berikutnya Anda boleh mengakses jadual ini untuk melihat model kad grafik yang paling sesuai untuk inferens model bahasa besar. 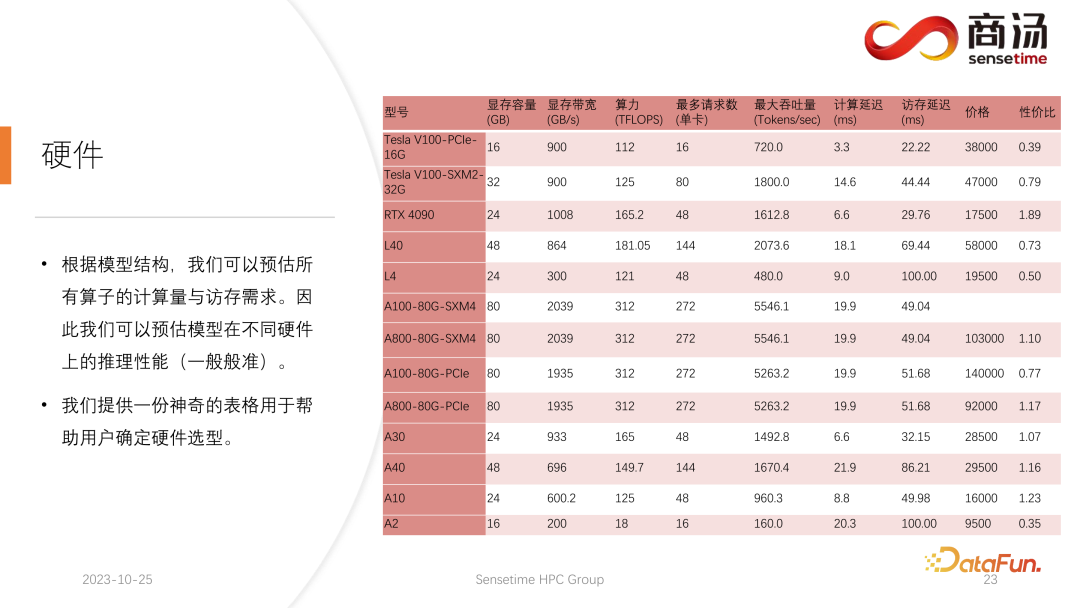
Untuk inferens model bahasa yang besar, kerana kebanyakan pengendali adalah intensif akses memori, kependaman akses memori akan sentiasa lebih tinggi daripada kependaman pengiraan. Kerana matriks parameter model bahasa besar sememangnya terlalu besar, walaupun pada A100/80G, apabila saiz kelompok dibuka kepada 272, kelewatan pengiraannya adalah kecil, tetapi kelewatan akses memori akan lebih tinggi. Oleh itu, banyak pengoptimuman kami bermula daripada akses memori. Apabila memilih perkakasan, hala tuju utama kami ialah memilih peralatan dengan lebar jalur yang agak tinggi dan memori video yang besar. Ini membolehkan model bahasa besar menyokong lebih banyak permintaan dan akses memori yang lebih pantas semasa inferens, dan daya pemprosesan yang sepadan akan lebih tinggi.
Di atas adalah kandungan yang dikongsikan kali ini. Semua maklumat yang berkaitan diletakkan pada cakera rangkaian, lihat pautan di atas. Semua kod kami juga telah menjadi sumber terbuka pada github. Anda dialu-alukan untuk berkomunikasi dengan kami pada bila-bila masa. 
IV. Soal Jawab
S1: Adakah terdapat sebarang masalah akses memori seperti Softmax dalam Flash Attention yang dioptimumkan dalam PPL.LLM?
A1: Menyahkod Attention ialah operator yang sangat istimewa Panjang Qnya sentiasa 1, jadi ia tidak akan menghadapi jumlah akses memori yang sangat besar dalam Softmax seperti Flash Attention. Malah, semasa pelaksanaan Decoding Attention, ia adalah pelaksanaan lengkap Softmax, dan ia tidak perlu dilaksanakan secepat Flash Attention.
S2: Mengapakah kuantisasi Berat Sahaja INT4 secara linear dengan kelompok Adakah ini nombor tetap?
A2: Ini adalah soalan yang bagus, pertama sekali, kuantifikasi penyelesaian ini tidak seperti yang difikirkan oleh semua orang pemberat. Sebenarnya, ini tidak berlaku, kerana ini adalah pengkuantitian penyelesaian yang disepadukan ke dalam pendaraban matriks Anda tidak boleh mengkuantisasi semua penyelesaian berat sebelum melakukan pendaraban matriks, letakkannya di sana dan kemudian bacanya. Dengan cara ini kuantisasi INT4 yang kami lakukan tidak bermakna. Ia sentiasa menyelesaikan pengkuantitian semasa proses pelaksanaan Kerana kita akan melakukan pendaraban matriks blok, bilangan bacaan dan tulis untuk setiap pemberat bukan 1. Ia perlu dikira secara berterusan. Maksudnya, berbeza daripada kaedah pengoptimuman pengkuantitian sebelumnya, akan ada pengendali pengkuantitian berasingan dan pengendali pengkuantitian penyelesaian. Untuk memasukkan dua pengendali, pengkuantitian penyelesaian disepadukan terus ke dalam operator. Kami sedang melakukan pendaraban matriks, jadi bilangan kali yang kami perlukan untuk menyelesaikan pengkuantitian bukan sekali.
S3: Bolehkah pengiraan kuantisasi songsang dalam Cache KV disembunyikan oleh tiruan?
A3: Mengikut ujian kami, ia boleh ditutup, dan sebenarnya masih banyak lagi. Pengkuantitian songsang dan pengkuantitian dalam pengiraan KV akan disepadukan ke dalam pengendali perhatian diri, khususnya Perhatian Penyahkodan. Mengikut ujian, pengendali ini mungkin bertopeng walaupun dengan 10 kali ganda jumlah pengiraan. Malah kelewatan capaian memori tidak dapat menutupnya kesesakan utamanya ialah capaian memori, dan jumlah pengiraannya jauh daripada mencapai tahap yang boleh menutup capaian ingatannya. Oleh itu, pengiraan pengkuantitian songsang dalam cache KV pada asasnya adalah perkara yang dilindungi dengan baik untuk pengendali ini.
Atas ialah kandungan terperinci Reka bentuk dan pelaksanaan rangka kerja inferens LLM berprestasi tinggi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- 使用curl_multi实现并发请求步骤分析
- Tiada anotasi manual diperlukan, rangka kerja arahan yang dijana sendiri memecahkan kesesakan kos LLM seperti ChatGPT
- Melalui MAmmoT, LLM menjadi generalis matematik: daripada logik formal kepada empat operasi aritmetik
- Pasukan Universiti Fudan mengeluarkan DISC-LawLLM, sistem perundangan pintar China, untuk membina penanda aras penilaian kehakiman dan sumber terbuka 300,000 data diperhalusi